Web Development Resources Site
webdevhub
Markdown PDF
This extension converts Markdown files to pdf, html, png or jpeg files.
Table of Contents
Features
Supports the following features * Syntax highlighting * emoji * markdown-it-checkbox * markdown-it-container * markdown-it-include * PlantUML * markdown-it-plantuml * mermaid
Sample files * pdf * html * png * jpeg
markdown-it-container
INPUT
::: warning
*here be dragons*
:::
OUTPUT
<div class="warning">
<p><em>here be dragons</em></p>
</div>
markdown-it-plantuml
INPUT
@startuml
Bob -[#red]> Alice : hello
Alice -[#0000FF]->Bob : ok
@enduml
OUTPUT

markdown-it-include
Include markdown fragment files: :[alternate-text]([https://github.com/yzane/vscode-markdown-pdf/blob/master/relative-path-to-file.md](https://github.com/yzane/vscode-markdown-pdf/blob/master/relative-path-to-file.md)).
├── [plugins]
│ └── README.md
├── CHANGELOG.md
└── README.md
INPUT
README Content
:[Plugins](https://github.com/yzane/vscode-markdown-pdf/blob/master/./plugins/README.md)
:[Changelog](https://github.com/yzane/vscode-markdown-pdf/blob/master/CHANGELOG.md)
OUTPUT
Content of README.md
Content of plugins/README.md
Content of CHANGELOG.md
mermaid
INPUT
```mermaid stateDiagram [*] --> First state First { [*] --> second second --> [*] } ```
OUTPUT

Install
Chromium download starts automatically when Markdown PDF is installed and Markdown file is first opened with Visual Studio Code.
However, it is time-consuming depending on the environment because of its large size (~ 170Mb Mac, ~ 282Mb Linux, ~ 280Mb Win).
During downloading, the message Installing Chromium is displayed in the status bar.
If you are behind a proxy, set the http.proxy option to settings.json and restart Visual Studio Code.
If the download is not successful or you want to avoid downloading every time you upgrade Markdown PDF, please specify the installed Chrome or ‘Chromium’ with markdown-pdf.executablePath option.
Usage
Command Palette
- Open the Markdown file
- Press
F1orCtrl+Shift+P - Type
exportand select below markdown-pdf: Export (settings.json)markdown-pdf: Export (pdf)markdown-pdf: Export (html)markdown-pdf: Export (png)markdown-pdf: Export (jpeg)markdown-pdf: Export (all: pdf, html, png, jpeg)

Menu
- Open the Markdown file
- Right click and select below
markdown-pdf: Export (settings.json)markdown-pdf: Export (pdf)markdown-pdf: Export (html)markdown-pdf: Export (png)markdown-pdf: Export (jpeg)markdown-pdf: Export (all: pdf, html, png, jpeg)

Auto convert
- Add
"markdown-pdf.convertOnSave": trueoption to settings.json - Restart Visual Studio Code
- Open the Markdown file
- Auto convert on save
Extension Settings
Visual Studio Code User and Workspace Settings
- Select File > Preferences > UserSettings or Workspace Settings
- Find markdown-pdf settings in the Default Settings
- Copy
markdown-pdf.*settings - Paste to the settings.json, and change the value

Options
List
CategoryOption nameConfiguration scopeSave optionsmarkdown-pdf.typemarkdown-pdf.convertOnSavemarkdown-pdf.convertOnSaveExcludemarkdown-pdf.outputDirectorymarkdown-pdf.outputDirectoryRelativePathFileStyles optionsmarkdown-pdf.stylesmarkdown-pdf.stylesRelativePathFilemarkdown-pdf.includeDefaultStylesSyntax highlight optionsmarkdown-pdf.highlightmarkdown-pdf.highlightStyleMarkdown optionsmarkdown-pdf.breaksEmoji optionsmarkdown-pdf.emojiConfiguration optionsmarkdown-pdf.executablePathCommon Optionsmarkdown-pdf.scalePDF optionsmarkdown-pdf.displayHeaderFooterresourcemarkdown-pdf.headerTemplateresourcemarkdown-pdf.footerTemplateresourcemarkdown-pdf.printBackgroundresourcemarkdown-pdf.orientationresourcemarkdown-pdf.pageRangesresourcemarkdown-pdf.formatresourcemarkdown-pdf.widthresourcemarkdown-pdf.heightresourcemarkdown-pdf.margin.topresourcemarkdown-pdf.margin.bottomresourcemarkdown-pdf.margin.rightresourcemarkdown-pdf.margin.leftresourcePNG JPEG optionsmarkdown-pdf.qualitymarkdown-pdf.clip.xmarkdown-pdf.clip.ymarkdown-pdf.clip.widthmarkdown-pdf.clip.heightmarkdown-pdf.omitBackgroundPlantUML optionsmarkdown-pdf.plantumlOpenMarkermarkdown-pdf.plantumlCloseMarkermarkdown-pdf.plantumlServermarkdown-it-include optionsmarkdown-pdf.markdown-it-include.enablemermaid optionsmarkdown-pdf.mermaidServer
Save options
markdown-pdf.type
- Output format: pdf, html, png, jpeg
- Multiple output formats support
Default: pdf
"markdown-pdf.type": [ "pdf", "html", "png", "jpeg" ],
markdown-pdf.convertOnSave
- Enable Auto convert on save
- boolean. Default: false
- To apply the settings, you need to restart Visual Studio Code
markdown-pdf.convertOnSaveExclude
Excluded file name of convertOnSave option
"markdown-pdf.convertOnSaveExclude": [ "^work", "work.md$", "work|test", "[0-9][0-9][0-9][0-9]-work", "work\test" // All '' need to be written as '\' (Windows) ],
markdown-pdf.outputDirectory
- Output Directory
All
\need to be written as\\(Windows)"markdown-pdf.outputDirectory": "C:\work\output",
- Relative path
- If you open the
Markdown file, it will be interpreted as a relative path from the file - If you open a
folder, it will be interpreted as a relative path from the root folder - If you open the
workspace, it will be interpreted as a relative path from the each root folder "markdown-pdf.outputDirectory": "output",
- Relative path (home directory)
If path starts with
~, it will be interpreted as a relative path from the home directory"markdown-pdf.outputDirectory": "~/output",
- If you set a directory with a
relative path, it will be created if the directory does not exist - If you set a directory with an
absolute path, an error occurs if the directory does not exist
markdown-pdf.outputDirectoryRelativePathFile
- If
markdown-pdf.outputDirectoryRelativePathFileoption is set totrue, the relative path set with markdown-pdf.outputDirectory is interpreted as relative from the file - It can be used to avoid relative paths from folders and workspaces
- boolean. Default: false
Styles options
markdown-pdf.styles
- A list of local paths to the stylesheets to use from the markdown-pdf
- If the file does not exist, it will be skipped
All
\need to be written as\\(Windows)"markdown-pdf.styles": [ "C:\Users\
\Documents\markdown-pdf.css", "/home/ /settings/markdown-pdf.css", ], - Relative path
- If you open the
Markdown file, it will be interpreted as a relative path from the file - If you open a
folder, it will be interpreted as a relative path from the root folder - If you open the
workspace, it will be interpreted as a relative path from the each root folder "markdown-pdf.styles": [ "markdown-pdf.css", ],
- Relative path (home directory)
If path starts with
~, it will be interpreted as a relative path from the home directory"markdown-pdf.styles": [ "~/.config/Code/User/markdown-pdf.css" ],
Online CSS (https://xxx/xxx.css) is applied correctly for JPG and PNG, but problems occur with PDF #67
"markdown-pdf.styles": [ "https://xxx/markdown-pdf.css" ],
markdown-pdf.stylesRelativePathFile
- If
markdown-pdf.stylesRelativePathFileoption is set totrue, the relative path set with markdown-pdf.styles is interpreted as relative from the file - It can be used to avoid relative paths from folders and workspaces
- boolean. Default: false
markdown-pdf.includeDefaultStyles
- Enable the inclusion of default Markdown styles (VSCode, markdown-pdf)
- boolean. Default: true
Syntax highlight options
markdown-pdf.highlight
- Enable Syntax highlighting
- boolean. Default: true
markdown-pdf.highlightStyle
- Set the style file name. for example: github.css, monokai.css …
- file name list
demo site : https://highlightjs.org/static/demo/
"markdown-pdf.highlightStyle": "github.css",
Markdown options
markdown-pdf.breaks
- Enable line breaks
- boolean. Default: false
Emoji options
markdown-pdf.emoji
- Enable emoji. EMOJI CHEAT SHEET
- boolean. Default: true
Configuration options
markdown-pdf.executablePath
- Path to a Chromium or Chrome executable to run instead of the bundled Chromium
- All
\need to be written as\\(Windows) To apply the settings, you need to restart Visual Studio Code
"markdown-pdf.executablePath": "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
Common Options
markdown-pdf.scale
- Scale of the page rendering
number. default: 1
"markdown-pdf.scale": 1
PDF options
- pdf only. puppeteer page.pdf options
markdown-pdf.displayHeaderFooter
- Enable display header and footer
- boolean. Default: true
markdown-pdf.headerTemplate
markdown-pdf.footerTemplate
- HTML template for the print header and footer
<span class='date'></span>: formatted print date<span class='title'></span>: markdown file name<span class='url'></span>: markdown full path name<span class='pageNumber'></span>: current page number<span class='totalPages'></span>: total pages in the document"markdown-pdf.headerTemplate": "<div style="font-size: 9px; margin-left: 1cm;"> <div style="font-size: 9px; margin-left: auto; margin-right: 1cm; "> ",
"markdown-pdf.footerTemplate": "<div style="font-size: 9px; margin: 0 auto;"> / ",
markdown-pdf.printBackground
- Print background graphics
- boolean. Default: true
markdown-pdf.orientation
- Paper orientation
- portrait or landscape
- Default: portrait
markdown-pdf.pageRanges
- Paper ranges to print, e.g., ‘1-5, 8, 11-13’
Default: all pages
"markdown-pdf.pageRanges": "1,4-",
markdown-pdf.format
- Paper format
- Letter, Legal, Tabloid, Ledger, A0, A1, A2, A3, A4, A5, A6
Default: A4
"markdown-pdf.format": "A4",
markdown-pdf.width
markdown-pdf.height
- Paper width / height, accepts values labeled with units(mm, cm, in, px)
If it is set, it overrides the markdown-pdf.format option
"markdown-pdf.width": "10cm", "markdown-pdf.height": "20cm",
markdown-pdf.margin.top
markdown-pdf.margin.bottom
markdown-pdf.margin.right
markdown-pdf.margin.left
Paper margins.units(mm, cm, in, px)
"markdown-pdf.margin.top": "1.5cm", "markdown-pdf.margin.bottom": "1cm", "markdown-pdf.margin.right": "1cm", "markdown-pdf.margin.left": "1cm",
PNG JPEG options
- png and jpeg only. puppeteer page.screenshot options
markdown-pdf.quality
jpeg only. The quality of the image, between 0-100. Not applicable to png images
"markdown-pdf.quality": 100,
markdown-pdf.clip.x
markdown-pdf.clip.y
markdown-pdf.clip.width
markdown-pdf.clip.height
- An object which specifies clipping region of the page
number
// x-coordinate of top-left corner of clip area "markdown-pdf.clip.x": 0,
// y-coordinate of top-left corner of clip area "markdown-pdf.clip.y": 0,
// width of clipping area "markdown-pdf.clip.width": 1000,
// height of clipping area "markdown-pdf.clip.height": 1000,
markdown-pdf.omitBackground
- Hides default white background and allows capturing screenshots with transparency
- boolean. Default: false
PlantUML options
markdown-pdf.plantumlOpenMarker
- Oppening delimiter used for the plantuml parser.
- Default: @startuml
markdown-pdf.plantumlCloseMarker
- Closing delimiter used for the plantuml parser.
- Default: @enduml
markdown-pdf.plantumlServer
- Plantuml server. e.g. http://localhost:8080
- Default: http://www.plantuml.com/plantuml
- For example, to run Plantuml Server locally #139 :
docker run -d -p 8080:8080 plantuml/plantuml-server:jetty- plantuml/plantuml-server — Docker Hub
markdown-it-include options
markdown-pdf.markdown-it-include.enable
- Enable markdown-it-include.
- boolean. Default: true
mermaid options
markdown-pdf.mermaidServer
- mermaid server
- Default: https://unpkg.com/mermaid/dist/mermaid.min.js
FAQ
How can I change emoji size ?
Add the following to your stylesheet which was specified in the markdown-pdf.styles
.emoji { height: 2em; }
Auto guess encoding of files
Using files.autoGuessEncoding option of the Visual Studio Code is useful because it automatically guesses the character code. See files.autoGuessEncoding
"files.autoGuessEncoding": true,
Output directory
If you always want to output to the relative path directory from the Markdown file.
For example, to output to the “output” directory in the same directory as the Markdown file, set it as follows.
"markdown-pdf.outputDirectory" : "output",
"markdown-pdf.outputDirectoryRelativePathFile": true,
Page Break
Please use the following to insert a page break.
<div class="page"/>
Known Issues
markdown-pdf.styles option
- Online CSS (https://xxx/xxx.css) is applied correctly for JPG and PNG, but problems occur with PDF. #67
Release Notes
1.4.4 (2020/03/19)
- Change: mermaid javascript reads from URL instead of from local file
- Add:
markdown-pdf.mermaidServeroption - add an option to disable mermaid #175
- Add:
markdown-pdf.plantumlServeroption - support configuration of plantUML server #139
- Add: configuration scope
- extend setting ‘headerTemplate’ with scope… #184
- Update: slug for markdown-it-named-headers
- Update: markdown.css, markdown-pdf.css
- Update: dependent packages
- Fix: Fix for issue #186 #187
- Fix: move the Meiryo font to the end of the font-family setting
- Meiryo font causing \ to show as ¥ #83
- Backslash false encoded #124
- Errors in which 한글(korean word) is not properly printed #148
- Fix: Improve the configuration schema of package.json
- Some settings can now be set from the settings editor.

NEXT
Ruby for Visual Studio Code
This extension provides enhanced Ruby language and debugging support for Visual Studio Code.
Features
- Automatic Ruby environment detection with support for rvm, rbenv, chruby, and asdf
- Lint support via RuboCop, Standard, and Reek
- Format support via RuboCop, Standard, Rufo, Prettier and RubyFMT
- Semantic code folding support
- Semantic highlighting support
- Basic Intellisense support
Installation
Search for ruby in the VS Code Extension Gallery and install it!
Initial Configuration
By default, the extension provides sensible defaults for developers to get a better experience using Ruby in Visual Studio Code. However, these defaults do not include settings to enable features like formatting or linting. Given how dynamic Ruby projects can be (are you using rvm, rbenv, chruby, or asdf? Are your gems globally installed or via bundler? etc), the extension requires additional configuration for additional features to be available.
Using the Language Server
It is highly recommended that you enable the Ruby language server (via the Use Language Server setting or ruby.useLanguageServer config option). The server does not default to enabled while it is under development but it provides a significantly better experience than the legacy extension functionality. See docs/language-server.md for more information on the language server.
Legacy functionality will most likely not receive additional improvements and will be fully removed when the extension hits v1.0
Example Initial Configuration:
"ruby.useBundler": true, //run non-lint commands with bundle exec
"ruby.useLanguageServer": true, // use the internal language server (see below)
"ruby.lint": {
"rubocop": {
"useBundler": true // enable rubocop via bundler
},
"reek": {
"useBundler": true // enable reek via bundler
}
},
"ruby.format": "rubocop" // use rubocop for formatting
Reviewing the linting, formatting, and environment detection docs is recommended
For full details on configuration options, please take a look at the Ruby section in the VS Code settings UI. Each option is associated with a name and description.
Debug Configuration
See docs/debugger.md.
Legacy Configuration
docs/legacy.md contains the documentation around the legacy functionality
Troubleshooting
Other Notable Extensions
- Ruby Solargraph — Solargraph is a language server that provides intellisense, code completion, and inline documentation for Ruby.
- VSCode Endwise — Wisely add “end” in Ruby

Comment Divider
This is Visual Studio Code extension, which provides commands for generating comment-wrapped separators from line content.
Supports all common languages.
Install
https://marketplace.visualstudio.com/items?itemName=stackbreak.comment-divider
Demo

Commands
Make main header
- Default Shortcut:
**Shift**+**Alt**+**X**- Default Style:
/* -------------------------------------------------------------------------- */ /* Example text */ /* -------------------------------------------------------------------------- */
Make subheader
- Default Shortcut:
**Alt**+**X**- Default Style:
/* ------------------------------ Example text ------------------------------ */
Insert solid line
- Default Shortcut:
**Alt**+**Y**- Default Style:
/* -------------------------------------------------------------------------- */
Language Support
Extension uses relevant comment characters for all common languages.
For example, in python files subheader looks like
# ------------------------------ python example ------------------------------ #
or in html files
<!-- ---------------------------- html example ----------------------------- -->
Also, you can easily add support for any missing language or override the default preset.
Default Configuration
Common
// Set line length for all dividers.
"comment-divider.length": 80,
Main Header
// "Set symbol for main header line filling (only one).
"comment-divider.mainHeaderFiller": "-",
// Set main header vertical style.
"comment-divider.mainHeaderHeight": "block",
// Set main header text align.
"comment-divider.mainHeaderAlign": "center",
// Set main header text transform style.
"comment-divider.mainHeaderTransform": "none",
Subheader
// "Set symbol for subheader line filling (only one).
"comment-divider.subheaderFiller": "-",
// Set subheader vertical style.
"comment-divider.subheaderHeight": "line",
// Set subheader text align.
"comment-divider.subheaderAlign": "center",
// Set subheader text transform style.
"comment-divider.subheaderTransform": "none",
Solid Line
// Set symbol for solid line filling.
"comment-divider.lineFiller": "-",
Languages Configuration
If some language is not supported out of the box, or you want to change default comment characters for an already supported language, it is possible to do it in the settings.
"comment-divider.languagesMap": {
"toml": ["#", "#"],
"scss": ["//"]
}
The item name is the language mode name and is associated with an array of 1 or 2 elements. The first element is the start of the line. The second, if defined, is the end.
The example above defines the right characters for toml and overrides scss defaults. As a result, the subheaders for these languages look like this:
# ------------------------------ toml subheader ------------------------------ #
// ----------------------------- scss subheader --------------------------------
Issues
Request features and report bugs using GitHub.

NEXT
Auto Import — ES6, TS, JSX, TSX (VSCode Extension)
Automatically finds, parses and provides code actions and code completion for all available imports. Works with JavaScript (ES6) and TypeScript (TS). Forker from old repo vscode-extension-auto-import

PostgreSQL for Visual Studio Code
Welcome to PostgreSQL for Visual Studio Code! An extension for developing PostgreSQL with functionalities including:
- Connect to PostgreSQL instances
- Manage connection profiles
- Connect to a different Postgres instance or database in each tab
- View object DDL with ‘Go to Definition’ and ‘Peek Definition’
- Write queries with IntelliSense
- Run queries and save results as JSON, csv, or Excel
Install link: https://marketplace.visualstudio.com/items?itemName=ms-ossdata.vscode-postgresql
Quickstart
- Open the Command Palette (Ctrl + Shift + P).
- Search and select ‘PostgreSQL: New Query’
- In the command palette, select ‘Create Connection Profile’. Follow the prompts to enter your Postgres instance’s hostname, database, username, and password.
You are now connected to your Postgres database. You can confirm this via the Status Bar (the ribbon at the bottom of the VS Code window). It will show your connected hostname, database, and user.
- You can type a query like ‘SELECT * FROM pgstatactivity’;
- Right-click, select ‘Execute Query’ and the results will show in a new window.
You can save the query results to JSON, csv or Excel.
Offline Installation
The extension will download and install a required PostgreSQL Tools Service package during activation. For machines with no Internet access, you can still use the extension by choosing the Install from VSIX... option in the Extension view and installing a bundled release from our Releases page. Each operating system has a .vsix file with the required service included. Pick the file for your OS, download and install to get started. We recommend you choose a full release and ignore any alpha or beta releases as these are our daily builds used in testing.
Support
Support for this extension is provided on our GitHub Issue Tracker. You can submit a bug report, a feature suggestion or participate in [discussions].

JS JSX Snippets
Supported languages (file extensions)
- JavaScript (.js)
- TypeScript (.ts)
- JavaScript React (.jsx)
- TypeScript React (.tsx)
Usage
After install this snippets add this inside your settings
"editor.snippetSuggestions": "top",
Snippets
Import and export
TriggerContentimpimport name from 'module';imdimport { } from 'module';
Import package
TriggerContentDescriptionimrimport React from 'react';useful in testiptimport PropTypes from 'prop-types';
Basic methods
TriggerContentcomComment Blockclgconsole.log()
React components
Only contain class component and function component.
TriggerContentrccclass component skeletonrccpclass component skeleton with prop types after the classrfcfunction component skeletonrfcpfunction component with prop types skeletonconclass default constructor with propsestempty state objectcdmcomponentDidMount methodscushouldComponentUpdate methodcdupcomponentDidUpdate methodcwuncomponentWillUnmount methodgsbugetSnapshotBeforeUpdate methodgdsfpstatic getDerivedStateFromProps methodcdccomponentDidCatch methodsstthis.setState with object as parameterssfthis.setState with function as parameterpropsthis.propsstatethis.statebndbinds the this of method inside the constructoruseStateuseState blockuseEffectuseEffect blockuseContextuseContext block
Jest
TriggerContentdescribedescribe Blocktesttest Blockitit Block
PropTypes
TriggerContentptaPropTypes.array,ptarPropTypes.array.isRequired,ptoPropTypes.object.,ptorPropTypes.object.isRequired,ptbPropTypes.bool,ptbrPropTypes.bool.isRequired,ptfPropTypes.func,ptfrPropTypes.func.isRequired,ptnPropTypes.number,ptnrPropTypes.number.isRequired,ptsPropTypes.string,ptsrPropTypes.string.isRequired,ptndPropTypes.node,ptndrPropTypes.node.isRequired,ptelPropTypes.element,ptelrPropTypes.element.isRequired,ptiPropTypes.instanceOf(ClassName),ptirPropTypes.instanceOf(ClassName).isRequired,ptePropTypes.oneOf(['News', 'Photos']),pterPropTypes.oneOf(['News', 'Photos']).isRequired,ptetPropTypes.oneOfType([PropTypes.string, PropTypes.number]),ptetrPropTypes.oneOfType([PropTypes.string, PropTypes.number]).isRequired,ptaoPropTypes.arrayOf(PropTypes.number),ptaorPropTypes.arrayOf(PropTypes.number).isRequired,ptooPropTypes.objectOf(PropTypes.number),ptoorPropTypes.objectOf(PropTypes.number).isRequired,ptshPropTypes.shape({color: PropTypes.string, fontSize: PropTypes.number}),ptshrPropTypes.shape({color: PropTypes.string, fontSize: PropTypes.number}).isRequired,

NEXT
Indent-Rainbow
A simple extension to make indentation more readable
If you like this plugin, please consider a small donation:

This extension colorizes the indentation in front of your text alternating four different colors on each step. Some may find it helpful in writing code for Nim or Python.

Get it here: Visual Studio Code Marketplace
It uses the current editor window tab size and can handle mixed tab + spaces but that is not recommended. In addition it visibly marks lines where the indentation is not a multiple of the tab size. This should help to find problems with indentation in some situations.
Configuration
Although you can just use it as it is there is the possibility to configure some aspects of the extension:
// For which languages indent-rainbow should be activated (if empty it means all).
"indentRainbow.includedLanguages": [] // for example ["nim", "nims", "python"]
// For which languages indent-rainbow should be deactivated (if empty it means none).
"indentRainbow.excludedLanguages": ["plaintext"]
// The delay in ms until the editor gets updated.
"indentRainbow.updateDelay": 100 // 10 makes it super fast but may cost more resources
Notice: Defining both _includedLanguages_ and _excludedLanguages_ does not make much sense. Use one of both!
You can configure your own colors by adding and tampering with the following code:
// Defining custom colors instead of default "Rainbow" for dark backgrounds.
// (Sorry: Changing them needs an editor restart for now!)
"indentRainbow.colors": [
"rgba(255,255,64,0.07)",
"rgba(127,255,127,0.07)",
"rgba(255,127,255,0.07)",
"rgba(79,236,236,0.07)"
]
// The indent color if the number of spaces is not a multiple of "tabSize".
"indentRainbow.errorColor": "rgba(128,32,32,0.6)"
// The indent color when there is a mix between spaces and tabs.
// To be disabled this coloring set this to an empty string.
"indentRainbow.tabmixColor": "rgba(128,32,96,0.6)"
Notice:
_errorColor_was renamed from_error_color_in earlier versions.
Skip error highlighting for RegEx patterns. For example, you may want to turn off the indent errors for JSDoc’s valid additional space (disabled by default), or comment lines beginning with //
// Example of regular expression in JSON (note double backslash to escape characters)
"indentRainbow.ignoreLinePatterns" : [
"/[ \t]* [*]/g", // lines begining with <whitespace><space>*
"/[ \t]+[/]{2}/g" // lines begininning with <whitespace>//
]
Skip error highlighting for some or all languages. For example, you may want to turn off the indent errors for markdown and haskell (which is the default)
"indentRainbow.ignoreErrorLanguages" : [
"markdown",
"haskell"
]
If error color is disabled, indent colors will be rendered until the length of rendered characters (white spaces, tabs, and other ones) is divisible by tabsize. Turn on this option to render white spaces and tabs only.
"indentRainbow.colorOnWhiteSpaceOnly": true // false is the default
Build with:
npm install
npm run vscode:prepublish
Running npm run compile makes the compiler recompile on file change.

NEXT
Path Intellisense
Visual Studio Code plugin that autocompletes filenames.
Sponsors

Eliminate context switching and costly distractions. Create and merge PRs and perform code reviews from inside your IDE while using jump-to-definition, your favorite keybindings, and other IDE tools.
Learn more
Installation
In the command palette (cmd-shift-p) select Install Extension and choose Path Intellisense.
To use Path Intellisense instead of the default autocompletion, the following configuration option must be added to your settings:
{ "typescript.suggest.paths": false }
Usage

Node packages intellisense
Use npm intellisense
BaseUrl
Pathintellisense uses the ts.config.compilerOptions.baseUrl as a mapping. So no need to define it twice. There is no support for paths at the moment.
For example:
{
"baseUrl": "src",
}
would allow to type:
{
import {} from "src/mymodule";
}
Settings
File extension in import statements
Path Intellisense removes the file extension by default if the statement is a import statement. To enable file extensions set the following setting to true:
{
"path-intellisense.extensionOnImport": true,
}
Show hidden files
Per default, hidden files are not displayed. Set this to true to show hidden files.
{
"path-intellisense.showHiddenFiles": true,
}
If set to false, PathIntellisense ignores the default “files.exclude” as well:
{
"files.exclude": {
"**/*.map.js": true
}
}
Auto slash when navigating to folder
Per default, the autocompletion does not add a slash after a directory.
{
"path-intellisense.autoSlashAfterDirectory": false,
}
Absolute paths
Per default, absolute paths are resolved within the current workspace root path. Set it to false to resolve absolute paths to the disk root path.
{
"path-intellisense.absolutePathToWorkspace": true,
}
Mappings
Define custom mappings which can be useful for using absolute paths or in combination with webpack resolve options.
{
"path-intellisense.mappings": {
"/": "${workspaceFolder}",
"lib": "${workspaceFolder}/lib",
"global": "/Users/dummy/globalLibs"
},
}
Use ${workspaceFolder} when the path should be relative to the current root of the current project. V2.2.1 and lower used ${workspaceRoot}. Newer version support both placeholders.

turbo-js
Turbo-js for vscode is forked from atom-turbo-javascript
Declarations
l=⇥ let assignment
let ${1:name} = ${2:value}
co⇥ const statement
const ${1:name}
co=⇥ const assignment
const ${1:name} = ${2:value}
Flow Control
if⇥ if statement
if (${1:condition}) {
${0}
}
ife⇥ else statement
if (${1:condition}) {
${0}
} else {
}
fo⇥ for of loop (ES6)
for (let ${1:key} of ${2:source}) {
${0}
}
wl⇥ while loop
while (${1:condition}) {
${0}
}
tc⇥ try/catch
try {
${0}
} catch (${1:err}) {
}
Functions
fn⇥ named function
function ${1:name}(${2:arguments}) {
${0}
}
iife⇥ immediately-invoked function expression (IIFE)
(function (${1:arguments}) {
${0}
})(${2});
af⇥ arrow function (ES6)
(${1:arguments}) => ${2:statement}
afb⇥ arrow function with body (ES6)
(${1:arguments}) => {
\t${0}
}
Iterables
fe⇥ forEach loop (chainable)
${1:iterable}.forEach((${2:item}) => {
${0}
});
reduce⇥ reduce function (chainable)
${1:iterable}.reduce((${2:previous}, ${3:current}) => {
${0}
}${4:, initial});
filter⇥ filter function (chainable)
${1:iterable}.filter((${2:item}) => {
${0}
});
find⇥ ES6 find function (chainable)
${1:iterable}.find((${2:item}) => {
${0}
});
Objects and classes
cls⇥ class (ES6)
class ${1:name} {
constructor(${2:arguments}) {
${0}
}
}
cex⇥ child class (ES6)
class ${1:name} extends ${2:base} {
constructor(${2:arguments}) {
super(${2:arguments});
${0}
}
}
med⇥ method (ES6 syntax)
${1:method}(${2:arguments}) {
${0}
}
get⇥ getter (ES6 syntax)
get ${1:property}() {
${0}
}
set⇥ setter (ES6 syntax)
set ${1:property}(${2:value}) {
${0}
}
proto⇥ prototype method (chainable)
${1:Class}.prototype.${2:methodName} = function (${3:arguments}) {
${0}
};
oa⇥ Object assign
Object.assign(${1:dest}, ${2:source})
ok⇥ Object.keys
Object.keys(${1:obj})
Promises
rp⇥ return Promise (ES6)
return new Promise((resolve, reject) => {
${0}
});
ES6 modules
ex⇥ module export
export ${1:member};
exd⇥ module default export
export default ${1:member};
im⇥ module import
import ${1:*} from '${2:module}';
ima⇥ module import as
import ${1:*} as ${2:name} from '${3:module}';
Console
cl⇥ console.log
console.log(${0});
ce⇥ console.error
console.error(${0});
cw⇥ console.warn
console.warn(${0});
Timers
st⇥ setTimeout
setTimeout(() => {
${0}
}, ${1:delay});
si⇥ setInterval
setInterval(() => {
${0}
}, ${1:delay});
sim⇥ setImmediate
setImmediate(() => {
${0}
});
Node.js specifics
re⇥ require a module
require('${1:module}');
cre⇥ require a module
const ${1:name} = require('${2:module}');
me⇥ module.exports
module.exports = ${1:name};
Miscellaneous
us⇥ use strict
'use strict';
vscode-standardjs-snippets
Optinionated set of JS snippets. Originally forked from https://github.com/gaboesquivel/atom-standardjs-snippets, but we’ve added couple more. Also these are not using special characters because vscode doesn’t accept them in the snippets.
Standard JavaScript Snippets for Visual studio code
A collection of javascript and react snippets for faster JavaScript development in Visual studio Code.
This collection is complementary to atom/language-javascript. It’s based on extrabacon/atom-turbo-javascript.
Code style
Yes!, no semicolons:
- Are Semicolons Necessary in JavaScript?
- An Open Letter to JavaScript Leaders Regarding Semicolons
- JavaScript Semicolon Insertion — Everything You Need to Know
Snippets
Snippets are optimized to be short and easy to remember. Shortest are the ones you should be using most often. Note that these links work only on github, not on VSCode marketplace:
- declarations
- flow control
- functions
- iterables
- objects and classes
- returning values
- types
- promises
- ES6 modules
- testing
- console
- timers
- DOM
- Node.js
- miscellaneous
Declarations
v⇥ var statement
var ${1:name}
va⇥ var assignment
var ${1:name} = ${2:value}
l⇥ let statement
let ${1:name}
la⇥ let assignment awaited
let ${1:name} = await ${2:value}
ly⇥ let yielded assignment
let ${1:name} = yield ${2:value}
c⇥ const statement
const ${1:name}
cd⇥ const from destructuring
const { ${1:name} } = ${2:value}
ca⇥ const assignment awaited
const ${1:name} = await ${2:value}
cd⇥ const from destructuring awaited
const { ${1:name} } = await ${2:value}
cf⇥ const arrow function assignment
const ${1:name} = (${2:arguments}) => {\n\treturn ${0}\n}
cy⇥ const yielded assignment
const ${1:name} = yield ${2:value}
Flow Control
i⇥ if statement
if (${1:condition}) {
${0}
}
te⇥ ternary statement
${1:cond} ? ${2:true} : ${3: false}
ta⇥ ternary statement
const ${0} = ${1:cond} ? ${2:true} : ${3: false}
el⇥ else statement
else {
${0}
}
ife⇥ else statement
if (${1:condition}) {
${0}
} else {
}
ei⇥ else if statement
else if (${1:condition}) {
${0}
}
fl⇥ for loop (ES6)
for (let ${1:i} = 0, ${2:len} = ${3:iterable}.length ${1:i} < ${2:len}; ${1:i}++) {
${0}
}
fi⇥ for in loop (ES6)
for (let ${1:key} in ${2:source}) {
if (${2:source}.hasOwnProperty(${1:key})) {
${0}
}
}
fo⇥ for of loop (ES6)
for (const ${1:key} of ${2:source}) {
${0}
}
wl⇥ while loop
while (${1:condition}) {
${0}
}
wid⇥ while iteration decrementing
let ${1:array}Index = ${1:array}.length
while (${1:array}Index--) {
${0}
}
tc⇥ try/catch
try {
${0}
} catch (${1:err}) {
}
tf⇥ try/finally
try {
${0}
} finally {
}
tcf⇥ try/catch/finally
try {
${0}
} catch (${1:err}) {
} finally {
}
Functions
fan⇥ anonymous function
function (${1:arguments}) {${0}}
fn⇥ named function
function ${1:name}(${2:arguments}) {
${0}
}
asf⇥ async function
async function (${1:arguments}) {
${0}
}
aa⇥ async arrow function with
async (${1:arguments}) => {
${0}
}
iife⇥ immediately-invoked function expression (IIFE)
;(function (${1:arguments}) {
${0}
})(${2})
aiife⇥ async immediately-invoked function expression
;(async (${1:arguments}) => {
${0}
})(${2})
fa⇥ function apply
${1:fn}.apply(${2:this}, ${3:arguments})
fc⇥ function call
${1:fn}.call(${2:this}, ${3:arguments})
fb⇥ function bind
${1:fn}.bind(${2:this}, ${3:arguments})
af⇥ arrow function (ES6)
(${1:arguments}) => ${2:statement}
fd⇥ arrow function with destructuring
({${1:arguments}}) => ${2:statement}
fdr⇥ arrow function with destructuring returning destructured
({${1:arguments}}) => ${1:arguments}
f⇥ arrow function with body (ES6)
(${1:arguments}) => {
${0}
}
fr⇥ arrow function with return (ES6)
(${1:arguments}) => {
return ${0}
}
gf⇥ generator function (ES6)
function* (${1:arguments}) {
${0}
}
gfn⇥ named generator function (ES6)
function* ${1:name}(${1:arguments}) {
${0}
}
Iterables
fe⇥ forEach loop
${1:iterable}.forEach((${2:item}) => {
${0}
})
map⇥ map function
${1:iterable}.map((${2:item}) => {
${0}
})
reduce⇥ reduce function
${1:iterable}.reduce((${2:previous}, ${3:current}) => {
${0}
}${4:, initial})
filter⇥ filter function
${1:iterable}.filter((${2:item}) => {
${0}
})
find⇥ ES6 find function
${1:iterable}.find((${2:item}) => {
${0}
})
every⇥ every function
${1:iterable}.every((${2:item}) => {
${0}
})
some⇥ some function
${1:iterable}.some((${2:item}) => {
${0}
})
Objects and classes
cs⇥ class (ES6)
class ${1:name} {
constructor(${2:arguments}) {
${0}
}
}
csx⇥ extend a class (ES6)
class ${1:name} extends ${2:base} {
constructor(${2:arguments}) {
super(${2:arguments})
${0}
}
}
m⇥ method (ES6 syntax)
${1:method} (${2:arguments}) {
${0}
}
get⇥ getter (ES6 syntax)
get ${1:property} () {
${0}
}
set⇥ setter (ES6 syntax)
set ${1:property} (${2:value}) {
${0}
}
gs⇥ getter and setter (ES6 syntax)
get ${1:property} () {
${0}
}
set ${1:property} (${2:value}) {
}
proto⇥ prototype method
${1:Class}.prototype.${2:methodName} = function (${3:arguments}) {
${0}
}
ok Object.keys
Object.keys(${1:obj})
ov Object.values
Object.values(${1:obj})
oe Object.entries
Object.entries(${1:obj})
oc Object.create
Object.create(${1:obj})
oa Object.assign
Object.assign(${1:dest}, ${2:source})
og Object.getOwnPropertyDescriptor
Object.getOwnPropertyDescriptor(${1:dest}, '${2:prop}')
od Object.defineProperty
Object.defineProperty(${1:dest}, '${2:prop}', {
${0}
})
Returning values
r⇥ return
return ${0}
rt⇥ return this
return this
rn⇥ return null
return null
ro⇥ return new object
return {
${0}
}
ra⇥ return new array
return [
${0}
]
rp⇥ return Promise (ES6)
return new Promise((resolve, reject) => {
${0}
})
tof⇥ typeof comparison
typeof ${1:source} === '${2:undefined}'
tf⇥ this
this.
iof⇥ instanceof comparison
${1:source} instanceof ${2:Object}
ia⇥ isArray
Array.isArray(${1:source})
Promises
pa⇥ Promise.all
Promise.all(${1:value})
p⇥ new Promise (ES6)
new Promise((resolve, reject) => {
${0}
})
pt⇥ Promise.then
${1:promise}.then((${2:value}) => {
${0}
})
pc⇥ Promise.catch
${1:promise}.catch(error => {
${0}
})
ES6 modules
e⇥ module export
export ${1:member}
ed⇥ module default export
export default ${1:member}
edf⇥ module default export function
export default function ${1:name} (${2:arguments}) {\n\t${0}\n}
ec⇥ module export const
export const ${1:member} = ${2:value}
ef⇥ module export const
export function ${1:member} (${2:arguments}) {\n\t${0}\n}
im⇥ module import
import ${1:*} from '${2:module}'
ia⇥ module import as
import ${1:*} as ${2:name} from '${3:module}'
id⇥ module import destructuring
import { $1 } from '${2:module}'
BDD testing (Mocha, Jasmine, etc.)
desc⇥ describe
describe('${1:description}', function () {
${0}
})
it⇥ asynchronous “it”
it('${1:description}', async () => {
${0}
})
itd⇥ “it” with callback
it('${1:description}', (done) => {
${0}
})
its⇥ “it” synchronous
it('${1:description}', () => {
${0}
})
bf⇥ before test suite
before(function () {
${0}
})
bfe⇥ before each test
beforeEach(function () {
${0}
})
aft⇥ after test suite
after(function () {
${0}
})
afe⇥ after each test
afterEach(function () {
${0}
})
Timers
st⇥ setTimeout
setTimeout(() => {
${0}
}, ${1:delay})
si⇥ setInterval
setTimeout(() => {
${0}
}, ${1:delay})
sim⇥ setImmediate
setImmediate(() => {
${0}
})
DOM
ae⇥ addEventListener
${1:document}.addEventListener('${2:event}', ${3:ev} => {
${0}
})
rel⇥ removeEventListener
${1:document}.removeEventListener('${2:event}', ${3:listener})
evc dom event cancel default and propagation
ev.preventDefault()
ev.stopPropagation()
return false
gi⇥ getElementById
${1:document}.getElementById('${2:id}')
gc⇥ getElementsByClassName
Array.from(${1:document}.getElementsByClassName('${2:class}'))
gt⇥ getElementsByTagName
Array.from(${1:document}.getElementsByTagName('${2:tag}'))
qs⇥ querySelector
${1:document}.querySelector('${2:selector}')
qsa⇥ querySelectorAll
Array.from(${1:document}.querySelectorAll('${2:selector}'))
cdf⇥ createDocumentFragment
${1:document}.createDocumentFragment(${2:elem});
cel⇥ createElement
${1:document}.createElement(${2:elem});
heac⇥ appendChild
${1:document}.appendChild(${2:elem});
herc⇥ removeChild
${1:document}.removeChild(${2:elem});
hecla⇥ classList.add
${1:document}.classList.add('${2:class}');
hect⇥ classList.toggle
${1:document}.classList.toggle('${2:class}');
heclr⇥ classList.remove
${1:document}.classList.remove('${2:class}');
hega⇥ getAttribute
${1:document}.getAttribute('${2:attr}');
hesa⇥ setAttribute
${1:document}.setAttribute('${2:attr}', ${3:value});
hera⇥ removeAttribute
${1:document}.removeAttribute('${2:attr}');
Node.js
cb⇥ Node.js style callback
function (err, ${1:value}) {
if (err) throw err
t${0}
}
rq⇥ require a module
require('${1:module}')
cr⇥ require and assign a module
const ${1:module} = require('${1:module}')
em⇥ export member
exports.${1:name} = ${2:value}
me⇥ module.exports
module.exports = ${1:name}
on⇥ attach an event handler
${1:emitter}.on('${2:event}', (${3:arguments}) => {
${0}
})
Miscellaneous
uss⇥ use strict
'use strict'
js⇥ JSON Stringify
JSON.stringify($0)
jp⇥ JSON Parse
JSON.parse($0)
a⇥ await
await ${0}
apa⇥ Promise.all
await Promise.all(${1:value})
apm⇥ Promise.all map
await Promise.all(${1:array}.map((async ${2:value}) => {\n\t${0}\n}))
ast⇥ Promise sleep
await new Promise((r) => setTimeout(r, ${0}))
Console
cl⇥ console.log
console.log(${0})
cv⇥ console.log
console.log('${0}:', ${0})
ce⇥ console.error
console.error(${0})
cw⇥ console.warn
console.warn(${0})
cod⇥ console.dir
console.dir(${0})
React snippets
Are only enabled in jsx or tsx files. If you write your jsx in js files, you need to copy the react.json files manually and add it to your custom snippets.
Why do we include them here?
If you’re not writing react, including them should not really bother you because they are not short as the regular JS snippets. Also IMHO react is the leading solution for FE apps deserves to be included by default, because any JS dev will have to write some react eventually over the course of his/her careeer. By having them in a single package we can easily make sure -there aren’t any conflicts in the trigger prefixes.
Supported languages (file extensions)
- JavaScript (.js)
- TypeScript (.ts)
- JavaScript React (.jsx)
- TypeScript React (.tsx)
These were originally taken from https://github.com/TimonVS/vscode-react-standard because the maintainer wasn’t able to publish a new version for months even when there was a considerable flaw in the released version. Below is a list of all available snippets and the triggers of each one.
TriggerContentjjsx elementdpdestructuring of propsdsdestructuring of propsjcjsx self-closed elementjmjsx elements mapjmrjsx elements map with returnrfcfunctional component. Prefer for 99% of new react componentrfcefunctional component with emotion css importrccclass component skeletonrccpclass component skeleton with prop types after the classrcjcclass component skeleton without import and default export linesrcfcclass component skeleton that contains all the lifecycle methodsrfcpstateless component with prop types skeletonrptempty propTypes declarationconclass default constructor with propsconcclass default constructor with props and contextestempty state objectcwmcomponentWillMount methodcdmcomponentDidMount methodcwrcomponentWillReceiveProps methodcgdcomponentGetDerivedStateFromProps methodscushouldComponentUpdate methodcwupcomponentWillUpdate methodcdupcomponentDidUpdate methodcwuncomponentWillUnmount methodrenrender methodsstthis.setState with object as parameterssfthis.setState with function as parametertpthis.propststhis.stateususeStateueuseEffectuecuseEffect with a cleanup functionuruseRefcccreateContextucuseContextumeuseMemo——-—————————————————————-uquseQuery to be used with graphql-codegenuqcuseQuery that loads up data for current component, to be used with graphql-codegenumuseMutation to be used with graphql-codegenuqguseQuery with raw gqlumguseMutation with raw gql
There are also snippets to be triggered with a text selection(trigger via insert snippet command):
jsx element wrap selection
The following table lists all the snippets that can be used for prop types. Every snippet regarding prop types begins with pt so it’s easy to group it all together and explore all the available options. On top of that each prop type snippets has one equivalent when we need to declare that this property is also required. For example pta creates the PropTypes.array and ptar creates the PropTypes.array.isRequired
TriggerContentptaPropTypes.array,ptarPropTypes.array.isRequired,ptbPropTypes.bool,ptbrPropTypes.bool.isRequired,ptfPropTypes.func,ptfrPropTypes.func.isRequired,ptnPropTypes.number,ptnrPropTypes.number.isRequired,ptoPropTypes.object.,ptorPropTypes.object.isRequired,ptsPropTypes.string,ptsrPropTypes.string.isRequired,ptndPropTypes.node,ptndrPropTypes.node.isRequired,ptelPropTypes.element,ptelrPropTypes.element.isRequired,ptiPropTypes.instanceOf(ClassName),ptirPropTypes.instanceOf(ClassName).isRequired,ptePropTypes.oneOf(['News', 'Photos']),pterPropTypes.oneOf(['News', 'Photos']).isRequired,ptetPropTypes.oneOfType([PropTypes.string, PropTypes.number]),ptetrPropTypes.oneOfType([PropTypes.string, PropTypes.number]).isRequired,ptaoPropTypes.arrayOf(PropTypes.number),ptaorPropTypes.arrayOf(PropTypes.number).isRequired,ptooPropTypes.objectOf(PropTypes.number),ptoorPropTypes.objectOf(PropTypes.number).isRequired,ptshPropTypes.shape({color: PropTypes.string, fontSize: PropTypes.number}),ptshrPropTypes.shape({color: PropTypes.string, fontSize: PropTypes.number}).isRequired,

C/C++ for Visual Studio Code
Repository | Issues | Documentation | Code Samples | Offline Installers
The C/C++ extension adds language support for C/C++ to Visual Studio Code, including features such as IntelliSense and debugging.
Overview and tutorials
C/C++ extension tutorials per compiler and platform * Microsoft C++ compiler (MSVC) on Windows * GCC and Mingw-w64 on Windows * GCC on Windows Subsystem for Linux (WSL) * GCC on Linux * Clang on macOS
Quick links
- Editing features (IntelliSense)
- IntelliSense configuration
- Enhanced colorization
- Debugging
- Debug configuration
- Enable logging for IntelliSense or debugging
Questions and feedback
FAQs
Check out the FAQs before filing a question.
Provide feedback
File questions, issues, or feature requests for the extension.
Known issues
If someone has already filed an issue that encompasses your feedback, please leave a  or
or  reaction on the issue to upvote or downvote it to help us prioritize the issue.
reaction on the issue to upvote or downvote it to help us prioritize the issue.
Quick survey
Let us know what you think of the extension by taking the quick survey.
Offline installation
The extension has platform-specific binary dependencies, therefore installation via the Marketplace requires an Internet connection in order to download additional dependencies. If you are working on a computer that does not have access to the Internet or is behind a strict firewall, you may need to use our platform-specific packages and install them by running VS Code’s "Install from VSIX..." command. These “offline’ packages are available at: https://github.com/Microsoft/vscode-cpptools/releases.
PackagePlatformcpptools-linux.vsixLinux 64-bitcpptools-linux-armhf.vsixLinux ARM 32-bitcpptools-linux-aarch64.vsixLinux ARM 64-bitcpptools-osx.vsixmacOScpptools-win32.vsixWindows 64-bit & 32-bitcpptools-win-arm64.vsixWindows ARM64cpptools-linux32.vsixLinux 32-bit (available up to version 0.27.0)
Contribution
Contributions are always welcome. Please see our contributing guide for more details.
Microsoft Open Source Code of Conduct
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
Data and telemetry
This extension collects usage data and sends it to Microsoft to help improve our products and services. Collection of telemetry is controlled via the same setting provided by Visual Studio Code: "telemetry.enableTelemetry". Read our privacy statement to learn more.

NEXT
Visual Studio IntelliCode
The Visual Studio IntelliCode extension provides AI-assisted development features for Python, TypeScript/JavaScript and Java developers in Visual Studio Code, with insights based on understanding your code context combined with machine learning.
You’ll need Visual Studio Code October 2018 Release 1.29.1 or later to use this extension. For each supported language, please refer to the “Getting Started” section below to understand any other pre-requisites you’ll need to install and configure to get IntelliCode completions.
For C#, C++, TypeScript/JavaScript, and XAML support in the Visual Studio IDE, check out the IntelliCode extension on the Visual Studio Marketplace.
About IntelliCode
This extension provides AI-assisted IntelliSense by showing recommended completion items for your code context at the top of the completions list. The example below shows this in action for Python code.

When it comes to overloads, rather than taking the time to cycle through the alphabetical list of member, IntelliCode presents the most relevant one first. In the example shown above, you can see that the predicted APIs that IntelliCode elevates appear in a new section of the list at the top with members prefixed by a star icon. Similarly, a member’s signature or overloads shown in the IntelliSense tool-tip will have additional text marked by a small star icon and wording to explain the recommended status. This visual experience for members in the list and the tool-tip that IntelliCode provides is not intended as final — it is intended to provide you with a visual differentiation for feedback purposes only.
Contextual recommendations are based on practices developed in thousands of high quality, open-source projects on GitHub each with high star ratings. This means you get context-aware code completions, tool-tips, and signature help rather than alphabetical or most-recently-used lists. By predicting the most likely member in the list based on your coding context, AI-assisted IntelliSense stops you having to hunt through the list yourself.
Getting Started
Install the Visual Studio IntelliCode extension by clicking the install link on this page, or install from the Extensions tab in Visual Studio Code. Then follow the language-specific instructions below.
For TypeScript/JavaScript users:
That’s it — just open a TypeScript or JavaScript file, and start editing.
For Python users:
- Set up the Python extension by following the steps in the Python tutorial
- Start editing Python files, you should get a prompt to enable the Microsoft Python Language Server, which itself is a preview release.
- Reload Visual Studio Code after enabling the language server
- After the language server finishes initializing, you should now see recommended completions
For Java users:
- Set up the Java extension for Visual Studio Code by following the steps in the Java Tutorial
- Make sure that you have a minimum of Java 8 Update 151 installed
- Reload Visual Studio Code after enabling the Java extension
- After the Java language server finishes initializing, you should now see recommended completions
If you found this guide helpful feel free to checkout my github/gists where I host similar content:
A condensed summary of the entire “JavaScript the Good Parts” book
I hope these notes help shed some light and save some time… (this is the most I could condense an entire book)

Chapter 1 — Good Parts
Most programming languages contain good parts and bad parts. I discovered that I could be a better programmer by using only the good parts and avoiding the bad parts. After all, how can you build something good out of bad parts?
The best parts of Javascript include:
- functions
- loose typing (variables are declared as variables, without a type)
- dynamic objects
- object literal notation (where you can create an object already with a list of key/value pairs inside curly braces)
The worst parts include global variables — there is a common global object namespace where they’re all lumped together and they’re essential to the language.
Javascript has a class free object makeup, relying instead on objects inheriting properties directly from other objects — this is prototypal inheritance.
Chapter 2 — Grammar
Always use // for comments, even multi-line ones to avoid having to escape /* characters.
Numbers
- There is a single, 64-bit floating point number type.
NaN(Not-a-Number) is not equal to any value (including itself) and is essentially an illegal number value, but typeOf(NaN)===number is true- Use
isNaN(number)to check for NaNs
Number methods are discussed in Chapter 8.
Strings
- 16-bit character set and don’t have character types.
- Backslashes (\) are used for escaping characters that could cause problems in strings.
- Strings are immutable.
Single quotes are often used to define a String in JavaScript, but if a person’s name has an apostrophe (and the developer does not know the difference between an apostrophe and single quote) it is useful to “escape” the apostrophe character:
var name = 'Patrick O\'Brian'; // using a backslash in front of the apostrophe
console.log('name:', name); // name: Patrick O'Brian
further reading: https://webdesignledger.com/common-typography-mistakes-apostrophes-versus-quotation-marks

String methods are discussed in Chapter 8.
Statements
- Inside a function, the var statement creates variables local to that function
- switch, while, for and do statements can have an optional label which can be used with
breakandcontinueto provide more precise control over exactly which statement to break or continue. Format:labelname: statementand thencontinue labelname; - ES2015 presents two new keywords for declaring variables, let and const. Whereas the var keyword is function scoped (the variables are local to the function), let and const are both block scoped, which means they are local to any statement with {}.
- falsy values:
- false
- null
- undefined
- Empty string ‘ ‘
- The number 0
- The number NaN
- All other values are truthy including all objects & the string ‘false’
- If no matches are found in
casestatements, the optional default statement is executed, otherwise the matching case statement is carried out - When using a for in loop, usually a good idea to use
hasOwnProperty(variable)to make sure the property belongs to the object you want and is not instead an inherited property from the prototype chain:
for (myvariable in object) {
if (object.hasOwnProperty(myvariable)) {
//....statements to be executed
}
}
- A do while statement is always executed at least once as the while condition is only checked after the first iteration of the loop
catchclause in a try statement must create a new variable that will catch the exception object- Scope of
throwstatement is thetryblock it’s in, or thetryof the function it’s in - If there is no
returnstatement,return===undefined breakexits the statement andcontinueforces a new iteration of the loop, both with the optional label mentioned above
Expressions
- For
expression ? expression2 : expression3, if expression is truthy, execute expresion2; if it’s falsy, execute expression3 - Invocation is
(expression1, expression2, etc) - refinement is either
.nameor[expression]as used in an array
Literals
- Names or strings used for specifying new objects (object literals) or arrays (array literals)
- Properties of the object are expressions and must be known at compile time
Functions
- A function literal defines a function value
- More details in Chapter 4
Chapter 3 — Objects
Javascript simple types:
- numbers (has object-like methods but they are immutable)
- strings (has object-like methods but they are immutable)
- booleans (has object-like methods but they are immutable)
- null
- undefined
All other values are objects including arrays and functions.
Objects are class free, can contain other objects and can inherit properties from their prototypes (which can reduce object initialisation time and memory consumption).
Object Literals
- An object literal is zero or more comma-separated name/value pairs surrounded by curly braces {}
var empty_object = {};
var today = {
day: "Wednesday",
month: "April",
year: 2014,
weather: { //objects can contain nested objects like this one
morning: "sunny",
afternoon: "cloudy"
}
}
Retrieval
- Can be done with either dot notation
today.weather.morningor with square bracketstoday['month'] - Or operand (||) can be used to fill in default values for nonexistent data to prevent and undefined error:
var weath = today.weather.evening || "unknown"
Update
- Assigning a property value to an object overwrites any existing property values with that property name
Reference
- Objects refer to each other, they don’t hold duplicate copies of data
Prototype
- Every object has a prototype object from which it inherits properties
- Object.prototype comes standard with Javascript and is almost like a ‘root parent’

- The
Object.createmethod is now available in ES5 (but the method is in the book if required for older versions) - If an object does not have a property you ask it for, it will keep looking up the prototype chain until it finds it
- If the property does note exist anywhere in the chain, it will return undefined
- A new property is immediately visible to all of the objects below it in the chain once created
More details in Chapter 6
Reflection
- Determining what properties an object has
- Using
typeofincludes all properties in the prototype chain including functions - To avoid inherited properties, use
hasOwnProperty(type);which returns true if that property exists only in that object itself (not the chain)
today.hasOwnProperty(‘number’) //will return true today.hasOwnProperty(‘constructor’) //will return false
Enumeration
- Best way to enumerate all the properties you want is a for loop:
let i;
var properties = [ ‘day’, ‘month’, ‘year’ ];
for (i = 0; i < properties.length; i++) {
document.writeIn(properties[i] + ‘:’ + today[properties[i]]);
}
- This ensures you get the properties you want (i.e. not up the prototype chain) and in the order you want, as opposed to a for in loop which achieves neither of these
Delete
- Removes property from object, but also reveals property from further up the prototype chain if it exists
- Format:
delete today.month
Global Abatement
- One way to mitigate the risks of global variables is to create a single global variable which then contains your whole application
let MYAPP = {}
MYAPP.today = {
day: "Wednesday",
month: "April",
year: 2014,
weather: { //objects can contain nested objects like this one
morning: "sunny",
afternoon: "cloudy"
}
}
//Making sure all other variables (like today) are contained within this one global variable (MYAPP) means none of them have global scope and therefore the risk of naming conflicts, etc in your application is reduced
- Closures are also a way of mitigating the risks of global variables
- Note: Most Javascript MVCs these days (2014) will take care of wrapping your app for you
Chapter 4 — Functions
The best thing about JavaScript is its implementation of functions.
Function Objects
- Functions are objects linked to function.prototype (which is linked to Object.prototype).
- As well as usual object behaviour, they can be invoked.
Function Literal
- A function literal has 4 parts:
- The (reserved) word
functionitself - An optional name (un-named functions are considered anonymous functions)
- Comma-seperated parameters of the function, in parentheses —
(parameters) - Set of statements in curly brackets to be carried out when the function is invoked —
{statements}
//Format of a function
function name (parameterA, parameterB){
statements;
}
- Functions can be nested within functions and the inner function can access all the parameters of the outer function as well as its own
Invocation
- Stops the current function from running and tells the function you have invoked both to start and to use the arguments (values in parentheses) you have passed it in the invocation
function (parameters) - If arguments > number of arguments expected, the extra values will be ignored
- If arguments < number of arguments expected, the function will assume undefined in place of the missing arguments
- No error is thrown
- Note: The difference between an argument and a parameter is that a parameter is usually what is used in the function literal, when you’re setting up the function (almost like the placeholder for the actual values that the function will use when it is active) and an argument is usually the value passed to a function at the time it is invoked
- Parameters
thisandargumentsare also passed to the function when it is invoked, but their value depends on how the function is invoked
Method Invocation Pattern
- When a function is stored as the property of the object (invoked with a dot . expression) it is called on and is called a method
myObject.incrementFunction();
- The method is bound to the object and therefore can use
thisto retrieve or update values from the object - These methods are highly reusable
- Because their object context comes from
thisthey are considered public methods
Function Invocation Pattern
- When a function is not the property of an object, it is invoked as a function
var sum = add(3, 4);
- These functions are bound to the global object (a “mistake in the design of the language” according to Douglas Crockford) and consequently so is
thiseven in inner functions - Invoking
thiswithin an inner function will therefore refer to its ownthisand not the one in global scope
Workaround: Artificially create a new this:
myObject.double = function() {
//in the book, the var here is called `that` but name changed for clarity
var globalScopeThis = this; //workaround
var innerFunc = function() {
globalScopeThis.value = add(globalScopeThis.value, globalScopeThis.value);
};
innerFunc(); //invoke innerFunc as function
};
myObject.double();
console.log(myObject.value);
Constructor Invocation Pattern
- When a function is created with
new, that function contains a link to the function’s prototype - This means that methods that were created for the prototype function are also available to the function created using
new
//create a function Quo that takes a string - Quo will be our prototype function as we will see
var Quo = function (string){
this.status = string;
}
//Now create a getstatus method for Quo - this will be a public method
Quo.prototype.getstatus = function () {
return this.status;
}
//create a new instance of Quo using the prefix NEW
var myQuo = new Quo("happy");
//because of the use of the new prefix, myQuo is an instance of Quo which means it can access the public method getstatus from it's prototype
document.writeIn(myQuo.getstatus()); //returns 'happy'
- This style of constructor pattern is not recommended, there will be better examples in Chapter 5 — this is noted again in Appendix B
- The first letter of a constructor function (in this case Quo) must always be capitalized
Apply Invocation Pattern
- The
applymethod lets you choose the value to be bound tothis - It also takes the parameters for a function in an array
- Format:
function.apply(valueForThis, arrayOfParamentersForFunction);
var array = [5, 2] //will be the parameters for our function
var sum = add.apply(null, array); //value of 'this' is null and value of sum is 7 as the 'apply' method passes 5 and 2 to the 'add' method
Arguments
- Another default parameter of functions is the
argumentsarray which contains all the arguments that were supplied when the function was invoked - This means you don’t have to know the exact number of arguments when you build a function because you can loop through all the arguments provided at invocation with the use of the default
argumentsarray
//inside the function for (i = 0; i < arguments.length; i++) { dosomething; //e.g. sum +=arguments[i] }
argumentslacks all the array methods except .length because of a bug
Return
- When a function gets to a
returnstatement, it returns immediately without carrying out the remaining statements in the function - A function always returns a
valueor if unspecified, it returnsundefined - “If the function was invoked with the
newprefix (used when creating a new object so it must return an object) and thereturnvalue is not an object, thenthis(the new object) is returned instead.”
Exceptions
- A
throwstatement interrupts the execution of the code is used to handle expected exceptions like an incorrect type of argument (e.g. a string where a number is expected) - Each
throwstatement should have an exception object with anameholding the type of exception and amessagewith an explanation of it + any other properties you like
//Thinking through what exceptions could happen in an add function, the main function contains the throw statement with the exception object
let add = function (a,b) {
if (typeof a !== ‘number’ || typeof b !== ‘number’){
throw {
name: ‘TypeError’;
message: ‘The add function requires numbers’;
}
}
return a + b;
}
- When you write a function to use add(), you include a
tryblock where the exception object from thethrowstatement in add() will pass control to a single catch clause for all exceptions
//When you use the function later on, add a try block with a catch clause to catch the exception object
var try_it = function () {
try{
add("seven"); //will throw an exception as it is not a number
}
catch (e) {
document.writeIn(e.name + ':' + e.message);
}
}
try_it(); //you could rewrite this function so the argument is passed in here where it is invoked
Augmenting Types
- Adding a method to the prototype of an object
Object.prototype(or function, array, string, number, regular expression or boolean), you make it available to all the instances of that object so you don’t have to use theprototypeproperty again - By augmenting the basic types (essentially the root prototypes), we can improve Javascript overall
- For example, adding a method named trim to remove spaces from the end of strings, available to all String instances in your code:
String.method (‘trim’, function () { return this.replace(/ˆ\s+|\s+$/g, ‘’); //uses regular expression });
- To be on the safe side, create a method conditionally, only when you know the method is missing
//Makes a method available to all functions, ONLY when it definitely does not already exist
Function.prototype.method (methodName, func) {
if (!this.prototype[methodName]){
this.prototype[methodName] = func;
return this;
}
};
- Remember that for in statements don’t work well with prototypes
Recursion
- Used when a task can be divided into simple sub-problems and a function can call itself repeatedly to solve them
- Takes the format:
var variable = function functionName (parameters){
//wrap the statements to be executed and the recursive call in a loop statement so it doesn't recurse forever
//statements to be executed in the function;
functionName(arguments);
};
functionName (initialArguments); //initial call to the function
- Javascript does not have tail recursion optimization and therefore does not optimize recursive functions — this also means they sometimes fail if they “recurse very deeply”; On a side note, tail call optimization is now supported in ECMA-262
Scope
- A block is a set of statements contained in curly brackets {}
- Javascript does not have block scope but does have function scope
- All variables declared anywhere within a function are available everywhere in that function — i.e. and inner function will have access to the variables of the outer function in which it is defined
- A variable can be overwritten with a new value in an inner function and that new value’s scope will be just the body of the inner function — as soon as you’re back out to the outer function, the value of that variable will revert to what it was before the inner function began its execution
- All variable should be declared at the top of the function body
Closure
- Inner functions have access to the actual parameters of the outer functions (not copies)
- If an object is created as a result of a function and assigned to myObject, myObject continues to share access to the variables in the functions that created it (actual variables, not copies)
- It has access to the context in which it was created — this is closure
- This includes later on, even if the outer function has completed its execution and returned, when the inner function is called, it will still have access to all the variables it had access to at the time it was defined (i.e. the variables that were in context when the inner function was defined)
Callbacks
- A callback function is a function passed to another function as a parameter and executed in this other function
- When making a request to a server, use an asynchronous request as asynchronous functions return immediately, therefore freeing up the client
- In this example, we pass the callback function to the asynchronous request as a parameter so the callback function will only be called when a response is available
request = preparetherequest();
sendrequestasynchronously(request, function(response){
//function being passed in as a parameter
display(response);
}
);
Module
- A module is a function or object whose contents can be used, but its state and implementation are hidden
- It is essentially using function scope and closures keep the variables and functions contained within as private as well as binding them to a non-global object — whilst still being accessible
- Using the module pattern is widely used and good practice as it promotes information hiding (avoiding naming conflicts, etc) and encapsulation
- This is a good article on how to use the module pattern with examples
- It can also be used to produce secure objects (see durable objects below)
- Methods contained in the object do not make use of
thisorthatso it becomes impossible to change them from outside of the object except in ways explicitly permitted by the methods (like passing them a parameter) - The methods can be replaced but the secrets of how these methods function (like how they generate a number for example) can’t be revealed because they are not tied to a global object
var Serial_maker = function() {
//all variables defined in this object are now fixed and hidden from anything outside this function
//see page 42 of book for full example
};
//calls to methods passing them parameters are made here
- Note: Whilst Javascript variables are usually lowercase, there is some convention around capitalizing the first letter of a Module
Cascade
- Some methods return nothing, albeit
undefined - If we alter these methods to return
thisinstead ofundefined, they return the object which can then be passed to the next method, e.ggetElement(myBox).move(350,150)gets the element and then passes is to the move function for the next action - This enables cascades, where you call many methods on the same object in sequence because the object is passed from one method to the next (usually separated by
.as above) - Cascades also stop you from trying to do too much in one method and makes your code more descriptive
Curry
- A
currymethod allows you to partially evaluate an existing function - An example is below where the function expects two arguments, but it is first invoked with only one (in this case using
curryas inadd.curry(10);) and then later passed the second argument - It can also be explained as transforming a function that takes multiple arguments (
add(a,b)) into a chain of functions that take a single argument each (addA = add(A); addA(B);where the two functions are nowadd()&addA())
//set up a simple function that we will customise with curry
var add = function (a,b){
return a + b;
}
var addTen = add.curry(10); //passes 10 as the first argument to the add() function
addTen(20); //The use of the curry method in addTen means addTen === add(10, 20);
- Javascript does not have a
currymethod natively but this can be added to theFunction.protoype:
Function.method('curry', function() {
var slice = Array.prototype.slice,
args = slice.apply(arguments),
that = this;
return function() {
return that.apply(null, args.concat(slice.apply(arguments)));
}
});
Memoization
- Storing the results of previous operations in objects (such as arrays) allows them to be reused without having to keep recalculating the value — this optimization is called memoization
- Adding an object to store the results memoizes the function
- Particularly useful when a function is recursive and uses the results of its previous iteration in the current iteration
- A memoizer function can be created to help memoize future functions:
var meoizer = function(memo, fundamental) {
var shell = function(n) {
var result = memo[n];
if (typeof result !== 'number') {
result = fundamental(shell, n);
memo[n] = result;
}
return result;
}
return shell;
}
Chapter 5 — Inheritance
Javascript is a prototypal language, which means that objects inherit directly from other objects
Main benefit of inheritance is code reuse — you only have to specify differences.
Javascript can mimic classical inheritance but has a much richer set of code reuse patterns
- This chapter looks at the more straightforward patterns but it is always best to keep it simple
Pseudoclassical
- The pseudoclassical code reuse pattern essentially has constructor functions (functions invoked using the
newprefix) work like classes to mimic the classical structure - All properties are public
- If you forget to use the
newprefix,thisis not bound to the new object – it is instead bound to the global object and you’ll be unwittingly altering these instead! - There is no need to use it, there are better code reuse patterns in JavaScript
Object Specifiers
Rather than: var myObject = maker (f, l, m, c, s) which has too many parameters to remember in the right order, use an object specifier:
var myObject = maker ({ //note curly braces
first: f,
last: l,
state: s,
city: c
}
;)
to contain them. They can now be listed in any order
Also useful to pass object specifiers to JSON (see Appendix E notes)
Prototypal
- Zero classes, one object inherits from another
- Create an object literal of a useful object and then make an instance of it using the format
var myObject = Object.create(originalObjectName) - When you then customise the new object (adding properties or methods through the dot notation for example), this is differential inheritance, where you specify the differences from the original object
Functional
- All properties of an object are visible (Javascript has no classes so there is no such thing as a ‘private variable’ which can only be seen within a class as per other languages)
- When you use a function to create your original object and the same with the object instances, you’re essentially utilising Javascript functional scope to create private properties and methods
- The below is an example of how you would create an original object, the
nameandsayingproperties are now completely private and only accessible to theget_nameandsaysmethod
var mammal = function (spec) {
var that = {}; //that is a new object which is basically a container of 'secrets' shared to the rest of the inheritance chain
that.get\_name = function () {
return spec.name;
};
that.says = function () {
return spec.saying || ''; //returns an empty string if no 'saying' argument is passed through the spec object when calling mammal
};
return that; //returns the object that contains the now private properties and methods (under functional scope)
}
var myMammal = mammal({name: 'Herb'});
Creating an object ‘cat’ can now inherit from the mammal constructor and only pay attention to the differences between it and mammal:
var cat = function (spec) {
spec.saying = spec.saying || 'meow'; //if spec.saying doesn't already exists, make it 'meow'
var that = mammal(spec); //here the object 'container of secrets' is set up inheriting from mammal already
//functions and property augmentations happen here
return that; //as above
}
- Requires less effort and gives better encapsulation and information hiding than the pseudoclassical pattern, as well as access to super methods (see page 54 of book for super method example)
- An object created using the functional pattern and making no use of
thisorthatis a durable object and cannot be compromised by attackers - Briefly also discussed in Module section above
- If you do want something to have access to the object’s private properties and methods, you pass it the
thatbundle (i.e. your ‘container of secrets’)
Parts
- An object can be composed out of a set of parts
- For example, you can create a function that provides the object it is passed with a number of methods (which are defined in this function), where each method is a part that is added to the object
Chapter 6 — Arrays
Javascript only has array-like objects which are slower than ‘real’ arrays.
Retrieval and updating of properties works the same as with an object except with integer property names.
Arrays have their own literal format and their own set of methods (Chapter 8 — Methods).
Array Literals
- An array literal is a pair of square brackets surrounding zero or more comma-seperated values
[a, b, c, etc] - The first value will get the property name ‘0’, the second will be ‘1’ and so on
- Javascript allows an array to contain any mixture of values
Length
- If you add to the array, the
lengthproperty will increase to contain the new element – it will not give an error - If you set the
.lengthto a smaller number than the current length of the array, it will delete any properties with a subscript >= the newlength - The
push()method is sometimes useful to add an element to the end of an array numbers.push('go') //adds the element 'go' to the end of the numbers array
Delete
- Elements can be deleted from the array object using
deletebut this leaves a hole in the array - Use
array.splice(keyInArray, howManyElementsToDelete)which changes the keys for the remaining values in the array so there is no hole left - May be slow
Enumeration
- A
forstatement can be used to iterate over all the properties of an array (as it is an object) - Do not use
for inas it does not iterate through the properties in order and sometimes pulls in from further up the prototype chain
Confusion
The rule is simple: when the property names [keys] are small sequential integers, you should use an array. Otherwise, use an object.
- Arrays are most useful when property names are integers but they can also accept strings as property names
- Javascript doesn’t have a good way of telling an object from an array as
typeof array === object - To accurately detect arrays, have to define our own function:
var is_array = function(value) {
return Object.prototype.toString.apply(value) === '[object Array]';
//apply(value) binds `value` to `this` & returns true if `this` is an array }
Methods
- Array methods are stored in
Array.prototypewhich can be augmented using the format:
//capital A in Array means this refers to the prototype
Array.method('reduce', function(parameters) {
//define variables and function
//return a value
});
- Remember, every array inherits and can use the methods you add to
Array.prototype - You can also add methods directly to an array because they are objects
myArray.total = function () { //statements to execute; }adds a ‘total’ function to the arraymyArray- DO NOT USE:
Object.create()will create an object – lacking thelengthproperty – not an array.
Dimensions
- Using
[]will create an empty array as they are not initialized in JavaScript - Accessing a missing element will give you
undefined - If you have an algorithm that relies on the array not being empty and not having
undefinedvalues, you can write a function that will prep your array to have a certain number of defined values, essentially initializing it with certain values in place - An
Array.dimfunction is outlined on page 63 which will allowvar myArray = Array.dim(10,0)to make an array with 10 zeroes starting from the first position in the array(0) - Javascript only has one dimensional arrays but can have array of arrays
- Two dimensional arrays (matrices) will have to be set up by the programmer
- page 63 gives a method for this and for explicitly setting cell values so as not to have an empty matrix
Chapter 7 — Regular Expressions
A regular expression is the specification of the syntax of a simple language
Used with regexp.exec, regexp.test, string.match, string.replace, string.search and string.split to interact with string (more in Chapter 8 – Methods)
Quite convoluted and difficult to read as they do not allow comments or whitespace so a JavaScript regular expression must be on a single line
An Example
/ˆ(?:([A-Za-z]+):)?(\/{0,3})([0-9.\-A-Za-z]+)(?::(\d+))?(?:\/([ˆ?#]*))?(?:\?([ˆ#]*))?(?:#(.*))?$/
Breaking it down one portion (factor) at a time:
- Note that the string starts and ends with a slash
/ ˆindicates the beginning of a string(?:([A-Za-z]+):)?(?:...)indicates a noncapturing group, where the ‘…’ is replaced by the group that you wish to match, but not save to anywhere- Suffix
?indicates the group is optional, so it could or could not exist in the string – it could even exist more than once ()around the ([A-Za-z]+) indicates a capturing group which is therefore captured and placed in theresultarray- They groups are placed in the array in order, so the first will appear in
result[1] - Noncapturing groups are preferred to capturing groups because capturing groups have a performance penalty (on account of saving to the result array)
- You can also have capturing groups within noncapturing groups such as
[(?:Bob says: (\w+))](http://www.rexegg.com/regex-disambiguation.html) [...]indicates a character classA-Za-zis a character class containing all 26 letters of the alphabet in both upper and lower case- Suffix
+means character class will be matched one or more times - Suffix
:is matched literally (so the letters will be followed by a colon in this case) (\/{0,3})\/The backslash\escapes the forward slash/(which traditionally symbolises the end of the regular expression literal) and together they indicate that the forward slash/should be matched- Suffix
{0,3}means the slash/will be matched between 0 and 3 times ([0-9.\-A-Za-z]+)- String made up of one or more (note the
+at the end denoting possible multiple occurrences) digits, letters (upper or lower case), full stops (.) or hyphens (-) - Note that the hyphen was escaped with a backslash
\-as hyphens usually denote a range but in this case is a hyphen within the expression (?::(\d+))?\drepresents a digit character so this will be a sequence of one or more digit characters (as per the+)- The digit characters will be immediately preceded by a colon
: (\d+)will be the fourth capturing group in this expression, it is also optional (?) and inside a non-capturing group(?:...)(?:\/([ˆ?#]*))?- Another optional group (
?), beginning with a literal slash/(escaped by the backslash) - The
ˆat the beginning of character class[ˆ?#]means it includes all characters except ? and # - This actually leaves the regexp open to attack because too many characters are included in the character class
- The
*indicates the character class will appear zero or more times (?:\?([ˆ#]*))?- We’ve seen everything here before: An optional capturing group starting with a literal
?(escaped by the backslash) with zero or more characters that are not # (?:#(.*))?- Final optional group beginning with a
# .matches any character except a line ending character$represents the end of a string- Note:
ˆand$are important because they anchor the regexp and checks whether the string matched against it contains only what is in the regexp - If
ˆand$weren’t present, it would check that the string contained the regexp but wouldn’t necessarily be only made up of this - Using only
ˆchecks the string starts with the regexp - Using only
$checks the string ends with the regexp
Another example
/ˆ-?\d+(?:\.\d*)?(?:e[+\-]?\d+)?$/i;
Most of this we have seen before but here are the new bits:
- The
iat the end means ignore case when matching letters -?means the minus sign is optional(?:\.\d*)matches a decimal point followed by zero or more digits (123.6834.4442284 does not match)- Note this expression only uses noncapturing groups
Construction
3 flags exist in regular expressions: i means insensitive – ignore the character case, g means global – to match multiple items and m means multiline – where ˆ and $ can match line-ending characters
Two ways to build a regular expression: 1. Regular Expression literals as per the examples above start and end with a slash /
- Here the flags are appended after the final slash, for example
/i - Be careful:
RegExpobjects made by regular expression literals share a single instance - Use
RegExpconstructor - The first parameter is the string to be made into a
RegExpobject, the second is the flag - Useful when all information for creating the regular expression is not available at time of programming
- Backslashes mean something in the constructor, so these must be doubled and quotes must be escaped
//example creating a regular expression object that matches a JavaScript string
var my_regexp = new RegExp("'(?:\\\\.|[ˆ\\\\\\'])*'", 'g');
Elements
Regexp Choice
| provides a match if any of the sequences provided match.
In "into".match(/in|int/);, the in will be a match so it doesn’t even look at the int.
Regexp Sequence
A regexp sequence is made up of one or more regexp factors. If there are no quantifiers after the factor (like ?, * or +), the factor will be matched one time.
Regexp Factor
A regexp factor can be a character, a parenthesized group, a character class, or an escape sequence.
It’s essentially a portion of the full RegExp, like what we broke down the regexp above into.
- The following special characters must all be escaped with a backslash
\to be taken literally, or they will take on an alternative meaning: / [ ] ( ) { } ? + * | . ˆ$ - The
\prefix does not make letters or digits literal - When unescaped:
.matches any character except line-endingˆmatches the beginning of the text whenlastIndexproperty is zero, or matches line-ending character when themflag is present- Having
ˆinside a character class means NOT, so [ˆ0-9] means does not match a digit $matches the beginning of the text or a line-ending character when themflag is present
Regexp Escape
As well as escaping special characters in regexp factors, the backslash has additional uses:
- As in strings,
\fis the formfeed character,\nis new line,\ris carriage return,\tis tab and\uspecifies Unicode as a 16-bit hex. But\bis not a backspace character \d=== [0-9] and\Dis the opposite, NOT (ˆ) a digit, [ˆ0-9]\smatches is a partial set of Unicode whitespace characters and\Sis the opposite\w=== [0-9A-Za-z] and\W=== [ˆ0-9A-Za-z] but useless for any real world language (because of accents on letters, etc)\1refers to the text captured in group 1 so it is matched again later on in the regexp\2refers to group 2,\3to group 3 and so on
*\b is a bad part. It was supposed to be a word-boundary anchor but is useless for multilingual applications
Regexp Group
Four kinds of groups:
- Capturing:
(...)where each group is captured into theresultarray – the first capturing group in the regexp goes intoresult[1], the second intoresult[2]and so on - Noncapturing
(?:...)where the text is matched, but not captured and saved anywhere, making is slightly faster than a capturing group (has no bearing on numbering of capturing groups) - Positive lookahead, a bad part:
(?=...)acts like a noncapturing group except after the match is made, it goes back to where text started - Negative lookahead, a bad part:
(?!...)is like a positive lookahead but only matches if there is no match with what is in it
Regexp Class
- Conveniently and easily specifies one of a set of characters using square brackets
[], for example vowels:[aeiou] - Can shorten specification of all 32 ASCII special characters to [!-/:-@[-`{-˜] (note that the ` in this piece of code is a back-tick)
- Also allows
ˆas the first character after the opening[to mean NOT the characters in the character set
Regexp Class Escape
There are specific characters that must be escaped in a character class: — / [ ] ˆ
Regexp Quantifier
A quantifier at the end of a factor indicates how many times the factor should be matched
- A number in curly braces means the factor should match that many times, so
/o{3}matches ooo - Two comma-seperated numbers in curly braces provide the range of times a factor should match, so
{3,5}indicates it will match 3, 4 or 5 times - Zero or one times (same thing as saying something is optional) can be
?or{0,1} - Zero or more times can be
*or{0,} - One or more times can be
+or{1,}
Prefer to use ‘zero or more’ or ‘one or more’ matching over the ‘zero or one’ matching — i.e. prefer greedy matching over lazy matching
Chapter 8 — Methods
Arrays
array.concat(item…)
Produces new array copying the original array with the items appended to it (does not modify the original array like array.push(item) does). If the item is an array, its elements are appended.
array.join(separator)
Creates a string of all the array’s elements, separated by the separator. Use an empty string separator (”) to join without separation.
array.pop()
Removes last element of array. Returns undefined for empty arrays.
array.push(item…)
Modifies the array, appending items onto the end. Returns the new length of the array.
array.reverse()
Modifies the array by reversing the order of the elements.
array.shift()
Removes the first element of the array (does not leave a hole in the array — same effect as using the .splice(a,b) method) and returns that first element.
array.slice(start, end)
Different to splice.
‘slice’ creates a new array, copying from the start element and stopping at the element before the end value given. If no end is given, default is array.length.
Negative values for start and end will have array.length added to them and if start>end, it will return an empty array.
array.sort(comparefn)
JavaScript has a sort() method which was created only to compare strings and therefore sorts numbers incorrectly (it will sort them as 1, 15, 2, 23, 54 for example). Therefore, we have to write a comparison function which returns 0 if the two elements you are comparing are equal, a positive number if the first element should come first and a negative number if the second element should come first. Then pass this comparison function to sort() as a parameter to allow it to sort array elements intelligently.
Page 80-82 in the book takes you through various iterations of the comparison functions — for numbers, simple strings, objects and objects with multiple keys (for example if you want to sort objects by first and last names). These should be taken from the book when required.
array.splice(start, deleteCount, item…)
Removes elements from the array making sure there are no holes left in the array. It is most popularly used for deleting elements from an array.
It removes the deleteCount number of elements from the array starting from the start position. If there are item parameters passed to it, it will replace the deleted elements in the array with the items.
It returns an array containing the deleted elements.
array.unshift(item…)
Works like push but adds items to the front of the array instead of the end. Returns the new length of the array.
Function
function.apply(thisArg, [argArray])
The apply method invokes a function, passing in the object that will be bound to this and optional array of arguments.
Number
number.toExponentional(fractionDigits)
Converts number to a string in exponential form (e.g. 3.14e+0). fractionDigits (from 0 to 20) gives the number of decimal places.
number.toFixed(fractionDigits)
Converts number to a string in decimal form (e.g. 3.1415927). fractionDigits (from 0 to 20) gives the number of decimal places.
number.toPrecision(precision)
Converts number to a string in decimal form (e.g. 3.1415927). The difference from toFixed is that precision (from 0 to 21) gives the number of total digits.
number.toString(radix)
Converts number to a string. radix is an optional parameter between 2 and 36 and gives the base. The default radix is 10.
Object
object.hasOwnProperty(name)
Does not look at the property chain. Returns true if the object contains the property name.
RegExp
regexp.exec(string)
Most powerful (and slowest) regexp method.
Checks the string against the regexp (starting at position 0) and returns an array containing the matches. The regexp is set up with various capturing groups and these determine the elements that go in the array:
- the 0 element of the array will contain the part of
stringthat matched the regexp - element 1 of the array will contain the text captured by the first capturing group in regexp
- element 2 of the array will contain the text captured by the second capturing group in regexp and so on
- if the match fails, it returns
null
If the regexp contains a g flag (e.g. var regexp = /[ˆ<>]+|<(\/?)([A-Za-z]+)([ˆ<>]*)>/g;), there is a lot more to look out for:
- Searching begins at
regexp.lastIndex(initially zero) - If a match is found,
lastIndexbecomes the position of the first character of the match - If no match is found,
lastIndexis reset to zero - If searching for multiple occurrences of a pattern by calling
execin a loop, ensure you reset_lastIndex_when exiting the loop and rememberˆonly matches when_lastIndex_is equal to zero
Example on page 87 of the book is worth reading to improve understanding.
regexp.test(string)
Simplest (and fastest) regexp method.
If regexp matches the string it returns true. Otherwise it returns false. Do not use the g flag with this method.
String
string.charAt(pos)
Returns character at position pos in the string starting from 0. If pos is less than zero or bigger than the string itself it return an empty string.
string.charCodeAt(pos)
Same as charAt except it returns the integer that represents the code point value of the character at position _pos_. Returns NaN if string.length < pos < 0.
string.concat(string…)
Creates new string concatenating various strings. + tends to be used instead of this method (e.g. var cat = 'c'+'a'+'t';)
string.indexOf(searchString, position)
Searches for searchString within string starting at position position (an optional parameter). If position is not provided, search starts at the beginning of the string. Returns the integer position of the first matched character or -1 if no match is found.
string.lastIndexOf(searchString, position)
Same as indexOf but searches from the end of the string instead of the beginning.
string.localeCompare(that)
Compares string to that parameter and returns:
- 0 if string ===
that - -1 if string <
that
NB. ‘a’ < ‘A’, comparison is not just in length.
string.match(regexp)
Works the same way as regexp.exec(string) if there is no g flag in the regexp.
If there is a g flag in teh regexp, it produces an array of the matches but excludes the capturing groups
string.replace(searchValue, replaceValue)
Searches for the searchValue in string and replaces it with the replaceValue.
If searchValue is a:
- string, only its first occurrence will be replaced with the
replaceValue - regexp with a g flag, all occurrences will be replaced with the
replaceValue; otherwise, only the first occurrence will be replaced
If replaceValue is a:
- string, a
$value has a special meaning when used in thereplaceValuethat conveys what to replace – see table on page 90 for possible variations on$ - function, it is called for each match and the string result of the function is used as the replacement text
- string result of the first call will replace capture group 1 of the string and so on
string.search(regexp)
Similar to .indexOf(string) but takes a regexp instead of a string, returning the position of the first match (or -1 if there is no match). The g flag is ignored.
string.slice(start, end)
Creates a new string by copying the characters from the start position to the character before the end position in string.
The end parameter is optional and defaults to string.length. If either parameter is negative, string.length is added to it.
string.split(separator, limit)
Creates an array of strings by splitting apart string at the points where the separator appears (e.g. if the separator is ‘.’, ab.cd’ becomes [‘ab’, ‘cd’]).
- If separator is an empty string, an array of single characters is produced.
limitis optional and determines how many pieces are to be split off from the original string.- The
separatorcan be aregexpbut - text from capturing groups within the regexp will be included in the split — e.g. in
var e = text.split(/\s*(,)\s*/);the commas (,) will each be included as a separate element in the resulting array - some systems ignore empty strings when the
separatoris aregexp
string.substring(start, end)
No reason to use, use slice instead.
string.toLocaleLowerCase()
Produces a new string converted to lower case, using the rules for the particular locale (geography).
string.toLocaleUpperCase()
Produces a new string converted to upper case, using the rules for the particular locale (geography).
string.toLowerCase()
Produces a new string converted to lower case.
string.toUpperCase()
Produces a new string converted to upper case.
String.fromCharCode(char…)
Produces a new string from a series of numbers. var a = String.fromCharCode(67, 97, 116); //a === 'Cat' NB. You’re calling the prototype here, not replacing ‘String’ with your own variable.
Chapter 9 — Style
JavaScripts’s loose typing and excessive error tolerance provide little compile-time assurance of our programs’ quality, so to compensate, we should code with strict discipline.
We should avoid the bad parts of JavaScript, but also the useful parts that can be occasionally dangerous
the likelihood a program will work [as intended] is significantly enhanced by our ability to read it
Must be written in a clear, consistent style, including:
Good use of whitespace
Put at most one statement on a line
If you have to break a statement into 2 or more lines, indent the 2nd line onwards (an extra four spaces)
Always use blocks (curly braces {}) with structured statements like
_if_and_while_to avoid confusion on what the statement is actually doing
Put the opening brace
_{_on the same (first) line as the statement to avoid JavaScript’s semicolon insertion issues – i.e_if (a) { ..._
Use line comments
_//comment_and not block commenting (unless you’re commenting out code)
Declare all your variables at the beginning of the function, due to JavaScript’s functional scope
- I use a single global variable to contain an application or library. Every object has its own namespace, so it is easy to use objects to organize my code. Use of closure provides further information hiding, increasing the strength of my modules.
Chapter 10 — Beautiful Features
Each feature you add to something has a lot of different costs (documentation costs, specification, design, testing and development costs) and these are often not properly accounted for.
Features that offer value to a minority of users impose a cost on all users
We cope with the complexity of feature-driven design by finding and sticking with the good parts. For example, microwaves do a ton of different things, but most people just use one setting, the timer and the clock. So why not design with just the good parts?
Appendix A — the Awful Parts
Need to know what all the pitfalls are with these parts.
Global variables
These are variables that are visible throughout the code in any scope. They can be changed at any time by any part of the program which makes them unreliable in larger complex programs. This can also lead to naming conflicts which can cause your code to fail or you to accidentally overwrite a global variable.
Defined in three ways:
- Using a
varstatement outside of any function;var foo = value; - By adding a property to the global object (container of all global variables), such as
windowin browsers;window.foo = value; - Using a variable without declaring it with
var, which makes it an implied global;foo = value
Scope
Although JavaScript has block syntax (i.e. is written in blocks) like a lot of other programming languages, it has functional scope and not block scope.
Variables should all be declared at the top of the function and not littered throughout the block.
Semicolon Insertion
Attempts to correct faulty programs by automatically inserting semicolons. Do not depend on this as it can hide underlying issues.
Also ensure opening curly braces ({) are on the first line of a statement, otherwise semicolons will be erroneously inserted and cause problems:
//Ensure curly braces open on the first line of a statement
return {
status: true //for example
};
//instead of
return
{
status:true
};
Reserved Words
Most JavaScript reserved words are not used in the language but cannot be used to name variables or parameters.
If used as the key in object literals, they must be quoted. For example object - {'case' : value}; or object['final'] = value; as case and final are both reserved words.
Unicode
JavaScript characters are 16 bits which only cover the original Unicode Basic Multilingual Place.
typeof
Watch out for:
typeof nullwhich returns ‘object’ instead of ‘null’- incorrect reporting on typeof regular expressions, with some implementations returning ‘object’ and some returning ‘function’
- arrays are objects in JavaScript so
typeof arraywill return ‘object’
All objects are truthy and null is falsy, so you can use the following to tell them apart:
if (myvalue && typeof myvalue === 'object') {
//then my value is definitely an object or an array because not only is its 'typeof' an object but it's also truthy (first statement)
}
NaN
typeof NaN === 'number'even though it stands for not-a-number- If you have a chain of formulas that together produce a
NaNthen at least one of them will have generatedNaN - Surprisingly
NaN !=== NaN isNaN(value)can be used to distinguish numbers from NaN
For numbers, best use your own isNumber formula:
var isNumber = function isNumber(value) {
return typeof value === 'number' && isFinite(value); //isFinite() rejects NaN and Infinity, but is only good for numbers, not strings
}
Phony Arrays
JavaScript doesn’t have real arrays, it has array-like objects.
- Good: No need to give them dimensions and don’t generate out-of-bounds errors
- Bad: Slower than ‘real’ arrays
To test if value is an array:
if (myvalue && typeof myvalue === 'object' && typeof myvalue.length === 'number' &&
!(myvalue.propertyIsEnumerable('length'))) {
//my_value is definitely an array!
}
The arguments array isn’t an array, just an object with a length property.
Falsy Values
0, NaN, '', false, null and undefined are all falsy values, but they are not interchangeable. When testing for a missing member of an object for example, you need to use undefined and not null.
undefined and NaN are actually global variables instead of constants but don’t change their values.
Object
JavaScript objects inherit members from the prototype chain so they are never truly empty.
To test for membership without prototype chain involvement, use the hasOwnProperty method or limit your results (for example, to specific types like number so you know you’re not dragging in object members from up the prototype for example if that’s what’s causing the problem).
Appendix B — the Bad Parts
Avoid these altogether
==and!=: Don’t function properly when result is false, use===or!==insteadwithstatement: Intended to provide a shortcut to properties of an object but results vary every time it is runeval: Adds unnecessary complication and compromises the security of the application- Giving string arguments to
setTimeoutandsetIntervalshould also be avoided as this makes them act likeeval continuestatement: Forces a loop into its next iteration but the code is usually much improved when re-written withoutcontinueswitchfall through: In aswitchstatement, eachcasefalls through to the nextcaseunless you explicitly disrupt the flow, but using these intentional fall throughs makes the unintentional ones that are causing errors basically impossible to find- This is one of those parts of JavaScript that appears useful but you’re better off avoiding because it’s occasionally very dangerous
- Block-less statements: Always use curly braces
{}to block in statements so as to avoid misinterpretation and aid error finding - Bitwise operators: Shouldn’t really be doing this kind of manipulations because they are quite slow in JavaScript, therefore there shouldn’t be a need to use
&,|,ˆ,˜,>>,>>>or<< - This doesn’t mean you can’t use
&&for example ++and--: This one seems debatable to me; Douglas Crockford finds it makes his coding style much more cryptic and difficult to read (the book uses+=1and-=1instead)
The function statement vs the function expression: To use JavaScript well, important to understand that functions are values.
- A function statement is shorthand for a var statement with a function value, so
function foo() {}(a function statement) means pretty much the same asvar foo = function foo(){};(a function expression) - Logically, to write the language well you should define a function before using it, but in JavaScript, function statements (using just
function foo(){}) are hoisted to the top of the scope in which they are defined – this encourages sloppy programming and should be avoided - function statements also don’t function consistently in
ifstatements - if you need to start a function expression with the word function, wrap it in parentheses (), or JavaScript assumes it’s a function statement
Typed wrappers: Don’t use new Boolean or new String or new Number, it’s completely unnecessary. Also avoid new Object and new Array and use {} and [] instead.
new operator: Functions that are intended to be used with new (conventionally starting with a capital letter) should be avoided (don’t define them) as they can cause all kinds of issues and complex bugs which are difficult to catch.
void: In JavaScript, this actually takes a value and returns undefined, which is hugely confusing and not helpful. Don’t use it.
Appendix C — JSLint
JSLint is a code quality tool for JavaScript which checks your syntax.
Having read through this appendix (you can read more about JSLint here), I tend more towards JSHint, a fork of JSLint. It allows programmers to customise for themselves which the good parts and bad parts are and define their own subset, although naturally there are a number of pre-defined options. This is a really fantastic article on using JSHint; it’s simple and aimed at having you using JSHint in a few minutes as well as providing various sources for pre-defined subsets.
Further resources:
https://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5bhttps://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5bhttps://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5bhttps://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5b
Part 1

How to learn effectively
Learning: The acquisition of skills and the ability to apply them in the future.
What makes an Effective learner?
- They are active listeners.
- They are engaged with the material.
- They are receptive of feedback.
- They are open to difficulty.
Why do active learning techniques feel difficult?
- It feels difficult because you are constantly receiving feedback, and so you are constantly adapting and perfecting the material.
Desirable Difficulty
- The skills we wish to obtain is often a difficult one.
- We want challenging but possible lessons based on current level of skill.
Effective learners space their practice
- Consistent effort > cramming => for durable knowledge
Here’s a REPL to practice with:
https://replit.com/@bgoonz/lambda-prep#README.html
https://replit.com/@bgoonz/lambda-prep#README.html
Hello World
- console.log : command used to print something onto the screen.
- syntax : the exact arrangement of the symbols, characters, and keywords in our code.
- // : notation for creating a code comment in JS.
- code comment : useful for annotating pieces of code to explain how something works, ignored by computer.
“Simplicity is prerequisite for reliability.” — Edsger W. Dijkstra
The Number Data Type
The number data type in JS is used to represent any numerical values, including integers and decimal numbers.
Basic Arithmetic Operators
Operators are the symbols that perform particular operations.
- + (addition)
- – (subtraction)
- asterisk (multiplication)
- / (division)
- % (modulo)
JS evaluates more complex expressions using the general math order of operations aka PEMDAS.
- PEMDAS : Parentheses, Exponents, Multiplication, Division, Modulo, Addition, Subtraction.
- To force a specific order of operation, use the group operator ( ) around a part of the expression.
Modulo : Very useful operation to check divisibility of numbers, check for even & odd, whether a number is prime, and much more! (Discrete Math concept, circular problems can be solved with modulo)
- Whenever you have a smaller number % a larger number, the answer will just be the initial small number.
console.log(7 % 10); // => 7;
The String Data Type
The string data type is a primitive data type that used to represent textual data.
- can be wrapped by either single or double quotation marks, best to choose one and stick with it for consistency.
- If your string contains quotation marks inside, can layer single or double quotation marks to allow it to work.
"That's a great string"; (valid)'Shakespeare wrote, "To be or not to be"'; (valid)'That's a bad string'; (invalid)- Alt. way to add other quotes within strings is to use template literals.
`This is a temp'l'ate literal ${function}` // use ${} to invoke functions within.- .length : property that can be appended to data to return the length.
- empty strings have a length of zero.
- indices : indexes of data that begin at 0, can call upon index by using the bracket notation [ ].
console.log("bootcamp"[0]); // => "b"
console.log("bootcamp"[10]); // => "undefined"
console.log("boots"[1 * 2]); // => "o"
console.log("boots"["boot".length - 1]); // => "t"
- we can pass expressions through the brackets as well since JS always evaluates expressions first.
- The index of the last character of a string is always one less than it’s length.
- indexOf() : method used to find the first index of a given character within a string.
console.log("bagel".indexOf("b")); // => 0 console.log("bagel".indexOf("z")); // => -1- if the character inside the indexOf() search does not exist in the string, the output will be -1.
- the indexOf() search will return the first instanced index of the the char in the string.
- concatenate : word to describe joining strings together into a single string.
The Boolean Data Type
The boolean data type is the simplest data type since there are only two values: true and false.
- Logical Operators (Boolean Operators) are used to establish logic in our code.
- ! (not) : reverses a boolean value.
console.log(!true); // => false console.log(!!false); // => false- && (and) Truth Table

- Logical Order of Operations : JS will evaluate !, then &&, then ||.
- De Morgan’s Law : Common mistake in boolean logic is incorrectly distributing ! across parentheses.
!(A || B) === !A && !B; !(A && B) === !A || !B;- In summary, to correctly distribute ! across parentheses we must also flip the operation within.
- Short-Circuit Evaluation : Because JS evalutes from left to right, expressions can “short-circuit”. For example if we have true on the left of an || logical comparison, it will stop evaluating and yield true instead of wasting resources on processing the rest of the statement.
console.log(true || !false); // => stops after it sees "true ||"
Comparison Operators
All comparison operators will result in a boolean output.
The relative comparators
- > (greater than)
- < (less than)
- >= (greater than or equal to)
- <= (less than or equal to)
- === (equal to)
- !== (not equal to)
Fun Fact: “a” < “b” is considered valid JS Code because string comparisons are compared lexicographically (meaning dictionary order), so “a” is less than “b” because it appears earlier!
If there is ever a standstill comparison of two string lexicographically (i.e. app vs apple) the comparison will deem the shorter string lesser.
Difference between == and ===
- === : Strict Equality, will only return true if the two comparisons are entirely the same.
- == : Loose Equality, will return true even if the values are of a different type, due to coercion. (Avoid using this)
Variables
Variables are used to store information to be referenced and manipulated in a program.
- We initialize a variable by using the let keyword and a = single equals sign (assignment operator).
let bootcamp = "Lambda"; console.log(bootcamp); // "Lambda"- JS variable names can contain any alphanumeric characters, underscores, or dollar signs (cannot being with a number).
- If you do not declare a value for a variable, undefined is automatically set.
let bootcamp; console.log(bootcamp); // undefined- We can change the value of a previously declared variable (let, not const) by re-assigning it another value.
- let is the updated version of var; there are some differences in terms of hoisting and global/block scope — will be covered later in the course (common interview question!)
Assignment Shorthand
let num = 0;
num += 10; // same as num = num + 10
num -= 2; // same as num = num - 2
num /= 4; // same as num = num / 4
num *= 7; // same as num = num * 7
- In general, any nonsensical arithmetic will result in NaN ; usually operations that include undefined.
- declaration : process of simply introducing a variable name.
- initialization : process of both declaring and assigning a variable on the same line.
Functions
A function is a procedure of code that will run when called. Functions are used so that we do not have to rewrite code to do the same thing over and over. (Think of them as ‘subprograms’)
- Function Declaration : Process when we first initially write our function.
- Includes three things:
- Name of the function.
- A list of parameters ()
- The code to execute {}
- Function Calls : We can call upon our function whenever and wherever* we want. (*wherever is only after the initial declaration)
- JS evaluates code top down, left to right.
- When we execute a declared function later on in our program we refer to this as invoking our function.
- Every function in JS returns undefined unless otherwise specified.
- When we hit a return statement in a function we immediately exit the function and return to where we called the function.
- When naming functions in JS always use camelCase and name it something appropriate. > Greate code reads like English and almost explains itself. Think: Elegant, readable, and maintainable!
Parameters and Arguments
- Parameters : Comma seperated variables specified as part of a function’s declaration.
- Arguments : Values passed to the function when it is invoked.
- If the number of arguments passed during a function invocation is different than the number of parameters listed, it will still work.
- However, is there are not enough arguments provided for parameters our function will likely yield Nan.
Further resources:
https://replit.com/@bgoonz/lambda-prep#README.htmlhttps://replit.com/@bgoonz/lambda-prep#README.htmlhttps://replit.com/@bgoonz/lambda-prep#README.htmlhttps://replit.com/@bgoonz/lambda-prep#README.html
More content at plainenglish.io
A all encompassing list of tools and resources for web developers

General resources
- Devdocs.io: Fast, offline, and free documentation browser for developers. Search 100+ docs in one web app: HTML, CSS, JavaScript, PHP, Ruby, Python, Go, C, C++…
- DevHints: cheatsheets for many web technologies
- Carbon: use this to share images of your code in presentations etc
- Badgen:
- Shields.io:
- to your documentation/readmes
- Git Flight Rules: A guide for astronauts (now, programmers using Git) about what to do when things go wrong.
- browser-2020: Things you can do with a browser in 2020

 Finding and vetting npm packages
Finding and vetting npm packages
- pika: A searchable catalog of modern “module” packages on npm
- npms: A better and open source search for node packages
- emma: Terminal assistant to find and install node packages
- npmvet: A simple CLI tool for vetting npm package versions
- Bundlephobia: See the “cost” of any npm package
- Snyk: Find any security vulnerabilities for any npm package. Search their database here:
[https://snyk.io/vuln/npm](https://snyk.io/vuln/npm):{package}e.g. https://snyk.io/vuln/npm:react - runpkg: Explore, learn about and perform static analysis on npm packages in the browser
 CSS
CSS
- CSS Tricks “Complete Guide to Flexbox”
- CSS Tricks “Complete Guide to Grid”
- Cubic bezier curve creator
- Ceaser: Cubic bezier curve generator
- CSS Triggers: find out what CSS properties trigger Paint/Layout/Composite renders
- Fluid-responsive font-size calculator: To scale typography smoothly across viewport widths.
- Browserhacks: Browserhacks is an extensive list of browser specific CSS and JavaScript hacks from all over the interwebs
- Absolute centering: useful techniques for absolute centering in CSS
- modern-css-reset: A bare-bones CSS reset for modern web development
- CSSFX: Beautifully simple click-to-copy CSS effects
- Shape Divider App
CSS-in-JS
- CSS-in-JS libraries
- Styled Components: CSS-in-JS for React
- Emotion: CSS-in-JS library
- linaria: Zero-runtime CSS in JS library
- Design System Utils: Design system framework for modern front-end projects (made by me!)
- Polished: A lightweight toolset for writing styles in JavaScript
- styled-by: Simple and powerful lib to handle styled props in your components
- xstyled: Consistent theme based CSS for styled-components

- Theme UI: Build consistent, themeable React apps based on constraint-based design principles
JavaScript
Useful JS links
- JS module import/export syntax
- JavaScript Event KeyCodes
- JavaScript Visualizer
- Does it mutate?
- jsPerf: JavaScript performance playground
- modern-js-cheatsheet
- HTML DOM: Common tasks of managing HTML DOM with vanilla JavaScript
Framework agnostic packages
General utilities
- Lodash: A modern JavaScript utility library delivering modularity, performance & extras.
- Just: A library of dependency-free utilities that do just do one thing (like Lodash but smaller)
- Install each util independently
- Read the tradeoffs document to see if Lodash is better
- tiny-get: A minimal-weight lodash.get equivalent utility
- evt: A type safe replacement for node’s EventEmitter
- liteready: A lightweight DOM ready.
- passport: Simple, unobtrusive authentication for Node.js
- get-size: Get the size of elements
- length.js: Library for length units conversion
- action-outside: Invoke a callback function when clicked or tabbed outside one or multiple DOM elements
- select-dom: Lightweight
querySelector/Allwrapper that outputs an Array - memoizee: Complete memoize/cache solution for JavaScript
- memoize-one: A memoization library which only remembers the latest invocation
- kind-of: Get the native JavaScript type of a value, fast.
- iterare: Array methods + ES6 Iterators =
- eases-jsnext: A grab-bag of modular easing equations
- normalizr: Normalizes nested JSON according to a schema
- lazy-value: Create a lazily evaluated value
- fast-equals: A blazing fast equality comparison, either shallow or deep
- fast-copy: A blazing fast deep object copier
- compute-scroll-into-view: Utility for calculating what should be scrolled, how it’s scrolled is up to you
- arr: A collection of tiny, highly performant Array.prototype alternatives
- timedstorage: A library for storing and expiring objects in window.localstorage
- left-pad: String left pad
- dont-go: A small client-side library with zero dependencies to change the title and/or favicon of the page when it is inactive
- always-done: Handle completion and errors with elegance! Support for async/await, promises, callbacks, streams and observables. A drop-in replacement for async-done — pass 100% of its tests plus more
- words: Linguistic javascript modules
- no-scroll: Disable scrolling on an element that would otherwise scroll
- libphonenumber-js: A simpler (and smaller) rewrite of Google Android’s libphonenumber library
- text-mask: Input mask for React, Angular, Ember, Vue, & plain JavaScript
- msk: Small library to mask strings
- focus-trap: Trap focus within a DOM node
- tinykeys: A tiny (~400 B) & modern library for keybindings
- clack: A modern keyboard shortcut library written in Typescript
- clack-react: React support for @reasonink/clack
- js-humanize: Humanize large numbers
- sub-in:
 A tiny (115B) find-and-replace utility for strings in Javascript
A tiny (115B) find-and-replace utility for strings in Javascript - color-hash: Generate color based on the given string (using HSL color space and BKDRHash)
- title: A service for capitalizing your title properly
- string-similarity: Finds degree of similarity between two strings, based on Dice’s Coefficient, which is mostly better than Levenshtein distance
- cuid: Collision-resistant ids optimized for horizontal scaling and performance
- obj-str: A tiny (96B) library for serializing Object values to Strings. Also serves as a faster & smaller drop-in replacement for the classnames module
- clsx: A tiny (223B) utility for constructing className strings conditionally. Also serves as a faster & smaller drop-in replacement for the classnames module
- xstate: State machines and statecharts for the modern web
- tasktimer: An accurate timer utility for running periodic tasks on the given interval ticks or dates. (Node and Browser)
- rough-notation: Create and animate hand-drawn annotations on a web page
Async
- axios: Promise based HTTP client for the browser and node.js
- axios-retry: Axios plugin that intercepts failed requests and retries them whenever possible
- redaxios: The Axios API, as an 800 byte Fetch wrapper
- cross-fetch: Universal WHATWG Fetch API for Node, Browsers and React Native
- awaity: A functional, lightweight alternative to bluebird.js, built with
async/awaitin mind - loadjs: A tiny async loader / dependency manager for modern browsers (789 bytes)
- await-to-js: Async await wrapper for easy error handling without try-catch
Node
- Fastify: Fast and low overhead web framework, for Node.js
- Express
- helmet: Help secure Express apps with various HTTP headers
- reqresnext: Tiny helper for express middleware testing
- lusca: Application security for express apps
- cookie-session: Simple cookie-based session middleware
- nodebestpractices: The largest Node.JS best practices list. Curated from the top ranked articles and always updated
- dumper.js: A better and pretty variable inspector for your Node.js applications
- http-terminator: Gracefully terminates HTTP(S) server
- uuid: Generate RFC-compliant UUIDs in JavaScript
- http-errors: Create HTTP Errors
- boom: HTTP-friendly error objects
- deno: A secure JavaScript and TypeScript runtime
- nanomatch: Fast, minimal glob matcher for node.js. Similar to micromatch, minimatch and multimatch, but without support for extended globs (extglobs), posix brackets or braces, and with complete Bash 4.3 wildcard support: (“*”, “**”, and “?”)
- yn: Parse yes/no like values
- ncp: Asynchronous recursive file copying with Node.js
Logging
Responsive
- responsive-watch: Watch some media queries and react when they change
- tornis: Tornis helps you watch and respond to changes in your browser’s viewport

- actual: Determine actual CSS media query breakpoints via JavaScript
Media and Images
- images-loaded: Wait for images to load using promises. No dependencies.
- lazysizes: High performance and SEO friendly lazy loader for images (responsive and normal), iframes and more, that detects any visibility changes triggered through user interaction, CSS or JavaScript without configuration.
Image services
- sharp: High performance Node.js image processing, the fastest module to resize JPEG, PNG, WebP and TIFF images. Uses the libvips library.
- IMGIX: Real-time image processing and image CDN
Date
- date-fns: Modern JavaScript date utility library
- tinydate: A tiny (337B) reusable date formatter. Extremely fast!
- tinytime:
 A straightforward date and time formatter in <1kb
A straightforward date and time formatter in <1kb
Scrolling
- scroll-watcher
- scrolldir: Leverage Vertical Scroll Direction with CSS
Carousels
Animation
- ramjet: Morph DOM elements from one state to another with smooth animations and transitions
- anime: JavaScript Animation Engine
- GSAP:the standard for JavaScript HTML5 animation | GreenSock
- Vanilla-tilt.js: A smooth 3D tilt javascript library forked from Tilt.js
Web workers
- workerize: Run a module in a Web Worker
- greenlet: Move an async function into its own thread. A simplified single-function version of workerize.
Immutable
- immer: Create the next immutable state tree by simply modifying the current tree
- use-immer: Use immer to drive state with a React hooks
- unchanged: A tiny, fast, unopinionated handler for updating JS objects and arrays immutably
- seamless-immutable: Immutable data structures for JavaScript which are backwards-compatible with normal JS Arrays and Objectsseamless-immutable`
- mutik: A tiny (495B) immutable state management library based on Immer
Typography
- fitty: Makes text fit perfectly
Polyfills
- resize-observer-polyfill:A polyfill for the Resize Observer API
 React
React
React-specific libs:
- react-powerplug: Renderless Containers
- formik: Build forms in React, without the tears

- react-router: Declarative routing for React
- Reach Router
- react-fns: React Components for common Web APIs
- react-portal: React component for transportation of modals, lightboxes, loading bars… to document.body
- react-ideal-image:
 An Almost Ideal React Image Component
An Almost Ideal React Image Component - react-adopt: Compose render props components like a pro
- downshift
- react-loadable: A higher order component for loading components with promises
- react-portal: React component for transportation of modals, lightboxes, loading bars… to document.body
- js-lingui:

 : A readable, automated, and optimized (5 kb) internationalization (Intl / i18n) for JavaScript
: A readable, automated, and optimized (5 kb) internationalization (Intl / i18n) for JavaScript - react-mq: Barebones CSS media query component for React, ~560 bytes
- react-media: CSS media queries for React. This is SSR compatible as well.
- merge-props: Merges className, style, and event handler props for React elements
- react-uid: Render-less container for generating UID for a11y, consistent react key, and any other good reason

- clsx: A tiny (229B) utility for constructing
classNamestrings conditionally - Framer Motion: An open source React library to power production-ready animations. Design fluid animations for the web, across desktop and mobile
- react-axe: Accessibility auditing for React.js applications
- use-click-away: React hook to detect click or touch events outside an element
- react-tiny-virtual-list: A tiny but mighty 3kb list virtualization library, with zero dependencies
 Supports variable heights/widths, sticky items, scrolling to index, and more!
Supports variable heights/widths, sticky items, scrolling to index, and more! - react-laag: Primitives to build things like tooltips, dropdown menu’s and popovers in React
- react-dnd: Drag and Drop for React
React Hooks
State management
Server-rendered React
- Next.js (repo): — Framework for server-rendered or statically-exported React apps
- next-plugins
Static site generators
- Gatsby: Blazing fast static site generator for React
Microservices/Serverless
TypeScript
- What’s new in TypeScript: Microsoft/TypeScript Wiki
- TypeScript Deep Dive
- TypeScript Evolution
- JSON to Typescript Interface
- react-typescript-cheatsheet: a cheatsheet for react users using typescript with react for the first (or nth!) time
- clean-code-typescript: Clean Code concepts adapted for TypeScript
Command Line, Terminal and shells
Fish shell: The user-friendly command line shell
- My fish_config
- awesome-fish: A curated list of packages, prompts, and resources for the amazing fish shell
- Starship: Cross-Shell Prompt
- tide:
 A modern prompt manager for the Fish shell
A modern prompt manager for the Fish shell
Creating CLI apps
- gluegun: A delightful toolkit for building Node-powered CLIs
- inquirer: A collection of common interactive command line user interfaces
- commander: node.js command-line interfaces made easy
- sade: Sade is a small but powerful tool for building command-line interface (CLI) applications for Node.js that are fast, responsive, and helpful!
CLI apps
- hub: hub is an extension to command-line git that helps you do everyday GitHub tasks without ever leaving the terminal
- serve: Static file serving and directory listing
- awesome-cli-apps: A curated list of command line apps
- SpaceVim: A community-driven modular vim distribution — The ultimate vim configuration
Tooling
Code bundlers
- preconstruct:
 Dev and build your code painlessly in monorepos
Dev and build your code painlessly in monorepos - Webpack: script/asset bundler
- Webpack recipes
- ifdef-loader: Webpack loader for JavaScript/TypeScript conditional compilation
- Parcel: Blazing fast, zero configuration web application bundler
- microbundle: Zero-configuration bundler for tiny modules
- rollup.js: Rollup is a module bundler for JavaScript
- ncc: Node.js Compiler Collection. Simple CLI for compiling a Node.js module into a single file, together with all its dependencies, gcc-style.
- fastpack: Pack JS code into a single bundle fast & easy
Package management and publishing
Commit hooks
Testing
Code formatting and linting
- Prettier
- precise-commits: Painlessly apply Prettier by only formatting lines you have modified anyway!
- pretty-quick: Runs Prettier on your changed files
- Eslint
- eslint-plugin-prettier: ESLint plugin for prettier formatting
- eslint-config-prettier: Turns off all rules that are unnecessary or might conflict with Prettier
- eslint-plugin-react: — React specific linting rules for ESLint
Miscellaneous
- npm-run-all: A CLI tool to run multiple npm-scripts in parallel or sequential
- cross-port-killer: Kill the process running on a given TCP port on Windows, Linux and Mac
- envinfo: Generate a report about your development environment for debugging and issue reporting
- mkcert: A simple zero-config tool to make locally trusted development certificates with any names you’d like
Progressive Web Apps
Code Sandboxes
- CodeSandbox: CodeSandbox is perfect for React demo apps
- Codepen: Codepen is perfect for non-React front-end demos and prototypes
- CodeShare: Codeshare is useful for collaborating on a single file if devs are not in the same room
- Glitch
APIs
- Postman: used to develop, test and monitor APIs
- MockAPI: create a mock API
- jsonbin: A personal JSON store as a RESTful service
- test-cors.org
- Reqres: A hosted REST-API ready to respond to your AJAX requests
- Mirage JS: An API mocking library for frontend developers
- Postwoman: API request builder
GraphQL
JSON
- JSON generator: generate a lot of custom JSON for your app/site
- JSON Editor Online: view/edit JSON in a better format
- fx: Command-line tool and terminal JSON viewer

HTML
- github.com/joshbuchea/HEAD: the definitive resource for everything that could go in the head of your document
- MetaTags.io: Preview, Edit and Generate
- HEY META: Website Meta Tag Check
- Rich Link Preview
SVG
- A Practical Guide to SVGs on the web
- Get Waves: Create SVG waves for your next design
- Blobmaker: Make organic SVG shapes for your next design
- flubber: Tools for smoother shape animations
- Hero Patterns: Free repeatable SVG background patterns for your web projects
Icons
- ICONSVG: Quick customizable SVG icons for your project
- Simple Icons
- React Icons
- Evil Icons
- Icon Font & SVG Icon Sets ❍ IcoMoon
- SVG PORN
- Feather: Simply beautiful open source icons
- react-feather: React component for Feather icons
- System UIcons
SVG/Image Media compression
Conversions and unicode
Features and feature detection
- Can I Use…: Browser support tables for modern web technologies (HTML5, CSS3, JavaScript etc)
- Kangax JavaScript compatibility table
Performance
- Bundlephobia: find the cost of adding a npm package to your bundle
Performance testing and monitoring
Design
- Subtract Guides: Simple Rules for Designing Web & Mobile Forms
Design Systems and documentation
- Storybook: UI dev environment you’ll love to use
- react-styleguidist: — Isolated React component development environment with a living style guide
- Docusaurus: Easy to Maintain Open Source Documentation Websites
- Docz
- design-system-utils: — Design system framework for modern front-end projects
- Docute: The fastest way to create a documentation site for your project
- playroom: Design with JSX, powered by your own component library
Accessibility (A11y)
Accessibility is an extremely important part of any web project. While the SOW, functional spec or user-stories might not directly mention a11y, it is up to each developer to ensure that best efforts are made to make our websites as accessible as possible.
DevOps
Continuous integration
Docker
- dockle: Container Image Linter for Security, Helping build the Best-Practice Docker Image, Easy to start
Hosting
Domains
Design
Typography
IDEs and Text Editors
VS Code
- My VS Code extensions
- My preferences
- awesome-vscode: A curated list of delightful VS Code packages and resources
Programming fonts
Code colour schemes
Regular expressions
- Regex101: Online regex tester and debugger: PHP, PCRE, Python, Golang and JavaScript
If you found this guide helpful feel free to checkout my other articles:
https://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5b
OR GitHub/gists where I host similar content:
https://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5bhttps://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5b
Or Checkout my personal Resource Site:
https://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5b
Fundamental Data Structures In JavaScript * { font-family: Georgia, Cambria, “Times New Roman”, Times, serif; } html, body { margin: 0; padding: 0; } h1 { font-size: 50px; margin-bottom: 17px; color: #333; } h2 { font-size: 24px; line-height: 1.6; margin: 30px 0 0 0; margin-bottom: 18px; margin-top: 33px; color: #333; } h3 { font-size: 30px; margin: 10px 0 20px 0; color: #333; } header { width: 640px; margin: auto; } section { width: 640px; margin: auto; } section p { margin-bottom: 27px; font-size: 20px; line-height: 1.6; color: #333; } section img { max-width: 640px; } footer { padding: 0 20px; margin: 50px 0; text-align: center; font-size: 12px; } .aspectRatioPlaceholder { max-width: auto !important; max-height: auto !important; } .aspectRatioPlaceholder-fill { padding-bottom: 0 !important; } header, section[data-field=subtitle], section[data-field=description] { display: none; }
Data structures in JavaScript
Fundamental Data Structures In JavaScript
Data structures in JavaScript
Here’s a website I created to practice data structures!
Here’s the repo that the website is built on:
Here’s a live code editor where you can mess with any of the examples…
Resources (article content below):
Videos
Books
- Introduction to Algorithms by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein
- Competitive Programming 3 by Steven Halim and Felix Halim
- Competitive Programmers Hand Book Beginner friendly hand book for competitive programmers.
- Data Structures and Algorithms Made Easy by Narasimha Karumanchi
- Learning Algorithms Through Programming and Puzzle Solving by Alexander Kulikov and Pavel Pevzner
Coding practice
Courses
- Master the Coding Interview: Big Tech (FAANG) Interviews Course by Andrei and his team.
- Common Python Data Structures Data structures are the fundamental constructs around which you build your programs. Each data structure provides a particular way of organizing data so it can be accessed efficiently, depending on your use case. Python ships with an extensive set of data structures in its standard library.
- Fork CPP A good course for beginners.
- EDU Advanced course.
- C++ For Programmers Learn features and constructs for C++.
Guides
space
The space complexity represents the memory consumption of a data structure. As for most of the things in life, you can’t have it all, so it is with the data structures. You will generally need to trade some time for space or the other way around.
time
The time complexity for a data structure is in general more diverse than its space complexity.
Several operations
In contrary to algorithms, when you look at the time complexity for data structures you need to express it for several operations that you can do with data structures. It can be adding elements, deleting elements, accessing an element or even searching for an element.
Dependent on data
Something that data structure and algorithms have in common when talking about time complexity is that they are both dealing with data. When you deal with data you become dependent on them and as a result the time complexity is also dependent of the data that you received. To solve this problem we talk about 3 different time complexity.
- The best-case complexity: when the data looks the best
- The worst-case complexity: when the data looks the worst
- The average-case complexity: when the data looks average
Big O notation
The complexity is usually expressed with the Big O notation. The wikipedia page about this subject is pretty complex but you can find here a good summary of the different complexity for the most famous data structures and sorting algorithms.
The Array data structure

Definition
An Array data structure, or simply an Array, is a data structure consisting of a collection of elements (values or variables), each identified by at least one array index or key. The simplest type of data structure is a linear array, also called one-dimensional array. From Wikipedia
Arrays are among the oldest and most important data structures and are used by every program. They are also used to implement many other data structures.
Complexity
Average
Access Search Insertion Deletion
O(1) O(n) O(1) O(n)

indexvalue0 … this is the first value, stored at zero position
- The index of an array runs in sequence
2. This could be useful for storing data that are required to be ordered, such as rankings or queues
3. In JavaScript, array’s value could be mixed; meaning value of each index could be of different data, be it String, Number or even Objects
2. Objects
Think of objects as a logical grouping of a bunch of properties.
Properties could be some variable that it’s storing or some methods that it’s using.
I also visualize an object as a table.
The main difference is that object’s “index” need not be numbers and is not necessarily sequenced.

The Hash Table

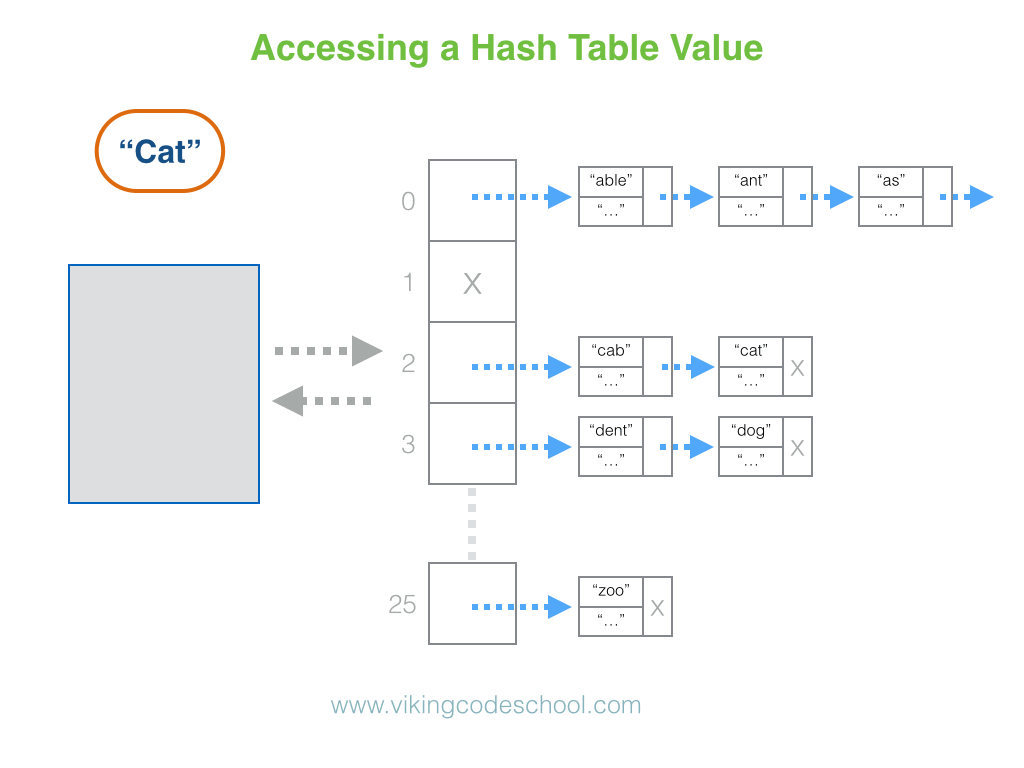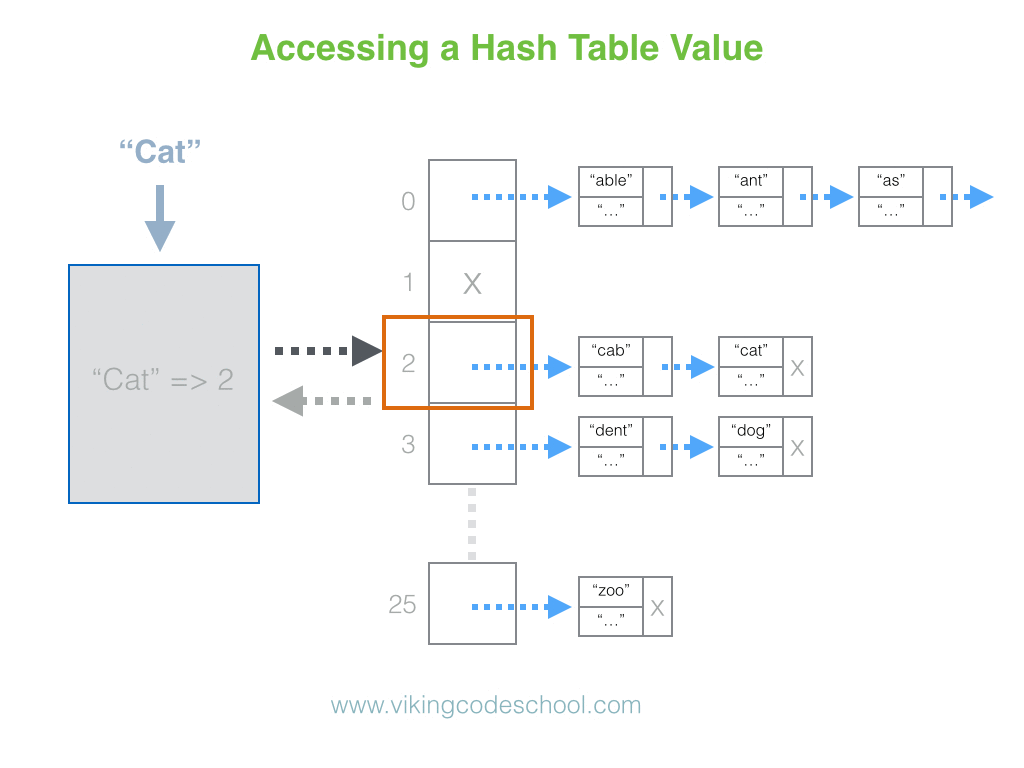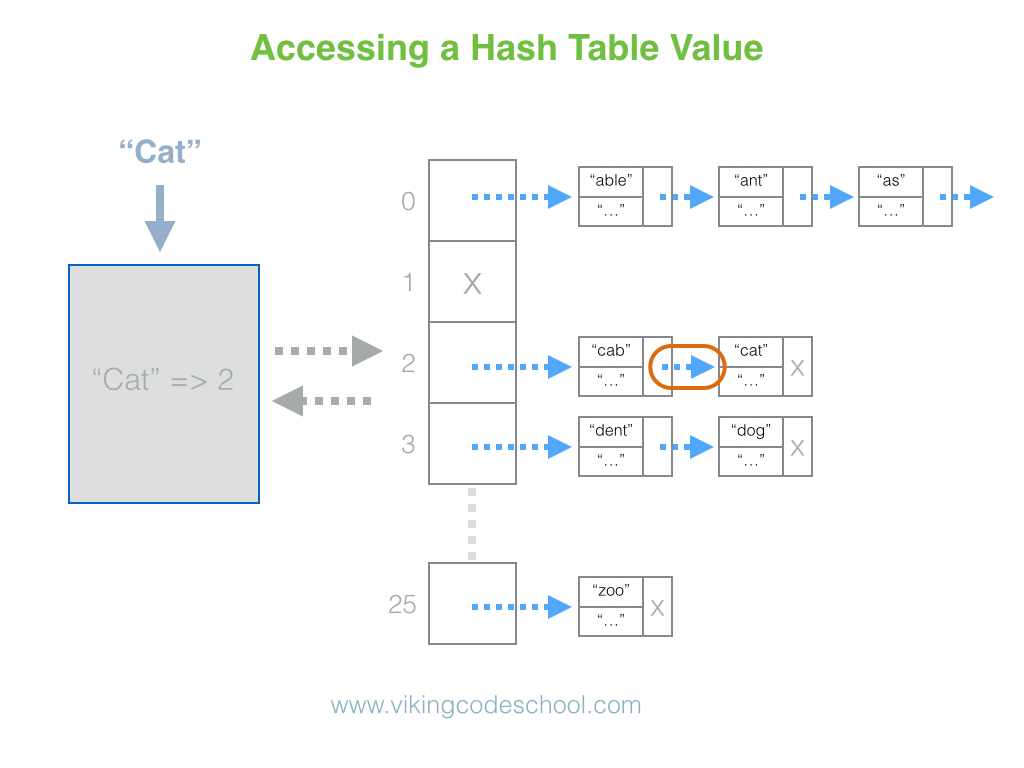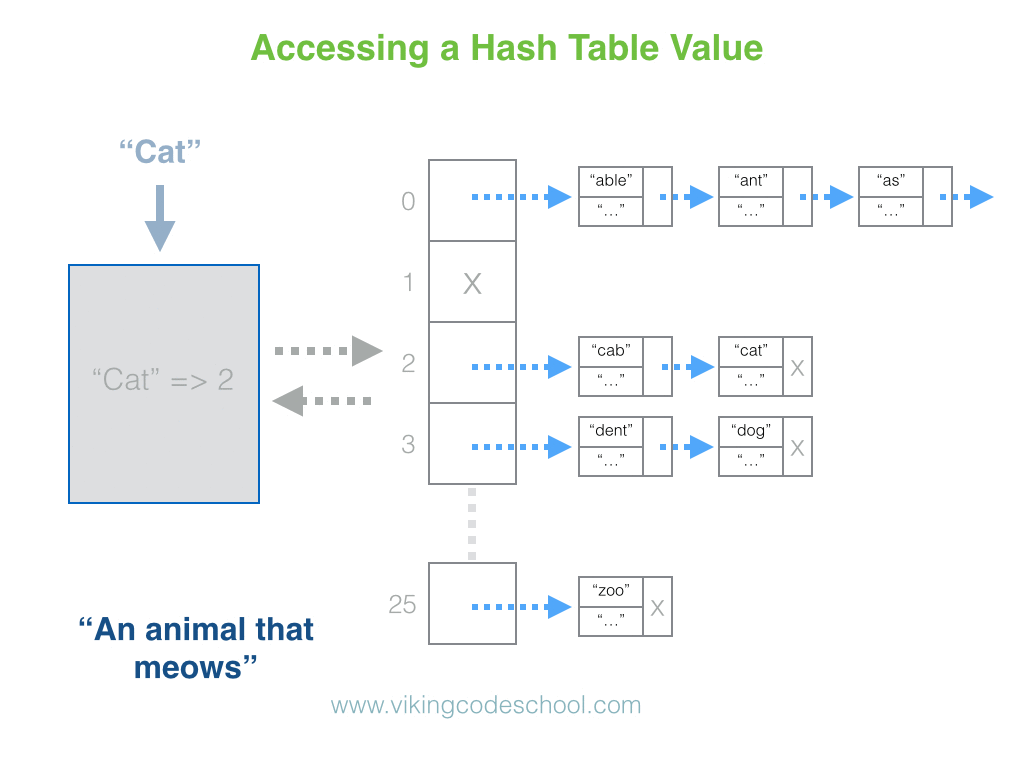
Definition
A Hash Table (Hash Map) is a data structure used to implement an associative array, a structure that can map keys to values. A Hash Table uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found. From Wikipedia
Hash Tables are considered the more efficient data structure for lookup and for this reason, they are widely used.
Complexity
Average
Access Search Insertion Deletion
- O(1) O(1) O(1)
The code
Note, here I am storing another object for every hash in my Hash Table.
The Set
Sets
Sets are pretty much what it sounds like. It’s the same intuition as Set in Mathematics. I visualize Sets as Venn Diagrams.

Definition
A Set is an abstract data type that can store certain values, without any particular order, and no repeated values. It is a computer implementation of the mathematical concept of a finite Set. From Wikipedia
The Set data structure is usually used to test whether elements belong to set of values. Rather then only containing elements, Sets are more used to perform operations on multiple values at once with methods such as union, intersect, etc…
Complexity
Average
Access Search Insertion Deletion
- O(n) O(n) O(n)
The code
The Singly Linked List

Definition
A Singly Linked List is a linear collection of data elements, called nodes pointing to the next node by means of pointer. It is a data structure consisting of a group of nodes which together represent a sequence. Under the simplest form, each node is composed of data and a reference (in other words, a link) to the next node in the sequence.
Linked Lists are among the simplest and most common data structures because it allows for efficient insertion or removal of elements from any position in the sequence.
Complexity
Average
Access Search Insertion Deletion
O(n) O(n) O(1) O(1)
The code
The Doubly Linked List

Definition
A Doubly Linked List is a linked data structure that consists of a set of sequentially linked records called nodes. Each node contains two fields, called links, that are references to the previous and to the next node in the sequence of nodes. From Wikipedia
Having two node links allow traversal in either direction but adding or removing a node in a doubly linked list requires changing more links than the same operations on a Singly Linked List.
Complexity
Average
Access Search Insertion Deletion
O(n) O(n) O(1) O(1)
The code
The Stack

Definition
A Stack is an abstract data type that serves as a collection of elements, with two principal operations: push, which adds an element to the collection, and pop, which removes the most recently added element that was not yet removed. The order in which elements come off a Stack gives rise to its alternative name, LIFO (for last in, first out). From Wikipedia
A Stack often has a third method peek which allows to check the last pushed element without popping it.
Complexity
Average
Access Search Insertion Deletion
O(n) O(n) O(1) O(1)
The code
The Queue

Definition
A Queue is a particular kind of abstract data type or collection in which the entities in the collection are kept in order and the principal operations are the addition of entities to the rear terminal position, known as enqueue, and removal of entities from the front terminal position, known as dequeue. This makes the Queue a First-In-First-Out (FIFO) data structure. In a FIFO data structure, the first element added to the Queue will be the first one to be removed.
As for the Stack data structure, a peek operation is often added to the Queue data structure. It returns the value of the front element without dequeuing it.
Complexity
Average
Access Search Insertion Deletion
O(n) O(n) O(1) O(n)
The code
The Tree
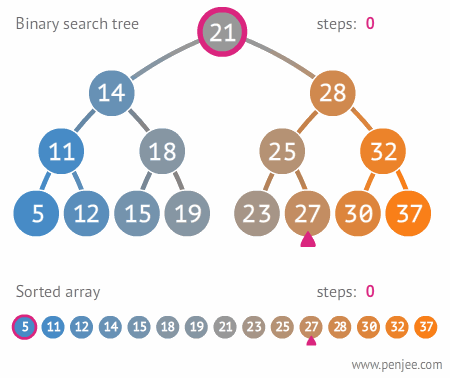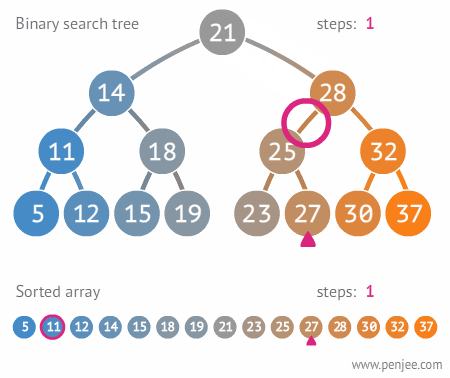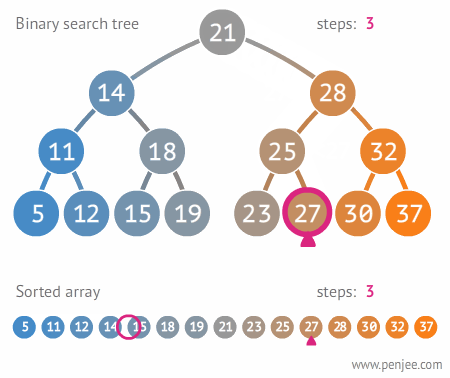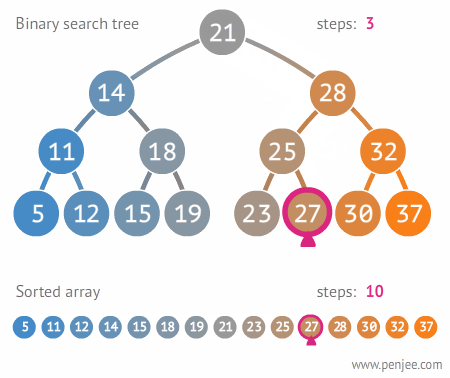
Definition
A Tree is a widely used data structure that simulates a hierarchical tree structure, with a root value and subtrees of children with a parent node. A tree data structure can be defined recursively as a collection of nodes (starting at a root node), where each node is a data structure consisting of a value, together with a list of references to nodes (the “children”), with the constraints that no reference is duplicated, and none points to the root node. From Wikipedia
Complexity
Average
Access Search Insertion Deletion
O(n) O(n) O(n) O(n)
To get a full overview of the time and space complexity of the Tree data structure, have a look to this excellent Big O cheat sheet.

The code
The Graph

Definition
A Graph data structure consists of a finite (and possibly mutable) set of vertices or nodes or points, together with a set of unordered pairs of these vertices for an undirected Graph or a set of ordered pairs for a directed Graph. These pairs are known as edges, arcs, or lines for an undirected Graph and as arrows, directed edges, directed arcs, or directed lines for a directed Graph. The vertices may be part of the Graph structure, or may be external entities represented by integer indices or references.
- A graph is any collection of nodes and edges.
- Much more relaxed in structure than a tree.
- It doesn’t need to have a root node (not every node needs to be accessible from a single node)
- It can have cycles (a group of nodes whose paths begin and end at the same node)
- Cycles are not always “isolated”, they can be one part of a larger graph. You can detect them by starting your search on a specific node and finding a path that takes you back to that same node.
- Any number of edges may leave a given node
- A Path is a sequence of nodes on a graph
Cycle Visual

A Graph data structure may also associate to each edge some edge value, such as a symbolic label or a numeric attribute (cost, capacity, length, etc.).
Representation
There are different ways of representing a graph, each of them with its own advantages and disadvantages. Here are the main 2:
Adjacency list: For every vertex a list of adjacent vertices is stored. This can be viewed as storing the list of edges. This data structure allows the storage of additional data on the vertices and edges.
Adjacency matrix: Data are stored in a two-dimensional matrix, in which the rows represent source vertices and columns represent destination vertices. The data on the edges and vertices must be stored externally.
Graph
The code
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
Or Checkout my personal Resource Site:
CODEX
VSCode Extensions that are indispensable in JavaScript development
Back and Forth
- Adds backwards and forwards buttons to the toolbar in VSCode
- https://marketplace.visualstudio.com/items?itemName=nick-rudenko.back-n-forth
Bracket Pair Colorizer 2
- Colors matching brackets so it’s easier to tell which brackets match.
- https://marketplace.visualstudio.com/items?itemName=CoenraadS.bracket-pair-colorizer-2

Babel Javascript
- A better syntax highlighter for JavaScript code
- https://marketplace.visualstudio.com/items?itemName=mgmcdermott.vscode-language-babel
Code Runner
- Puts a “Play” button in your toolbar and let’s you run code files by pressing it.
- https://marketplace.visualstudio.com/items?itemName=formulahendry.code-runner
Code Runner
Run code snippet or code file for multiple languages: C, C++, Java, JavaScript, PHP, Python, Perl, Perl 6, Ruby, Go, Lua, Groovy, PowerShell, BAT/CMD, BASH/SH, F# Script, F# (.NET Core), C# Script, C# (.NET Core), VBScript, TypeScript, CoffeeScript, Scala, Swift, Julia, Crystal, OCaml Script, R, AppleScript, Elixir, Visual Basic .NET, Clojure, Haxe, Objective-C, Rust, Racket, Scheme, AutoHotkey, AutoIt, Kotlin, Dart, Free Pascal, Haskell, Nim, D, Lisp, Kit, V, SCSS, Sass, CUDA, Less, Fortran, and custom command
Features
Run code file of current active Text Editor
Run code file through context menu of file explorer
Run selected code snippet in Text Editor
Run code per Shebang
Run code per filename glob
Run custom command
Stop code running
View output in Output Window
Set default language to run
Select language to run
Support REPL by running code in Integrated Terminal
Usages
To run code:
- use shortcut
Ctrl+Alt+N - or press
F1and then select/typeRun Code, - or right click the Text Editor and then click
Run Codein editor context menu - or click
Run Codebutton in editor title menu - or click
Run Codebutton in context menu of file explorer - To stop the running code:
- use shortcut
Ctrl+Alt+M - or press
F1and then select/typeStop Code Run - or right click the Output Channel and then click
Stop Code Runin context menu
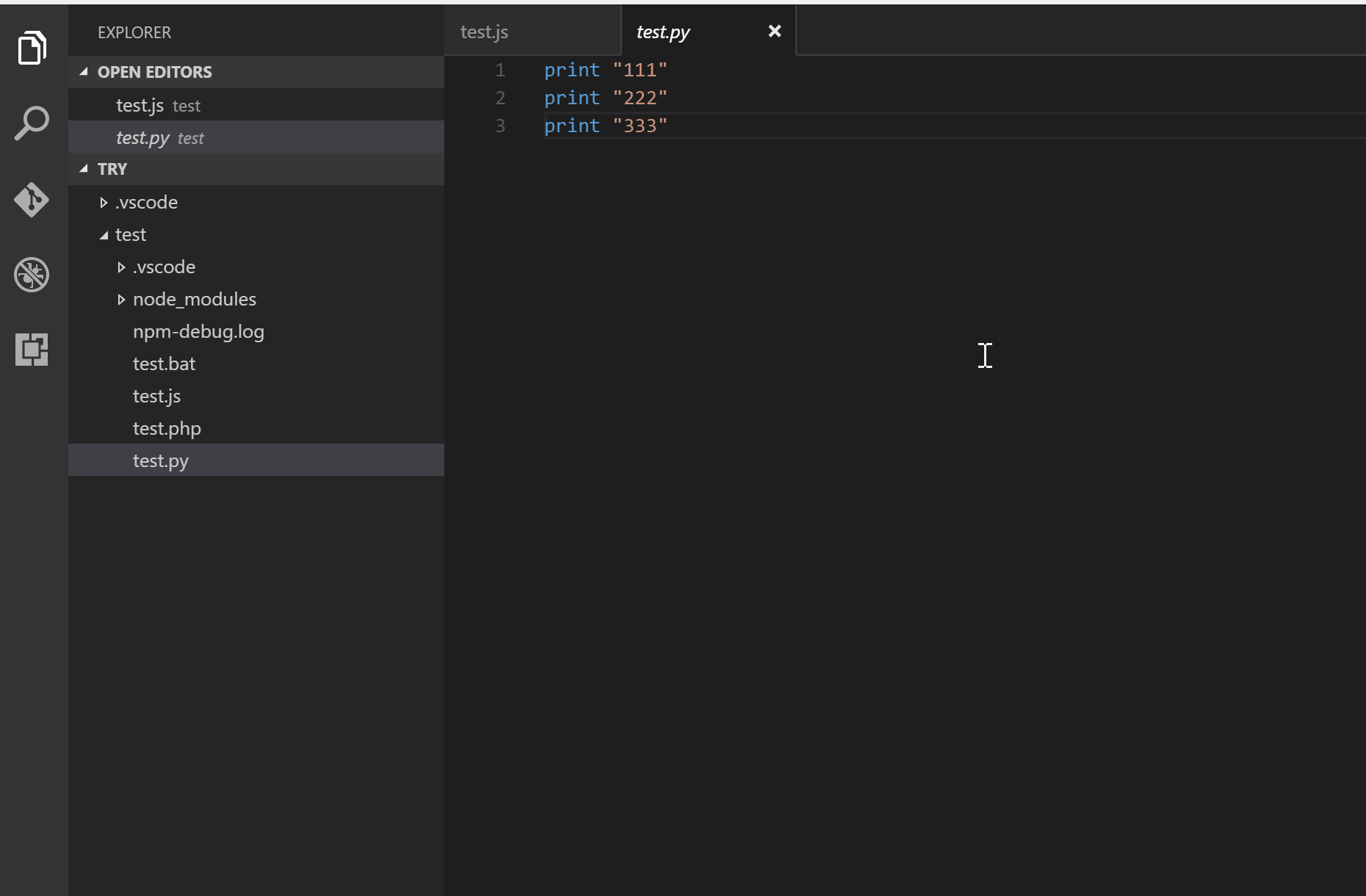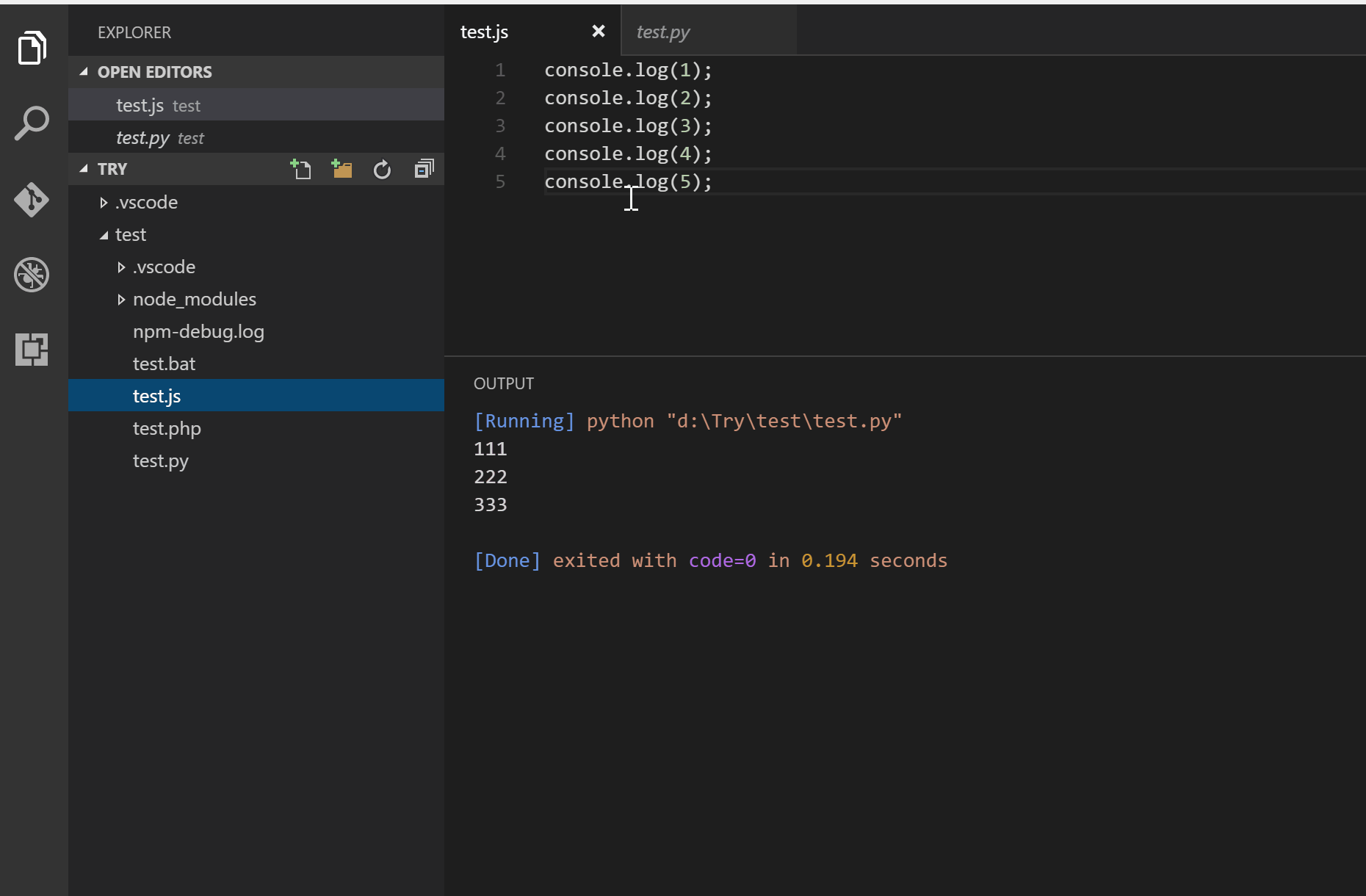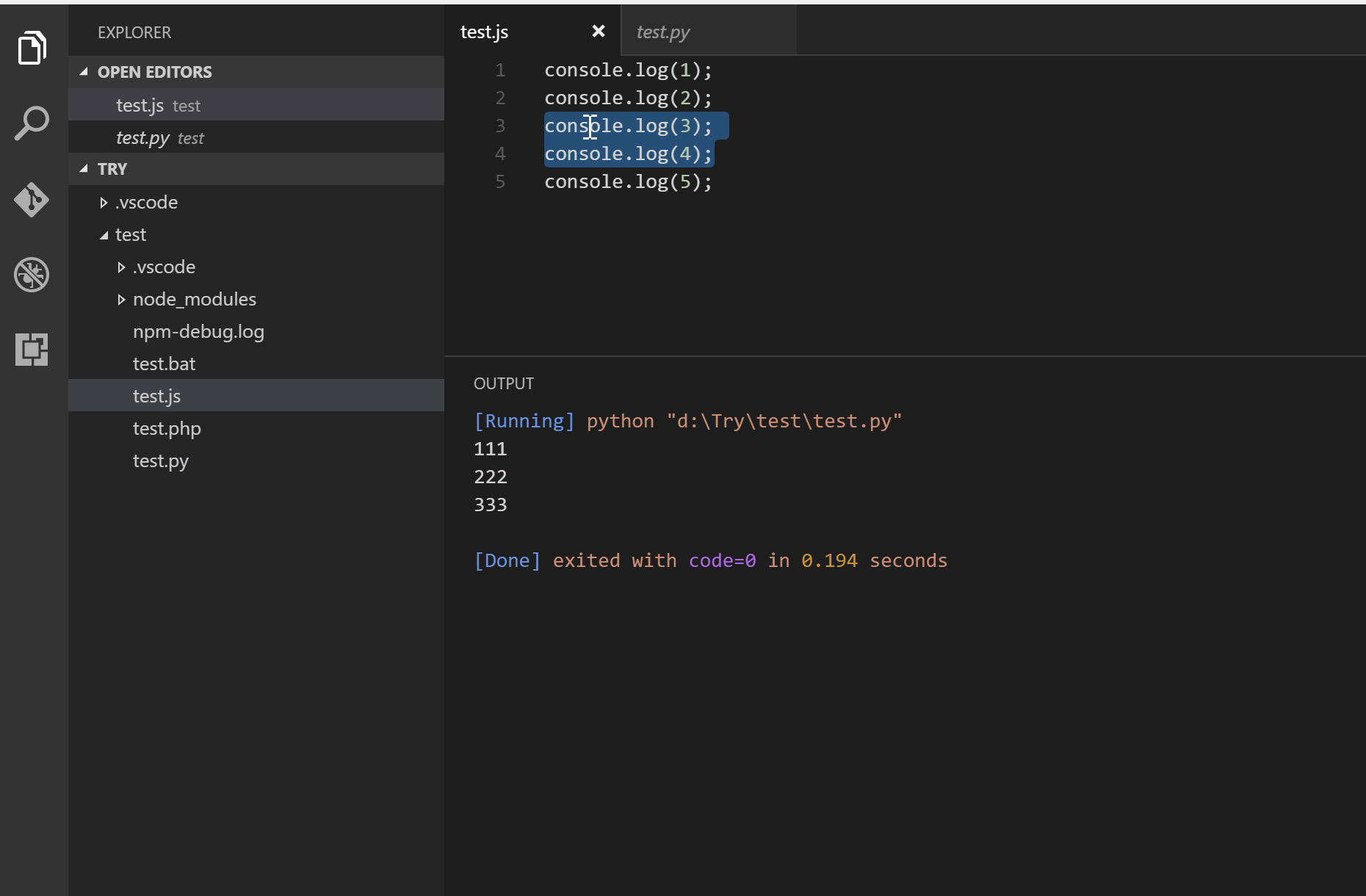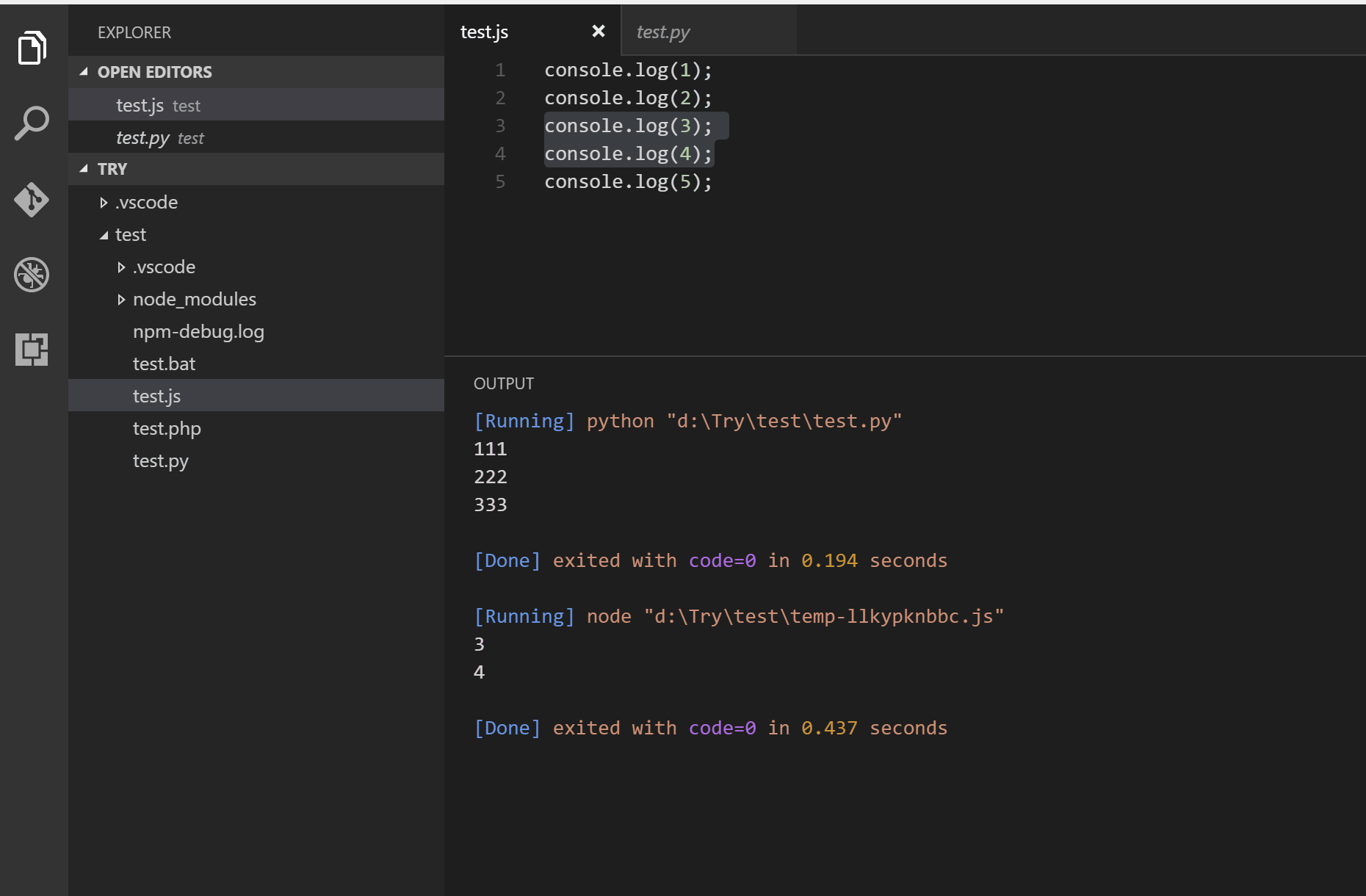
- To select language to run, use shortcut
Ctrl+Alt+J, or pressF1and then select/typeRun By Language, then type or select the language to run: e.gphp, javascript, bat, shellscript...
- To run custom command, then use shortcut
Ctrl+Alt+K, or pressF1and then select/typeRun Custom Command
Color Highlight
- Changes the background color of hex colors in your code to show you what color it actually is
- https://marketplace.visualstudio.com/items?itemName=naumovs.color-highlight
Git Graph
- Shows you a graphical representation of your git branches and commits
- https://marketplace.visualstudio.com/items?itemName=mhutchie.git-graph
GitLens
- Adds tons of cool features to vscode, like viewing commits inline inside the editor
- https://marketplace.visualstudio.com/items?itemName=eamodio.gitlens
Here are just some of the features that GitLens provides,
- effortless revision navigation (backwards and forwards) through the history of a file
- an unobtrusive current line blame annotation at the end of the line showing the commit and author who last modified the line, with more detailed blame information accessible on hover
- authorship code lens showing the most recent commit and number of authors at the top of files and/or on code blocks
- a status bar blame annotation showing the commit and author who last modified the current line
- on-demand file annotations in the editor gutter, including
- blame — shows the commit and author who last modified each line of a file
- changes — highlights any local (unpublished) changes or lines changed by the most recent commit
- heatmap — shows how recently lines were changed, relative to all the other changes in the file and to now (hot vs. cold)
- many rich Side Bar views
- a Commits view to visualize, explore, and manage Git commits
- a Repositories view to visualize, explore, and manage Git repositories
- a File History view to visualize, navigate, and explore the revision history of the current file or just the selected lines of the current file
- a Line History view to visualize, navigate, and explore the revision history of the selected lines of the current file
- a Branches view to visualize, explore, and manage Git branches
- a Remotes view to visualize, explore, and manage Git remotes and remote branches
- a Stashes view to visualize, explore, and manage Git stashes
- a Tags view to visualize, explore, and manage Git tags
- a Contributors view to visualize, navigate, and explore contributors
- a Search & Compare view to search and explore commit histories by message, author, files, id, etc, or visualize comparisons between branches, tags, commits, and more
- a Git Command Palette to provide guided (step-by-step) access to many common Git commands, as well as quick access to
- commits — history and search
- stashes
- status — current branch and working tree status
- a user-friendly interactive rebase editor to easily configure an interactive rebase session
- terminal links —
ctrl+clickon autolinks in the integrated terminal to quickly jump to more details for commits, branches, tags, and more - rich remote provider integrations — GitHub, GitLab, Bitbucket, Azure DevOps
- issue and pull request auto-linking
- rich hover information provided for linked issues and pull requests (GitHub only)
- associates pull requests with branches and commits (GitHub only)
- many powerful commands for navigating and comparing revisions, and more
- user-defined modes for quickly toggling between sets of settings
- and so much more

Features
Revision Navigation
Markdown All in One
- Everything you need to help you write markdown files in VSCode
- https://marketplace.visualstudio.com/items?itemName=yzhang.markdown-all-in-one
Features
Keyboard shortcuts

(Typo: multiple words)

See full key binding list in the keyboard shortcuts section
Table of contents
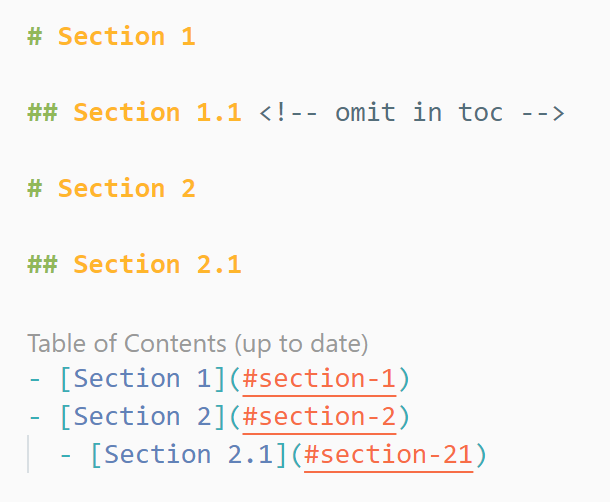
- Run command “Create Table of Contents” to insert a new table of contents.
- The TOC is automatically updated on file save by default. To disable, please change the
toc.updateOnSaveoption. - The indentation type (tab or spaces) of TOC can be configured per file. Find the setting in the right bottom corner of VS Code’s status bar.
- Note: Be sure to also check the
list.indentationSizeoption. - To make TOC compatible with GitHub or GitLab, set option
slugifyModeaccordingly - Three ways to control which headings are present in the TOC:
- Click to expand
- Easily add/update/remove section numbering
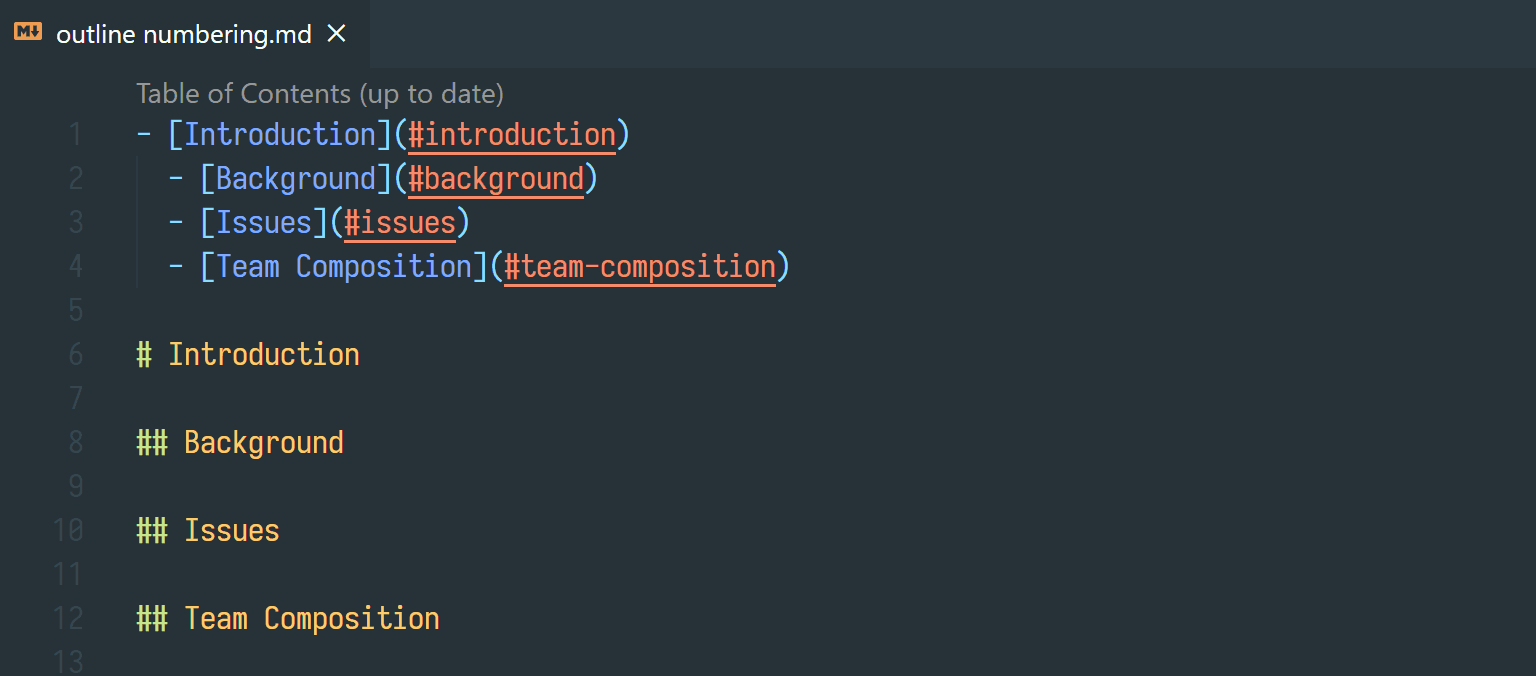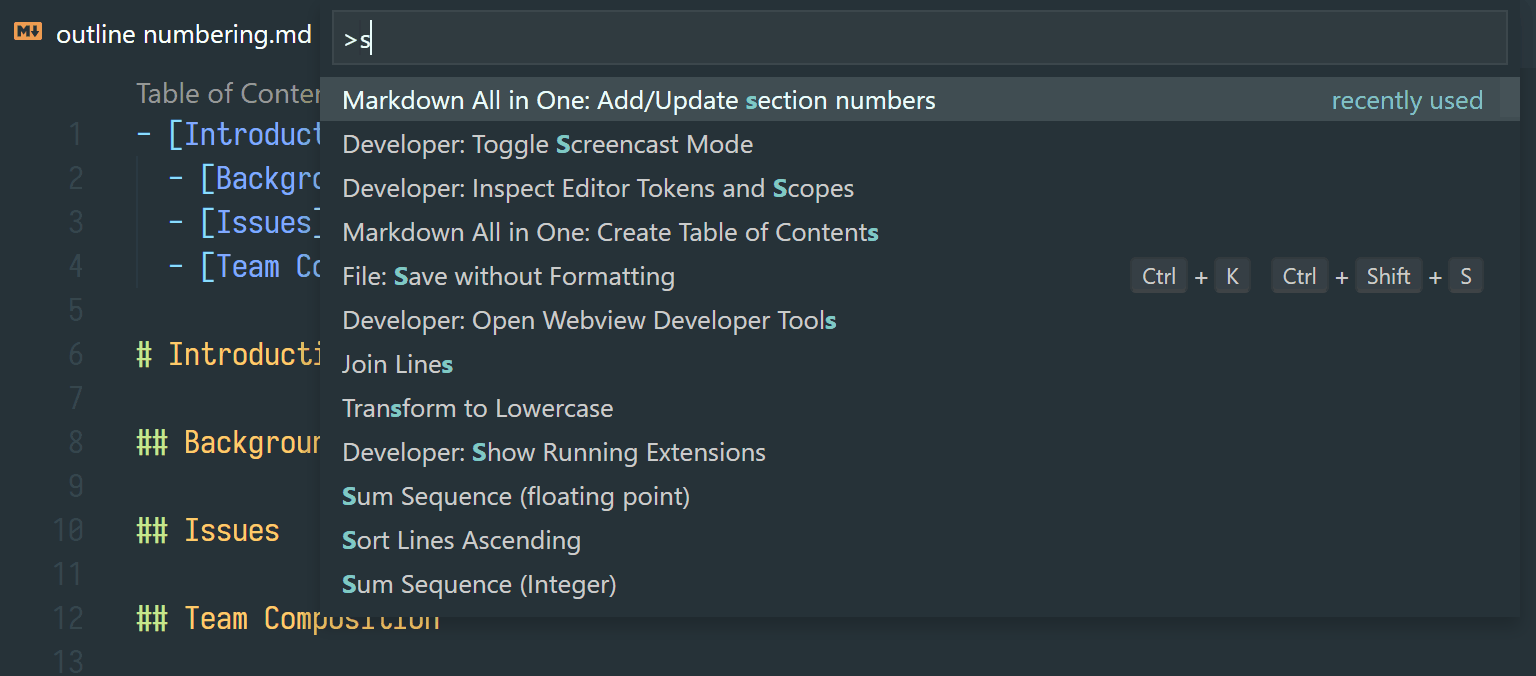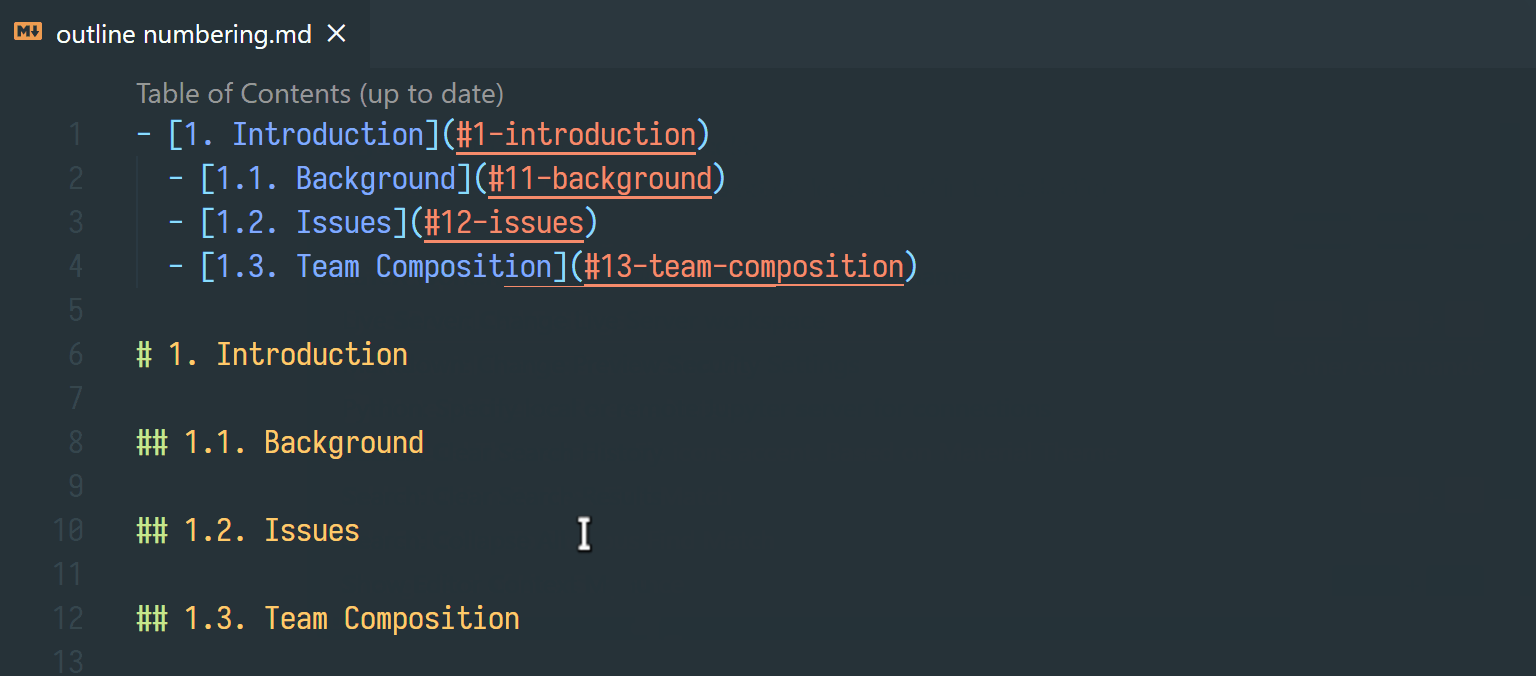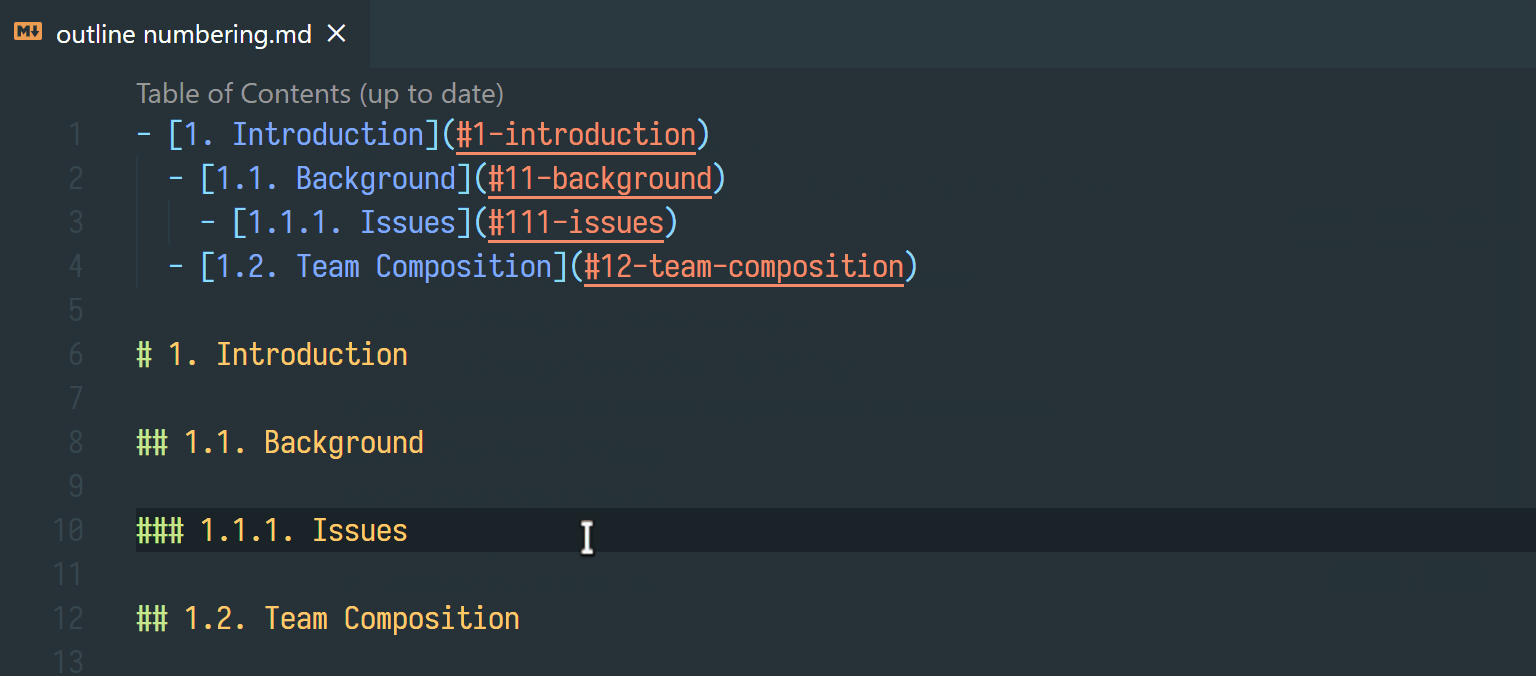
- In case you are seeing unexpected TOC recognition, you can add a
_<!-- no toc -->_comment above the list.
List editing
Note: By default, this extension tries to determine indentation size for different lists according to CommonMark Spec. If you prefer to use a fixed tab size, please change the list.indentationSize setting.
Print Markdown to HTML
- Commands
Markdown: Print current document to HTMLandMarkdown: Print documents to HTML(batch mode) - Compatible with other installed Markdown plugins (e.g. Markdown Footnotes) The exported HTML should look the same as inside VSCode.
- Use comment
<!-- title: Your Title -->to specify a title of the exported HTML. - Plain links to
.mdfiles will be converted to.html. - It’s recommended to print the exported HTML to PDF with browser (e.g. Chrome) if you want to share your documents with others.
GitHub Flavored Markdown
- Table formatter
- Note: The key binding is Ctrl + Shift + I on Linux. See Visual Studio Code Key Bindings.
- Task lists
Math

Please use Markdown+Math for dedicated math support. Be sure to disable math.enabled option of this extension.
Auto completions
Tip: also support the option completion.root
- Images/Files (respects option
search.exclude)
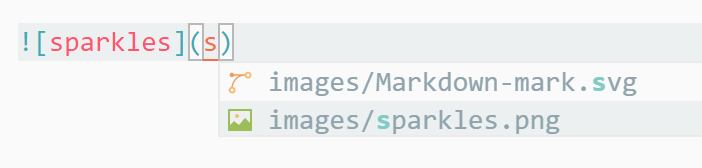
- Math functions (including option
katex.macros)
Mocah Test Explorer
- Lets you run mocha tests in the VSCode sidebar
- https://marketplace.visualstudio.com/items?itemName=hbenl.vscode-mocha-test-adapter
Features
Import command
{ "npm-intellisense.importES6": true, "npm-intellisense.importQuotes": "'", "npm-intellisense.importLinebreak": ";\r\n", "npm-intellisense.importDeclarationType": "const",}
Import command (ES5)
{ "npm-intellisense.importES6": false, "npm-intellisense.importQuotes": "'", "npm-intellisense.importLinebreak": ";\r\n", "npm-intellisense.importDeclarationType": "const",}
NPM Intellisense
- Autocomlpetes npm module names when you are typing require or import.
- https://marketplace.visualstudio.com/items?itemName=christian-kohler.npm-intellisense
Features
Import command
{ "npm-intellisense.importES6": true, "npm-intellisense.importQuotes": "'", "npm-intellisense.importLinebreak": ";\r\n", "npm-intellisense.importDeclarationType": "const",}
Import command (ES5)
{ "npm-intellisense.importES6": false, "npm-intellisense.importQuotes": "'", "npm-intellisense.importLinebreak": ";\r\n", "npm-intellisense.importDeclarationType": "const",}
Scan devDependencies
Npm intellisense scans only dependencies by default. Set scanDevDependencies to true to enable it for devDependencies too.
{ "npm-intellisense.scanDevDependencies": true,}
Path Intellisense
- Auto completes filesystem paths when you are typing them
- https://marketplace.visualstudio.com/items?itemName=christian-kohler.path-intellisense
Usage
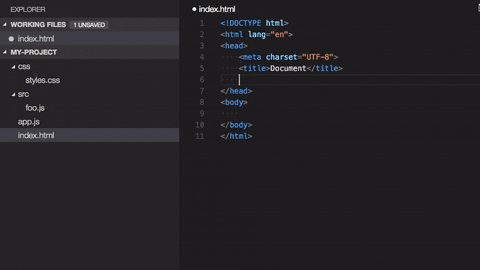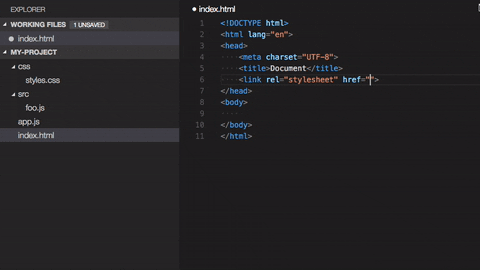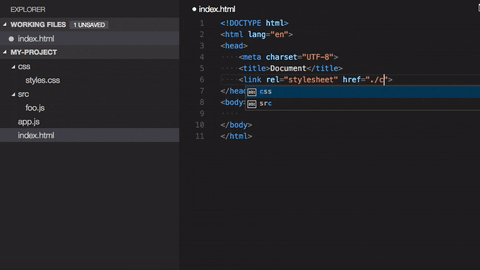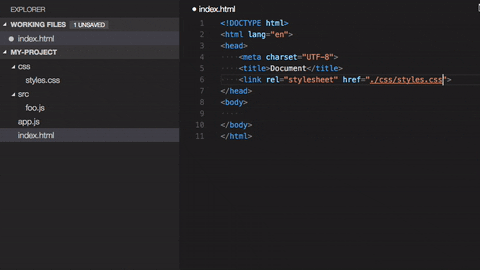
Commerical Extensions
Quokka.js
- A paid extension that does amazing things by showing the results of your javascript inline inside the editor window
- https://marketplace.visualstudio.com/items?itemName=WallabyJs.quokka-vscode
Quokka.js Visual Studio Code Extension
Quokka.js is a developer productivity tool for rapid JavaScript / TypeScript prototyping. Runtime values are updated and displayed in your IDE next to your code, as you type.

If you found this guide helpful feel free to checkout my other articles:
https://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5b
OR GitHub/gists where I host similar content:
https://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5bhttps://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5b
Or Checkout my personal Resource Site:
https://bryanguner.medium.com/a-list-of-all-of-my-articles-to-link-to-future-posts-1f6f88ebdf5b
CODEX
This installment is going to be the least technically demanding thus far however these questions are a more realistic reflection on what a junior developer could be asked by a company with reasonable hiring practices…

… Speaking of which … stay tuned till the end of the article or skip down to it for a list of web development companies with reportedly fair hiring practices!
Here’s parts one and two; they’re both much more technical in nature than this one!
View at Medium.comView at Medium.com
 Behavioral & Cultural Interview Questions
Behavioral & Cultural Interview Questions
Software engineer interviewers ask behavioral/cultural questions to evaluate interviewee’s soft skills, and also to decide whether the candidate is a cultural fit. Make sure you’ve prepared great answers to these interview questions.
Tell me about yourself

What are some side projects you’re currently working on?
Current Experience
Past Experience
Now it’s time to highlight your skills a little:
Future Expectations
How you strike a balance between multiple ongoing projects
Describe one or two instances where you had several projects running simultaneously and how you managed to prioritize different tasks, make progress, meet milestones, and work on iterations based on feedback.
Professional Skills
For the second question, showcase your excitement for the job. Hiring managers want to see your excitement for these reasons:
Commitment to the company
Why should we hire you?
 Interview Etiquette & Other Tips
Interview Etiquette & Other Tips
Nailing an interview takes more than just knowing how to answer common interview questions. You’ll also need to prepare questions of your own, think about salary, and get your communications right. Here’s how.
Questions to ask in an interview
⮕As the job seeker, it’s normal to feel like you’re being interrogated during interviews. However, at its core, an interview is a conversation, and should be a two-way interaction. As the interviewee, you need to stay engaged and ask thoughtful questions.
⮕By asking questions, you’re expressing your genuine curiosity towards the company. This helps companies know that you’re serious about them. Additionally, it also helps you evaluate whether the job and/or the company is really what you’re looking for.
⮕There are fantastic resources out there with more than a dozen questions you can ask interviewers. Here, we’ll provide a few that we think are essential to help you gain deeper understandings about the role, company, and your future within the company:
⮕The job and cross-team communication
⮕The company’s values and working culture
⮕What are some shared qualities and characteristics among your employees?
⮕What’s your favorite part about working at the company?
⮕What’s your least favorite part about working at the company?
Professional growth opportunities
⮕Are there multiple product/service teams in the company? Can engineers apply to join a different team? What does the process look like?
⮕Are there professional development courses and training available?
⮕Do senior engineers and engineering leads usually get promoted from within the company?
Closing questions and next steps
Follow up ?????
Thank you email
A thank you email should be sent out on the same day of the interview or one day after your interview. The main purpose of this email is to show your excitement and appreciation. This email should be short and sweet and should include:
A thank you note for their time
⮕A brief mention of the specific job you interviewed for
⮕A brief note of what you found most impressive about the company
⮕One or two things you learned about the organization
⮕One sentence about how you’re excited you are to contribute in a specific way

Technical interview :
⮕questions examine a candidate’s thought processes and assess what approaches they adopt to solve problems. The most common end-to-end software development questions are listed below.
Here’s the repo that I use to practice my technical chops for interviews:
1. Development
2. Based on your experience in this project, specify your favorite and least favorite part of this type of collaboration.
Remember to keep positive because the interviewers are always looking for constructive answers.
3. Based on the project, what programming languages / tools / services did you use? And why did you choose them?
To begin with, give an example of a project in which you had the most ownership or you had the greatest sense of achievement/efficiency/effectiveness from the toolchain used.
4. Describe the biggest toolchain-related challenge you encountered in the project:
5. How would you design this system for scale?
6. Testing: What is your process to test a code when developing a software or application? How do you decide the scope of your test case?
Monitoring
7. What kind of tools / services do you use for logging? What kind of data will you log? And what’s the next step when you get the log?
What to avoid
_
NOW; Here’s some for you guys to answer in the comments!
8. Which logging services have you researched and used before?
9. Why did you choose or look into each particular logging service?
10. Was your decision because of the scale, the features, or the size of the community?
11. In what scenarios did you check these logs? Was it scheduled daily/weekly/monthly or as an on-demand activity?
12. What information would the data be transformed into? Was it for development, business, or customer decision-making?
13. What information would the data be transformed into? Was it for development, business, or customer decision-making?
https://gist.github.com/bgoonz/15a638abb3b4026abc8e5ca05f8d90f1
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
View at Medium.comView at Medium.com
Or Checkout my personal Resource Site:
Translation if you read this today (3/21/2021) it will be exceedingly short… because it’s just gonna accumulate entries as I learn of them over time.

1.) Stack Overflow for Teams is now free forever for up to 50 users
2.) https://webflow.com/
A plethora of front-end code playgrounds have appeared over the years. They offer a convenient way to experiment with client-side code and teach/share with others without the hassle of configuring a development environment.
Typical features of these online playgrounds include:
- color-coded HTML, CSS and JavaScript editors
- a preview window — many update on the fly without a refresh
- HTML pre-processors such as HAML
- LESS, SASS and Stylus CSS pre-processing
- inclusion of popular JavaScript libraries
- developer consoles and code validation tools
- sharing via a short URL
- embedding demonstrations in other pages
- code forking
- zero cost (or payment for premium services only)
- showing off your coding skills to the world!
The following list is in no particular order and which playground you use is a matter of application and personal taste, they each have their own specialities.
1.) REPL.IT
My personal favorite for it’s simplicity, versatility and capabilities.
No downloads, no configs, no setups
In your browser. Repl.it runs fully in your browser, so you can get started coding in seconds. No more ZIPs, PKGs, DMGs and WTFs.
Any OS, any device(I’m looking at you chromebook coders). You can use Repl.it on macOS, Windows, Linux, or any other OS .
Clone, commit and push to any GitHub repo.
Repl from Repo. Get started with any Github repo, right from your browser. Commit and push without touching your terminal.
Markdown Preview
>A new but fundamentally important feature
No-setup Unit Testing
>Unit testing is a powerful way to verify that code works as intended and creates a quick feedback loop for development & learning. However, setting up a reproducible unit-testing environment is a time-consuming and delicate affair. Repl.it now features zero-setup unit testing!
HTTPS by default
In the example below I have 72 solved Javascript Leetcode Problems but REPL.IT can handle almost any language you can think of.
https://repl.it/@bgoonz/leetcode-level-1
Here’s another one that contains the Repl.it Docs:
https://replit.com/@bgoonz/replit-docs-1#curriculum/introHTMLCSS.md
JS-Fiddle
jsFiddle is a cloud-based JavaScript code playground that allows web developers to tweak their code and see the results of this tweaking in real time. The editor supports not only JavaScript and its variants but also HTML and CSS code, and it further supports popular JavaScript frameworks, such as jQuery, AngularJS, ReactiveJS and D3. The ad-supported site is also completely free to use.
Entering and running code
JSFiddle has the notion of panels (or tabs if you switch into the tabbed layout), there are 4 panels, 3 where you can enter code, and 1 to see the result.
- HTML — structure code, no need to add
bodydoctypehead, that’s added automatically - CSS — styles. You can switch pre-pocessor to SCSS
- JavaScript — behavior. There are many frameworks and code pre-processors you can use
Once you enter code, just hit Run in the top actions bar, and the fourth panel with results will appear.
Saving and Forking code
- Save / Update will do what you think, it’ll save a new fiddle or update an existing one (and add a version number to it)
- Fork will split out an existing fiddle into a new one, starting with version 0
https://jsfiddle.net/bgoonz/L6082jrs/2/
StackBlitz
Dependencies still slip into the install process as dev & sub-dependencies and are downloaded & extracted all the same, resulting in the infamous black hole known as
node_modules:

Dank, relevant meme (pictured Left)
This is the crux of what prevents NPM from working natively in-browser. Resolving, downloading, and extracting the hundreds of megabytes (or gigabytes) typical frontend projects contain in their **node_modules** folder is a challenge browsers just aren’t well suited for. Additionally, this is also why existing server side solutions to this problem have proven to be slow, unreliable

Then just paste the embed code in an iframe and you’re good to go!
On StackBlitz.com, you can create new projects and get the embed code from the ‘Share’ dropdown link in the top navigation like so:
Embed Options

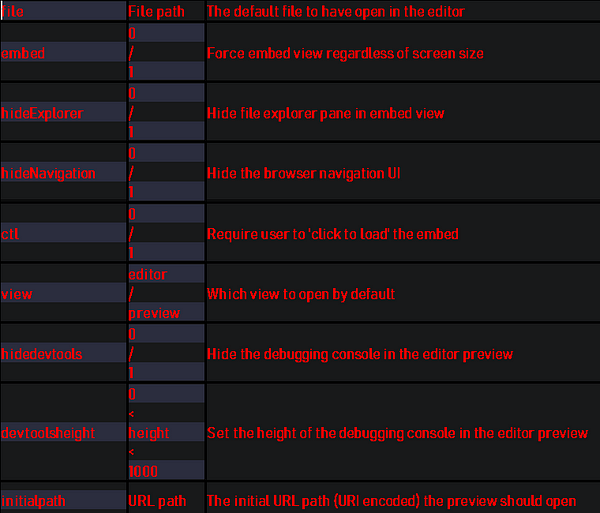
🡩 Alternatively, you can also use StackBlitz’s Javascript SDK methods for easily embedding StackBlitz projects on the page & avoid all the hassles of creating/configuring iframes.
Here’s a sample project of mine, it’s a medium clone… (So Metta)… feel free to write a post… or don’t …but either way … as you can see… Stack Blitz enables you to write serious web applications in a fraction of the time it would take with a conventional setup.
Glitch
Glitch provides two project templates that you can use to start creating your app:
- Classic Website
- Node.js
If you know the type of project that you would like to create, click here to get started! Or keep reading to learn more about the Classic Website and Node.js templates.
Classic Website

The Classic Website template is your starting point for creating a static website that includes an index.html page and static HTML, JavaScript, and CSS. Just start typing and your work will be live on the internet! Static websites enjoy unlimited uptime too! This means that your website stays on 24/7 without using your Project Hours.
An existing project will be identified by Glitch as a static site if it does not contain one of the following files:
- package.json
- requirements.txt
- glitch.json
Node.js
If you are looking to build a full-stack JavaScript application, choose the Node.js template. This template includes both front-end and back-end code using the popular Express Node.js application framework.
Here are some other ways to get started on Glitch…

- Create an app by importing a GitHub repo.
- Build an app that integrates with a popular third-party platform or framework, by remixing one of these starter templates.
Still not sure where to start? Check out these categories of community-built apps for inspiration:
Here’s a (temporarily) broken version of my personal portfolio .. hosted on glitch
Click ‘view app’ below to see how it renders
https://glitch.com/edit/#!/yielding-auspicious-periwinkle?path=README.md%3A1%3A0
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://gist.github.com/bgoonzhttps://gist.github.com/bgoonz
Or Checkout my personal Resource Site:
https://gist.github.com/bgoonz
CODEX
These will focus more on vocabulary and concepts than the application-driven approach in my last post!

Here’s part one for reference:
https://bryanguner.medium.com/the-web-developers-technical-interview-e347d7db3822
- If you were to describe semantic HTML to the next cohort of students, what would you say?
Semantic HTML is markup that conveys meaning, not appearance, to search engines to make everything easier to identify.
- Name two big differences between display: block; and display: inline;.
block starts on a new line and takes up the full width of the content.
inline starts on the same line as previous content, in line with other content, and takes up only the space needed for the content.
· What are the 4 areas of the box model?
content, padding, border, margin
· While using flexbox, what axis does the following property work on: align-items: center?
cross-axis
· Explain why git is valuable to a team of developers.
Allows you to dole out tiny pieces of a large project to many developers who can all work towards the same goal on their own chunks, allows roll back if you make a mistake; version control.
· What is the difference between an adaptive website and a fully responsive website?
An adaptive website “adapts” to fit a pre-determined set of screen sizes/devices, and a responsive one changes to fit all devices.
· Describe what it means to be mobile first vs desktop first.
It means you develop/code the site with mobile in mind first and work your way outward in screen size.
· What does font-size: 62.5% in the html tag do for us when using rem units?
This setting makes it so that 1 rem = 10 px for font size, easier to calculate.
· How would you describe preprocessing to someone new to CSS?
Preprocessing is basically a bunch of functions and variables you can use to store CSS settings in different ways that make it easier to code CSS.
· What is your favorite concept in preprocessing? What is the concept that gives you the most trouble?
Favorite is (parametric) mixins; but I don’t have a lot of trouble with preprocessing. What gives me the most trouble is knowing ahead of time what would be good to go in a mixin for a given site.
· Describe the biggest difference between .forEach & .map.
forEach iterates over an array item by item, and map calls a function on each array item, but returns another/additional array, unlike forEach.
· What is the difference between a function and a method?
Every function is an object. If a value is a function, it is a method. Methods have to be ‘received’ by something; functions do not.
· What is closure?
It is code identified elsewhere that we can use later; gives the ability to put functions together. If a variable isn’t defined, a function looks outward for context.
· Describe the four rules of the ‘this’ keyword.
1. Window/global binding — this is the window/console object. ‘use strict’; to prevent window binding.
2. Implicit binding — when a function is called by a dot, the object preceding the dot is the ‘this’. 80 percent of ‘this’ is from this type of binding.
3. New binding — points to new object created & returned by constructor function
4. Explicit binding — whenever call, bind, or apply are used.
· Why do we need super() in an extended class?
Super ties the parent to the child.
- What is the DOM?
Document object model, the ‘window’ or container that holds all the page’s elements
- What is an event?
An event is something happening on or to the page, like a mouse click, doubleclick, key up/down, pointer out of element/over element, things like this. There are tons of “events” that javascript can detect.
- What is an event listener?
Javascript command that ‘listens’ for an event to happen on the page to a given element and then runs a function when that event happens
- Why would we convert a NodeList into an Array?
A NodeList isn’t a real array, so it won’t have access to array methods such as slice or map.
- What is a component?
Reusable pieces of code to display info in a consistent repeatable way
· What is React JS and what problems does it try and solve? Support your answer with concepts introduced in class and from your personal research on the web.
ReactJS is a library used to build large applications. It’s very good at assisting developers in manipulating the DOM element to create rich user experiences. We need a way to off-load the state/data that our apps use, and React helps us do that.
· What does it mean to think in react?
It makes you think about how to organize/build apps a little differently because it’s very scalable and allows you to build huge apps. React’s one-way data flow makes everything modular and fast. You can build apps top-down or bottom-up.
· Describe state.
Some data we want to display.
· Describe props.
Props are like function arguments in JS and attributes in HTML.
· What are side effects, and how do you sync effects in a React component to state or prop changes?
Side effects are anything that affects something outside the executed function’s scope like fetching data from an API, a timer, or logging.
· Explain benefit(s) using client-side routing?
Answer: It’s much more efficient than the traditional way, because a lot of data isn’t being transmitted unnecessarily.
· Why would you use class component over function components (removing hooks from the question)?
Because some companies still use class components and don’t want to switch their millions of dollars’ worth of code over to all functional hooks, and also there’s currently a lot more troubleshooting content out there for classes that isn’t out there for hooks. Also, functional components are better when you don’t need state, presentational components.
· Name three lifecycle methods and their purposes.
componentDidMount = do the stuff inside this ‘function’ after the component mounted
componentDidUpdate = do the stuff inside this function after the component updated
componentWillUnmount = clean-up in death/unmounting phase
· What is the purpose of a custom hook?
allow you to apply non-visual behavior and stateful logic throughout your components by reusing the same hook over and over again
· Why is it important to test our apps?
Gets bugs fixed faster, reduces regression risk, makes you consider/work out the edge cases, acts as documentation, acts as safety net when refactoring, makes code more trustworthy
· What problem does the context API help solve?
You can store data in a context object instead of prop drilling.
· In your own words, describe actions, reducers and the store and their role in Redux. What does each piece do? Why is the store known as a ‘single source of truth’ in a redux application?
Everything that changes within your app is represented by a single JS object called the store. The store contains state for our application. When changes are made to our application state, we never write to our store object but rather clone the state object, modify the clone, and replace the original state with the new copy, never mutating the original object. Reducers are the only place we can update our state. Actions tell our reducers “how” to update the state, and perhaps with what data it should be updated, but only a reducer can actually update the state.
· What is the difference between Application state and Component state? When would be a good time to use one over the other?
App state is global, component state is local. Use component state when you have component-specific variables.
· Describe redux-thunk, what does it allow us to do? How does it change our action-creators?
Redux Thunk is middleware that provides the ability to handle asynchronous operations inside our Action Creators, because reducers are normally synchronous.
· What is your favorite state management system you’ve learned and this sprint? Please explain why!
Redux, because I felt it was easier to understand than the context API.
· Explain what a token is used for.
Many services out in the wild require the client (our React app, for example) to provide proof that it’s authenticated with them. The server running these services can issue a JWT (JSON Web Token) as the authentication token, in exchange for correct login credentials.
· What steps can you take in your web apps to keep your data secure?
As we build our web apps, we will most likely have some “protected” routes — routes that we only want to render if the user has logged in and been authenticated by our server. The way this normally works is we make a login request, sending the server the user’s username and password. The server will check those credentials against what is in the database, and if it can authenticate the user, it will return a token. Once we have this token, we can add two layers of protection to our app. One with protected routes, the other by sending an authentication header with our API calls (as we learned in the above objective).
· Describe how web servers work.
The “world wide web” (which we’ll refer to as “the web”) is just a part of the internet — which is itself a network of interconnected computers. The web is just one way to share data over the internet. It consists of a body of information stored on web servers, ready to be shared across the world. The term “web server” can mean two things:
· a computer that stores the code for a website
· a program that runs on such a computer
The physical computer device that we call a web server is connected to the internet, and stores the code for different websites to be shared across the world at all times. When we load the code for our websites, or web apps, on a server like this, we would say that the server is “hosting” our website/app.
· Which HTTP methods can be mapped to the CRUD acronym that we use when interfacing with APIs/Servers.
Create, Read, Update, Delete
· Mention two parts of Express that you learned about this week.
Routing/router, Middleware, convenience helpers
· Describe Middleware?
array of functions that get executed in the order they are introduced into the server code
· Describe a Resource?
o everything is a resource.
o each resource is accessible via a unique URI.
o resources can have multiple representations.
o communication is done over a stateless protocol (HTTP).
o management of resources is done via HTTP methods.
· What can the API return to help clients know if a request was successful?
200 status code/201 status code
· How can we partition our application into sub-applications?
By dividing the code up into multiple files and ‘requiring’ them in the main server file.
· Explain the difference between Relational Databases and SQL.
SQL is the language used to access a relational database.
· Why do tables need a primary key?
To uniquely identify each record/row.
· What is the name given to a table column that references the primary key on another table.
Foreign key
· What do we need in order to have a many to many relationship between two tables.
An intermediary table that holds foreign keys that reference the primary key on the related tables.
· What is the purpose of using sessions?
The purpose is to persist data across requests.
· What does bcrypt do to help us store passwords in a secure manner?
o password hashing function.
o implements salting both manual and automatically.
o accumulative hashing rounds.
· What does bcrypt do to slow down attackers?
Having an algorithm that hashes the information multiple times (rounds) means an attacker needs to have the hash, know the algorithm used, and how many rounds were used to generate the hash in the first place. So it basically makes it a lot more difficult to get somebody’s password.
· What are the three parts of the JSON Web Token?
Header, payload, signature
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://bryanguner.medium.com/the-web-developers-technical-interview-e347d7db3822https://bryanguner.medium.com/the-web-developers-technical-interview-e347d7db3822
Or Checkout my personal Resource Site:
https://bryanguner.medium.com/the-web-developers-technical-interview-e347d7db3822
Because I compile these things compulsively anyway…

- Ansible
- Awesome Lists
- CI/CD
- Data Science
- Docker
- DynamoDB
- Elasticsearch
- Environment Setups
- Epic Github Repos
- Golang
- Grafana
- Great Blogs
- Knowledge Base
- Kubernetes
- Kubernetes Storage
- Machine Learning
- Monitoring
- MongoDB
- Programming
- Queues
- Self Hosting
- Email Server Setups
- Mailscanner Server Setups
- Serverless
- Sysadmin References
- VPN
- Web Frameworks
Ansible
Awesome Lists
Epic Github Repos
Authentication
Data Science
Grafana
Docker
Deploy Stacks to your Swarm: 

Logging:
Metrics:
- StefanProdan — Prometheus, Grafana, cAdvisor, Node Exporter and Alert Manager
- Mlabouardy — Telegraf, InfluxDB, Chronograf, Kapacitor & Slack
Awesome Docker Repos
RaspberryPi ARM Images:
- arm32v6/alpine:edge
- arm32v6/golang:alpine
- arm32v6/haproxy:alpine
- arm32v6/node:alpine
- arm32v6/openjdk:alpine
- arm32v6/postgres:alpine
- arm32v6/python:2.7-alpine3.6
- arm32v6/python:3.6-alpine3.6
- arm32v6/rabbitmq:alpine
- arm32v6/redis:alpine
- arm32v6/ruby:alpine3.6
- arm32v6/tomcat:alpine
- arm32v6/traefik:latest
- arm32v7/debian:lates
- hypriot/rpi-redis
- jixer/rpi-mongo
- alexellis/armhf
- zeiot: rpi-prometheus stack
- larmog
- Rpi MongoDB
- ARM Swarm
Docker Image Repositories
- Docker Hub: arm32v6
- Docker Hub: armv7
- Github: Luvres Armhf
- Apache/PHP7 on Alpine
- Tomcat on Alpine
- Nginx (jwilder)
- Alpine Images (smebberson)
- SameerSbn
- Linuxserver.io
- Apache-PHP5
- Apache-PHP-Email
Docker-Awesome-Lists
Docker Blogs:
- Whoami used in Traefik Docs
- Sqlite with Docker
- Rails with Postgres and Redis
- Async Tasks with Flask and Redis
- Flask and Postgres
- Elastic Beats on RaspberryPi
Docker Storage
OpenFaas:
Prometheus / Grafana on Swarm:
- StefanProdan — SwarmProm
- Monitoring with Prometheus
- UschtWill — Prometheus Grafana Elastalert
- Chmod-Org Promethus with Blackbox
- Finestructure: Prometheus Tutorial
Logging / Kibana / Beats
Libraries
Frameworks
Continious Integration:
Circle-CI
Concourse
- Setup Concourse Environment with Docker
- Getting Started with Concourse and Docker
- Concourse Gated Pipelines
- Concourse Boilerplate
Jenkins
- Modess — PHP with Jenkins
- CI/CD Nodejs Tutorial with Jenkins
- CI/CD Nodejs Tutorial with Jenkins @medium
- Epic CICD workflow with Jenkins, Gitlab, Sonar, Nexus
SwarmCi
Travis-CI
- Getting Started with Travis-CI (Original Docs)
- Getting Started with Travis-CI (dwyl — nodejs)
- Blog Site with Travis-CI (Python)
- Build Tests with Python on Travis-CI
- Moving app with Travis-CI
LambCI
DynamoDB
DynamoDB Docs
DynamoDB Best Practices
DynamoDB General Info
Elasticsearch
Elasticsearch Documentation
- General Recommendation
- How Many Shards in my Cluster
- Managing Time-Based Indices Efficiently
- Elasticsearch Best Practices (Bonsai.io)
- AWS ES — Scaling up my Domain
Elasticsearch Cheetsheets:
Elasticsearch Blogs
- Maximize Elasticsearch Indexing Performance
- Autoritative Guide to ES Performance Tuning
- Full text Search Queries
- Query Elasticsearch
Elasticsearch Tools
Environment Setups:
Knowledge Base
KB HTTPS
Kubernetes
- Awesome Kubernetes
- Kubernetes Cheatsheet
- Getting Started: Python application on Kubernetes
- Kubernetes Deployments: The Ultimate Guide
- Prometheus Monitoring Stack with Kubernetes on DO
- Traefik as an Ingress Controller on Minikube
- Traefik Ingress with Kubernetes
- Manual Connect your Kubernetes from Outside
- HTTPS Letsencrypt on k3s
- Kubernetes: Nodeport vs Loadbalancer
- Prometheus Monitoring Pipeline on Kubernetes
- Building a Kubernetes CI/CD Pipeline with Rancher
- Building a Kubernetes CI/CD Pipeline with AWS
- Gitea and Drone CI/CD on k3s
- Serverless with Kubernetes using OpenFaaS and Linkerd2
- Managing Kubernetes with kubectl
- OpenFaas Workshop on k3s
- Kubernetes Hands-On Lab with collabnix
- Create ReadWrite Persistent Volumes on Kubernetes
- Kubernetes Clusters with k3s and multipass
Kubernetes Storage
Golang
Great Blogs
Linuxkit:
Logging Stacks
Machine Learning:
Metrics:
MongoDB:
- Setup MongoDB Cluster
- MongoDB Scripts
- MongoDB Monitoring Tools
- Roles with MongoDB
- Queries: Guru99
- Queries: Exploratory
- Queries: Tutorialspoint
- Queries: MongoDB Cheatsheet
Monitoring
- Docker Swarm Monitoring Stack: Telegraf, InfluxDB, Chronograf, Kapacitor github source
- Docker Swarm Monitoring Stack: Prometheus, Grafana, cAdvisor, Node Exporter github source
- Prometheus Grafana Docker
- Prometheus Blog Seros
- Memcached Monitoring
- Nagios with Nagios Graph
- Slack Alerts with Prometheus
- Local Prometheus Stack
- Docker Swarm Promethus Setup #1
- Docker Swarm Prometheus Setup #1: Blog
- Docker Swarm Promethus Setup #2
- Docker Swarm Promethus Setup #3 (Blackbox)
- Uptime (fzaninotto)
Monitoring and Alerting
Monitoring as Statuspages
Programming
Golang:
Java:
Python
Ruby:
- Learn Ruby: Learn Ruby the Hard Way
- Learn Ruby: Ruby for Beginners
- Learn Ruby: Launch School
- Learn Ruby: Arrays
- Install Ruby Environment on Mac
Ruby on Rails:
Queues
Sysadmin References:
- Sysadmin Command References
- Linux Performance Observability Tools
- Troubleshooting High IO Wait
- IO Monitoring in Linux
- IOStat and VMStat for Performance Monitoring
- Debugging Heavy Load
Self Hosting
Email Server Setups
- Extratione: Postfix Dovecot MySQL Virtual Users Postfixadmin
- Extratione: Postfix Dovecot MySQL Virtual Users Postfixadmin (Ubuntu 18)
- Linuxsize: Postfix Dovecot MySQL Virtual Users Postfixadmin
- Howtoforge: Postfix, MySQL, Dovecto, Dspam
- Linuxsize: VirtualUsers, MySQL, Postfix, Dovecot
Mailscanner Server Setups
Financial
Self Hosting Frameworks:
Serverless
VPN:
VPN-Howto:
- Ubuntu OpenVPN Script
- Ubuntu IPSec Script
- DO — Setup OpenVPN on Ubuntu
- Elasticshosts — IPSec VPN
- PPTP/IPSec/OpenVPN Auto Install
Website Templates
Resume Templates
Web Frameworks
Python Flask:
- Python Flask Upload Example
- Awesome Flask — humiaozuzu
- Awesome Flask Apps — Greyli
- Flask over HTTPS (MG)
- Flask Advanced Patterns
- Flask MVC Boilerplate
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://gist.github.com/bgoonzhttps://gist.github.com/bgoonz
Or Checkout my personal Resource Site:
https://gist.github.com/bgoonz
Questions….Answers… and links to the missing pieces.
Resources first… the actual article is below!

https://trusting-dijkstra-4d3b17.netlify.app/
First off.. Here’s a link to a website I created for practicing with data structures in javascript:
https://trusting-dijkstra-4d3b17.netlify.app/
Here’s a live code editor where you can mess with any of the examples…
https://repl.it/@bgoonz/DS-ALGO-OFFICIAL-2
And here’s the part where I go through leetcode problems:
https://trusting-dijkstra-4d3b17.netlify.app/
Additionally, here’s another Medium Article I wrote on data structures:
https://trusting-dijkstra-4d3b17.netlify.app/
All the code provided in this article will be embeded at the bottom of this article as a gist so that you can see the proper syntax highlighting… and copy it all at once if you like!
Asymptotic Notation

Definition:
Asymptotic Notation is the hardware independent notation used to tell the time and space complexity of an algorithm. Meaning it’s a standardized way of measuring how much memory an algorithm uses or how long it runs for given an input.
Complexities
The following are the Asymptotic rates of growth from best to worst:
- constant growth —
O(1)Runtime is constant and does not grow withn - logarithmic growth —
O(log n)Runtime grows logarithmically in proportion ton - linear growth —
O(n)Runtime grows directly in proportion ton - superlinear growth —
O(n log n)Runtime grows in proportion and logarithmically ton - polynomial growth —
O(n^c)Runtime grows quicker than previous all based onn - exponential growth —
O(c^n)Runtime grows even faster than polynomial growth based onn - factorial growth —
O(n!)Runtime grows the fastest and becomes quickly unusable for even
small values ofn
(source: Soumyadeep Debnath, Analysis of Algorithms | Big-O analysis)
Visualized below; the x-axis representing input size and the y-axis representing complexity:
(source: Wikipedia, Computational Complexity of Mathematical Operations)
Big-O notation
Big-O refers to the upper bound of time or space complexity of an algorithm, meaning it worst case runtime scenario. An easy way to think of it is that runtime could be better than Big-O but it will never be worse.
Big-Ω (Big-Omega) notation
Big-Omega refers to the lower bound of time or space complexity of an algorithm, meaning it is the best runtime scenario. Or runtime could worse than Big-Omega, but it will never be better.
Big-θ (Big-Theta) notation
Big-Theta refers to the tight bound of time or space complexity of an algorithm. Another way to think of it is the intersection of Big-O and Big-Omega, or more simply runtime is guaranteed to be a given complexity, such as n log n.
What you need to know
- Big-O and Big-Theta are the most common and helpful notations
- Big-O does not mean Worst Case Scenario, Big-Theta does not mean average case, and Big-Omega does not mean Best Case Scenario. They only connote the algorithm’s performance for a particular scenario, and all three can be used for any scenario.
- Worst Case means given an unideal input, Average Case means given a typical input, Best case means a ideal input. Ex. Worst case means given an input the algorithm performs particularly bad, or best case an already sorted array for a sorting algorithm.
- Best Case and Big Omega are generally not helpful since Best Cases are rare in the real world and lower bound might be very different than an upper bound.
- Big-O isn’t everything. On paper merge sort is faster than quick sort, but in practice quick sort is superior.
Data Structures
Array
Definition
- Stores data elements based on an sequential, most commonly 0 based, index.
- Based on tuples from set theory.
- They are one of the oldest, most commonly used data structures.
What you need to know
- Optimal for indexing; bad at searching, inserting, and deleting (except at the end).
- Linear arrays, or one dimensional arrays, are the most basic.
- Are static in size, meaning that they are declared with a fixed size.
- Dynamic arrays are like one dimensional arrays, but have reserved space for additional elements.
- If a dynamic array is full, it copies its contents to a larger array.
- Multi dimensional arrays nested arrays that allow for multiple dimensions such as an array of arrays providing a 2 dimensional spacial representation via x, y coordinates.
Time Complexity
- Indexing: Linear array:
O(1), Dynamic array:O(1) - Search: Linear array:
O(n), Dynamic array:O(n) - Optimized Search: Linear array:
O(log n), Dynamic array:O(log n) - Insertion: Linear array: n/a, Dynamic array:
O(n)
Linked List
Definition
- Stores data with nodes that point to other nodes.
- Nodes, at its most basic it has one datum and one reference (another node).
- A linked list chains nodes together by pointing one node’s reference towards another node.
What you need to know
- Designed to optimize insertion and deletion, slow at indexing and searching.
- Doubly linked list has nodes that also reference the previous node.
- Circularly linked list is simple linked list whose tail, the last node, references the head, the first node.
- Stack, commonly implemented with linked lists but can be made from arrays too.
- Stacks are last in, first out (LIFO) data structures.
- Made with a linked list by having the head be the only place for insertion and removal.
- Queues, too can be implemented with a linked list or an array.
- Queues are a first in, first out (FIFO) data structure.
- Made with a doubly linked list that only removes from head and adds to tail.
Time Complexity
- Indexing: Linked Lists:
O(n) - Search: Linked Lists:
O(n) - Optimized Search: Linked Lists:
O(n) - Append: Linked Lists:
O(1) - Prepend: Linked Lists:
O(1) - Insertion: Linked Lists:
O(n)
Hash Table or Hash Map
Definition
- Stores data with key value pairs.
- Hash functions accept a key and return an output unique only to that specific key.
- This is known as hashing, which is the concept that an input and an output have a one-to-one correspondence to map information.
- Hash functions return a unique address in memory for that data.
What you need to know
- Designed to optimize searching, insertion, and deletion.
- Hash collisions are when a hash function returns the same output for two distinct inputs.
- All hash functions have this problem.
- This is often accommodated for by having the hash tables be very large.
- Hashes are important for associative arrays and database indexing.
Time Complexity
- Indexing: Hash Tables:
O(1) - Search: Hash Tables:
O(1) - Insertion: Hash Tables:
O(1)
Binary Tree
Definition
- Is a tree like data structure where every node has at most two children.
- There is one left and right child node.
What you need to know
- Designed to optimize searching and sorting.
- A degenerate tree is an unbalanced tree, which if entirely one-sided, is essentially a linked list.
- They are comparably simple to implement than other data structures.
- Used to make binary search trees.
- A binary tree that uses comparable keys to assign which direction a child is.
- Left child has a key smaller than its parent node.
- Right child has a key greater than its parent node.
- There can be no duplicate node.
- Because of the above it is more likely to be used as a data structure than a binary tree.
Time Complexity
- Indexing: Binary Search Tree:
O(log n) - Search: Binary Search Tree:
O(log n) - Insertion: Binary Search Tree:
O(log n)
Algorithms
Algorithm Basics
Recursive Algorithms
Definition
- An algorithm that calls itself in its definition.
- Recursive case a conditional statement that is used to trigger the recursion.
- Base case a conditional statement that is used to break the recursion.
What you need to know
- Stack level too deep and stack overflow.
- If you’ve seen either of these from a recursive algorithm, you messed up.
- It means that your base case was never triggered because it was faulty or the problem was so massive you ran out of alloted memory.
- Knowing whether or not you will reach a base case is integral to correctly using recursion.
- Often used in Depth First Search
Iterative Algorithms
Definition
- An algorithm that is called repeatedly but for a finite number of times, each time being a single iteration.
- Often used to move incrementally through a data set.
What you need to know
- Generally you will see iteration as loops, for, while, and until statements.
- Think of iteration as moving one at a time through a set.
- Often used to move through an array.
Recursion Vs. Iteration
- The differences between recursion and iteration can be confusing to distinguish since both can be used to implement the other. But know that,
- Recursion is, usually, more expressive and easier to implement.
- Iteration uses less memory.
- Functional languages tend to use recursion. (i.e. Haskell)
- Imperative languages tend to use iteration. (i.e. Ruby)
- Check out this Stack Overflow post for more info.
Pseudo Code of Moving Through an Array
Recursion | Iteration----------------------------------|----------------------------------recursive method (array, n) | iterative method (array) if array[n] is not nil | for n from 0 to size of array print array[n] | print(array[n]) recursive method(array, n+1) | else | exit loop |
Greedy Algorithms
Definition
- An algorithm that, while executing, selects only the information that meets a certain criteria.
- The general five components, taken from Wikipedia:
- A candidate set, from which a solution is created.
- A selection function, which chooses the best candidate to be added to the solution.
- A feasibility function, that is used to determine if a candidate can be used to contribute to a solution.
- An objective function, which assigns a value to a solution, or a partial solution.
- A solution function, which will indicate when we have discovered a complete solution.
What you need to know
- Used to find the expedient, though non-optimal, solution for a given problem.
- Generally used on sets of data where only a small proportion of the information evaluated meets the desired result.
- Often a greedy algorithm can help reduce the Big O of an algorithm.
Pseudo Code of a Greedy Algorithm to Find Largest Difference of any Two Numbers in an Array.
greedy algorithm (array) let largest difference = 0 let new difference = find next difference (array[n], array[n+1]) largest difference = new difference if new difference is > largest difference repeat above two steps until all differences have been found return largest difference
This algorithm never needed to compare all the differences to one another, saving it an entire iteration.
Search Algorithms
Breadth First Search
Definition
- An algorithm that searches a tree (or graph) by searching levels of the tree first, starting at the root.
- It finds every node on the same level, most often moving left to right.
- While doing this it tracks the children nodes of the nodes on the current level.
- When finished examining a level it moves to the left most node on the next level.
- The bottom-right most node is evaluated last (the node that is deepest and is farthest right of it’s level).
What you need to know
- Optimal for searching a tree that is wider than it is deep.
- Uses a queue to store information about the tree while it traverses a tree.
- Because it uses a queue it is more memory intensive than depth first search.
- The queue uses more memory because it needs to stores pointers
Time Complexity
- Search: Breadth First Search: O(V + E)
- E is number of edges
- V is number of vertices
Depth First Search
Definition
- An algorithm that searches a tree (or graph) by searching depth of the tree first, starting at the root.
- It traverses left down a tree until it cannot go further.
- Once it reaches the end of a branch it traverses back up trying the right child of nodes on that branch, and if possible left from the right children.
- When finished examining a branch it moves to the node right of the root then tries to go left on all it’s children until it reaches the bottom.
- The right most node is evaluated last (the node that is right of all it’s ancestors).
What you need to know
- Optimal for searching a tree that is deeper than it is wide.
- Uses a stack to push nodes onto.
- Because a stack is LIFO it does not need to keep track of the nodes pointers and is therefore less memory intensive than breadth first search.
- Once it cannot go further left it begins evaluating the stack.
Time Complexity
- Search: Depth First Search: O(|E| + |V|)
- E is number of edges
- V is number of vertices
Breadth First Search Vs. Depth First Search
- The simple answer to this question is that it depends on the size and shape of the tree.
- For wide, shallow trees use Breadth First Search
- For deep, narrow trees use Depth First Search
Nuances
- Because BFS uses queues to store information about the nodes and its children, it could use more memory than is available on your computer. (But you probably won’t have to worry about this.)
- If using a DFS on a tree that is very deep you might go unnecessarily deep in the search. See xkcd for more information.
- Breadth First Search tends to be a looping algorithm.
- Depth First Search tends to be a recursive algorithm.
Sorting Algorithms
Selection Sort
Definition
- A comparison based sorting algorithm.
- Starts with the cursor on the left, iterating left to right
- Compares the left side to the right, looking for the smallest known item
- If the left is smaller than the item to the right it continues iterating
- If the left is bigger than the item to the right, the item on the right becomes the known smallest number
- Once it has checked all items, it moves the known smallest to the cursor and advances the cursor to the right and starts over
- As the algorithm processes the data set, it builds a fully sorted left side of the data until the entire data set is sorted
- Changes the array in place.
What you need to know
- Inefficient for large data sets.
- Very simple to implement.
Time Complexity
- Best Case Sort: Merge Sort:
O(n^2) - Average Case Sort: Merge Sort:
O(n^2) - Worst Case Sort: Merge Sort:
O(n^2)
Space Complexity
- Worst Case:
O(1)
Visualization

(source: Wikipedia, Insertion Sort)
Insertion Sort
Definition
- A comparison based sorting algorithm.
- Iterates left to right comparing the current cursor to the previous item.
- If the cursor is smaller than the item on the left it swaps positions and the cursor compares itself again to the left hand side until it is put in its sorted position.
- As the algorithm processes the data set, the left side becomes increasingly sorted until it is fully sorted.
- Changes the array in place.
What you need to know
- Inefficient for large data sets, but can be faster for than other algorithms for small ones.
- Although it has an
O(n^2), in practice it slightly less since its comparison scheme only requires checking place if its smaller than its neighbor.
Time Complexity
- Best Case:
O(n) - Average Case:
O(n^2) - Worst Case:
O(n^2)
Space Complexity
- Worst Case:
O(n)
Visualization
(source: Wikipedia, Insertion Sort)
Merge Sort
Definition
- A divide and conquer algorithm.
- Recursively divides entire array by half into subsets until the subset is one, the base case.
- Once the base case is reached results are returned and sorted ascending left to right.
- Recursive calls are returned and the sorts double in size until the entire array is sorted.
What you need to know
- This is one of the fundamental sorting algorithms.
- Know that it divides all the data into as small possible sets then compares them.
Time Complexity
- Worst Case:
O(n log n) - Average Case:
O(n log n) - Best Case:
O(n)
Space Complexity
- Worst Case:
O(1)
Visualization
(source: Wikipedia, Merge Sort)
Quicksort
Definition
- A divide and conquer algorithm
- Partitions entire data set in half by selecting a random pivot element and putting all smaller elements to the left of the element and larger ones to the right.
- It repeats this process on the left side until it is comparing only two elements at which point the left side is sorted.
- When the left side is finished sorting it performs the same operation on the right side.
- Computer architecture favors the quicksort process.
- Changes the array in place.
What you need to know
- While it has the same Big O as (or worse in some cases) many other sorting algorithms it is often faster in practice than many other sorting algorithms, such as merge sort.
Time Complexity
- Worst Case:
O(n^2) - Average Case:
O(n log n) - Best Case:
O(n log n)
Space Complexity
- Worst Case:
O(log n)
Visualization

(source: Wikipedia, Quicksort)
Merge Sort Vs. Quicksort
- Quicksort is likely faster in practice, but merge sort is faster on paper.
- Merge Sort divides the set into the smallest possible groups immediately then reconstructs the incrementally as it sorts the groupings.
- Quicksort continually partitions the data set by a pivot, until the set is recursively sorted.
Additional Resources
Khan Academy’s Algorithm Course
What is ARIA and when should you use it?
Answer
ARIA stands for “Accessible Rich Internet Applications”, and is a technical specification created by the World Wide Web Consortium (W3C). Better known as WAI-ARIA, it provides additional HTML attributes in the development of web applications to offer people who use assistive technologies (AT) a more robust and interoperable experience with dynamic components. By providing the component’s role, name, and state, AT users can better understand how to interact with the component. WAI-ARIA should only be used when an HTML element equivalent is not available or lacks full browser or AT support. WAI-ARIA’s semantic markup coupled with JavaScript works to provide an understandable and interactive experience for people who use AT.
An example using ARIA:
Credit: W3C’s ARIA 1.1 Combobox with Grid Popup Example
Don’t forget:
- Accessible Rich Internet Applications
- Benefits people who use assistive technologies (AT)
- Provides role, name, and state
- Semantic HTML coupled with JavaScript
Additional links
What is the minimum recommended ratio of contrast between foreground text and background to comply with WCAG? Why does this matter?
Answer
4.5:1 is the calculated contrast ratio between foreground text and background that is recommended by the Web Content Accessibiity Guidelines (WCAG) success criteria (SC) 1.4.3: Contrast (Minimum). This SC was written by the World Wide Web Consortium (W3C) to ensure that people with low vision or color deficiencies are able to read (perceive) important content on a web page. It goes beyond color choices to ensure text stands out on the background it’s placed on.
Don’t forget:
- At least 4.5:1 contrast ratio between foreground text and background
- Benefits people with low vision or color deficiencies
Additional links
What are some of the tools available to test the accessibility of a website or web application?
Answer
There are multiple tools that can help you to find for accessibility issues in your website or application.
Check for issues in your website:
- Lighthouse from Google, it provides an option for accessibility testing, it will check for the compliance of different accessibility standards and give you an score with details on the different issues
- Axe Coconut from DequeLabs, it is a Chrome extension that adds a tab in the Developer tools, it will check for accessibility issues and it will classify them by severity and suggest possible solutions
Check for issues in your code: * Jest Axe, you can add unit tests for accessibility * React Axe, test your React application with the axe-core accessibility testing library. Results will show in the Chrome DevTools console. * eslint-plugin-jsx-a11y, pairing this plugin with an editor lint plugin, you can bake accessibility standards into your application in real-time.
Check for individual issues: * Color Contrast checkers * Use a screen reader * Use only keyboard to navigate your site
Don’t forget:
- None of the tools will replace manual testing
- Mention of different ways to test accessibility
Additional links
What is the Accessibility Tree?
Answer
The Accessibility Tree is a structure produced by the browser’s Accessibility APIs which provides accessibility information to assistive technologies such as screen readers. It runs parallel to the DOM and is similar to the DOM API, but with much fewer nodes, because a lot of that information is only useful for visual presentation. By writing semantic HTML we can take advantage of this process in creating an accessible experience for our users.
Don’t forget:
- Tree structure exposing information to assistive technologies
- Runs parallel to the DOM
- Semantic HTML is essential in creating accessible experiences
Additional links
What is the purpose of the alt attribute on images?
Answer
The alt attribute provides alternative information for an image if a user cannot view it. The alt attribute should be used to describe any images except those which only serve a decorative purpose, in which case it should be left empty.
Don’t forget:
- Decorative images should have an empty
altattribute. - Web crawlers use
alttags to understand image content, so they are considered important for Search Engine Optimization (SEO). - Put the
.at the end ofalttag to improve accessibility.
Additional links
What are defer and async attributes on a <script> tag?
Answer
If neither attribute is present, the script is downloaded and executed synchronously, and will halt parsing of the document until it has finished executing (default behavior). Scripts are downloaded and executed in the order they are encountered.
The defer attribute downloads the script while the document is still parsing but waits until the document has finished parsing before executing it, equivalent to executing inside a DOMContentLoaded event listener. defer scripts will execute in order.
The async attribute downloads the script during parsing the document but will pause the parser to execute the script before it has fully finished parsing. async scripts will not necessarily execute in order.
Note: both attributes must only be used if the script has a src attribute (i.e. not an inline script).
<script src="myscript.js"></script>http://myscript.jshttp://myscript.js
Don’t forget:
- Placing a
deferscript in the<head>allows the browser to download the script while the page is still parsing, and is therefore a better option than placing the script before the end of the body. - If the scripts rely on each other, use
defer. - If the script is independent, use
async. - Use
deferif the DOM must be ready and the contents are not placed within aDOMContentLoadedlistener.
Additional links
What is an async function?
async function foo() {
...
}
Answer
An async function is a function that allows you to pause the function’s execution while it waits for (awaits) a promise to resolve. It’s an abstraction on top of the Promise API that makes asynchronous operations look like they’re synchronous.
async functions automatically return a Promise object. Whatever you return from the async function will be the promise’s resolution. If instead you throw from the body of an async function, that will be how your async function rejects the promise it returns.
Most importantly, async functions are able to use the await keyword in their function body, which pauses the function until the operation after the await completes, and allows it to return that operation’s result to a variable synchronously.
// Normal promises in regular function:
function foo() {
promiseCall()
.then(result => {
// do something with the result
})
}
// async functions
async function foo() {
const result = await promiseCall()
// do something with the result
}
Don’t forget:
asyncfunctions are just syntactic sugar on top of Promises.- They make asynchronous operations look like synchronous operations in your function.
- They implicitly return a promise which resolves to whatever your
asyncfunction returns, and reject to whatever yourasyncfunctionthrows.
Additional links
Create a function batches that returns the maximum number of whole batches that can be cooked from a recipe.
/**
It accepts two objects as arguments: the first object is the recipe
for the food, while the second object is the available ingredients.
Each ingredient's value is a number representing how many units there are.
`batches(recipe, available)`
*/
// 0 batches can be made
batches(
{ milk: 100, butter: 50, flour: 5 },
{ milk: 132, butter: 48, flour: 51 }
)
batches(
{ milk: 100, flour: 4, sugar: 10, butter: 5 },
{ milk: 1288, flour: 9, sugar: 95 }
)
// 1 batch can be made
batches(
{ milk: 100, butter: 50, cheese: 10 },
{ milk: 198, butter: 52, cheese: 10 }
)
// 2 batches can be made
batches(
{ milk: 2, sugar: 40, butter: 20 },
{ milk: 5, sugar: 120, butter: 500 }
)
Answer
We must have all ingredients of the recipe available, and in quantities that are more than or equal to the number of units required. If just one of the ingredients is not available or lower than needed, we cannot make a single batch.
Use Object.keys() to return the ingredients of the recipe as an array, then use Array.prototype.map() to map each ingredient to the ratio of available units to the amount required by the recipe. If one of the ingredients required by the recipe is not available at all, the ratio will evaluate to NaN, so the logical OR operator can be used to fallback to 0 in this case.
Use the spread ... operator to feed the array of all the ingredient ratios into Math.min() to determine the lowest ratio. Passing this entire result into Math.floor() rounds down to return the maximum number of whole batches.
const batches = (recipe, available) =>
Math.floor(
Math.min(...Object.keys(recipe).map(k => available[k] / recipe[k] || 0))
)
Don’t forget:
Additional links
What is CSS BEM?
Answer
The BEM methodology is a naming convention for CSS classes in order to keep CSS more maintainable by defining namespaces to solve scoping issues. BEM stands for Block Element Modifier which is an explanation for its structure. A Block is a standalone component that is reusable across projects and acts as a “namespace” for sub components (Elements). Modifiers are used as flags when a Block or Element is in a certain state or is different in structure or style.
/* block component */.block {}
/* element */.block__element {}
/* modifier */.block__element--modifier {}
Here is an example with the class names on markup:
<nav class="navbar"> <a href="/" class="navbar__link navbar__link--active"></a> <a href="/" class="navbar__link"></a> <a href="/" class="navbar__link"></a></nav>
In this case, navbar is the Block, navbar__link is an Element that makes no sense outside of the navbar component, and navbar__link--active is a Modifier that indicates a different state for the navbar__link Element.
Since Modifiers are verbose, many opt to use is-* flags instead as modifiers.
<a href="/" class="navbar__link is-active"></a>
These must be chained to the Element and never alone however, or there will be scope issues.
.navbar__link.is-active {}
Don’t forget:
- Alternative solutions to scope issues like CSS-in-JS
Additional links
What is Big O Notation?
Answer
Big O notation is used in Computer Science to describe the time complexity of an algorithm. The best algorithms will execute the fastest and have the simplest complexity.
Algorithms don’t always perform the same and may vary based on the data they are supplied. While in some cases they will execute quickly, in other cases they will execute slowly, even with the same number of elements to deal with.
In these examples, the base time is 1 element = 1ms.
O(1)
arr[arr.length - 1]
- 1000 elements =
1ms
Constant time complexity. No matter how many elements the array has, it will theoretically take (excluding real-world variation) the same amount of time to execute.
O(N)
arr.filter(fn)
- 1000 elements =
1000ms
Linear time complexity. The execution time will increase linearly with the number of elements the array has. If the array has 1000 elements and the function takes 1ms to execute, 7000 elements will take 7ms to execute. This is because the function must iterate through all elements of the array before returning a result.
O([1, N])
arr.some(fn)
- 1000 elements =
1ms <= x <= 1000ms
The execution time varies depending on the data supplied to the function, it may return very early or very late. The best case here is O(1) and the worst case is O(N).
O(NlogN)
arr.sort(fn)
- 1000 elements ~=
10000ms
Browsers usually implement the quicksort algorithm for the sort() method and the average time complexity of quicksort is O(NlgN). This is very efficient for large collections.
O(N²)
for (let i = 0; i < arr.length; i++) {
for (let j = 0; j < arr.length; j++) {
// ...
}
}
- 1000 elements =
1000000ms
The execution time rises quadratically with the number of elements. Usually the result of nesting loops.
O(N!)
const permutations = arr => {
if (arr.length <= 2) return arr.length === 2 ? [arr, [arr[1], arr[0]]] : arr
return arr.reduce(
(acc, item, i) =>
acc.concat(
permutations([...arr.slice(0, i), ...arr.slice(i + 1)]).map(val => [
item,
...val
])
),
[]
)
}
- 1000 elements =
Infinity(practically) ms
The execution time rises extremely fast with even just 1 addition to the array.
Don’t forget:
- Be wary of nesting loops as execution time increases exponentially.
Additional links
Create a standalone function bind that is functionally equivalent to the method Function.prototype.bind.
function example() {
console.log(this)
}
const boundExample = bind(example, { a: true })
boundExample.call({ b: true }) // logs { a: true }
Answer
Return a function that accepts an arbitrary number of arguments by gathering them with the rest ... operator. From that function, return the result of calling the fn with Function.prototype.apply to apply the context and the array of arguments to the function.
const bind = (fn, context) => (...args) => fn.apply(context, args)
Don’t forget:
Additional links
What is the purpose of cache busting and how can you achieve it?
Answer
Browsers have a cache to temporarily store files on websites so they don’t need to be re-downloaded again when switching between pages or reloading the same page. The server is set up to send headers that tell the browser to store the file for a given amount of time. This greatly increases website speed and preserves bandwidth.
However, it can cause problems when the website has been changed by developers because the user’s cache still references old files. This can either leave them with old functionality or break a website if the cached CSS and JavaScript files are referencing elements that no longer exist, have moved or have been renamed.
Cache busting is the process of forcing the browser to download the new files. This is done by naming the file something different to the old file.
A common technique to force the browser to re-download the file is to append a query string to the end of the file.
src="js/script.js"=>src="js/script.js?v=2"
The browser considers it a different file but prevents the need to change the file name.
Don’t forget:
Additional links
How can you avoid callback hells?
getData(function(a) {
getMoreData(a, function(b) {
getMoreData(b, function(c) {
getMoreData(c, function(d) {
getMoreData(d, function(e) {
// ...
})
})
})
})
})
Answer
Refactoring the functions to return promises and using async/await is usually the best option. Instead of supplying the functions with callbacks that cause deep nesting, they return a promise that can be awaited and will be resolved once the data has arrived, allowing the next line of code to be evaluated in a sync-like fashion.
The above code can be restructured like so:
async function asyncAwaitVersion() {
const a = await getData()
const b = await getMoreData(a)
const c = await getMoreData(b)
const d = await getMoreData(c)
const e = await getMoreData(d)
// ...
}
There are lots of ways to solve the issue of callback hells:
- Modularization: break callbacks into independent functions
- Use a control flow library, like async
- Use generators with Promises
- Use async/await (from v7 on)
Don’t forget:
- As an efficient JavaScript developer, you have to avoid the constantly growing indentation level, produce clean and readable code and be able to handle complex flows.
Additional links
What is the purpose of callback function as an argument of setState?
Answer
The callback function is invoked when setState has finished and the component gets rendered. Since setState is asynchronous, the callback function is used for any post action.
setState({ name: "sudheer" }, () => {
console.log("The name has updated and component re-rendered")
})
Don’t forget:
- The callback function is invoked after
setStatefinishes and is used for any post action. - It is recommended to use lifecycle method rather this callback function.
Additional links
- React docs on
[setState](https://reactjs.org/docs/react-component.html#setstate)
Which is the preferred option between callback refs and findDOMNode()?
Answer
Callback refs are preferred over the findDOMNode() API, due to the fact that findDOMNode() prevents certain improvements in React in the future.
// Legacy approach using findDOMNode()
class MyComponent extends Component {
componentDidMount() {
findDOMNode(this).scrollIntoView()
}
render() {
return
}
}
// Recommended approach using callback refs
class MyComponent extends Component {
componentDidMount() {
this.node.scrollIntoView()
}
render() {
return <div ref={node => (this.node = node)} />
}
}
Don’t forget:
- Callback refs are preferred over
findDOMNode().
Additional links
What is a callback? Can you show an example using one?
Answer
Callbacks are functions passed as an argument to another function to be executed once an event has occurred or a certain task is complete, often used in asynchronous code. Callback functions are invoked later by a piece of code but can be declared on initialization without being invoked.
As an example, event listeners are asynchronous callbacks that are only executed when a specific event occurs.
function onClick() {
console.log("The user clicked on the page.")
}
document.addEventListener("click",
onClick)
However, callbacks can also be synchronous. The following map function takes a callback function that is invoked synchronously for each iteration of the loop (array element).
const map = (arr, callback) => {
const result = []
for (let i = 0; i < arr.length; i++) {
result.push(callback(arr[i], i))
}
return result
}
map([1, 2, 3, 4, 5], n => n * 2) // [2, 4, 6, 8, 10]
Don’t forget:
- Functions are first-class objects in JavaScript
- Callbacks vs Promises
Additional links
What is the children prop?
Answer
children is part of the props object passed to components that allows components to be passed as data to other components, providing the ability to compose components cleanly. There are a number of methods available in the React API to work with this prop, such as React.Children.map, React.Children.forEach, React.Children.count, React.Children.only and React.Children.toArray. A simple usage example of the children prop is as follows:
function GenericBox({ children }) {
return
}
function App() {
return (
Hello World
)
}
Don’t forget:
- Children is a prop that allows components to be passed as data to other components.
- The React API provides methods to work with this prop.
Additional links
Why does React use className instead of class like in HTML?
Answer
React’s philosophy in the beginning was to align with the browser DOM API rather than HTML, since that more closely represents how elements are created. Setting a class on an element meant using the className API:
const element = document.createElement("div")
element.className = "hello"
Additionally, before ES5, reserved words could not be used in objects:
const element = {
attributes: {
class: "hello"
}
}
In IE8, this will throw an error.
In modern environments, destructuring will throw an error if trying to assign to a variable:
const { class } = this.props // Error
const { className } = this.props // All good
const { class: className } =
this.props // All good, but
cumbersome!
However, class can be used as a prop without problems, as seen in other libraries like Preact. React currently allows you to use class, but will throw a warning and convert it to className under the hood. There is currently an open thread (as of January 2019) discussing changing className to class to reduce confusion.
Don’t forget:
Additional links
How do you clone an object in JavaScript?
Answer
Using the object spread operator ..., the object’s own enumerable properties can be copied into the new object. This creates a shallow clone of the object.
const obj = { a: 1, b: 2 }
const shallowClone = { ...obj }
With this technique, prototypes are ignored. In addition, nested objects are not cloned, but rather their references get copied, so nested objects still refer to the same objects as the original. Deep-cloning is much more complex in order to effectively clone any type of object (Date, RegExp, Function, Set, etc) that may be nested within the object.
Other alternatives include:
JSON.parse(JSON.stringify(obj))can be used to deep-clone a simple object, but it is CPU-intensive and only accepts valid JSON (therefore it strips functions and does not allow circular references).Object.assign({}, obj)is another alternative.Object.keys(obj).reduce((acc, key) => (acc[key] = obj[key], acc), {})is another more verbose alternative that shows the concept in greater depth.
Don’t forget:
- JavaScript passes objects by reference, meaning that nested objects get their references copied, instead of their values.
- The same method can be used to merge two objects.
Additional links
What is a closure? Can you give a useful example of one?
Answer
A closure is a function defined inside another function and has access to its lexical scope even when it is executing outside its lexical scope. The closure has access to variables in three scopes:
- Variables declared in its own scope
- Variables declared in the scope of the parent function
- Variables declared in the global scope
In JavaScript, all functions are closures because they have access to the outer scope, but most functions don’t utilise the usefulness of closures: the persistence of state. Closures are also sometimes called stateful functions because of this.
In addition, closures are the only way to store private data that can’t be accessed from the outside in JavaScript. They are the key to the UMD (Universal Module Definition) pattern, which is frequently used in libraries that only expose a public API but keep the implementation details private, preventing name collisions with other libraries or the user’s own code.
Don’t forget:
- Closures are useful because they let you associate data with a function that operates on that data.
- A closure can substitute an object with only a single method.
- Closures can be used to emulate private properties and methods.
Additional links
How do you compare two objects in JavaScript?
Answer
Even though two different objects can have the same properties with equal values, they are not considered equal when compared using == or ===. This is because they are being compared by their reference (location in memory), unlike primitive values which are compared by value.
In order to test if two objects are equal in structure, a helper function is required. It will iterate through the own properties of each object to test if they have the same values, including nested objects. Optionally, the prototypes of the objects may also be tested for equivalence by passing true as the 3rd argument.
Note: this technique does not attempt to test equivalence of data structures other than plain objects, arrays, functions, dates and primitive values.
function isDeepEqual(obj1, obj2, testPrototypes = false) {
if (obj1 === obj2) {
return true
}
if (typeof obj1 === "function" && typeof obj2 === "function") {
return obj1.toString() === obj2.toString()
}
if (obj1 instanceof Date && obj2 instanceof Date) {
return obj1.getTime() === obj2.getTime()
}
if (
Object.prototype.toString.call(obj1) !==
Object.prototype.toString.call(obj2) ||
typeof obj1 !== "object"
) {
return false
}
const prototypesAreEqual = testPrototypes
? isDeepEqual(
Object.getPrototypeOf(obj1),
Object.getPrototypeOf(obj2),
true
)
: true
const obj1Props = Object.getOwnPropertyNames(obj1)
const obj2Props = Object.getOwnPropertyNames(obj2)
return (
obj1Props.length === obj2Props.length &&
prototypesAreEqual &&
obj1Props.every(prop => isDeepEqual(obj1[prop], obj2[prop]))
)
}
Don’t forget:
- Primitives like strings and numbers are compared by their value
- Objects on the other hand are compared by their reference (location in memory)
Additional links
What is context?
Answer
Context provides a way to pass data through the component tree without having to pass props down manually at every level. For example, authenticated user, locale preference, UI theme need to be accessed in the application by many components.
const { Provider, Consumer } = React.createContext(defaultValue)
Don’t forget:
- Context provides a way to pass data through a tree of React components, without having to manually pass props.
- Context is designed to share data that is considered global for a tree of React components.
Additional links
What is CORS?
Answer
Cross-Origin Resource Sharing or CORS is a mechanism that uses additional HTTP headers to grant a browser permission to access resources from a server at an origin different from the website origin.
An example of a cross-origin request is a web application served from [http://mydomain.com](http://mydomain.com/) that uses AJAX to make a request for [http://yourdomain.com](http://yourdomain.com./).
For security reasons, browsers restrict cross-origin HTTP requests initiated by JavaScript. XMLHttpRequest and fetch follow the same-origin policy, meaning a web application using those APIs can only request HTTP resources from the same origin the application was accessed, unless the response from the other origin includes the correct CORS headers.
Don’t forget:
- CORS behavior is not an error, it’s a security mechanism to protect users.
- CORS is designed to prevent a malicious website that a user may unintentionally visit from making a request to a legitimate website to read their personal data or perform actions against their will.
Additional links
Describe the layout of the CSS Box Model and briefly describe each component.
Answer
Content: The inner-most part of the box filled with content, such as text, an image, or video player. It has the dimensions content-box width and content-box height.
Padding: The transparent area surrounding the content. It has dimensions padding-box width and padding-box height.
Border: The area surrounding the padding (if any) and content. It has dimensions border-box width and border-box height.
Margin: The transparent outer-most layer that surrounds the border. It separates the element from other elements in the DOM. It has dimensions margin-box width and margin-box height.

alt text
Don’t forget:
- This is a very common question asked during front-end interviews and while it may seem easy, it is critical you know it well!
- Shows a solid understanding of spacing and the DOM
Additional links
What are the advantages of using CSS preprocessors?
Answer
CSS preprocessors add useful functionality that native CSS does not have, and generally make CSS neater and more maintainable by enabling DRY (Don’t Repeat Yourself) principles. Their terse syntax for nested selectors cuts down on repeated code. They provide variables for consistent theming (however, CSS variables have largely replaced this functionality) and additional tools like color functions (lighten, darken, transparentize, etc), mixins, and loops that make CSS more like a real programming language and gives the developer more power to generate complex CSS.
Don’t forget:
- They allow us to write more maintainable and scalable CSS
- Some disadvantages of using CSS preprocessors (setup, re-compilation time can be slow etc.)
Additional links
What is the difference between ‘+’ and ‘~’ sibling selectors?.
Answer
The General Sibling Selector ~ selects all elements that are siblings of a specified element.
The following example selects all <p> elements that are siblings of <div> elements:
div ~ p { background-color: blue;}
The Adjacent Sibling Selector + selects all elements that are the adjacent siblings of a specified element.
The following example will select all <p> elements that are placed immediately after <div> elements:
div + p { background-color: red;}
Don’t forget:
Additional links
Can you describe how CSS specificity works?
Answer
Assuming the browser has already determined the set of rules for an element, each rule is assigned a matrix of values, which correspond to the following from highest to lowest specificity:
- Inline rules (binary — 1 or 0)
- Number of id selectors
- Number of class, pseudo-class and attribute selectors
- Number of tags and pseudo-element selectors
When two selectors are compared, the comparison is made on a per-column basis (e.g. an id selector will always be higher than any amount of class selectors, as ids have higher specificity than classes). In cases of equal specificity between multiple rules, the rules that comes last in the page’s style sheet is deemed more specific and therefore applied to the element.
Don’t forget:
- Specificity matrix: [inline, id, class/pseudo-class/attribute, tag/pseudo-element]
- In cases of equal specificity, last rule is applied
Additional links
What is debouncing?
Answer
Debouncing is a process to add some delay before executing a function. It is commonly used with DOM event listeners to improve the performance of page. It is a technique which allow us to “group” multiple sequential calls in a single one. A raw DOM event listeners can easily trigger 20+ events per second. A debounced function will only be called once the delay has passed.
const debounce = (func, delay) => {
let debounceTimer;
return function() {
const context = this;
const args = arguments;
clearTimeout(debounceTimer);
debounceTimer = setTimeout(() => func.apply(context, args), delay);
}
}
window.addEventListere('scroll', debounce(function() {
// Do stuff, this function will be called after a delay of 1 second
}, 1000));
Don’t forget:
- Common use case is to make API call only when user is finished typing while searching.
Additional links
What is the DOM?
Answer
The DOM (Document Object Model) is a cross-platform API that treats HTML and XML documents as a tree structure consisting of nodes. These nodes (such as elements and text nodes) are objects that can be programmatically manipulated and any visible changes made to them are reflected live in the document. In a browser, this API is available to JavaScript where DOM nodes can be manipulated to change their styles, contents, placement in the document, or interacted with through event listeners.
Don’t forget:
- The DOM was designed to be independent of any particular programming language, making the structural representation of the document available from a single, consistent API.
- The DOM is constructed progressively in the browser as a page loads, which is why scripts are often placed at the bottom of a page, in the
<head>with adeferattribute, or inside aDOMContentLoadedevent listener. Scripts that manipulate DOM nodes should be run after the DOM has been constructed to avoid errors. document.getElementById()anddocument.querySelector()are common functions for selecting DOM nodes.- Setting the
innerHTMLproperty to a new value runs the string through the HTML parser, offering an easy way to append dynamic HTML content to a node.
Additional links
What is the difference between the equality operators == and ===?
Answer
Triple equals (===) checks for strict equality, which means both the type and value must be the same. Double equals (==) on the other hand first performs type coercion so that both operands are of the same type and then applies strict comparison.
Don’t forget:
- Whenever possible, use triple equals to test equality because loose equality
==can have unintuitive results. - Type coercion means the values are converted into the same type.
- Mention of falsy values and their comparison.
Additional links
What is the difference between an element and a component in React?
Answer
An element is a plain JavaScript object that represents a DOM node or component. Elements are pure and never mutated, and are cheap to create.
A component is a function or class. Components can have state and take props as input and return an element tree as output (although they can represent generic containers or wrappers and don’t necessarily have to emit DOM). Components can initiate side effects in lifecycle methods (e.g. AJAX requests, DOM mutations, interfacing with 3rd party libraries) and may be expensive to create.
const Component = () => "Hello"
const componentElement =
const domNodeElement =
Don’t forget:
- Elements are immutable, plain objects that describe the DOM nodes or components you want to render.
- Components can be either classes or functions, that take props as an input and return an element tree as the output.
Additional links
What is the difference between em and rem units?
Answer
Both em and rem units are based on the font-size CSS property. The only difference is where they inherit their values from.
emunits inherit their value from thefont-sizeof the parent elementremunits inherit their value from thefont-sizeof the root element (html)
In most browsers, the font-size of the root element is set to 16px by default.
Don’t forget:
- Benefits of using
emandremunits
Additional links
What are error boundaries in React?
Answer
Error boundaries are React components that catch JavaScript errors anywhere in their child component tree, log those errors, and display a fallback UI instead of the component tree that crashed.
Class components become error boundaries if they define either (or both) of the lifecycle methods static getDerivedStateFromError() or componentDidCatch().
class ErrorBoundary extends React.Component {
constructor(props) {
super(props)
this.state = { hasError: false }
}
// Use componentDidCatch to log the error
componentDidCatch(error, info) {
// You can also log the error to an error reporting service
logErrorToMyService(error, info)
}
// use getDerivedStateFromError to update state
static getDerivedStateFromError(error) {
// Display fallback UI
return { hasError: true };
}
render() {
if (this.state.hasError) {
// You can render any custom fallback UI
return
Something went wrong.
}
return this.props.children
}
}
Don’t forget:
- Error boundaries only catch errors in the components below them in the tree. An error boundary can’t catch an error within itself.
Additional links
https://trusting-dijkstra-4d3b17.netlify.app/
What is event delegation and why is it useful? Can you show an example of how to use it?
Answer
Event delegation is a technique of delegating events to a single common ancestor. Due to event bubbling, events “bubble” up the DOM tree by executing any handlers progressively on each ancestor element up to the root that may be listening to it.
DOM events provide useful information about the element that initiated the event via Event.target. This allows the parent element to handle behavior as though the target element was listening to the event, rather than all children of the parent or the parent itself.
This provides two main benefits:
- It increases performance and reduces memory consumption by only needing to register a single event listener to handle potentially thousands of elements.
- If elements are dynamically added to the parent, there is no need to register new event listeners for them.
Instead of:
document.querySelectorAll("button").forEach(button => {
button.addEventListener("click", handleButtonClick)
})
Event delegation involves using a condition to ensure the child target matches our desired element:
document.addEventListener("click", e => {
if (e.target.closest("button")) {
handleButtonClick()
}
})
Don’t forget:
- The difference between event bubbling and capturing
Additional links
What is event-driven programming?
Answer
Event-driven programming is a paradigm that involves building applications that send and receive events. When the program emits events, the program responds by running any callback functions that are registered to that event and context, passing in associated data to the function. With this pattern, events can be emitted into the wild without throwing errors even if no functions are subscribed to it.
A common example of this is the pattern of elements listening to DOM events such as click and mouseenter, where a callback function is run when the event occurs.
document.addEventListener("click", function(event) {
// This callback function is run when the user
// clicks on the document.
})
Without the context of the DOM, the pattern may look like this:
const hub = createEventHub()
hub.on("message", function(data) {
console.log(`${data.username} said ${data.text}`)
})
hub.emit("message", {
username: "John",
text: "Hello?"
})
With this implementation, on is the way to subscribe to an event, while emit is the way to publish the event.
Don’t forget:
- Follows a publish-subscribe pattern.
- Responds to events that occur by running any callback functions subscribed to the event.
- Show how to create a simple pub-sub implementation with JavaScript.
Additional links
What is the difference between an expression and a statement in JavaScript?
Answer
There are two main syntactic categories in JavaScript: expressions and statements. A third one is both together, referred to as an expression statement. They are roughly summarized as:
- Expression: produces a value
- Statement: performs an action
- Expression statement: produces a value and performs an action
A general rule of thumb:
If you can print it or assign it to a variable, it’s an expression. If you can’t, it’s a statement.
Statements
let x = 0
function declaration() {}
if (true) {
}
Statements appear as instructions that do something but don’t produce values.
// Assign `x` to the absolute value of `y`.
var x
if (y >= 0) {
x = y
} else {
x = -y
}
The only expression in the above code is y >= 0 which produces a value, either true or false. A value is not produced by other parts of the code.
Expressions
Expressions produce a value. They can be passed around to functions because the interpreter replaces them with the value they resolve to.
5 + 5 // => 10
lastCharacter("input") // => "t"
true === true // => true
Expression statements
There is an equivalent version of the set of statements used before as an expression using the conditional operator:
// Assign `x` as the absolute value of `y`.
var x = y >= 0 ? y : -y
This is both an expression and a statement, because we are declaring a variable x (statement) as an evaluation (expression).
Don’t forget:
- Function declarations vs function expressions
Additional links
What are truthy and falsy values in JavaScript?
Answer
A value is either truthy or falsy depending on how it is evaluated in a Boolean context. Falsy means false-like and truthy means true-like. Essentially, they are values that are coerced to true or false when performing certain operations.
There are 6 falsy values in JavaScript. They are:
falseundefinednull""(empty string)NaN0(both+0and-0)
Every other value is considered truthy.
A value’s truthiness can be examined by passing it into the Boolean function.
Boolean("") // false
Boolean([]) // true
There is a shortcut for this using the logical NOT ! operator. Using ! once will convert a value to its inverse boolean equivalent (i.e. not false is true), and ! once more will convert back, thus effectively converting the value to a boolean.
!!"" // false
!![] // true
Don’t forget:
Additional links
Generate an array, containing the Fibonacci sequence, up until the nth term.
Answer
Initialize an empty array of length n. Use Array.prototype.reduce() to add values into the array, using the sum of the last two values, except for the first two.
const fibonacci = n =>
[...Array(n)].reduce(
(acc, val, i) => acc.concat(i > 1 ? acc[i - 1] + acc[i - 2] : i),
[]
)
Don’t forget:
Additional links
Given an array of words, write a method to output matching sets of anagrams.
const words = ['rates', 'rat', 'stare', 'taser', 'tears', 'art', 'tabs', 'tar', 'bats', 'state'];
Answer
const words = ['rates', 'rat', 'stare', 'taser', 'tears', 'art', 'tabs', 'tar', 'bats', 'state'];
function anagramGroups(wordAry){
const groupedWords = {};
// iterate over each word in the array
wordAry.map(word => {
// alphabetize the word and a separate variable
alphaWord = word.split('').sort().join('');
// if the alphabetize word is already a key, push the actual word value (this is an anagram)
if(groupedWords\[alphaWord\]) {
return groupedWords\[alphaWord\].push(word);
}
// otherwise add the alphabetize word key and actual word value (may not turn out to be an anagram)
groupedWords\[alphaWord\] = \[word\];
})
return groupedWords;
}
// call the function and store results in a variable called collectedAnagrams
const collectedAnagrams = anagramGroups(words);
// iterate over groupedAnagrams, printing out group of values
for(const sortedWord in collectedAnagrams) {
if(collectedAnagrams[sortedWord].length > 1) {
console.log(collectedAnagrams[sortedWord].toString());
}
}
Don’t forget:
- Iterate the array
- Alphabetize each word
- Store alphabetize word as the key value in a groupedWords object with the original word as the value
- Compare alphabetize words to object keys and add additional original words when matches are found
- Iterate over the return object and output the values, when there is more then one. (single values mean no anagram )
Additional links
Using flexbox, create a 3-column layout where each column takes up a col-{n} / 12 ratio of the container.
<div class="row"> <div class="col-2"></div> <div class="col-7"></div> <div class="col-3"></div></div>
Answer
Set the .row parent to display: flex; and use the flex shorthand property to give the column classes a flex-grow value that corresponds to its ratio value.
.row { display: flex;}
.col-2 { flex: 2;}
.col-7 { flex: 7;}
.col-3 { flex: 3;}
Don’t forget:
Additional links
What does 0.1 + 0.2 === 0.3 evaluate to?
Answer
It evaluates to false because JavaScript uses the IEEE 754 standard for Math and it makes use of 64-bit floating numbers. This causes precision errors when doing decimal calculations, in short, due to computers working in Base 2 while decimal is Base 10.
0.1 + 0.2 // 0.30000000000000004
A solution to this problem would be to use a function that determines if two numbers are approximately equal by defining an error margin (epsilon) value that the difference between two values should be less than.
const approxEqual = (n1, n2, epsilon = 0.0001) => Math.abs(n1 - n2) < epsilon
approxEqual(0.1 + 0.2, 0.3) // true
Don’t forget:
- A simple solution to this problem
Additional links
What is a focus ring? What is the correct solution to handle them?
Answer
A focus ring is a visible outline given to focusable elements such as buttons and anchor tags. It varies depending on the vendor, but generally it appears as a blue outline around the element to indicate it is currently focused.
In the past, many people specified outline: 0; on the element to remove the focus ring. However, this causes accessibility issues for keyboard users because the focus state may not be clear. When not specified though, it causes an unappealing blue ring to appear around an element.
In recent times, frameworks like Bootstrap have opted to use a more appealing box-shadow outline to replace the default focus ring. However, this is still not ideal for mouse users.
The best solution is an upcoming pseudo-selector :focus-visible which can be polyfilled today with JavaScript. It will only show a focus ring if the user is using a keyboard and leave it hidden for mouse users. This keeps both aesthetics for mouse use and accessibility for keyboard use.
Don’t forget:
Additional links
What is the difference between the array methods map() and forEach()?
Answer
Both methods iterate through the elements of an array. map() maps each element to a new element by invoking the callback function on each element and returning a new array. On the other hand, forEach() invokes the callback function for each element but does not return a new array. forEach() is generally used when causing a side effect on each iteration, whereas map() is a common functional programming technique.
Don’t forget:
- Use
forEach()if you need to iterate over an array and cause mutations to the elements without needing to return values to generate a new array. map()is the right choice to keep data immutable where each value of the original array is mapped to a new array.
Additional links
What are fragments?
Answer
Fragments allow a React component to return multiple elements without a wrapper, by grouping the children without adding extra elements to the DOM. Fragments offer better performance, lower memory usage, a cleaner DOM and can help in dealing with certain CSS mechanisms (e.g. tables, Flexbox and Grid).
render() {
return (
<React.Fragment>
</React.Fragment>
);
}
// Short syntax supported by Babel 7
render() {
return (
<>
</>
);
}
Don’t forget:
- Fragments group multiple elements returned from a component, without adding a DOM element around them.
Additional links
What is functional programming?
Answer
Functional programming is a paradigm in which programs are built in a declarative manner using pure functions that avoid shared state and mutable data. Functions that always return the same value for the same input and don’t produce side effects are the pillar of functional programming. Many programmers consider this to be the best approach to software development as it reduces bugs and cognitive load.
Don’t forget:
- Cleaner, more concise development experience
- Simple function composition
- Features of JavaScript that enable functional programming (
.map,.reduceetc.) - JavaScript is multi-paradigm programming language (Object-Oriented Programming and Functional Programming live in harmony)
Additional links
- Javascript and Functional Programming: An Introduction
- Master the JavaScript Interview: What is Functional Programming?
Describe your thoughts on how a single page web app should handle focus when changing routes
Answer
Single page applications make use of client-side rendering. This means that ‘examplesite.com’ and ‘examplesite.com/page2’ are actually the same HTML web page, but the client app decides what content to drop into that single page at runtime. Your user never actually “leaves” the page, and this causes some accessibility issues in terms of focus.
Unless focus is explicitly managed in the app, a scenario like this may happen:
- User visits ‘examplesite.com’
- User clicks a link to go to another route: ‘examplesite.com/product1’
- Client app changes the visible content to show the details for this new route (e.g. some info about Product 1)
- Focus is still on the link that was clicked in step 2
- If a user uses the keyboard or screen reader to now try and read the content, the focused starting point is in the middle of the page on an element no longer visible
Many strategies have been proposed in handling this situation, all involving explicitly managing the focus when the new page content is rendered. Recent research by GatsbyJS suggests the best approach is:
- User visits ‘examplesite.com’
- User clicks a link to go to another route: ‘examplesite.com/product1’
- Client app changes the visible content to show the details for this new route (e.g. some info about Product 1)
- Client app manually places focus on the main header at the top of the page (almost always this will be the H1 element)
By doing so, focus is reset to the top of the page, ready for the user to begin exploring the new content. This solution requires inserting the main heading into the start of tabbing order with tabindex="-1".
Don’t forget:
- Focus issues caused by client-side rendering, instead of server-side
- Focus should not be left on elements no longer visible on the page
- Challenges faced by screen reader users and users utilising keyboard navigation
- Careful manual focus management required
Additional links
What are higher-order components?
Answer
A higher-order component (HOC) is a function that takes a component as an argument and returns a new component. It is a pattern that is derived from React’s compositional nature. Higher-order components are like pure components because they accept any dynamically provided child component, but they won’t modify or copy any behavior from their input components.
const EnhancedComponent = higherOrderComponent(WrappedComponent)
Don’t forget:
- They can be used for state abstraction and manipulation, props manipulation, render high jacking, etc.
Additional links
What will the console log in this example?
var foo = 1
var foobar = function() {
console.log(foo)
var foo = 2
}
foobar()
Answer
Due to hoisting, the local variable foo is declared before the console.log method is called. This means the local variable foo is passed as an argument to console.log() instead of the global one declared outside of the function. However, since the value is not hoisted with the variable declaration, the output will be undefined, not 2.
Don’t forget:
- Hoisting is JavaScript’s default behavior of moving declarations to the top
- Mention of
strictmode
Additional links
How does hoisting work in JavaScript?
Answer
Hoisting is a JavaScript mechanism where variable and function declarations are put into memory during the compile phase. This means that no matter where functions and variables are declared, they are moved to the top of their scope regardless of whether their scope is global or local.
However, the value is not hoisted with the declaration.
The following snippet:
console.log(hoist)
var hoist = "value"
is equivalent to:
var hoist
console.log(hoist)
hoist = "value"
Therefore logging hoist outputs undefined to the console, not "value".
Hoisting also allows you to invoke a function declaration before it appears to be declared in a program.
myFunction() // No error; logs "hello"
function myFunction() {
console.log("hello")
}
But be wary of function expressions that are assigned to a variable:
myFunction() // Error: `myFunction` is not a function
var myFunction = function() {
console.log("hello")
}
Don’t forget:
- Hoisting is JavaScript’s default behavior of moving declarations to the top
- Functions declarations are hoisted before variable declarations
Additional links
Can a web page contain multiple <header> elements? What about <footer> elements?
Answer
Yes to both. The W3 documents state that the tags represent the header(<header>) and footer(<footer>) areas of their nearest ancestor “section”. So not only can the page <body> contain a header and a footer, but so can every <article> and <section> element.
Don’t forget:
- W3 recommends having as many as you want, but only 1 of each for each “section” of your page, i.e. body, section etc.
Additional links
Discuss the differences between an HTML specification and a browser’s implementation thereof.
Answer
HTML specifications such as HTML5 define a set of rules that a document must adhere to in order to be “valid” according to that specification. In addition, a specification provides instructions on how a browser must interpret and render such a document.
A browser is said to “support” a specification if it handles valid documents according to the rules of the specification. As of yet, no browser supports all aspects of the HTML5 specification (although all of the major browser support most of it), and as a result, it is necessary for the developer to confirm whether the aspect they are making use of will be supported by all of the browsers on which they hope to display their content. This is why cross-browser support continues to be a headache for developers, despite the improved specificiations.
Don’t forget:
HTML5defines some rules to follow for an invalidHTML5document (i.e., one that contains syntactical errors)- However, invalid documents may contain anything, so it’s impossible for the specification to handle all possibilities comprehensively.
- Thus, many decisions about how to handle malformed documents are left up to the browser.
Additional links
What is the difference between HTML and React event handling?
Answer
In HTML, the attribute name is in all lowercase and is given a string invoking a function defined somewhere:
<button onclick="handleClick()"></button>
In React, the attribute name is camelCase and are passed the function reference inside curly braces:
Note that extra re-rendering can occur using this technique because a new function reference is created on render, which gets passed down to child components and breaks shouldComponentUpdate / PureComponent shallow equality checks to prevent unnecessary re-renders. In cases where performance is important, it is preferred to go with bind in the constructor, or the public class fields syntax approach, because the function reference remains constant.
Don’t forget:
- You can either bind methods to the component instance context in the constructor, use public class fields syntax, or use inline arrow functions.
Additional links
What is a MIME type and what is it used for?
Answer
MIME is an acronym for Multi-purpose Internet Mail Extensions. It is used as a standard way of classifying file types over the Internet.
Don’t forget:
- A
MIME typeactually has two parts: a type and a subtype that are separated by a slash (/). For example, theMIME typefor Microsoft Word files isapplication/msword(i.e., type is application and the subtype is msword).
Additional links
Contrast mutable and immutable values, and mutating vs non-mutating methods.
Answer
The two terms can be contrasted as:
- Mutable: subject to change
- Immutable: cannot change
In JavaScript, objects are mutable while primitive values are immutable. This means operations performed on objects can change the original reference in some way, while operations performed on a primitive value cannot change the original value.
All String.prototype methods do not have an effect on the original string and return a new string. On the other hand, while some methods of Array.prototype do not mutate the original array reference and produce a fresh array, some cause mutations.
const myString = "hello!"
myString.replace("!", "") // returns a new string, cannot mutate the original value
const originalArray = [1, 2, 3]
originalArray.push(4) // mutates originalArray, now [1, 2, 3, 4]
originalArray.concat(4) // returns a new array, does not mutate the original
Don’t forget:
- List of mutating and non-mutating array methods
Additional links
What is the only value not equal to itself in JavaScript?
Answer
NaN (Not-a-Number) is the only value not equal to itself when comparing with any of the comparison operators. NaN is often the result of meaningless math computations, so two NaN values make no sense to be considered equal.
Don’t forget:
- The difference between
isNaN()andNumber.isNaN() const isNaN = x => x !== x
Additional links
- MDN docs for
[NaN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/NaN)
NodeJS often uses a callback pattern where if an error is encountered during execution, this error is passed as the first argument to the callback. What are the advantages of this pattern?
fs.readFile(filePath, function(err, data) {
if (err) {
// handle the error, the return is important here
// so execution stops here
return console.log(err)
}
// use the data object
console.log(data)
})
Answer
Advantages include:
- Not needing to process data if there is no need to even reference it
- Having a consistent API leads to more adoption
- Ability to easily adapt a callback pattern that will lead to more maintainable code
As you can see from below example, the callback is called with null as its first argument if there is no error. However, if there is an error, you create an Error object, which then becomes the callback’s only parameter. The callback function allows a user to easily know whether or not an error occurred.
This practice is also called the Node.js error convention, and this kind of callback implementations are called error-first callbacks.
var isTrue = function(value, callback) {
if (value === true) {
callback(null, "Value was true.")
} else {
callback(new Error("Value is not true!"))
}
}
var callback = function(error, retval) {
if (error) {
console.log(error)
return
}
console.log(retval)
}
isTrue(false, callback)
isTrue(true, callback)
/*
{ stack: [Getter/Setter],
arguments: undefined,
type: undefined,
message: 'Value is not true!' }
Value was true.
*/
Don’t forget:
- This is just a convention. However, you should stick to it.
Additional links
What is the event loop in Node.js?
Answer
The event loop handles all async callbacks. Callbacks are queued in a loop, while other code runs, and will run one by one when the response for each one has been received.
Don’t forget:
- The event loop allows Node.js to perform non-blocking I/O operations, despite the fact that JavaScript is single-threaded
Additional links
What is the difference between null and undefined?
Answer
In JavaScript, two values discretely represent nothing — undefined and null. The concrete difference between them is that null is explicit, while undefined is implicit. When a property does not exist or a variable has not been given a value, the value is undefined. null is set as the value to explicitly indicate “no value”. In essence, undefined is used when the nothing is not known, and null is used when the nothing is known.
Don’t forget:
typeof undefinedevaluates to"undefined".typeof nullevaluates"object". However, it is still a primitive value and this is considered an implementation bug in JavaScript.undefined == nullevaluates totrue.
Additional links
Describe the different ways to create an object. When should certain ways be preferred over others?
Answer
Object literal
Often used to store one occurrence of data.
const person = {
name: "John",
age: 50,
birthday() {
this.age++
}
}
person.birthday() // person.age === 51
Constructor
Often used when you need to create multiple instances of an object, each with their own data that other instances of the class cannot affect. The new operator must be used before invoking the constructor or the global object will be mutated.
function Person(name, age) {
this.name = name
this.age = age
}
Person.prototype.birthday = function() {
this.age++
}
const person1 = new Person("John", 50)
const person2 = new Person("Sally", 20)
person1.birthday() // person1.age === 51
person2.birthday() // person2.age === 21
Factory function
Creates a new object similar to a constructor, but can store private data using a closure. There is also no need to use new before invoking the function or the this keyword. Factory functions usually discard the idea of prototypes and keep all properties and methods as own properties of the object.
const createPerson = (name, age) => {
const birthday = () => person.age++
const person = { name, age, birthday }
return person
}
const person = createPerson("John", 50)
person.birthday() // person.age === 51
Object.create()
Sets the prototype of the newly created object.
const personProto = {
birthday() {
this.age++
}
}
const person = Object.create(personProto)
person.age = 50
person.birthday() // person.age === 51
A second argument can also be supplied to Object.create() which acts as a descriptor for the new properties to be defined.
Object.create(personProto, {
age: {
value: 50,
writable: true,
enumerable: true
}
})
Don’t forget:
- Prototypes are objects that other objects inherit properties and methods from.
- Factory functions offer private properties and methods through a closure but increase memory usage as a tradeoff, while classes do not have private properties or methods but reduce memory impact by reusing a single prototype object.
Additional links
What is the difference between a parameter and an argument?
Answer
Parameters are the variable names of the function definition, while arguments are the values given to a function when it is invoked.
function myFunction(parameter1, parameter2) {
console.log(arguments[0]) // "argument1"
}
myFunction("argument1", "argument2")
Don’t forget:
argumentsis an array-like object containing information about the arguments supplied to an invoked function.myFunction.lengthdescribes the arity of a function (how many parameters it has, regardless of how many arguments it is supplied).
Additional links
Does JavaScript pass by value or by reference?
Answer
JavaScript always passes by value. However, with objects, the value is a reference to the object.
Don’t forget:
- Difference between pass-by-value and pass-by-reference
Additional links
How do you pass an argument to an event handler or callback?
Answer
You can use an arrow function to wrap around an event handler and pass arguments, which is equivalent to calling bind:
<button onClick={() => this.handleClick(id)} />
<button onClick={this.handleClick.bind(this, id)} />
Don’t forget:
Additional links
Create a function pipe that performs left-to-right function composition by returning a function that accepts one argument.
const square = v => v * v
const double = v => v * 2
const addOne = v => v + 1
const res = pipe(square, double, addOne)
res(3) // 19; addOne(double(square(3)))
Answer
Gather all supplied arguments using the rest operator ... and return a unary function that uses Array.prototype.reduce() to run the value through the series of functions before returning the final value.
const pipe = (...fns) => x => fns.reduce((v, fn) => fn(v), x)
Don’t forget:
- Function composition is the process of combining two or more functions to produce a new function.
Additional links
What are portals in React?
Answer
Portal are the recommended way to render children into a DOM node that exists outside the DOM hierarchy of the parent component.
ReactDOM.createPortal(child, container)
The first argument (child) is any renderable React child, such as an element, string, or fragment. The second argument (container) is a DOM element.
Don’t forget:
Additional links
What is the difference between the postfix i++ and prefix ++i increment operators?
Answer
Both increment the variable value by 1. The difference is what they evaluate to.
The postfix increment operator evaluates to the value before it was incremented.
let i = 0
i++ // 0
// i === 1
The prefix increment operator evaluates to the value after it was incremented.
let i = 0
++i // 1
// i === 1
Don’t forget:
Additional links
In which states can a Promise be?
Answer
A Promise is in one of these states:
- pending: initial state, neither fulfilled nor rejected.
- fulfilled: meaning that the operation completed successfully.
- rejected: meaning that the operation failed.
A pending promise can either be fulfilled with a value, or rejected with a reason (error). When either of these options happens, the associated handlers queued up by a promise’s then method are called.
Don’t forget:
Additional links
What are Promises?
Answer
The Promise object represents the eventual completion (or failure) of an asynchronous operation, and its resulting value. An example can be the following snippet, which after 100ms prints out the result string to the standard output. Also, note the catch, which can be used for error handling. Promises are chainable.
new Promise((resolve, reject) => {
setTimeout(() => {
resolve("result")
}, 100)
})
.then(console.log)
.catch(console.error)
Don’t forget:
- Take a look into the other questions regarding
Promises!
Additional links
How to apply prop validation in React?
Answer
When the application is running in development mode, React will automatically check for all props that we set on components to make sure they are the correct data type. For incorrect data types, it will generate warning messages in the console for development mode. They are stripped in production mode due to their performance impact. Required props are defined with isRequired.
For example, we define propTypes for component as below:
import PropTypes from "prop-types"
class User extends React.Component {
static propTypes = {
name: PropTypes.string.isRequired,
age: PropTypes.number.isRequired
}
render() {
return (
Welcome, {this.props.name}
Age, {this.props.age}
)
}
}
Don’t forget:
- We can define custom
propTypes - Using
propTypes is not mandatory. However, it is a good practice and can reduce bugs.
propTypespropTypes is not mandatory. However, it is a good practice and can reduce bugs.Additional links
How does prototypal inheritance differ from classical inheritance?
Answer
In the classical inheritance paradigm, object instances inherit their properties and functions from a class, which acts as a blueprint for the object. Object instances are typically created using a constructor and the new keyword.
In the prototypal inheritance paradigm, object instances inherit directly from other objects and are typically created using factory functions or Object.create().
Don’t forget:
Additional links
What is a pure function?
Answer
A pure function is a function that satisfies these two conditions:
- Given the same input, the function returns the same output.
- The function doesn’t cause side effects outside of the function’s scope (i.e. mutate data outside the function or data supplied to the function).
Pure functions can mutate local data within the function as long as it satisfies the two conditions above.
Pure
const a = (x, y) => x + y
const b = (arr, value) => arr.concat(value)
const c = arr => [...arr].sort((a, b) => a - b)
Impure
const a = (x, y) => x + y + Math.random()
const b = (arr, value) => (arr.push(value), arr)
const c = arr => arr.sort((a, b) => a - b)
Don’t forget:
- Pure functions are easier to reason about due to their reliability.
- All functions should be pure unless explicitly causing a side effect (i.e.
setInnerHTML). - If a function does not return a value, it is an indication that it is causing side effects.
Additional links
How do you write comments inside a JSX tree in React?
Answer
Comments must be wrapped inside curly braces {} and use the /* */ syntax.
const tree = (
Text
What is recursion and when is it useful?
Answer
Recursion is the repeated application of a process. In JavaScript, recursion involves functions that call themselves repeatedly until they reach a base condition. The base condition breaks out of the recursion loop because otherwise the function would call itself indefinitely. Recursion is very useful when working with data structures that contain nesting where the number of levels deep is unknown.
For example, you may have a thread of comments returned from a database that exist in a flat array but need to be nested for display in the UI. Each comment is either a top-level comment (no parent) or is a reply to a parent comment. Comments can be a reply of a reply of a reply… we have no knowledge beforehand the number of levels deep a comment may be. This is where recursion can help.
const nest = (items, id = null, link = "parent_id") =>
items
.filter(item => item[link] === id)
.map(item => ({ ...item, children: nest(items, item.id) }))
const comments = [
{ id: 1, parentid: null, text: "First reply to post." },
{ id: 2, parentid: 1, text: "First reply to comment #1." },
{ id: 3, parentid: 1, text: "Second reply to comment #1." },
{ id: 4, parentid: 3, text: "First reply to comment #3." },
{ id: 5, parentid: 4, text: "First reply to comment #4." },
{ id: 6, parentid: null, text: "Second reply to post." }
]
nest(comments)
/*
[
{ id: 1, parentid: null, text: "First reply to post.", children: [...] },
{ id: 6, parentid: null, text: "Second reply to post.", children: [] }
]
*/
In the above example, the base condition is met if filter() returns an empty array. The chained map() won’t invoke the callback function which contains the recursive call, thereby breaking the loop.
Don’t forget:
- Recursion is useful when working with data structures containing an unknown number of nested structures.
- Recursion must have a base condition to be met that breaks out of the loop or it will call itself indefinitely.
Additional links
What is the output of the following code?
const a = [1, 2, 3]
const b = [1, 2, 3]
const c = "1,2,3"
console.log(a == c)
console.log(a == b)
Answer
The first console.log outputs true because JavaScript’s compiler performs type conversion and therefore it compares to strings by their value. On the other hand, the second console.log outputs false because Arrays are Objects and Objects are compared by reference.
Don’t forget:
- JavaScript performs automatic type conversion
- Objects are compared by reference
- Primitives are compared by value
Additional links
What are refs in React? When should they be used?
Answer
Refs provide a way to access DOM nodes or React elements created in the render method. Refs should be used sparringly, but there are some good use cases for refs, such as:
- Managing focus, text selection, or media playback.
- Triggering imperative animations.
- Integrating with third-party DOM libraries.
Refs are created using React.createRef() method and attached to React elements via the ref attribute. In order to use refs throughout the component, assign the ref to the instance property within the constructor:
class MyComponent extends React.Component {
constructor(props) {
super(props)
this.myRef = React.createRef()
}
render() {
return
}
}
Refs can also be used in functional components with the help of closures.
Don’t forget:
- Refs are used to return a reference to an element.
- Refs shouldn’t be overused.
- You can create a ref using
React.createRef()and attach to elements via therefattribute.
Additional links
Where and why is the rel="noopener" attribute used?
Answer
The rel="noopener" is an attribute used in <a> elements (hyperlinks). It prevents pages from having a window.opener property, which would otherwise point to the page from where the link was opened and would allow the page opened from the hyperlink to manipulate the page where the hyperlink is.
Don’t forget:
rel="noopener"is applied to hyperlinks.rel="noopener"prevents opened links from manipulating the source page.
Additional links
What is REST?
Answer
REST (REpresentational State Transfer) is a software design pattern for network architecture. A RESTful web application exposes data in the form of information about its resources.
Generally, this concept is used in web applications to manage state. With most applications, there is a common theme of reading, creating, updating, and destroying data. Data is modularized into separate tables like posts, users, comments, and a RESTful API exposes access to this data with:
- An identifier for the resource. This is known as the endpoint or URL for the resource.
- The operation the server should perform on that resource in the form of an HTTP method or verb. The common HTTP methods are GET, POST, PUT, and DELETE.
Here is an example of the URL and HTTP method with a posts resource:
- Reading:
/posts/=> GET - Creating:
/posts/new=> POST - Updating:
/posts/:id=> PUT - Destroying:
/posts/:id=> DELETE
Don’t forget:
- Alternatives to this pattern like GraphQL
Additional links
What does the following function return?
function greet() {
return
{
message: "hello"
}
}
Answer
Because of JavaScript’s automatic semicolon insertion (ASI), the compiler places a semicolon after return keyword and therefore it returns undefined without an error being thrown.
Don’t forget:
- Automatic semicolon placement can lead to time-consuming bugs
Additional links
Are semicolons required in JavaScript?
Answer
Sometimes. Due to JavaScript’s automatic semicolon insertion, the interpreter places semicolons after most statements. This means semicolons can be omitted in most cases.
However, there are some cases where they are required. They are not required at the beginning of a block, but are if they follow a line and:
- The line starts with
[
const previousLine = 3
;[1, 2, previousLine].map(n => n * 2)
- The line starts with
(
const previousLine = 3
;(function() {
// ...
})()
In the above cases, the interpreter does not insert a semicolon after 3, and therefore it will see the 3 as attempting object property access or being invoked as a function, which will throw errors.
Don’t forget:
- Semicolons are usually optional in JavaScript but have edge cases where they are required.
- If you don’t use semicolons, tools like Prettier will insert semicolons for you in the places where they are required on save in a text editor to prevent errors.
Additional links
What is short-circuit evaluation in JavaScript?
Answer
Short-circuit evaluation involves logical operations evaluating from left-to-right and stopping early.
true || false
In the above sample using logical OR, JavaScript won’t look at the second operand false, because the expression evaluates to true regardless. This is known as short-circuit evaluation.
This also works for logical AND.
false && true
This means you can have an expression that throws an error if evaluated, and it won’t cause issues.
true || nonexistentFunction()
false && nonexistentFunction()
This remains true for multiple operations because of left-to-right evaluation.
true || nonexistentFunction() || window.nothing.wouldThrowError
true || window.nothing.wouldThrowError
true
A common use case for this behavior is setting default values. If the first operand is falsy the second operand will be evaluated.
const options = {}
const setting = options.setting || "default"
setting // "default"
Another common use case is only evaluating an expression if the first operand is truthy.
// Instead of:
addEventListener("click", e => {
if (e.target.closest("button")) {
handleButtonClick(e)
}
})
// You can take advantage of short-circuit evaluation:
addEventListener(
"click",
e => e.target.closest("button") && handleButtonClick(e)
)
In the above case, if e.target is not or does not contain an element matching the "button" selector, the function will not be called. This is because the first operand will be falsy, causing the second operand to not be evaluated.
Don’t forget:
- Logical operations do not produce a boolean unless the operand(s) evaluate to a boolean.
Additional links
What are the advantages of using CSS sprites and how are they utilized?
Answer
CSS sprites combine multiple images into one image, limiting the number of HTTP requests a browser has to make, thus improving load times. Even under the new HTTP/2 protocol, this remains true.
Under HTTP/1.1, at most one request is allowed per TCP connection. With HTTP/1.1, modern browsers open multiple parallel connections (between 2 to 8) but it is limited. With HTTP/2, all requests between the browser and the server are multiplexed on a single TCP connection. This means the cost of opening and closing multiple connections is mitigated, resulting in a better usage of the TCP connection and limits the impact of latency between the client and server. It could then become possible to load tens of images in parallel on the same TCP connection.
However, according to benchmark results, although HTTP/2 offers 50% improvement over HTTP/1.1, in most cases the sprite set is still faster to load than individual images.
To utilize a spritesheet in CSS, one would use certain properties, such as background-image, background-position and background-size to ultimately alter the background of an element.
Don’t forget:
background-image,background-positionandbackground-sizecan be used to utilize a spritesheet.
Additional links
What is a stateful component in React?
Answer
A stateful component is a component whose behavior depends on its state. This means that two separate instances of the component if given the same props will not necessarily render the same output, unlike pure function components.
// Stateful class component
class App extends Component {
constructor(props) {
super(props)
this.state = { count: 0 }
}
render() {
// ...
}
}
// Stateful function component
function App() {
const [count, setCount] = useState(0)
return // ...
}
Don’t forget:
- Stateful components have internal state that they depend on.
- Stateful components are class components or function components that use stateful Hooks.
- Stateful components have their state initialized in the constructor or with
useState().
Additional links
What is a stateless component?
Answer
A stateless component is a component whose behavior does not depend on its state. Stateless components can be either functional or class components. Stateless functional components are easier to maintain and test since they are guaranteed to produce the same output given the same props. Stateless functional components should be preferred when lifecycle hooks don’t need to be used.
Don’t forget:
- Stateless components are independent of their state.
- Stateless components can be either class or functional components.
- Stateless functional components avoid the
thiskeyword altogether.
Additional links
Explain the difference between a static method and an instance method.
Answer
Static methods belong to a class and don’t act on instances, while instance methods belong to the class prototype which is inherited by all instances of the class and acts on them.
Array.isArray // static method of Array
Array.prototype.push // instance method of Array
In this case, the Array.isArray method does not make sense as an instance method of arrays because we already know the value is an array when working with it.
Instance methods could technically work as static methods, but provide terser syntax:
const arr = [1, 2, 3]
arr.push(4)
Array.push(arr, 4)
Don’t forget:
- How to create static and instance methods with ES2015 class syntax
Additional links
What is the difference between synchronous and asynchronous code in JavaScript?
Answer
Synchronous means each operation must wait for the previous one to complete.
Asynchronous means an operation can occur while another operation is still being processed.
In JavaScript, all code is synchronous due to the single-threaded nature of it. However, asynchronous operations not part of the program (such as XMLHttpRequest or setTimeout) are processed outside of the main thread because they are controlled by native code (browser APIs), but callbacks part of the program will still be executed synchronously.
Don’t forget:
- JavaScript has a concurrency model based on an “event loop”.
- Functions like
alertblock the main thread so that no user input is registered until the user closes it.
Additional links
What is the this keyword and how does it work?
Answer
The this keyword is an object that represents the context of an executing function. Regular functions can have their this value changed with the methods call(), apply() and bind(). Arrow functions implicitly bind this so that it refers to the context of its lexical environment, regardless of whether or not its context is set explicitly with call().
Here are some common examples of how this works:
Object literals
this refers to the object itself inside regular functions if the object precedes the invocation of the function.
Properties set as this do not refer to the object.
var myObject = {
property: this,
regularFunction: function() {
return this
},
arrowFunction: () => {
return this
},
iife: (function() {
return this
})()
}
myObject.regularFunction() // myObject
myObject["regularFunction"]() // my Object
myObject.property // NOT myObject; lexical `this`
myObject.arrowFunction() // NOT myObject; lexical `this`
myObject.iife // NOT myObject; lexical `this`
const regularFunction = myObject.regularFunction
regularFunction() // NOT myObject; lexical `this`
Event listeners
this refers to the element listening to the event.
document.body.addEventListener("click", function() {
console.log(this) // document.body
})
Constructors
this refers to the newly created object.
class Example {
constructor() {
console.log(this) // myExample
}
}
const myExample = new Example()
Manual
With call() and apply(), this refers to the object passed as the first argument.
var myFunction = function() {
return this
}
myFunction.call({ customThis: true }) // { customThis: true }
Unwanted this
Because this can change depending on the scope, it can have unexpected values when using regular functions.
var obj = {
arr: [1, 2, 3],
doubleArr() {
return this.arr.map(function(value) {
// this is now this.arr
return this.double(value)
})
},
double() {
return value * 2
}
}
obj.doubleArr() // Uncaught TypeError: this.double is not a function
Don’t forget:
- In non-strict mode, global
thisis the global object (windowin browsers), while in strict mode globalthisisundefined. Function.prototype.callandFunction.prototype.applyset thethiscontext of an executing function as the first argument, withcallaccepting a variadic number of arguments thereafter, andapplyaccepting an array as the second argument which are fed to the function in a variadic manner.Function.prototype.bindreturns a new function that enforces thethiscontext as the first argument which cannot be changed by other functions.- If a function requires its
thiscontext to be changed based on how it is called, you must use thefunctionkeyword. Use arrow functions when you wantthisto be the surrounding (lexical) context.
Additional links
[this](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/this)on MDN
What does the following code evaluate to?
typeof typeof 0
Answer
It evaluates to "string".
typeof 0 evaluates to the string "number" and therefore typeof "number" evaluates to "string".
Don’t forget:
Additional links
What are JavaScript data types?
Answer
The latest ECMAScript standard defines seven data types, six of them being primitive: Boolean, Null, Undefined, Number, String, Symbol and one non-primitive data type: Object.
Don’t forget:
- Mention of newly added
Symboldata type Array,Dateandfunctionare all of typeobject- Functions in JavaScript are objects with the capability of being callable
Additional links
What is the purpose of JavaScript UI libraries/frameworks like React, Vue, Angular, Hyperapp, etc?
Answer
The main purpose is to avoid manipulating the DOM directly and keep the state of an application in sync with the UI easily. Additionally, they provide the ability to create components that can be reused when they have similar functionality with minor differences, avoiding duplication which would require multiple changes whenever the structure of a component which is reused in multiple places needs to be updated.
When working with DOM manipulation libraries like jQuery, the data of an application is generally kept in the DOM itself, often as class names or data attributes. Manipulating the DOM to update the UI involves many extra steps and can introduce subtle bugs over time. Keeping the state separate and letting a framework handle the UI updates when the state changes reduces cognitive load. Saying you want the UI to look a certain way when the state is a certain value is the declarative way of creating an application, instead of the imperative way of manually updating the UI to reflect the new state.
Don’t forget:
- The virtual DOM is a representation of the real DOM tree in the form of plain objects, which allows a library to write code as if the entire document is thrown away and rebuilt on each change, while the real DOM only updates what needs to be changed. Comparing the new virtual DOM against the previous one leads to high efficiency as changing real DOM nodes is costly compared to recalculating the virtual DOM.
- JSX is an extension to JavaScript that provides XML-like syntax to create virtual DOM objects which is transformed to function calls by a transpiler. It simplifies control flow (if statements/ternary expressions) compared to tagged template literals.
Additional links
What does 'use strict' do and what are some of the key benefits to using it?
Answer
Including 'use strict' at the beginning of your JavaScript source file enables strict mode, which enforces more strict parsing and error handling of JavaScript code. It is considered a good practice and offers a lot of benefits, such as:
- Easier debugging due to eliminating silent errors.
- Disallows variable redefinition.
- Prevents accidental global variables.
- Oftentimes provides increased performance over identical code that is not running in strict mode.
- Simplifies
eval()andarguments. - Helps make JavaScript more secure.
Don’t forget:
- Eliminates
thiscoercion, throwing an error whenthisreferences a value ofnullorundefined. - Throws an error on invalid usage of
delete. - Prohibits some syntax likely to be defined in future versions of ECMAScript
Additional links
What are the differences between var, let, const and no keyword statements?
Answer
No keyword
When no keyword exists before a variable assignment, it is either assigning a global variable if one does not exist, or reassigns an already declared variable. In non-strict mode, if the variable has not yet been declared, it will assign the variable as a property of the global object (window in browsers). In strict mode, it will throw an error to prevent unwanted global variables from being created.
var
var was the default statement to declare a variable until ES2015. It creates a function-scoped variable that can be reassigned and redeclared. However, due to its lack of block scoping, it can cause issues if the variable is being reused in a loop that contains an asynchronous callback because the variable will continue to exist outside of the block scope.
Below, by the time the the setTimeout callback executes, the loop has already finished and the i variable is 10, so all ten callbacks reference the same variable available in the function scope.
Resources:
Resources:
https://gist.github.com/bgoonz/e3f9e82a133b0a8dca00f61d9ddcd62b
Here’s the code from this article:
for (var i = 0; i < 10; i++) {
setTimeout(() => {
// logs `10` ten times
console.log(i)
})
}
/* Solutions with `var` */
for (var i = 0; i < 10; i++) {
// Passed as an argument will use the value as-is in
// that point in time
setTimeout(console.log, 0, i)
}
for (var i = 0; i < 10; i++) {
// Create a new function scope that will use the value
// as-is in that point in time
;(i => {
setTimeout(() => {
console.log(i)
})
})(i)
}
let
let was introduced in ES2015 and is the new preferred way to declare variables that will be reassigned later. Trying to redeclare a variable again will throw an error. It is block-scoped so that using it in a loop will keep it scoped to the iteration.
for (let i = 0; i < 10; i++) {
setTimeout(() => {
// logs 0, 1, 2, 3, ...
console.log(i)
})
}
const
const was introduced in ES2015 and is the new preferred default way to declare all variables if they won’t be reassigned later, even for objects that will be mutated (as long as the reference to the object does not change). It is block-scoped and cannot be reassigned.
const myObject = {}
myObject.prop = "hello!" // No error
myObject = "hello" // Error
Don’t forget:
- All declarations are hoisted to the top of their scope.
- However, with
letandconstthere is a concept called the temporal dead zone (TDZ). While the declarations are still hoisted, there is a period between entering scope and being declared where they cannot be accessed. - Show a common issue with using
varand howletcan solve it, as well as a solution that keepsvar. varshould be avoided whenever possible and preferconstas the default declaration statement for all variables unless they will be reassigned later, then useletif so.
Additional links
[let](https://wesbos.com/let-vs-const/)vs[const](https://wesbos.com/let-vs-const/)
What is a virtual DOM and why is it used in libraries/frameworks?
Answer
The virtual DOM (VDOM) is a representation of the real DOM in the form of plain JavaScript objects. These objects have properties to describe the real DOM nodes they represent: the node name, its attributes, and child nodes.
<div class="counter"> <h1>0</h1> <button>-</button> <button>+</button></div>
The above markup’s virtual DOM representation might look like this:
{
nodeName: "div",
attributes: { class: "counter" },
children: [
{
nodeName: "h1",
attributes: {},
children: [0]
},
{
nodeName: "button",
attributes: {},
children: ["-"]
},
{
nodeName: "button",
attributes: {},
children: ["+"]
}
]
}
The library/framework uses the virtual DOM as a means to improve performance. When the state of an application changes, the real DOM needs to be updated to reflect it. However, changing real DOM nodes is costly compared to recalculating the virtual DOM. The previous virtual DOM can be compared to the new virtual DOM very quickly in comparison.
Once the changes between the old VDOM and new VDOM have been calculated by the diffing engine of the framework, the real DOM can be patched efficiently in the least time possible to match the new state of the application.
Don’t forget:
- Why accessing the DOM can be so costly.
Additional links
What is WCAG? What are the differences between A, AA, and AAA compliance?
Answer
WCAG stands for “Web Content Accessibility Guidelines”. It is a standard describing how to make web content more accessible to people with disabilities They have 12-13 guidelines and for each one, there are testable success criteria, which are at three levels: A, AA, and AAA. The higher the level, the higher the impact on the design of the web content. The higher the level, the web content is essentially more accessible by more users. Depending on where you live/work, there may be regulations requiring websites to meet certain levels of compliance. For instance, in Ontario, Canada, beginning January 1, 2021 all public websites and web content posted after January 1, 2012 must meet AA compliance.
Don’t forget:
- A guideline for making web content more accessible
- 3 different levels (A, AA, and AAA) of compliance for each guideline
- Governments are starting to require web content to meet a certain level of compliance by law
Additional links
What is a cross-site scripting attack (XSS) and how do you prevent it?
Answer
XSS refers to client-side code injection where the attacker injects malicious scripts into a legitimate website or web application. This is often achieved when the application does not validate user input and freely injects dynamic HTML content.
For example, a comment system will be at risk if it does not validate or escape user input. If the comment contains unescaped HTML, the comment can inject a <script> tag into the website that other users will execute against their knowledge.
- The malicious script has access to cookies which are often used to store session tokens. If an attacker can obtain a user’s session cookie, they can impersonate the user.
- The script can arbitrarily manipulate the DOM of the page the script is executing in, allowing the attacker to insert pieces of content that appear to be a real part of the website.
- The script can use AJAX to send HTTP requests with arbitrary content to arbitrary destinations.
Don’t forget:
- On the client, using
textContentinstead ofinnerHTMLprevents the browser from running the string through the HTML parser which would execute scripts in it. - On the server, escaping HTML tags will prevent the browser from parsing the user input as actual HTML and therefore won’t execute the script.
Additional links
Resources:
Resources:
https://gist.github.com/bgoonz/e3f9e82a133b0a8dca00f61d9ddcd62b
THE CODE:
https://gist.github.com/bgoonz/e4b19c1425ffce9744b23a7d337e147e
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://trusting-dijkstra-4d3b17.netlify.app/https://trusting-dijkstra-4d3b17.netlify.app/
Or Checkout my personal Resource Site:
https://trusting-dijkstra-4d3b17.netlify.app/
“If you want to build a ship, don’t drum up the men and women to gather wood, divide the work, and give orders. Instead, teach them to yearn for the vast and endless sea.” — Antoine de Saint-Exupery;

**HTTP**: Hypertext Transfer Protocol.**HT**: Hypertext – content with references to other content.- Term used to refer to content in computing.
- What makes the Web a “web”.
- Most fundamental part of how we interact.
**Hyperlinks**: Links; references between HT resources.**TP**: Transfer Protocol – set of guidelines surrounding the transmission of data.- Defines the expectations for both ends of the transer.
- Defines some ways the transfer might fail.
- HTTP is a
**request/response**protocol. - HTTP works between
**clients**&**servers**. **Clients**: User Agent – the data consumer.**Servers**: Origin – Data provider & where the application is running.

Components of HTTP-based systems
HTTP is a client-server protocol: requests are sent by one entity, the user-agent (or a proxy on behalf of it). Most of the time the user-agent is a Web browser, but it can be anything, for example a robot that crawls the Web to populate and maintain a search engine index.
Each individual request is sent to a server, which handles it and provides an answer, called the response. Between the client and the server there are numerous entities, collectively called proxies, which perform different operations and act as gateways or caches, for example.

Properties of HTTP
**Reliable Connections**: Messages passed between a client & server sacrifice a little speed for the sake of trust.**TCP**is HTTP’s preferred connection type.**Stateless Transfer**: HTTP is a stateless protocol – meaning it does not store any kind of information.- HTTP supports cookies.
**Intermediaries**: Servers or devices that pass your request along which come in three types:**Proxies**: Modify your request so it appears to come from a different source.**Gateways**: Pretend to be the resource server you requested.**Tunnels**: Simply passes your request along.
HTTP Requests
Structure of an HTTP Request
GET / HTTP/1.1Host: appacademy.ioConnection: keep-aliveUpgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3Accept-Encoding: gzip, deflateAccept-Language: en-US,en;q=0.9
Example of a request:
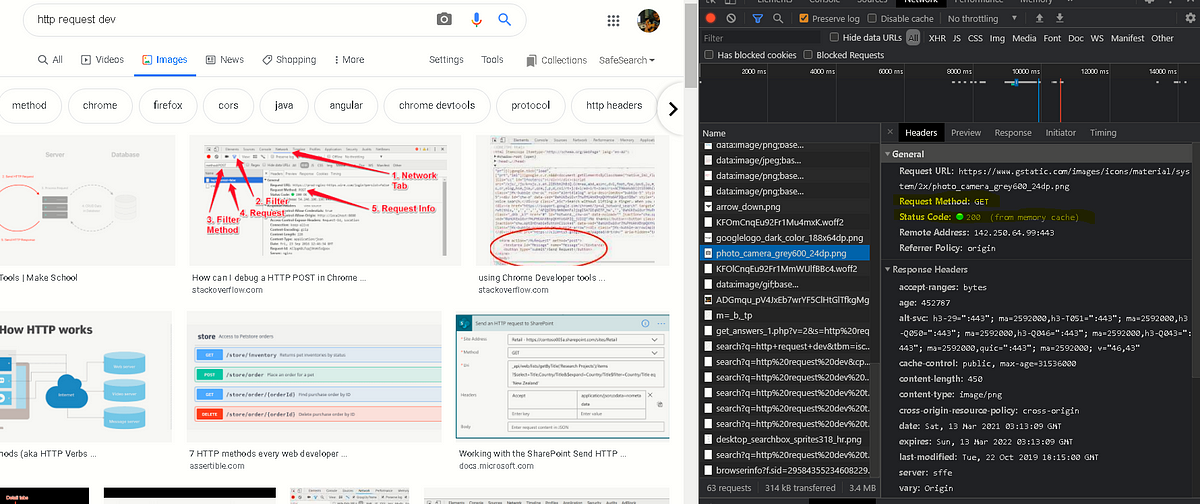
- Request-line & HTTP verbs
- The first line of an HTTP Request made up of three parts:
- The
**Method**: Indicated by an HTTP Verb. - The
**URI**: Uniform Resource Indicator that ID’s our request. - THe
**HTTP**Version : Version we expect to use. - HTTP Verbs are a simply way of declaring our intention to the server.
**GET**: Used for direct requests.**POST**: Used for creating new resources on the server.**PUT**: Used to updated a resource on the server.**PATCH**: Similar to PUT, but do not require the whole resource to perform the update.**DELETE**: Used to destroy resources on the server.
Headers
- Key-Value pairs that come after the request line — they appear on sep. lines and define metadata needed to process the request.
- Some common headers:
**Host**: Root path for our URI.**User-Agent**: Displays information about which browser the request originated from.**Referer**: Defines the URL you’re coming from.**Accept**: Indicates what the client will receive.**Content**– : Define Details about the body of the request.
Body
- For when we need to send data that doesn’t fit into the header & is too complex for the URI we can use the body.
**URL encoding**: Most common way form data is formatted.name=claire&age=29&iceCream=vanilla- We can also format using JSON or XML.
Sending an HTTP request from the command line
- netcat : (nc) A Utility that comes as part of Unix-line environments such as Ubuntu and macOS.
- Allows us to open a direct connection with a URL and manually send HTTP requests.
nc -v appacademy.io 80man ncto open the netcat manual.
HTTP Responses
Structure of a Response
HTTP/1.1 200 OKContent-Type: text/html; charset=utf-8Transfer-Encoding: chunkedConnection: closeX-Frame-Options: SAMEORIGINX-Xss-Protection: 1; mode=blockX-Content-Type-Options: nosniffCache-Control: max-age=0, private, must-revalidateSet-Cookie: _rails-class-site_session=BAh7CEkiD3Nlc3Npb25faWQGOgZFVEkiJTM5NWM5YTVlNTEyZDFmNTNlN; path=/; secure; HttpOnlyX-Request-Id: cf5f30dd-99d0-46d7-86d7-6fe57753b20dX-Runtime: 0.006894Strict-Transport-Security: max-age=31536000Vary: OriginVia: 1.1 vegurExpect-CT: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"Server: cloudflareCF-RAY: 51d641d1ca7d2d45-TXL
<!DOCTYPE html><html>......</html>
Status
- First line of an HTTP response — gives us a high level overview of the server’s intentions. (
**status line**) HTTP/1.1 200 OK**HTTP status codes**: numeric way of representing a server’s response.- Follow the structure: x: xxx — xxx;
**Status codes 100 - 199: Informational**
- Allow the clinet to know that a req. was received, and provides extra info from the server.
**Status codes 200 - 299: Successful**
- Indicate that the request has succeeded and the server is handling it.
- Common Examples: 200 OK (req received and fulfilled) & 201 Created (received and new record was created)
**Status codes 300 - 399: Redirection**
- Let the client know if there has been a change.
- Common Examples: 301 Moved Permanently (resource you requested is in a totally new location) & 302 Found (indicates a temporary move)
**Status codes 400 - 499: Client Error**
- Indicate problem with client’s request.
- Common Examples: 400 Bad Request (received, but could not understand) & 401 Unauthorized (resource exists but you’re not allowed to see w/o authentication) & 403 Forbidden (resource exists but you’re not allowed to see it at all ) & 404 Not Found (resource requested does not exist);
**Status codes 500 - 599: Server Error**
- Indicates request was formatted correctly, but the server couldn’t do what you asked due to an internal problem.
- Common Examples: 500 Internal Server Error (Server had trouble processing) & 504 Gateway Timeout (Server timeout);
Headers : Work just like HTTP requests.
Common Examples:
**Location**: Used by client for redirection responses.**Content-Type**: Let’s client know what format the body is in.**Expires**: When response is no longer valid**Content-Disposition**: Let’s client know how to display the response.**Set-Cookie**: Sends data back to the client to set on the cookie.**Data**: If the request is successful, the body of the response will contain the resource you have requested.
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://gist.github.com/bgoonzhttps://gist.github.com/bgoonz
Or Checkout my personal Resource Site:
Currently under development and very buggy!
https://gist.github.com/bgoonz
If you want to learn more and get some practice in … download Postman and start going through some tutorials!
Happy Coding!
My Awesome JavaScript List Part 2

Here’s the rest of my stash!
…well… not really… here’s the rest of my stash:
https://github.com/bgoonz/Cumulative-Resource-List/tree/master/README-s
Web Development frameworks
· Next.js — Framework for server-rendered or statically-exported React apps.
· San — Flexible JavaScript component framework.
· hapi — Rich framework for building applications and services.
· Koa — Smaller, more expressive, and more robust foundation for web applications and APIs.
· Umi — Pluggable enterprise-level react application framework.
· Vue.js — Progressive JavaScript Framework.
· Mithril — Modern client-side Javascript framework for building Single Page Applications. (HN)
· Solid — Declarative, efficient, and flexible JavaScript library for building user interfaces.
· Neutrino dev
· Alpine.js — Rugged, minimal framework for composing JavaScript behavior in your markup. (Awesome Alpine)
· After.js — Next.js-like framework for server-rendered React apps built with React Router 4.
· Torus — Event-driven model-view UI framework for the web, focused on being tiny, efficient, and free of dependencies. (Web)
· Hyperapp — Tiny framework for building web interfaces. (Web) (HN) (Hyperawesome)
· Hyperapp FX — Effects for use with Hyperapp.
· Phenomic — Modular website compiler (React, Webpack, Reason and whatever you want).
· Halfmoon — Front-end framework with a built-in dark mode and full customizability using CSS variables; great for building dashboards and tools. (Docs)
· Sinuous — Low-level UI library with a tiny footprint. (Docs)
· Overture — Powerful JS library for building really slick web applications, with performance at, or surpassing, native apps.
· Ractive.js — Next-generation DOM manipulation.
· JSX Lite — Write components once, run everywhere. Compiles to Vue, React, Solid, Liquid, and more.
· Perlite — Hyperactiv + lit-html + extensions. Simple and declarative way to create rich client-side widgets designed with server-side apps in mind.
· Democrat — Library that mimic the API of React (Components, hooks, Context…) but instead of producing DOM mutation it produces a state tree.
· Raj — Elm Architecture for JavaScript.
· Reframe — New kind of web framework.
· observablehq/stdlib — Observable standard library.
· Typera — Type-safe routes for Express and Koa.
· Frourio — Fast and type-safe full stack framework, for TypeScript. (Web)
· Svelto — Modular front end framework for modern browsers, with battery included: 100+ widgets and tools.
· modular — Collection of tools and guidance to enable UI development at scale. (Tweet)
· Turbo — Speed of a single-page web application without having to write any JavaScript. (Web)
· Fre — Tiny Coroutine framework with Fiber.
· Glimmer — Fast and light-weight UI components for the web. (Code)
· Glimmer VM — Flexible, low-level rendering pipeline for building a “live” DOM from Handlebars templates that can subsequently be updated cheaply when data changes.
· frint — Modular JavaScript framework for building scalable and reactive applications.
· Nano Router — Framework agnostic minimalistic router with a focus on named routes.
· tiny-request-router — Fast, generic and type safe router (match request method and path).
· Synergy — Tiny runtime library for building web user interfaces. (HN)
· dflex — JavaScript Project to Manipulate DOM Elements.
· morphdom — Fast and lightweight DOM diffing/patching (no virtual DOM needed).
· Forgo — Ultra-light UI runtime. Makes it super easy to create modern web apps using JSX (like React).
· Whats Up — Front-end framework based on ideas of streams and fractals.
· Boost — Collection of type-safe cross-platform packages for building robust server-side and client-side systems.
· Nostalgie — Opinionated, full-stack, runtime-agnostic framework for building web apps and web pages using react. (Web)
· Lumino — Library for building interactive web applications.
Animation
· Anime.js — JavaScript animation engine.
· popmotion — Functional, reactive animation library.
· impress.js — Presentation framework based on the power of CSS3 transforms and transitions.
· Pts — Library for visualization and creative-coding.
· lax.js — Simple & light weight (<2kb gzipped) vanilla JS plugin to create smooth & beautiful animations when you scroll.
· Flipping — Library (and collection of adapters) for implementing FLIP transitions.
· Ola — Smooth animation library for interpolating numbers.
· react-spring — Spring physics based React animation library.
· FAT — Web’s fastest and most lightweight animation tool.
· React Easy Flip — Lightweight React library for smooth FLIP animations.
· AOS — Animate on scroll library.
· flubber — Tools for smoother shape animations.
CLI
· qoa — Minimal interactive command-line prompts.
Test
· Unexpected — Extensible BDD assertion toolkit. (Docs)
· Fishery — Library for setting up JavaScript objects as test data.
· pentf — Parallel end-to-end test framework.
· test-flat — Test framework extension to support resources teardown and cleanup in flat tests.
· zora — Lightest, yet Fastest JavaScript test runner for nodejs and browsers.
· Vest — Declarative Validation Testing.
State management
· Mutik — Tiny (495B) immutable state management library based on Immer.
· Storeon — Tiny event-based Redux-like state manager for React and Preact.
· Overstated — React state management library that’s delightful to use, without sacrificing performance or scalability.
· Effector — Reactive state manager. (Awesome) (Docs) (effector-storage)
· Akita — State Management Tailored-Made for JS Applications.
· Observable Store — Provides a simple way to manage state in Angular, React, Vue.js and other front-end applications.
· Cerebral — Declarative state and side effects management solution for popular JavaScript frameworks.
· Hooksy — State management solution based on react hooks.
· React Easy State — Simple React state management. Made with
· wana — Easy observable state for React.
· Recoil — Experimental set of utilities for state management with React. (Web) (Video) (Reddit) (Rewriting from scratch) (Recoilize — Recoil developer tool)
· State Designer — JavaScript and TypeScript library for managing the state of a user interface.
· Fluxible — Pluggable container for universal flux applications.
· Logux State — Tiny state manager with CRDT, cross-tab, and Logux support.
· Statery — Surprise-Free State Management. Designed for React with functional components.
API bindings
DB
· sql.js — SQLite compiled to JavaScript. Allows you to create a relational database and query it entirely in the browser. (Docs) (HN)
· SQigiL — Postgres SQL template string for Javascript.
· Postgrest JS — Isomorphic JavaScript client for PostgREST.
· Connect PG Simple — Simple, minimal PostgreSQL session store for Express/Connect.
React
This is gonna be a big section….
· state-machines-in-react — Small React, xstate and Framer Motion demo.
UI Components
Table / Data Grid
reactable — Fast, flexible, and simple data tables in React.
ag-grid — Advanced Data Grid / Data Table supporting Javascript / React / AngularJS / Web Components.
griddle-react — Simple Grid Component written in React.
react-data-components — React components for sorting, filtering and pagination of data.
react-bootstrap-table — It’ s a react table for bootstrap.
react-data-grid — Excel-like grid component built with React, with editors, keyboard navigation, copy & paste, and the like.
react-pivot — React-Pivot is a data-grid component with pivot-table-like functionality for data display, filtering, and exploration.
autoresponsive-react — Auto Responsive Layout Library For React.
reactabular — Spectacular tables for React.
fixed-data-table — A React table component designed to allow presenting thousands of rows of data.
sematable — Client side sorting, pagination, and text filter for redux/react based apps.
Infinite Scroll
react-lazyload — Lazyload your Component, Image or anything matters the performance.
react-infinity — A UITableView Inspired list and grid display solution with element culling and smooth animations.
react-infinite — A browser-ready efficient scrolling container based on UITableView.
react-infinite-grid — A React component which renders a grid of elements.
react-list — A versatile infinite scroll React component.
react-virtualized — React components for efficiently rendering large lists and tabular data.
Overlay
Display overlay / modal / alert / dialog / lightbox / popup
react-dock — Resizable dockable react component.
react-overlays — Utilities for creating robust overlay components.
boron — A collection of dialog animations with React.js.
react-modal2 — Simple modal component for React.
react-modal — Accessible modal dialog component for React.
react-skylight — A react component for modals and dialogs.
rodal — A React modal with animations.
react-modal-box — React Modal Box Component.
react-aria-modal — A fully accessible and flexible React modal built according WAI-ARIA Authoring Practices.
Notification
Toaster / snackbar — Notify the user with a modeless temporary little popup
react-notification-system — A complete and totally customizable component for notifications in React.
react-notification — Snackbar notifications for React.
react-s-alert — Alerts / Notifications for React with rich configuration options.
react-crouton — A message component for reactjs.
reapop — A React & Redux notifications system.
Tooltip
react-tooltip — React tooltip component.
rc-tooltip — React Tooltip.
react-portal-tooltip — Awesome React tooltips.
Menu
Menus / sidebars
react-burger-menu — An off-canvas sidebar component with a collection of effects and styles using CSS transitions and SVG path animations.
react-sidebar — A sidebar component for React.
react-motion-menu — Motion menu component powered by React Motion.
react-offcanvas — Off-canvas menus for React.
react-tree-menu — A stateless tree menu component for React.
react-metismenu — A ready-to-use menu component for React.
react-contextmenu — Context Menu implemented in React.
rc-menu — React Menu.
Sticky
Fixed headers / scroll-up headers / sticky elements
react-sticky — < Sticky /> component for awesome React apps.
react-headroom — Hide your header until you need it.
react-listview-sticky-header — React listview with sticky section header.
react-sticky-state — React StickyState Component makes native position:sticky statefull and polyfills the missing sticky browser feature.
react-stickynode — A performant and comprehensive React sticky.
react-sticky-node — Sticky react component.
Tabs
react-tabs — React tabs component.
react-simpletabs — Just a simple tabs component built with React.
react-tabtab — React, tabs.
Loader
Loaders / spinners / progress bars — Let the user know that something is loading
halogen — A collection of loading spinners with React.js.
react-ladda — React wrapper for Ladda buttons.
react-progress-button — Simple react.js component for an inline progress indicator.
react-loader — React component that displays a spinner via spin.js until your component is loaded.
react-spinkit — A collection of loading indicators animated with CSS for React.
react-progress-label — Progress label component.
react-redux-loading-bar — Simple Loading Bar for Redux and React.
react-loaders — Lightweight wrapper around Loaders.css.
react-md-spinner — Material Design spinner components for React.js.
rc-progress — React Progress Bar.
react-block-ui — Easy way to block the user from interacting with your UI.
Carousel
react-slick — React carousel component.
react-responsive-carousel — React.js Responsive Carousel (with Swipe).
Collapse
react-collapse — Component-wrapper for collapse animation with react-motion for elements with variable (and dynamic) height.
react-accessible-accordion — Accessible Accordion component for React.
Chart
Display data in charts / graphs / diagrams
react-chartist — React component for Chartist.js.
d3-react-squared — Lightweight event system for (d3) charts and other components for ReactJS.
react-d3-components — D3 Components for React.
recharts — Redefined chart library built with React and D3.
react-chartjs — Common react charting components using chart.js.
react-dazzle — Dashboards made easy in React JS.
react-vis — Data visualization library based on React and d3.
react-sparkline — React component for rendering simple sparklines.
react-sparklines — Beautiful and expressive Sparklines React component.
rumble-charts — React components for building composable and flexible charts.
react-micro-bar-chart — React component for micro bar-charts rendered with D3.
react-timeseries-charts — Declarative timeseries charts.
react-google-charts — React-google-charts React component.
victory — Data viz for React.
react-sigmajs — Lightweight but powerful library for drawing network graphs built on top of SigmaJS.
chartify — React.js plugin for building animated draggable and customizable charts.
react-highcharts — React-highcharts.
react-trend — Simple, elegant spark lines.
Tree
Display a tree data structure
react-treeview — Easy, light, flexible tree view made with React.
react-ui-tree — React tree component.
react-treebeard — React Tree View Component. Data-Driven, Fast, Efficient and Customisable.
UI Navigation
Ways to navigate views
react-scroll — React scroll component.
react-swipe-views — A React Component for binded Tabs and Swipeable Views.
Custom Scrollbar
react-custom-scrollbars — React scrollbars component.
react-scrollbar — Scrollbar component for React.
react-smooth-scrollbar — React implementation of smooth-scrollbar.
react-gemini-scrollbar — React component for custom overlay-scrollbars with native scrolling mechanism.
react-custom-scroll — Easily customize the browser scroll bar with native OS scroll behavior.
Audio / Video
react-player — A react component for playing a variety of URLs, including file paths, YouTube, SoundCloud and Vimeo.
react-youtube — React.js powered YouTube player component.
react-soundplayer — Create custom SoundCloud players with React.
react-video — React component to load video from Vimeo or Youtube across any device.
react-music — Make beats with React.
react-dailymotion — Dailymotion player component for React.
video-react — A web video player built for the HTML5 world using React library.
Map
react-gmaps — A Google Maps component for React.js.
google-map-react — Universal google map react component, allows render react components on the google map.
react-googlemaps — A declarative React interface to Google Maps.
react-leaflet — React components for Leaflet maps.
react-geosuggest — A React autosuggest for the Google Maps Places API.
react-map-gl — A React wrapper for MapboxGL-js and overlay API.
react-mapbox-gl — A React binding of mapbox-gl-js.
Time / Date / Age
Display time / date / age
react-time — Component for React to render relative and/or formatted dates into < time> HTML5 element.
react-timeago — A simple time-ago component for ReactJs.
timeago-react — Simple and efficient react component to format date with
*** time agostatement. eg: ‘3 hours ago’.
Photo / Image
Display images / photos
react-image-gallery — Responsive image gallery, carousel, image slider react component.
react-images — A simple lightbox component for displaying an array of images.
react-photo-gallery — Responsive React Photo Gallery.
react-svg-pan-zoom — A React component that adds pan and zoom features to SVG.
react-image-lightbox — React lightbox component.
react-intense — A React component for viewing large images up close.
Icons
Display icons / icon set / emojis
react-icons — Svg react icons of popular icon packs using ES6 imports.
react-emoji — An emoji mixin for React.
react-emoji-react — A clone of slack emoji reactions in react.
Paginator
Display a control element to paginate
react-paginate — A ReactJS component that creates a pagination.
Markdown Viewer
Display parsed markdow source
react-markdown — Render Markdown as React components.
Miscellaneous
react-timesheet — Time Sheet Component for React.
react-blur — React component for blurred backgrounds.
react-split-pane — React split-pane component.
typography — A powerful toolkit for building websites with beautiful typography.
react-json-tree — React JSON Viewer Component, Extracted from redux-devtools.
react-resizable-and-movable — Resizable and movable component for React.
react-dnr — Dragable and Resizable window build with React.js.
react-resizable-box — Resizable component for React. #reactjs.
react-file-reader-input — React file input component for complete control over styling and abstraction from file reading.
react-pagespeed-score — A React component for display a dial-type chart of PageSpeed Insights.
react-autolink — An autolink mixin for React.
react-svg-buttons — Configurable animated SVG buttons for react.
react-avatar — Universal React avatar component makes it possible to generate avatars based on user information.
react-joyride — Create walkthroughs and guided tours for your ReactJS apps. Now with standalone tooltips!.
material-color-hash — Hash strings to Material UI colors.
react-facebook — Facebook components like a Login button, Like, Share, Comments, Page or Embedded Post.
Form Components
Let the user enter data
Date / Time picker
Date picker / time picker / datetime picker / date range picker
react-datepicker — A simple and reusable datepicker component for React.
rc-calendar — React Calendar.
react-date-range — A React component for choosing dates and date ranges.
react-day-picker — Flexible date picker for React.
react-daterange-picker — A React based date range picker.
react-yearly-calendar — React.js Yearly Calendar Component.
react-calendar — A modular toolkit to build calendar-related things in React.
input-moment — React datetime picker powered by momentjs.
react-datetime — A lightweight but complete datetime picker react component.
react-bootstrap-datetimepicker — A react.js datetime picker for bootstrap.
react-bootstrap-daterangepicker — A date/time picker for react (using bootstrap). This is a react port of bootstrap-daterangepicker.
react-big-calendar — Gcal/outlook like calendar component.
react-date-select — A React Date Select / Picker Input Component.
react-infinite-calendar — Infinite scrolling date-picker built with React, with localization, themes, keyboard support, and more.
react-dates — An easily internationalizable, mobile-friendly datepicker library for the web.
react-flatpickr — Flatpickr for React.
Input Types
Masked inputs, specialized inputs; email / telephone number / credit card / etc.
react-input-mask — Yet another react component for input masking.
react-maskedinput — Masked < input/> React component.
react-text-mask — Input mask for React, Angular, and vanilla JavaScript. Flexible, robust & tiny.
react-credit-cards — Beautiful credit cards for your payment forms.
Autocomplete
Autosuggest / autocomplete / typeahead
react-autosuggest — WAI-ARIA compliant React autosuggest component.
react-typeahead — Pure react-based typeahead and typeahead-tokenizer.
react-typeahead-component — Typeahead, written using the React.js library.
Select
react-selectize — A Stateless & Flexible Select component for React inspired by Selectize.
react-aria-menubutton — A fully accessible, easily themeable, React-powered menu button.
react-select — A Select control built with and for React JS.
react-select-box — An accessible select box component for React.
Color Picker
react-input-color — React input color component with hsv color picker.
react-color — Color Pickers from Sketch, Photoshop, Chrome & more.
coloreact — A tiny Color Picker for React.
Toggle
react-toggle — An elegant, accessible toggle component for React. Also a glorified checkbox.
react-ios-switch — React switch component.
Slider
rc-slider — React Slider.
react-slider — Slider component for React.
Radio Button
react-radio-group — Better radio buttons.
Type Select
Let the user select something (e.g. a tag) while typing
react-tagsinput — A simple react component for inputing tags.
react-tag-input — A fantastically simple tagging component for your React projects.
react-mentions — Mention people in a textarea.
react-tokeninput — Tokeninput component for React.
react-autocomplete-input — Autocomplete input field for React.
Autosize Input / Textarea
react-input-autosize — Auto-resizing input field for React.
react-textarea-autosize — < textarea /> component for React which grows with content.
Star Rating
react-star-rating — A simple star rating component built with React.
react-star-rating-input — React.js component for entering 0-5 (or more) stars.
Drag and Drop
react-draggable — React draggable component.
react-dnd-touch-backend — Touch Backend for react-dnd.
react-dropzone — Simple HTML5 drag-drop zone with React.js.
react-dnd — Drag and Drop for React.
react-sortable-pane — Sortable and resizable pane component for React.
react-dragula — Drag and drop so simple it hurts.
react-droparea — Drag and Drop library for React.
Sortable List
Let the user define an order on a list
sortablejs — Sortable — is a JavaScript library for reorderable drag-and-drop lists on modern browsers and touch devices. No jQuery. Supports Meteor, AngularJS, React, Polymer, Knockout and any CSS library, e.g. Bootstrap.
react-anything-sortable — A ReactJS component that can sort any children with touch support and IE8 compatibility.
react-sortable-hoc — A set of higher-order components to turn any list into an animated, touch-friendly, sortable list.
react-sortable — A sortable list component built with React.
Rich Text Editor
react-quill — A Quill component for React.
react-ace — React Ace Component.
react-contenteditable — React component for a div with editable contents.
react-codemirror — Codemirror Component for React.js.
react-medium-editor — React wrapper for medium-editor.
draft-js — A React framework for building text editors.
ritzy — Collaborative web-based rich text editor.
megadraft — Rich Text editor built on top of draft.js.
react-trumbowyg — React wrapper for Trumbowyg.
alloyeditor — WYSIWYG editor based on CKEditor with completely rewritten UI.
react-draft-wysiwyg — A Wysiwyg editor build on top of ReactJS and DraftJS.
Markdown Editor
react-md-editor — React.js Markdown Editor Component.
react-markdown-editor — A markdown editor using React/Reflux.
Image Editing
Image manipulation
react-avatar-cropper — Aiming to be a complete solution for avatar cropping in react.
react-avatar-editor — Facebook like, avatar / profile picture component. Resize and crop your uploaded image using a clear user interface.
react-image-crop — A responsive image cropping tool for React.
react-image-cropper — React image crop.
Form Component Collections
formsy-react-components — A set of React JS components for use in a formsy-react form. Markup adheres to Bootstrap 3 form structure.
formsy-material-ui — A Formsy compatibility wrapper for Material-UI form components.
react-input-enhancements — Set of enhancements for input control.
react-widgets — An à la carte set of polished, extensible, and accessible inputs built for React.
Miscellaneous
react-designer — Easy to configure, lightweight, editable vector graphics in your react components.
react-images-uploader — React.js component for uploading images to the server.
react-tabguard — React Tabguard.
MISC
· micro github — Tiny microservice that makes adding authentication with GitHub to your application easy.
· pico.js — Face detection library in200 lines of JavaScript.
· mdxc — Use React Components within Markdown.
· ReLaXeD — Create PDF documents using web technologies. (Examples)
· Dragula — Drag and drop so simple it hurts.
· Hammer.js — Multi-touch gestures.
· emittery — Simple and modern async event emitter.
· Xstate — State machines and statecharts for the modern web. (State Machines Workshop)
· xstate-component-tree — Build a tree of UI components based on your state chart.
· virtual-scroller — Maps a provided set of JavaScript objects onto DOM nodes, and renders only the DOM nodes that are currently visible, leaving the rest “virtualized”.
· jSPDF — Client-side JavaScript PDF generation for everyone.
· ForgJS — JavaScript lightweight object validator.
· faker.js — Generate massive amounts of realistic fake data in Node.js and the browser.
· arg — Simple argument parsing.
· fbt — JavaScript Internationalization Framework.
· fuzzysearch — Tiny and blazing-fast fuzzy search in JavaScript.
· normalizr — Normalizes nested JSON according to a schema.
· FBJS — Collection of utility libraries used by other Facebook JS projects.
· Uppy — Next open source file uploader for web browsers. (Web)
· ScrollReveal — Animate elements as they scroll into view.
· Shiny — Add shiny reflections to text, backgrounds, and borders on devices that support the DeviceMotion event.
· Hotkey Behavior — Trigger a action on element when keyboard hotkey is pressed.
· Bili — Makes it easier to bundle JavaScript libraries.
· Memoizee — Complete memoize/cache solution for JavaScript.
· Immer — Create the next immutable state by mutating the current one.
· FlexSearch — Web’s fastest and most memory-flexible full-text search library with zero dependencies.
· cofx — Node and javascript library that helps developers describe side-effects as data in a declarative, flexible API.
· Mercury Parser — Extracts the bits that humans care about from any URL you give it.
· Refract — Harness the power of reactive programming to supercharge your components.
· MemJS — Memcache client for node using the binary protocol and SASL authentication.
· memfs — In-memory filesystem with Node’s API.
· Accounts — Fullstack authentication and accounts-management for GraphQL and REST.
· Cleave.js — Format input text content when you are typing…
· Unistore — Tiny 350b centralized state container with component bindings for Preact & React.
· Ramda — Practical functional library for JavaScript programmers.
· fromfrom — JS library written in TS to transform sequences of data from format to another.
· Editor.js — Block-styled editor with clean JSON output.
· ijk — Transforms arrays into virtual DOM trees.
· Cleave.js — Format input text content when you are typing.
· Oboe.js — Streaming approach to JSON. Oboe.js speeds up web applications by providing parsed objects before the response completes.
· Choices.js — Vanilla JS customisable select box/text input plugin.
· Shepherd — Guide your users through a tour of your app.
· object-cull — Create a copy of an object with just the bits you actually need.
· Sigma — JavaScript library dedicated to graph drawing.
· interact.js — JavaScript drag and drop, resizing and multi-touch gestures with inertia and snapping for modern browsers.
· flru — Tiny (215B) and fast Least Recently Used (LRU) cache.
· Yup — Dead simple Object schema validation.
· Lerna — Tool for managing JavaScript projects with multiple packages.
· WikiJs — Wikipedia Interface for Node.js.
· virtual-audio-graph — Library for declaratively manipulating the Web Audio API.
· deep-object-diff — Deep diffs two objects, including nested structures of arrays and objects, and returns the difference.
· Snarkdown — Snarky 1kb Markdown parser written in JavaScript.
· Terser — JavaScript parser, mangler, optimizer and beautifier toolkit for ES6+.
· AppAuthJS — JavaScript client SDK for communicating with OAuth 2.0 and OpenID Connect providers.
· expr-eval — Mathematical expression evaluator in JavaScript.
· robust-predicates — Fast robust predicates for computational geometry in JavaScript.
· Sanctuary — JavaScript functional programming library inspired by Haskell and PureScript.
· modali — Delightful modal dialog component for React, built from the ground up to support React Hooks.
· Tweakpane — Compact GUI for fine-tuning parameters and monitoring value changes.
· crocks — Collection of well known Algebraic Data Types for your utter enjoyment.
· Just — Library of zero-dependency npm modules that do just do one thing.
· nanoid — Tiny (139 bytes), secure, URL-friendly, unique string ID generator for JavaScript.
· debug — Tiny JavaScript debugging utility modelled after Node.js core’s debugging technique. Works in Node.js and web browsers.
· roughViz.js — Reusable JavaScript library for creating sketchy/hand-drawn styled charts in the browser.
· Mitt — Tiny 200 byte functional event emitter / pubsub.
· RequireJS — File and module loader for JavaScript.
· Zero — 3D graphics rendering pipeline. Implemented in JavaScript. Run in a terminal.
· xstate-viz — Visualize state charts.
· htmr — Simple and lightweight (< 2kB) HTML string to React element conversion library.
· react-jsx-parser — React component which can parse JSX and output rendered React Components.
· Static Land — Specification for common algebraic structures in JavaScript based on Fantasy Land.
· sorted-queue — Sorted queue, based on an array-backed binary heap.
· polendina — Non-UI browser testing for JavaScript libraries from the command-line.
· agadoo — Check whether a package is tree-shakeable.
· Fielder — React form library which adapts to change.
· lemonad — Functional programming library for JavaScript. An experiment in elegant JS.
· Mockttp — Lets you quickly & reliably test HTTP requests & responses in JavaScript, in both Node and browsers.
· Flowy — Minimal javascript library to create flowcharts.
· d3-dag — Layout algorithms for visualizing directed acyclic graphs.
· renature — Physics-based animation library for React focused on modeling natural world forces.
· Morphism — Do not repeat anymore your objects transformations.
· Tonic — Stable, Minimal, Auditable, Build-Tool-Free, Low Profile Component Framework.
· Quiet.js — Transmit data with sound using Web Audio — Javascript binding for libquiet.
· Bindery — Library for designing printable books with HTML and CSS.
· Wretch — Tiny wrapper built around fetch with an intuitive syntax.
· Virt.js — Free collection of useful standard devices, that can be used to power various engine that makes use of the exposed interfaces.
· Path-to-RegExp — Turn a path string such as /user/:name into a regular expression.
· Bacon.js — Functional reactive programming library for TypeScript and JavaScript.
· GGEditor — Visual graph editor based on G6 and React.
· Arbor — Graph visualization library using web workers and jQuery. (Web)
· fsm-as-promised — Finite state machine library using ES6 promises.
· x-spreadsheet — Web-based JavaScript(canvas)spreadsheet.
· IsoCity — Isometric city builder in JavaScript.
· Picomatch — Blazing fast and accurate glob matcher written in JavaScript.
· react-isomorphic-data — Easily fetch data in your React components, with similar APIs to react-apollo.
· klona — Tiny (228B) and fast utility to “deep clone” Objects, Arrays, Dates, RegExps, and more.
· ScrollMagic — JavaScript library for magical scroll interactions.
· GoJS — JavaScript and TypeScript library for building interactive diagrams and graphs.
· Rete — JavaScript framework for visual programming and creating node editor. (HN)
· Pre3d — JavaScript 3d rendering engine.
· dancer.js — High-level audio API, designed to make sweet visualizations.
· model-viewer — Easily display interactive 3D models on the web and in AR.
· Spars — General toolkit for creating interactive web experiences.
· NeuroJS — JavaScript deep learning and reinforcement learning library.
· Hareactive — Purely functional reactive programming library.
· Mirage JS — Client-side server to develop, test and prototype your JavaScript app.
· dfa — State machine compiler with regular expression style syntax.
· Jtree — Tree Notation TypeScript/Javascript library.
· Hydra — Livecoding networked visuals in the browser.
· p-queue — Promise queue with concurrency control.
· gsheets — Get public Google Sheets as plain JavaScript/JSON.
· alga-ts — Algebraic graphs implementation in TypeScript.
· on-change — Watch an object or array for changes.
· clean-set — Deep assignment alternative to the object spread operator and Object.assign.
· Uppload — Better JavaScript image uploader with 30+ plugins.
· pino — Super fast, all natural JSON logger.
· Orbit — Composable data framework for ambitious web applications.
· panzoom — Universal pan and zoom library (DOM, SVG, Custom).
· intl-tel-input — JavaScript plugin for entering and validating international telephone numbers.
· three.js — JavaScript 3D library.
· shortid — Short id generator. Url-friendly. Non-predictable. Cluster-compatible.
· styx — Derives a control flow graph from a JavaScript AST.
· Crossfilter — JavaScript library for exploring large multivariate datasets in the browser.
· SiriWave — Apple Siri wave-form replicated in a JS library.
· Shades — Lodash-inspired lens-like library for Javascript.
· mxGraph — Fully client side JavaScript diagramming library.
· cacache — Node.js library for managing local key and content address caches.
· enhanced-resolve — Offers an async require.resolve function. It’s highly configurable.
· notevil — Evalulate javascript like the built-in javascript eval() method but safely.
· react-digraph — Library for creating directed graph editors.
· bent — Functional JS HTTP client (Node.js & Fetch) w/ async await.
· CLUI — Collection of JavaScript libraries for building command-line interfaces with context-aware autocomplete.
· cosha — Colorful shadows for your images.
· Rambda — Faster and smaller alternative to Ramda.
· MathJax — Open-source JavaScript display engine for LaTeX, MathML, and AsciiMath notation that works in all modern browsers. (Web) (HN)
· Litepicker — Date range picker — lightweight, no dependencies.
· core-js — Modular standard library for JavaScript.
· timeago.js — Nano library (less than 2 kb) used to format datetime with *** time ago statement. eg: ‘3 hours ago’.
· Serialize JavaScript — Serialize JavaScript to a superset of JSON that includes regular expressions, dates and functions.
· Tippy.js — Tooltip, popover, dropdown, and menu library.
· howler.js — JavaScript audio library for the modern web.
· date-fns — Modern JavaScript date utility library.
· Midi — Convert MIDI into Tone.js-friendly JSON.
· face-api.js — JavaScript API for face detection and face recognition in the browser and nodejs with tensorflow.js.
· Spotlight — Search widget for your web API.
· Fuse — Lightweight fuzzy-search, in JavaScript.
· Xterm.js — Terminal for the web.
· Change Case — Convert strings between camelCase, PascalCase, Capital Case, snake_case and more.
· ChronoGraph — Reactive, graph-based, computation engine.
· Sprotty — Diagramming framework for the web.
· prerender.js — Loads pages quickly on any browser.
· on-finished — Execute a callback when a request closes, finishes, or errors.
· ColorFns — Modern JavaScript color utilities library.
· grapheme-splitter — JavaScript library that breaks strings into their individual user-perceived characters.
· Web Animations — JavaScript implementation of the Web Animations API.
· p-limit — Run multiple promise-returning & async functions with limited concurrency.
· Highcharts JS — JavaScript charting library based on SVG.
· μPlot — Small, fast chart for time series, lines, areas, ohlc & bars.
· Baobab — JavaScript & TypeScript persistent and optionally immutable data tree with cursors.
· emoji-regex — Regular expression to match all Emoji-only symbols as per the Unicode Standard.
· MerkleTree.js — Construct Merkle Trees and verify proofs in JavaScript.
· Snabbdom — Virtual DOM library with focus on simplicity, modularity, powerful features and performance.
· Thwack — Tiny modern data fetching solution.
· Regenerate — Generate JavaScript-compatible regular expressions based on a given set of Unicode symbols or code points.
· Crank.js — Write JSX-driven components with functions, promises and generators. (Article) (Reddit) (HN)
· redaxios — Axios API, as an 800 byte Fetch wrapper.
· Math.js — Extensive math library for JavaScript and Node.js.
· pixelmatch — Smallest, simplest and fastest JavaScript pixel-level image comparison library.
· quilt — Loosely related set of packages for JavaScript / TypeScript projects at Shopify.
· jsondiffpatch — Diff & patch JavaScript objects.
· RVal — Minimalistic transparent reactive programming library.
· orbit-controls — Generic controls for orbiting a target in 3D.
· estree-walker — Traverse an ESTree-compliant AST.
· Jitsi Meet API library — Can use Jitsi Meet API to create Jitsi Meet video conferences with a custom GUI.
· isomer — Simple isometric graphics library for HTML5 canvas.
· Mordred — Source data from anywhere, for Next.js, Nuxt.js, Eleventy and many more.
· ASScroll — Hybrid smooth scroll setup that combines the performance gains of virtual scroll with the reliability of native scroll.
· Gallery — Light, responsive, and performant JavaScript gallery.
· Logux Server — Build own Logux server or make proxy between WebSocket and HTTP backend on any language.
· @expo/results — Efficient, standards-compliant library for representing results of successful or failed operations.
· Emojibase — Collection of lightweight, up-to-date, pre-generated, specification compliant, localized emoji JSON datasets, regex patterns, and more.
· serve-favicon — Node.js middleware for serving a favicon.
· download — Download and extract files.
· color2k — Color parsing and manipulation lib served in 2kB or less.
· Sandstorm — Open source platform for self-hosting web apps. (Code)
· transformation-matrix — JS isomorphic 2D affine transformations written in ES6 syntax.
· Muuri — JavaScript layout engine that allows you to build all kinds of layouts and make them responsive, sortable, filterable, draggable and/or animated.
· Split — Unopinionated utilities for resizeable split views.
· Parallax Engine — Reacts to the orientation of a smart device.
· fastq — Fast, in memory work queue.
· ac-colors — Reactive JavaScript color library that can freely convert color formats.
· sonic-boom — Extremely fast utf8 only stream implementation.
· Rough Notation — Small JavaScript library to create and animate annotations on a web page. (HN)
· fit-textarea — Automatically expand a to fit its content, in a few bytes.
· NanoPop — Ultra Tiny, Opinionated Positioning Engine. (Web)
· Angelfire — Lets you quickly build right-click-enabled context menus and drop-down menus for any element on your webpage.
· csv-parser — Streaming csv parser inspired by binary-csv that aims to be faster than everyone else.
· updeep — Easily update nested frozen objects and arrays in a declarative and immutable manner.
· Hull.js — JavaScript library that builds concave hull by set of points.
· StegCloak — Hide secrets with invisible characters in plain text securely using passwords.
· p-min-delay — Delay a promise a minimum amount of time.
· match-when — Pattern matching for modern JavaScript.
· NumJs — Like NumPy, in JavaScript.
· spect — Reactive aspect-oriented web-framework.
· js-cid — CID implementation in JavaScript.
· js-ipld-block — Implementation of the Block data structure in JavaScript.
· wildcard-api — Functions as API.
· bpmn-js — BPMN 2.0 rendering toolkit and web modeler.
· fit-curve — JavaScript implementation of Philip J. Schneider’s “Algorithm for Automatically Fitting Digitized Curves” from the book “Graphics Gems”.
· clean-deep — Remove falsy, empty or nullable values from objects.
· regular-table — Regular library, for async and virtual data models.
· Stimulus — Modest JavaScript framework for the HTML you already have. (Web)
· bigpicture.js — Library that allows infinite panning and infinite zooming in HTML pages. (Web)
· Tragopan — Minimal dependency-free pan/zoom library. (HN)
· Deakins — Small Canvas 2D Camera.
· Turbolinks — Makes navigating your web application faster.
· CindyJS — Framework to create interactive (mathematical) content for the web. (Web) (HN)
· axios — Promise based HTTP client for the browser and nodeJS.
· astray — Walk an AST without being led astray.
· vnopts — Validate and normalize options.
· canvas confetti — On-demand confetti gun. (Docs)
· Graphlib — JavaScript library that provides data structures for undirected and directed multi-graphs along with algorithms that can be used with them.
· Dagre — JavaScript library that makes it easy to lay out directed graphs on the client-side.
· ecsy — Highly experimental Entity Component System framework implemented in javascript, aiming to be lightweight, easy to use and with good performance. (Docs)
· Object Visualizer — Visualize the JSON object to the DOM. (HN)
· Reach Schema — Functional schema-driven JavaScript object validation library.
· @cycle/callbags — Set of commonly used stream operators implemented as callbags with Typescript and ES modules.
· umbrella — Broadly scoped ecosystem & mono-repository of ~135 TypeScript projects for functional, data driven development.
· HTM — JSX-like syntax in plain JavaScript — no transpiler necessary.
· NativeScript — Framework for building native iOS and Android apps using JavaScript and CSS.
· schema-dts — JSON-LD TypeScript types for Schema.org vocabulary.
· flatpickr — JS date time picker.
· superjson — Safely serialize JavaScript expressions to a superset of JSON, which includes Dates, BigInts, and more.
· lazy-collections — Collection of fast and lazy operations.
· Perfect Arrows — Set of functions for drawing perfect arrows between points and shapes.
· Autocomplete.js — Fast and full-featured autocomplete library.
· Diagram Maker — Library to display an interactive editor for any graph-like data. (Docs) (HN)
· js-coroutines — 60fps with JavaScript Coroutines for idle processing and animation.
· Transducist — Ergonomic JavaScript/TypeScript transducers for beginners and experts.
· decimal.js — Arbitrary-precision Decimal type for JavaScript.
· Constant-Time JavaScript — Constant-time algorithms written in TypeScript.
· SheetJS — Spreadsheet Data Toolkit. Read, edit, and export spreadsheets. Works in web browsers and servers. (Web)
· Graphology — Robust & multipurpose Graph object for JavaScript & TypeScript. (Docs)
· weak-napi — Make weak references to JavaScript Objects.
· nestie — Tiny (211B) and fast utility to expand a flattened object.
· Mock.js — Simulation data generator.
· Detect features — Detect and report browser and hardware features.
· JSZip — Create, read and edit .zip files with JavaScript.
· Classnames — Simple javascript utility for conditionally joining classNames together.
· cx — Concatenate your classes (with shortcuts).
· Defer — Tiny, type-safe, JavaScript-native defer implementation.
· freshie — Fresh take on building universal applications with support for pluggable frontends and backends.
· Luckysheet — Online spreadsheet like excel that is powerful, simple to configure, and completely open source. (Docs)
· noUiSlider — Lightweight JavaScript range slider.
· QRCode.js — Cross-browser QRCode generator for JavaScript. (Web)
· HyperScript — Create HyperText with JavaScript, on client or server.
· hyperscript-helpers — Terse syntax for hyperscript.
· EnlighterJS — Open source syntax highlighter written in pure javascript.
· eslisp — S-expression syntax for JavaScript, with Lisp-like hygienic macros. Minimal core, maximally customisable.
· Smoldash — Tiny lodash alternative built for the modern web.
· TypewriterJS — Simple yet powerful native javascript plugin for a cool typewriter effect.
· sse.js — Flexible Server Side Events source for JavaScript.
· Arkit — Visualises JavaScript, TypeScript and Flow codebases as meaningful and committable architecture diagrams. (Web)
· jsii — Allows code in any language to naturally interact with JavaScript classes.
· proxy-memoize — Intuitive magical memoization library with Proxy and WeakMap. (Tweet)
· CosmJS — Modular library consisting of multiple packages to power web experiences.
· Arwes — Futuristic Sci-Fi and Cyberpunk Graphical User Interface Framework for Web Apps. (Web)
· psl (Public Suffix List) — JavaScript domain name parser based on the Public Suffix List.
· invariant-packages — Packages for working with invariant(condition, message) assertions.
· evt — EventEmitter’s typesafe replacement.
· webscan — Browser-based network scanner & local-IP detection.
· Pill — Add dynamic content loading to static sites with only 1 KiB of JS.
· fast-deep-equal — Fastest deep equal with ES6 Map, Set and Typed arrays support.
· preview-card — Customizable social media preview image.
· egjs-flicking — Easy-to-use and performant infinite carousel.
· SSE-Z — Slim, easy-to-use wrapper around EventSource.
· DefinitelyExported — Community-defined export maps for popular npm packages.
· jsdiff — JavaScript text differencing implementation.
· HyperFormula — Open source, spreadsheet-like calculation engine.
· fast-json-stringify — Significantly faster than JSON.stringify() for small payloads.
· isbot — JavaScript module that detects bots/crawlers/spiders via the user agent.
· valtio — Makes proxy-state simple.
· pica — High quality image resize in browser.
· Planton — Database-agnostic task scheduler.
· mime-types — JavaScript content-type utility.
· match-sorter — Simple, expected, and deterministic best-match sorting of an array in JavaScript.
· Fetch Event Source — Better API for making Event Source requests, with all the features of fetch().
· rafz — Coordinate requestAnimationFrame calls across your app and/or libraries.
· p-state — Inspect the state of a promise.
· v86 — x86 virtualization in JavaScript, running in your browser and NodeJS. (Web)
· Notyf — Minimalistic, responsive, vanilla JavaScript library to show toast notifications.
· Moveable — Draggable, Resizable, Scalable, Rotatable, Warpable, Pinchable, Groupable, Snappable.
· Execa — Process execution for humans.
· quick-lru — Simple “Least Recently Used” (LRU) cache.
· Deepdash — Tree traversal library written in Underscore/Lodash fashion. (Docs)
· Nano Delay — Tiny (25 bytes) Promise wrapper around setTimeout.
· ES Module Lexer — Low-overhead lexer dedicated to ES module parsing for fast analysis.
· keez — Frictionless hotkey handling for browsers.
· Zet — Set() as it should be.
· Ketting — Hypermedia client for JavaScript.
· yocto-queue — Tiny queue data structure.
· Effects.js — Algebraic effects in javascript with scoped handlers, multishot delimited continuations, stack safety and do notation.
· flatten-js — JavaScript library for 2d geometry.
· is-retry-allowed — Check whether a request can be retried based on the error.code.
· backfill — JavaScript caching library for reducing build time.
· S-Libs — Collection of libraries for any of JS, RxJS, or Angular.
· watchpack — Wrapper library for directory and file watching.
· async-tag — Resolves template literals tag values before applying a generic tag.
· serialize-error — Serialize/deserialize an error into a plain object.
· errorstacks — Tiny library to parse error stack traces.
· Ape-ECS — Entity-Component-System library for JavaScript.
· rrule.js — JavaScript library for working with recurrence rules for calendar dates as defined in the iCalendar RFC and more. (Demo)
· scroller — Super-tiny library for your scrollytelling needs.
· Isomorphic DOMPurify — Makes it possible to use DOMPurify on server and client in the same way.
· navaid — Navigation aid (aka, router) for the browser in 850 bytes.
· glob-to-regexp — Convert a glob to a regular expression.
· cmap — Interactive visualization library for concept map.
· lezer-tree — Incremental GLR parser intended for use in an editor or similar system.
· matchit — Quickly parse & match URLs.
· acorn — Tiny, fast JavaScript parser, written completely in JavaScript.
· jsesc — Given some data, jsesc returns the shortest possible stringified & ASCII-safe representation of that data.
· fastjson — Single-tweet, standards-compliant, high-performance JSON stack.
· grfn — Tiny (~400B) utility that executes a dependency graph of async functions as concurrently as possible.
· Nunjucks — Powerful templating engine with inheritance, asynchronous control, and more. (Web)
· Behavior3JS — Structures and algorithms that assist you in the task of creating intelligent agents for your game or application.
· qs — Querystring parser with nesting support.
· Exifer — Small module that read JPEG/TIFF meta-data.
· jsVideoUrlParser — JavaScript parser to extract information like provider, channel, id, start time from YouTube, Vimeo, Dailymotion, Twitch,… urls.
· TypeDI — Dependency injection tool for TypeScript and JavaScript.
· ibridge — Tiny, promise based, type safe library for easy, bidirectional and secure iframe communication.
· Monio — Async-capable IO monad for JS.
· Total.js — Excellent and stable server-side Node.js framework, client-side library for creating web applications with more than 230 UI components for free.
· memoize-one — Memoization library which only remembers the latest invocation.
· pjson — JSON stream parser for Go.
· InternMap — Map and Set with automatic key interning.
· geometry-processing-js — Fast, general-purpose framework for geometry processing on the web.
· Iterplus — Best of Rust/Haskell/Python iterators in JavaScript.
· SmolScroll — Tiny, flexible scroll listener with React support.
· Robot — Functional, immutable Finite State Machine library. (Docs)
· Enmap — Enhanced Map structure with additional utility methods.
· Honeycomb — Create hex grids easily, in node or the browser.
· chunkify — Split an iterable into evenly sized chunks.
· wobble — Tiny spring physics micro-library that models a damped harmonic oscillator.
· tmp-cache — Least-recently-used cache in 35 lines of code.
· static-eval — Evaluate statically-analyzable expressions.
· Sparse Octree — Sparse, pointer-based octree data structure.
· Signature Pad — JavaScript library for drawing smooth signatures.
· dom-to-image-retina — dom-to-image but generates high-resolution images.
· loglevel — Minimal lightweight logging for JavaScript, adding reliable log level methods to wrap any available console.log methods.
· Perfect Freehand — Draw perfect freehand lines.
· Form-Data — Library to create readable “multipart/form-data” streams. Can be used to submit forms and file uploads to other web applications.
· conf — Simple config handling for your app or module.
· gifenc — Fast and lightweight pure-JavaScript GIF encoder.
· tldts — Blazing Fast URL Parsing.
· Barba.js — Easy-to-use library that helps you create fluid and smooth transitions between your website’s pages.
· Shuffle.js — Categorize, sort, and filter a responsive grid of items. (Web)
· stdlib — Standard library for JavaScript and Node.js. (Web)
· gensync — Allows users to use generators in order to write common functions that can be both sync or async.
· monet.js — Monadic types library for JavaScript.
· VivaGraph — Graph drawing library for JavaScript.
· Crochet — Small engine for story-driven games.
· diary — Zero-dependency, fast logging library for both Node and Browser.
· tinydate — Tiny reusable date formatter.
· FingerprintJS — Browser fingerprinting library with the highest accuracy and stability.
· Antiutils — TypeScript/JavaScript utilities for those who don’t like utilities.
General:
· NPM — Node package manager registry.
· Awesome WebAudio
· Awesome XState
· Moiva.io — Measure and compare JavaScript libraries side by side.
· Scarf — Installation analytics for your npm package. (Code)
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://github.com/bgoonz/Cumulative-Resource-List/tree/master/README-shttps://github.com/bgoonz/Cumulative-Resource-List/tree/master/README-s
Or checkout my personal resource site:
https://github.com/bgoonz/Cumulative-Resource-List/tree/master/README-s
Everyone’s seen the ‘Awesome’ lists on GitHub… and they are indeed awesome… so today I am going to attempt to curate my own…

- JavaScript. The Core
- Modern JavaScript Tutorial (HN)
- You don’t know JS books
- JS in 14 minutes
- 2017 JavaScript Rising Stars
- ES6 features
- The Definitive Guide to Object-Oriented JavaScript — Amazing video to understand JS inheritance & objects.
- JavaScript: The Core
- JavaScript is Good, Actually (HN)
- JavaScript Algorithms — Algorithms and data structures implemented in JavaScript with explanations and links to further readings.
- EC6 Features
- Clean Code concepts adapted for JavaScript
- Ask HN: “Expert Level” JavaScript questions?
- Benefits of prototypal inheritance over classical?
- Pax — Fastest JavaScript bundler in the galaxy.
- Philip Roberts: What the heck is the event loop anyway? (2014)
- Jake Archibald: In The Loop (2018)
- Yonatan Kra — The Event Loop and your code (2020)
- BundlePhobia — Find the cost of adding a npm package to your bundle. (Code) (Tweet)
- An Overview of JavaScript Testing in 2018
- Introduction to ES6 Promises — The Four Functions You Need To Avoid Callback Hell
- Nice ES6/Promises/React cheat sheets
- JavaScript Visualizer — Tool for visualizing Execution Context, Hoisting, Closures, and Scopes in JavaScript.
- WallabyJS — Integrated continuous testing tool for JavaScript.
- ES6 features
- The State of JavaScript — The State of the Web (2018)
- A Quick Tour Of ES6 (Or, The Bits You’ll Actually Use)
- JavaScript on the Desktop, Fast and Slow (2018)
- ES6 for humans
- 33 concepts every JavaScript developer should know
- Design Patterns JS — All the 23 (GoF) design patterns implemented in JavaScript.
- Standard Library Proposal
- 30 seconds of code — Curated collection of useful JavaScript snippets that you can understand in 30 seconds or less.
- puppet-run — Run anything JavaScript in a headless Chrome from your command line.
- Yalc — Better workflow than npm | yarn link for package authors.
- ECMAScript proposals
- FromJS — See where each character on the screen came from in code.
- RunJS — Scratchpad for your thoughts, a playground for your creativity.
- Pragmatic, balanced FP in JavaScript book
- Pack — Helps you build amazing packages without the hassle.
- Learning JavaScript (2016)
- @pika/web — Install npm dependencies that run directly in the browser. No Browserify, Webpack or import maps required.
- Sucrase — Super-fast alternative to Babel for when you can target modern JS runtimes.
- Airbnb JavaScript Style Guide
- JavaScript Developer’s Reading List — List of hand-picked books and articles for JavaScript developers.
- Promisees — Promise visualization playground for the adventurous.
- promise-fun — Promise packages, patterns, chat, and tutorials.
- Perflink — JavaScript performance benchmarks that you can share via URL.
- Mostly adequate guide to FP (in JavaScript) (Code) (HN)
- Volta — JavaScript Launcher.
- Modern JS Cheat Sheet
- Fastpack — Pack JavaScript fast & easy.
- Reference implementation for the JavaScript Binary AST format
- Babel Handbook
- List of (Advanced) JavaScript Questions
- Faster script loading with BinaryAST? (2019)
- recast — JavaScript syntax tree transformer, nondestructive pretty-printer, and automatic source map generator.
- Madge — Create graphs from your CommonJS, AMD or ES6 module dependencies.
- npmfs — JavaScript Package Inspector.
- Fantasy Land Specification — Specification for interoperability of common algebraic structures in JavaScript.
- Meriyah — 100% compliant, self-hosted javascript parser with high focus on both performance and stability.
- The cost of JavaScript in 2019 (HN)
- Poi — Zero-config bundler for JavaScript applications.
- Advanced JavaScript Course
- Jay — Supercharged JavaScript REPL.
- Data Structures and Algorithms in JavaScript
- JavaScript & Node.js Testing Best Practices
- Just — Library that organizes build tasks for your JS projects.
- ECMAScript (JS) specification (Code) (Web version 2)
- André Staltz: Two Fundamental Abstractions — Uphill Conf 2018
- JSMonday — Weekly JS inspiration.
- Chevrotain — Parser Building Toolkit for JavaScript.
- Comprehensive list of new ES features
- Exploring JS: JavaScript books for programmers
- JavaScript for Impatient Programmers book (HN)
- Exploring ES2018 and ES2019
- TC39 Meeting Notes
- Mesh Spreadsheet — Visualise data and edit JavaScript code using a spreadsheet interface. (Web)
- Immutable JavaScript Data Structures with Immer (2019)
- Immutability is Changing — From Immutable.js to Immer (2019)
- Tenko — 100% spec compliant ES2020 JavaScript parser written in JS.
- code-red — Experimental toolkit for writing x-to-JavaScript compilers.
- Reduce in JavaScript (2019)
- Pika — New kind of package registry for the modern web.
- Brian Holt: Futurist Code Bases: Integrating JS of the Future Today (2019)
- JS TLDR — Zen mode web-documentation. (Code) (Article)
- Currying Functions in ES6 (2016)
- Manipulating AST with JavaScript (2019)
- Is JavaScript Statically or Dynamically Scoped? (2018)
- Fixed-point combinators in JavaScript: Memoizing recursive functions
- runpkg — Lets you navigate any JavaScript package on npm thanks to unpkg.com.
- What is this in JavaScript?
- Beginner JavaScript course
- ES6 Cheat Sheet
- JavaScript Visualized: Event Loop (2019)
- JavaScript Visualized: Scope (Chain) (2019)
- JavaScript Visualized: Hoisting (2019)
- Fuzzilli — JavaScript Engine Fuzzer.
- Deep JavaScript: Theory and techniques (2019) (HN)
- JavaScript Adaption of Structure and Interpretation of Computer Programs (HN) (Code)
- State of JS 2019 (HN)
- Cancelation without Breaking a Promise (2016) — Reflecting on what was so tricky about cancelable Promises, embracing functional purity as a solution.
- ECMAScript Discussion Archives (Code)
- What Is JavaScript Made Of? (2019)
- JavaScript Visualized: Prototypal Inheritance (2020)
- Y: The Most Beautiful Idea in Computer Science explained in JavaScript (2018)
- 2019 JavaScript Rising Stars (Code)
- Best of JS — Best of JavaScript, HTML and CSS. (Code) (Web Timeline) (HN)
- omggif — JavaScript implementation of a GIF 89a encoder and decoder.
- Sampling bias, FDR, and The State of JS (2020)
- JavaScript Visualized: Generators and Iterators (2020)
- jsep — JavaScript Expression Parser.
- JS Tips & Tidbits
- I have been underestimating JS (2020) — Understanding V8 and NodeJS Steams.
- Taming the asynchronous beast with CSP channels in JavaScript (2014)
- Debounce vs Throttle: Definitive Visual Guide (2019)
- GistLink — Code apps or components. See them render as you type. Share your creations via URL.
- source-map-explorer — Analyze and debug space usage through source maps.
- Diglett — Keep your JS project lean by detecting duplicate dependencies.
- Learn Vanilla JS Roadmap
- Learn JavaScript — Easiest way to learn & practice modern JavaScript step by step.
- Mini projects built with HTML5, CSS & JavaScript. No frameworks or libraries (HN)
- IxJS — Interactive Extensions for JavaScript.
- Renovate — Universal dependency update tool that fits into your workflows.
- The ECMAScript Ecosystem (2020)
- esbuild — Extremely fast JavaScript bundler and minifier written in Go. (HN) (Architecture) (serverless-esbuild) (Awesome) (Web) (Esbuild plugins)
- Community plugins for esbuild
- Why Is Esbuild Fast? (HN)
- bundless — Dev server and bundler for esbuild. (Web)
- esbuild-register — Transpile JSX, TypeScript and esnext features on the fly with esbuild.
- JavaScript: Understanding the Weird Parts course (2015)
- Fastpack — Pack JS code into a single bundle fast & easy.
- guijs — App that helps you manage JS projects with a Graphical User Interface.
- Rome Toolchain — Linter, compiler, bundler, and more for JavaScript, TypeScript, HTML, Markdown, and CSS. (Web) (HN) (HN 2) (HN 3)
- Bolt — Super-powered JavaScript project management.
- tiny-js — Aims to be an extremely simple (~2000 line) JavaScript interpreter.
- JavaScript and TypeScript tooling overview
- Seafox — Blazing fast 100% spec compliant, self-hosted javascript parser written in Typescript.
- Awesome JavaScript Learning
- Awesome Promises
- jscodeshift — Toolkit for running codemods over multiple JavaScript or TypeScript files.
- React Workout: Reducers with Cassidy Williams (2020)
- JavaScript: The First 20 Years (2020)
- Awesome Storybook
- QuickJS — Small and embeddable Javascript engine. (Web) (HN)
- Test262: Official ECMAScript Conformance Test Suite
- Hegel — Advanced static type checker. (Web) (Intro to Hegel)
- NectarJS — JS God mode. No VM. No Bytecode. No Garbage Collector. Full Compiled and Native binaries.
- Eloquent JavaScript book (2018) (HN)
- JS.coach — Manually curated list of packages related to React, Vue, Webpack, Babel and PostCSS. (Code)
- How to create a reactive state-based UI component with vanilla JS Proxies (2020)
- Kite Autocomplete for JavaScript (Article)
- Excalidraw: Cool JS Tricks Behind the Scenes — Christopher Chedeau (2020)
- Cleaner async JavaScript code without the try/catch mess (2020)
- Shifty — Tweening engine for JavaScript. It is a lightweight library meant to be encapsulated by higher level tools.
- jspm — Package management CLI.
- JS Bits — JavaScript concepts explained with code.
- Binary-parser — Parser builder for JavaScript that enables you to write efficient binary parsers in a simple and declarative manner.
- estrella — Light-weight runner for the esbuild compiler.
- jsparagus — JavaScript parser written in Rust.
- Callbag — Standard for JS callbacks that enables lightweight observables and iterables. (Wiki)
- JavaScript Standard Style — JavaScript style guide, linter, and formatter. (Code)
- Boa — Experimental Javascript lexer, parser and compiler written in Rust.
- Understanding JavaScript Execution Context like never before (2020)
- Causes of Memory Leaks in JavaScript and How to Avoid Them (2020) (Lobsters)
- UI.dev — Master the JavaScript Ecosystem.
- Do Not Follow JavaScript Trends (2020) (Lobsters) (HN)
- Some things that can be avoided in JS for clearer code (2020)
- JS fundamentals and resources to learn them (2020)
- A little bit of plain JavaScript can do a lot (2020) (Lobsters) (HN)
- Memoization: What, Why, and How (2020)
- An Open Source Maintainer’s Guide to Publishing npm Packages (2020)
- Robust Client-Side JavaScript (2020) (HN)
- Visualization of npm dependencies
- How to Learn JavaScript (HN)
- Google Closure Compiler — Tool for making JavaScript download and run faster.
- JSConf — Conferences for the JavaScript Community.
- The history of Promises
- Skypack — New kind of JavaScript delivery network. (HN) (Introducing Skypack Discover) (Docs)
- Openbase — Help developers choose the right JS package for any task — through user reviews and insights about packages’ popularity, reliability, activity and more. (HN)
- Basho — Shell Automation with Plain JavaScript. (Docs)
- What is the JS Event Loop and Call Stack?
- Starving the Event Loop with microtasks
- GPU.js — GPU accelerated JavaScript. (HN)
- The JavaScript Promise Tutorial (2020)
- Underrated JS array methods (2020)
- Javascript Generators, Meet XPath (2020) (Lobsters)
- goja — ECMAScript 5.1(+) implementation in Go.
- Guide to unit testing in JavaScript
- How I wrote the fastest JavaScript memoization library (2017)
- JavaScript Playgrounds — Interactive JavaScript sandbox. (Code)
- Speakeasy JS — Weekly JavaScript meetup.
- Elsa — Minimal, fast and secure QuickJS wrapper written in Go. (HN)
- quickjs-rs — Rust wrapper for QuickJS.
- RSLint — JavaScript linter written in Rust designed to be as fast as possible, customizable, and easy to use.
- Beginner’s Series to: JavaScript by Microsoft (Code)
- Please stop using CDNs for external Javascript libraries (2020) (Lobsters) (HN)
- ESM Hot Module Replacement (ESM-HMR) Spec
- esbuild-js — es-build implemented in JS.
- Visual Guide to References in JavaScript (2020)
- Modern JavaScript features you may have missed (2019)
- RegPack — Self-contained packer for size-constrained JS code.
- ElectronJS alternative: SciterJS — HTML/CSS/JS in 4.5 MB executable (HN)
- ESTree Spec — Manipulate JavaScript source code.
- Pattern Matching in JavaScript (2020)
- How to chain methods in JS in order to write concise and readable code (2020)
- npmview — Web application to view npm package files. (Code)
- Metadata Reflection API for JS
- SurviveJS — Learn JavaScript. From apprentice to master.
- Composing Closures and Callbacks in JavaScript (2020)
- CJS Module Lexer — Fast lexer to extract named exports via analysis from CommonJS modules.
- JavaScript minification (2019)
- export-size — Analysis bundle cost for each export of an ESM package.
- ESM — Fast, global content delivery network ES Modules.
- Benny — Dead simple benchmarking framework for JS/TS libs.
- Functional Programming in JS — Composition (Currying, Lodash and Ramda) (2020)
- Understanding Modules, Import and Export in JavaScript (2020)
- Intent to stop using ‘null’ in my JS code (HN)
- What Makes JavaScript JavaScript? Prototypal Inheritance (2020)
- ni — Use the right package manager. Detect whether to use npm/yarn/pnpm.
- Making a modern JS library in 2020
- JavaScript Interview Questions & Answers
- JS Operator Lookup — Search JavaScript Operators.
- The state of JavaScript at the end of 2020 (HN)
- What the fuck JavaScript — List of funny and tricky JavaScript examples.
- 1loc — JavaScript Utilities in 1 LOC.
- Component Driven User Interfaces — Open standard for UI component examples based on JavaScript ES6 modules. (Code)
- JavaScript Modern Interview Code Challenges
- Building a Promise from Scratch (2020)
- Tips and tricks for working with types in JavaScript
- Astring — Tiny and fast JavaScript code generator from an ESTree-compliant AST.
- EStimator.dev — Calculate the size and performance impact of switching to modern JavaScript syntax. (Code)
- Publish, ship, and install modern JavaScript for faster applications (2020)
- Universal JavaScript Build and Packaging
- Maybe you don’t need Rust and WASM to speed up your JS (2018)
- lage — Task runner in JS monorepos. (Web)
- Module Server — System for efficient serving of CommonJS modules to web browsers.
- How JavaScript works: exceptions + best practices for synchronous and asynchronous code (2021)
- Source Map Visualization — Visualization of JavaScript source map data, which is useful for debugging problems with generated source maps. (Code)
- Manypkg — Linter for package.json files in Yarn, Bolt or pnpm monorepos.
- Putout — Pluggable and configurable code transformer with built-in eslint, babel plugins and jscodeshift codemods support. (Editor)
- Prettier Plugin: Organize Imports
- A mostly complete guide to error handling in JavaScript (2020)
- Awesome FP JS
- Perflink — JS Benchmarks.
- Element Worklet (2021)
- MDN JS Code Examples
- Understanding Hoisting in JavaScript (2021)
- JavaScript, the Good Parts Notes
- A Model for Reasoning About JavaScript Promises (2017)
- JavaScript Minification Benchmarks (HN)
- Faster JavaScript Calls (2021) (HN)
- Streams — The definitive guide (2021)
- Awesome JavaScript
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://gist.github.com/bgoonzhttps://gist.github.com/bgoonz
Or checkout my personal resource Site:
https://gist.github.com/bgoonz
Every extension or tool you could possibly need
Here’s a rudimentary static site I made that goes into more detail on the extensions I use…
https://5fff5b9a2430bb564bfd451d–stoic-mccarthy-2c335f.netlify.app/#h18
Here’s the repo it was deployed from:
https://github.com/bgoonz/vscode-Extension-readmes
Commands:
Command Palette
Access all available commands based on your current context.
Keyboard Shortcut: Ctrl+Shift+P
Command palette
⇧⌘PShow all commands⌘PShow files
Sidebars
⌘BToggle sidebar⇧⌘EExplorer⇧⌘FSearch⇧⌘DDebug⇧⌘XExtensions⇧^GGit (SCM)
Search
⌘FFind⌥⌘FReplace⇧⌘FFind in files⇧⌘HReplace in files
Panel
⌘JToggle panel⇧⌘MProblems⇧⌘UOutput⇧⌘YDebug console^`Terminal
View
⌘k zZen mode⌘k uClose unmodified⌘k wClose all
Debug
F5Start⇧F5Stop⇧⌘F5Restart^F5Start without debuggingF9Toggle breakpointF10Step overF11Step into⇧F11Step out⇧⌘DDebug sidebar⇧⌘YDebug panel

Tips-N-Tricks:
Here is a selection of common features for editing code. If the keyboard shortcuts aren’t comfortable for you, consider installing a keymap extension for your old editor.
Tip: You can see recommended keymap extensions in the Extensions view with Ctrl+K Ctrl+M which filters the search to @recommended:keymaps.
Multi cursor selection
To add cursors at arbitrary positions, select a position with your mouse and use Alt+Click (Option+click on macOS).
To set cursors above or below the current position use:
Keyboard Shortcut: Ctrl+Alt+Up or Ctrl+Alt+Down
You can add additional cursors to all occurrences of the current selection with Ctrl+Shift+L.
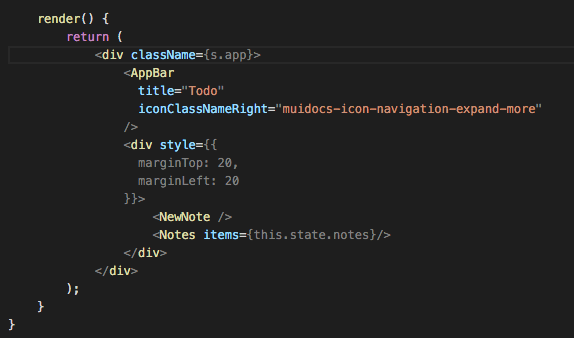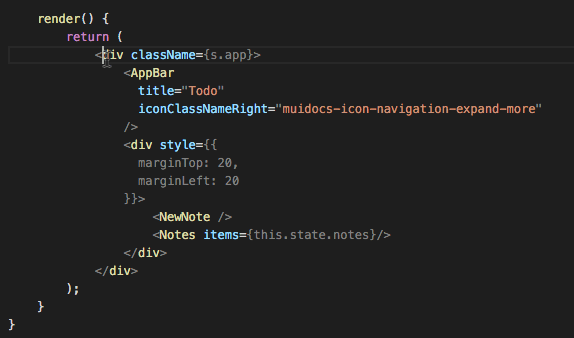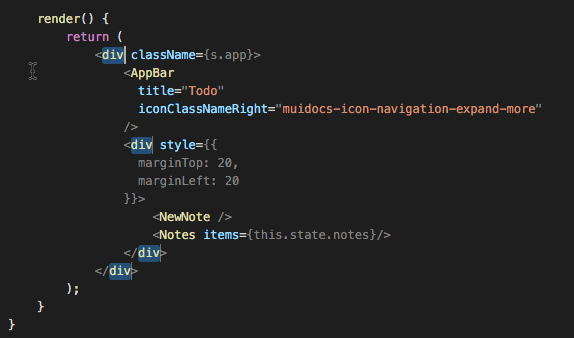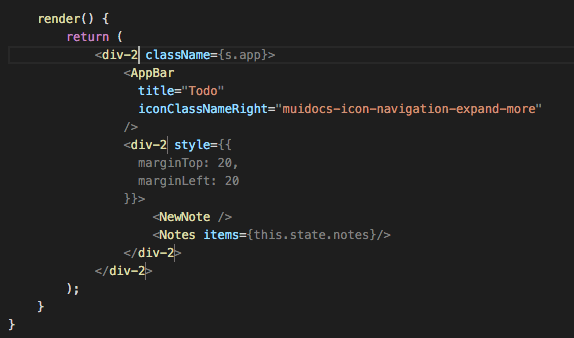
Note: You can also change the modifier to Ctrl/Cmd for applying multiple cursors with the
_editor.multiCursorModifier_setting . See Multi-cursor Modifier for details.
If you do not want to add all occurrences of the current selection, you can use Ctrl+D instead. This only selects the next occurrence after the one you selected so you can add selections one by one.
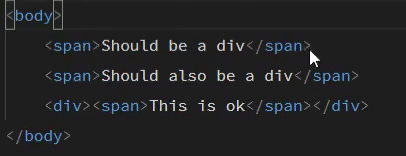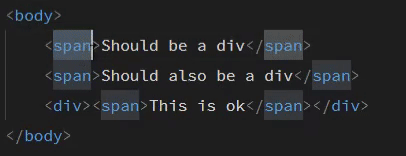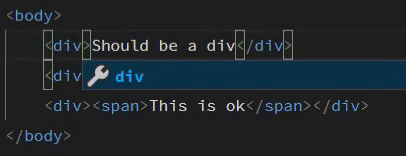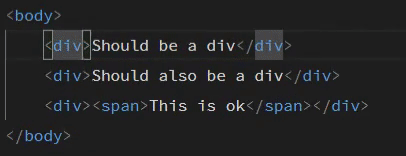
Column (box) selection
You can select blocks of text by holding Shift+Alt (Shift+Option on macOS) while you drag your mouse. A separate cursor will be added to the end of each selected line.
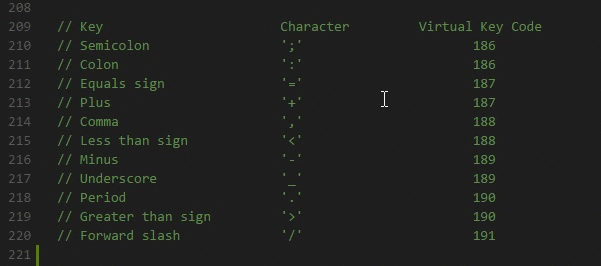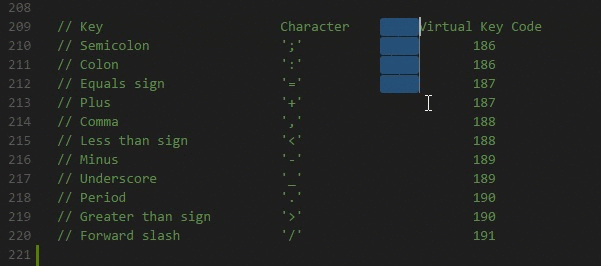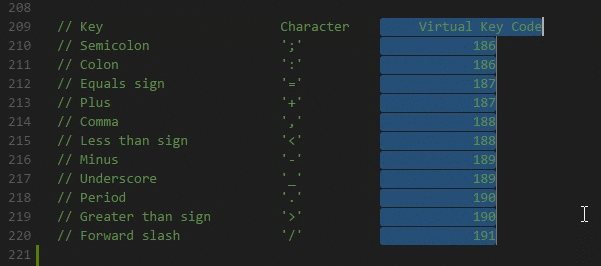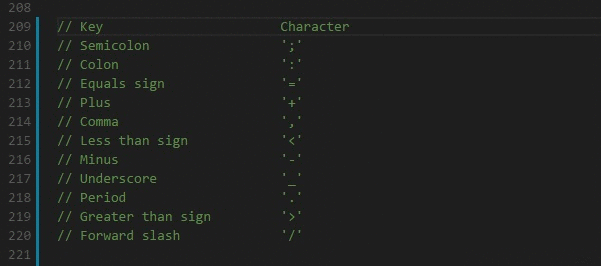
You can also use keyboard shortcuts to trigger column selection.
Extensions:
AutoHotkey Plus
Syntax Highlighting, Snippets, Go to Definition, Signature helper and Code formatter
Bash Debug
A debugger extension for Bash scripts based on
_bashdb_
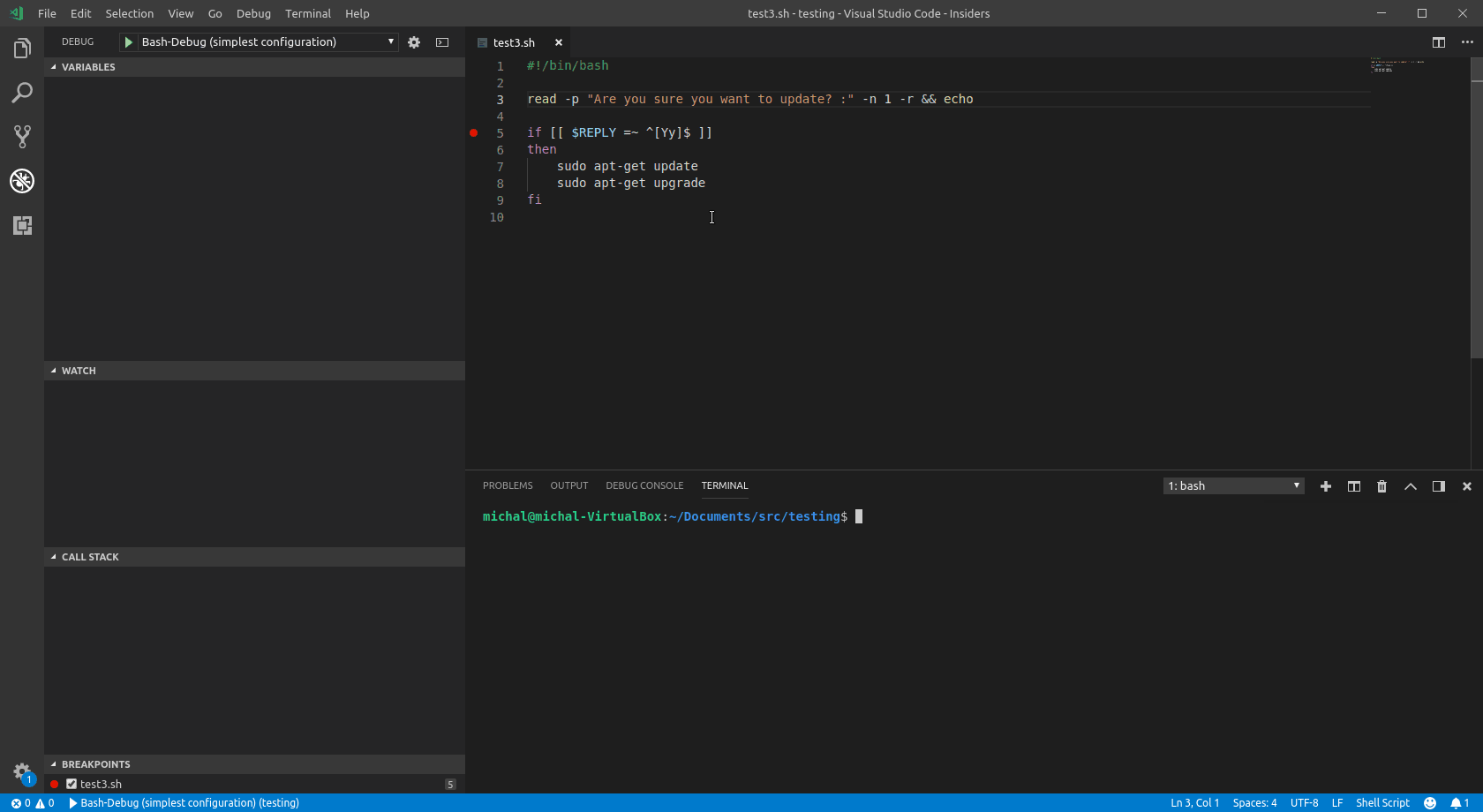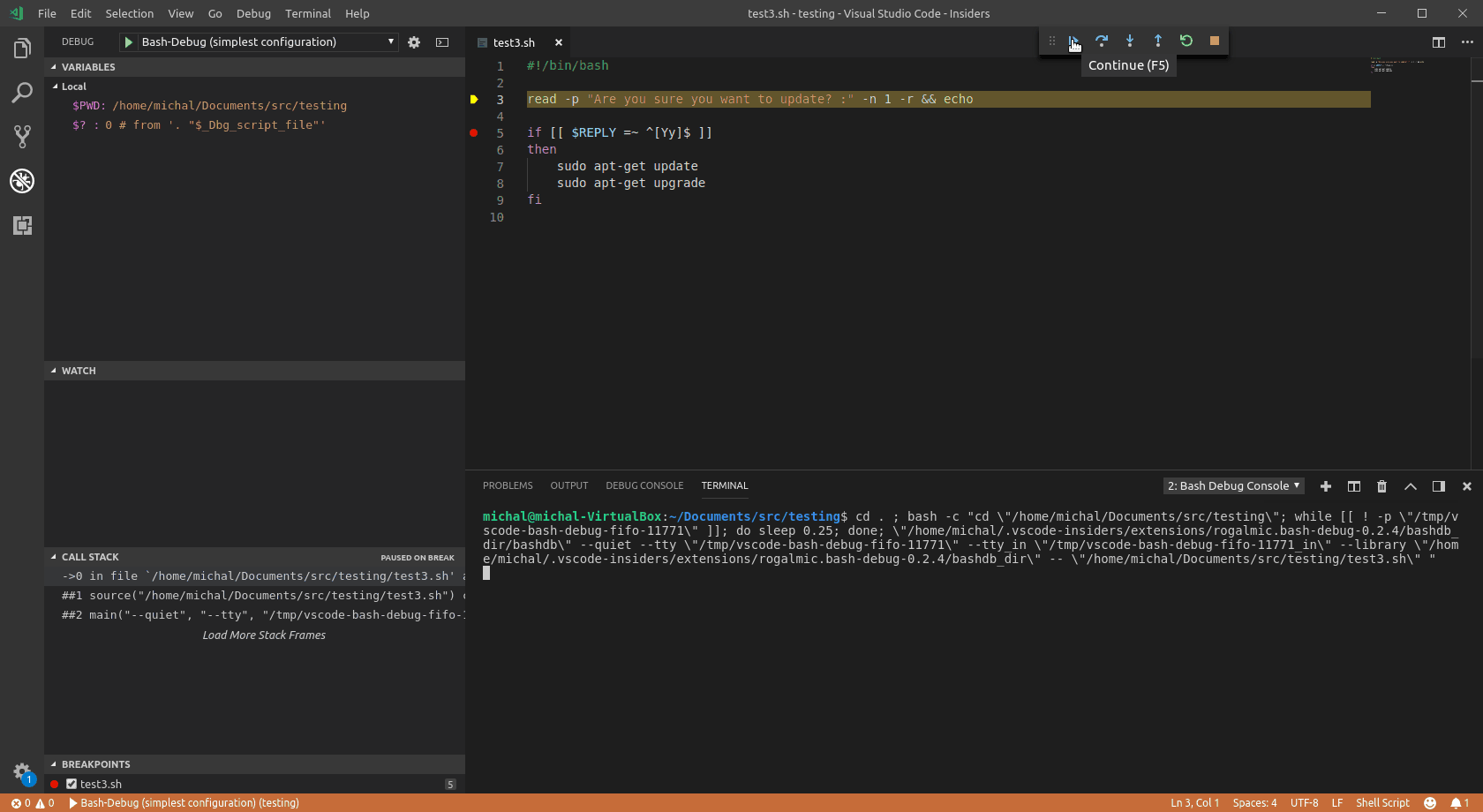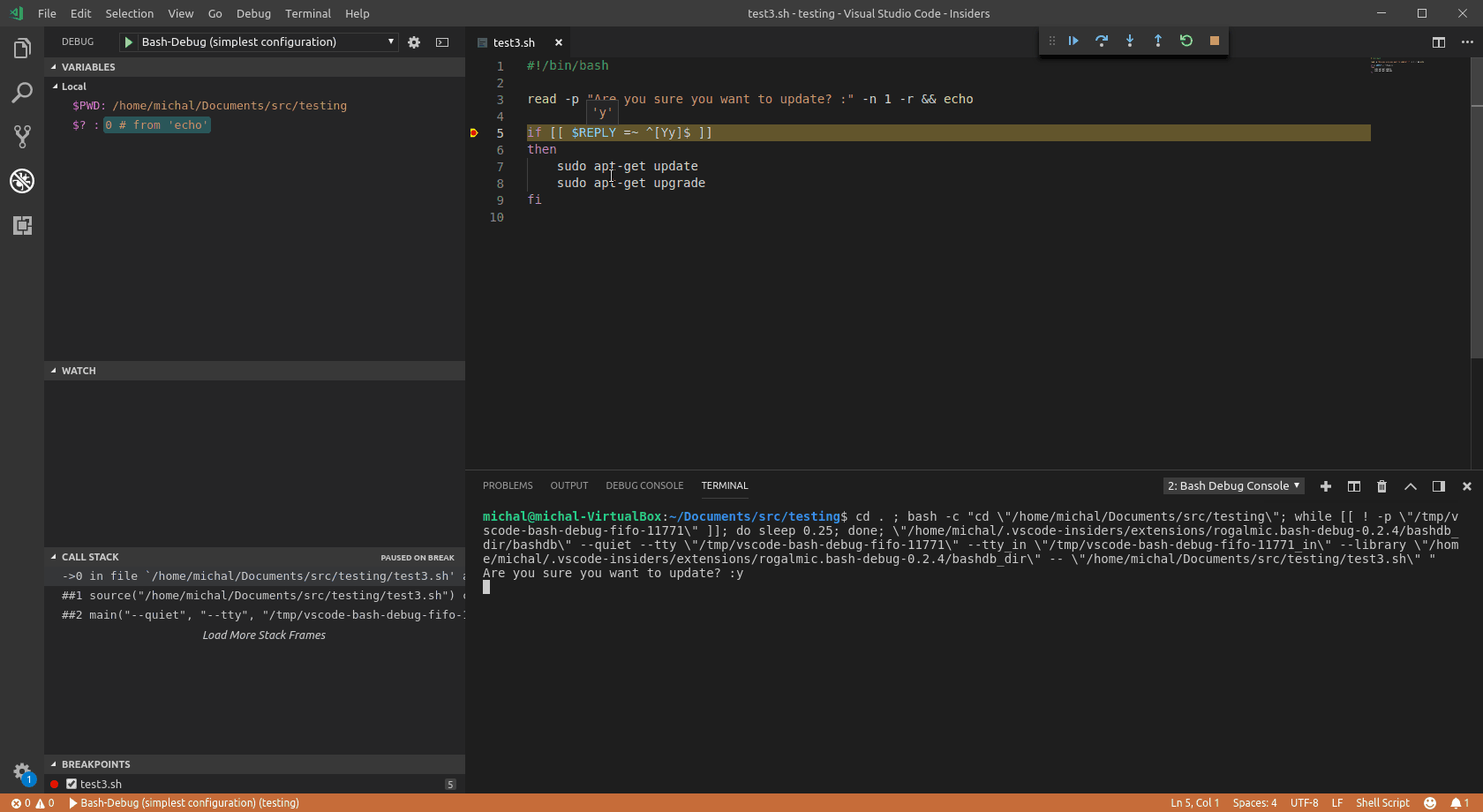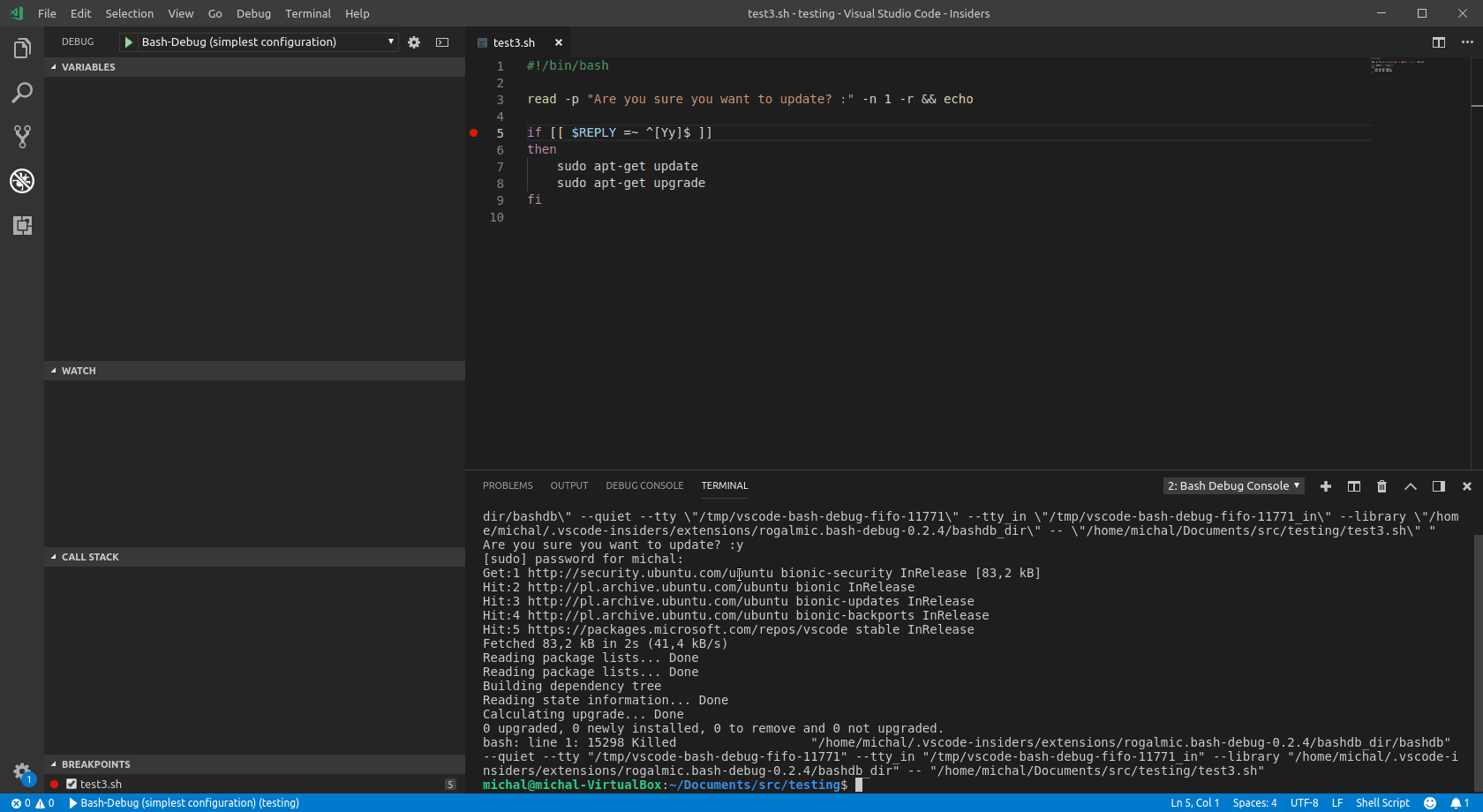
Shellman
Bash script snippets extension
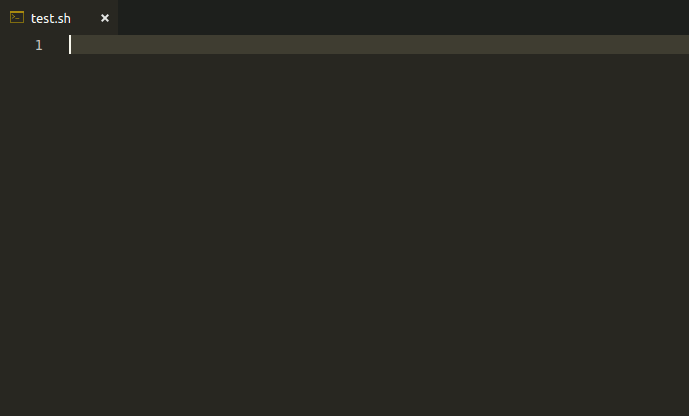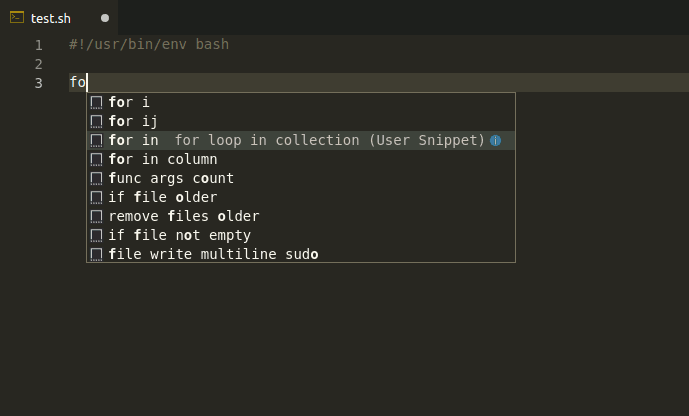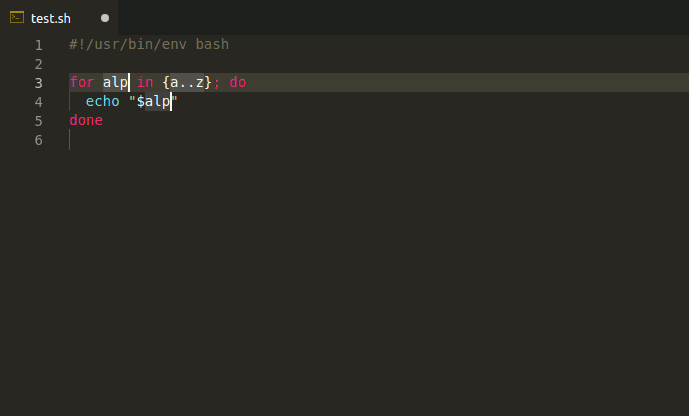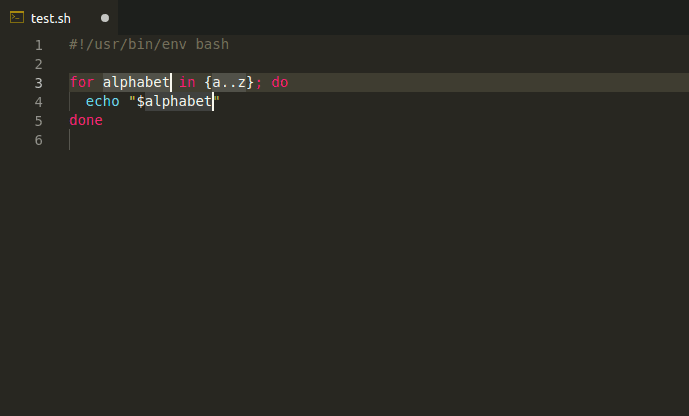
C++
C/C++ — Preview C/C++ extension by Microsoft, read official blog post for the details
Clangd — Provides C/C++ language IDE features for VS Code using clangd: code completion, compile errors and warnings, go-to-definition and cross references, include management, code formatting, simple refactorings.
gnu-global-tags — Provide Intellisense for C/C++ with the help of the GNU Global tool.
YouCompleteMe — Provides semantic completions for C/C++ (and TypeScript, JavaScript, Objective-C, Golang, Rust) using YouCompleteMe.
C/C++ Clang Command Adapter — Completion and Diagnostic for C/C++/Objective-C using Clang command.
CQuery — C/C++ language server supporting multi-million line code base, powered by libclang. Cross references, completion, diagnostics, semantic highlighting and more.
More
C#, ASP .NET and .NET Core
C# — C# extension by Microsoft, read official documentation for the details
C# FixFormat — Fix format of usings / indents / braces / empty lines
C# Extensions — Provides extensions to the IDE that will speed up your development workflow.
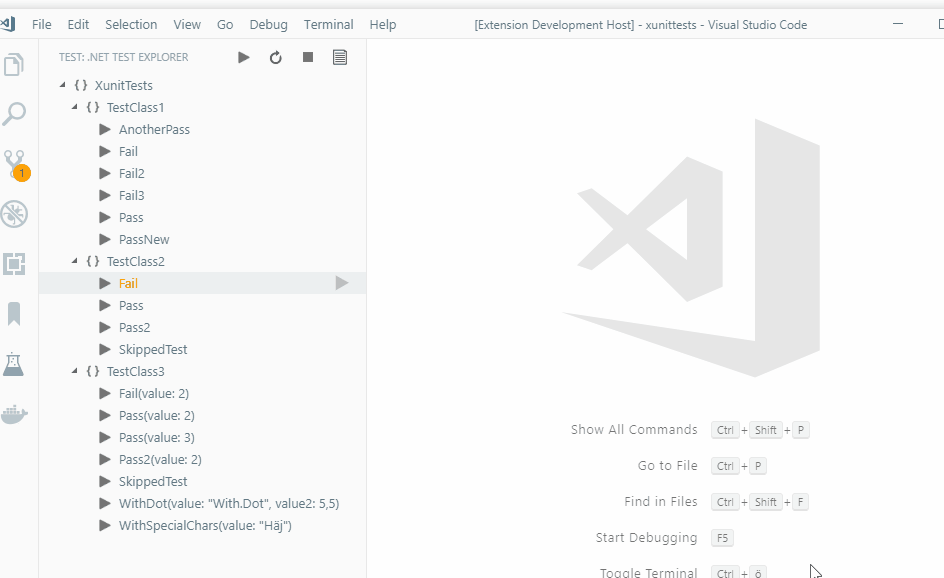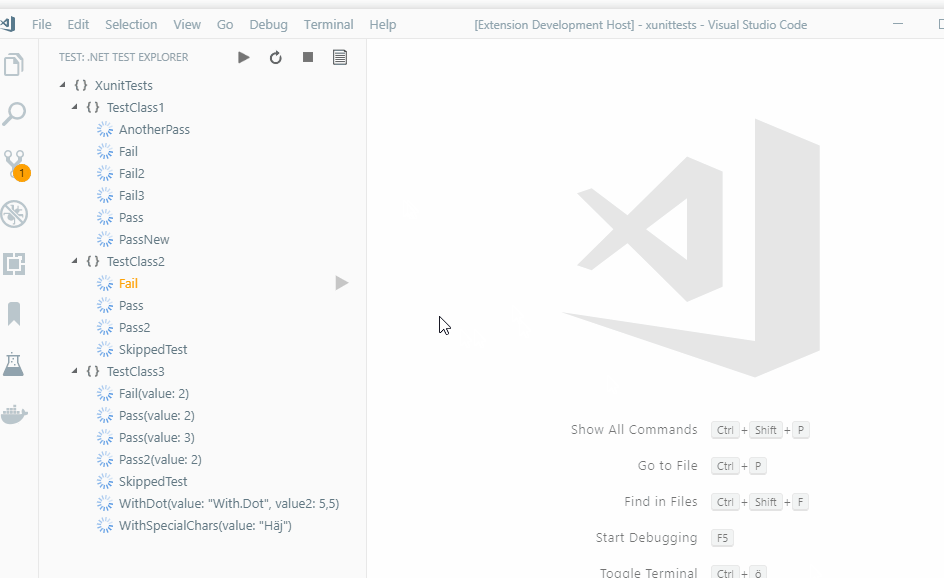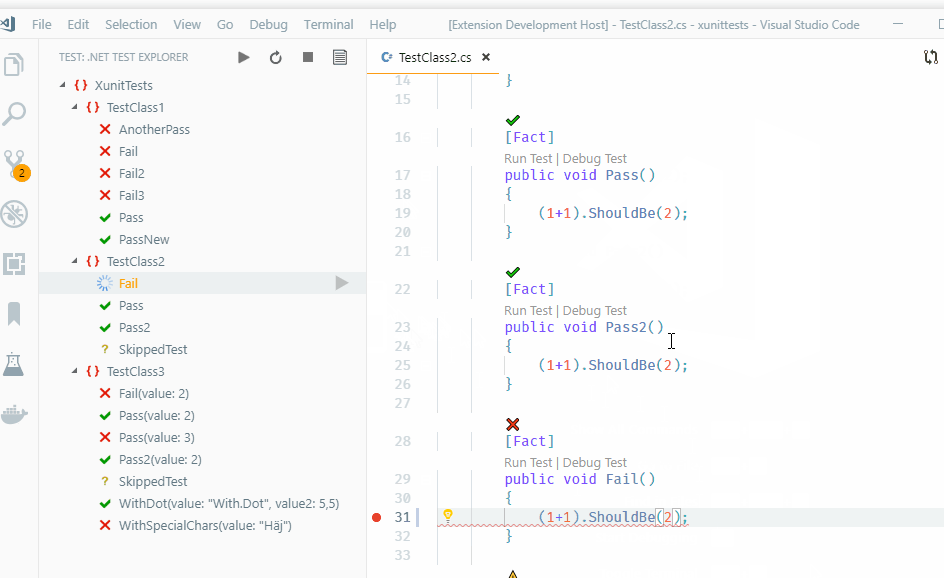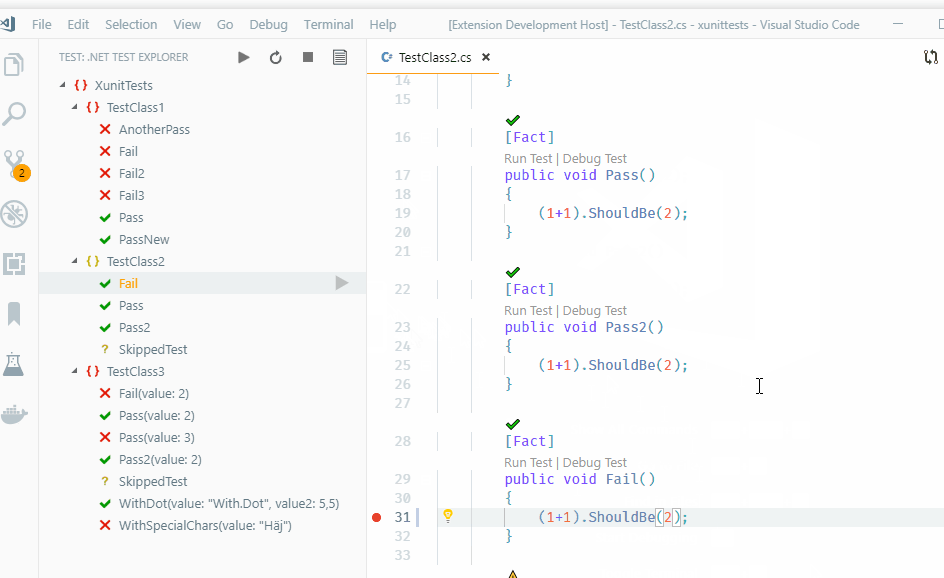
CSS
CSS Peek
Peek or Jump to a CSS definition directly from HTML, just like in Brackets!
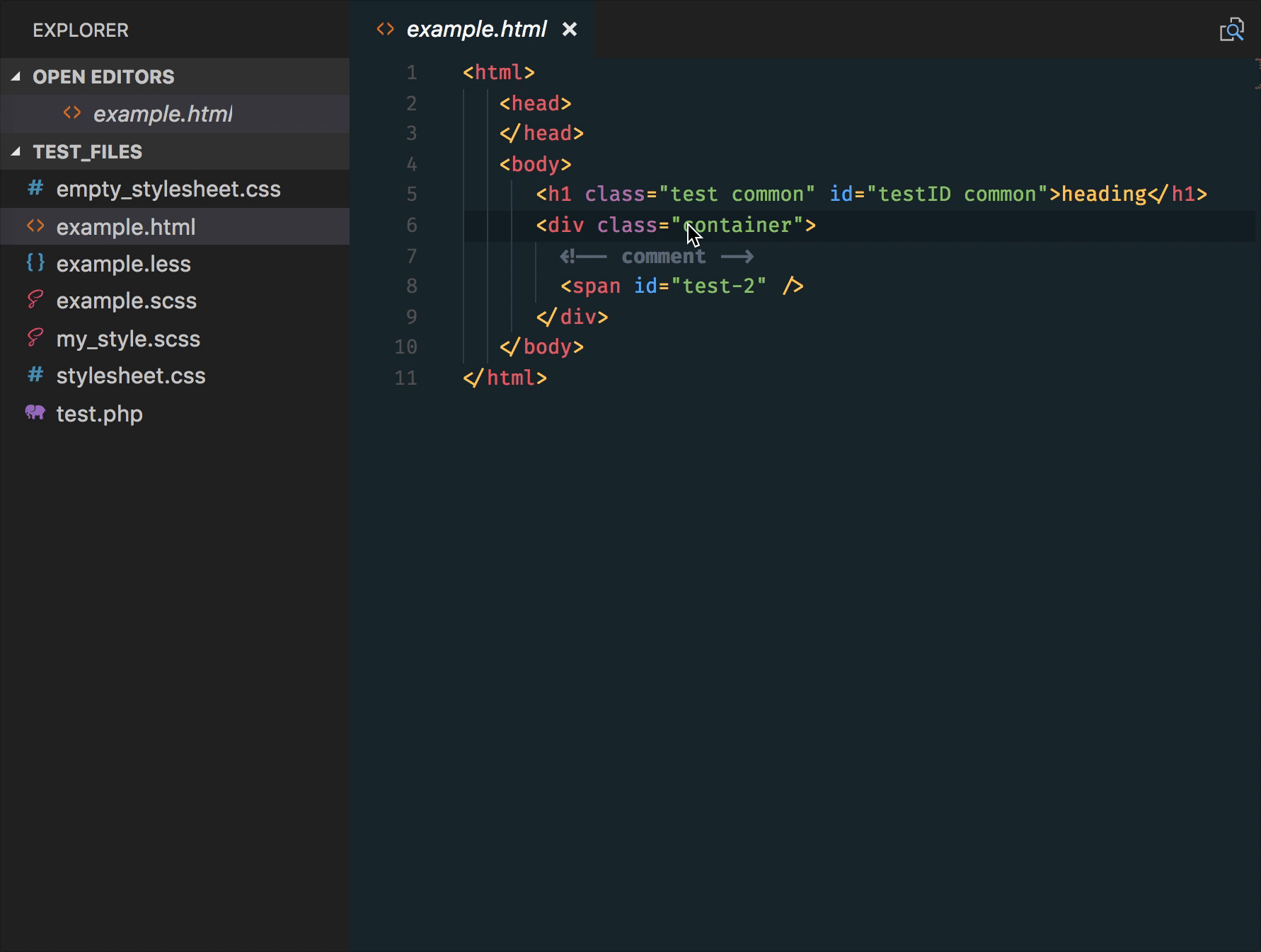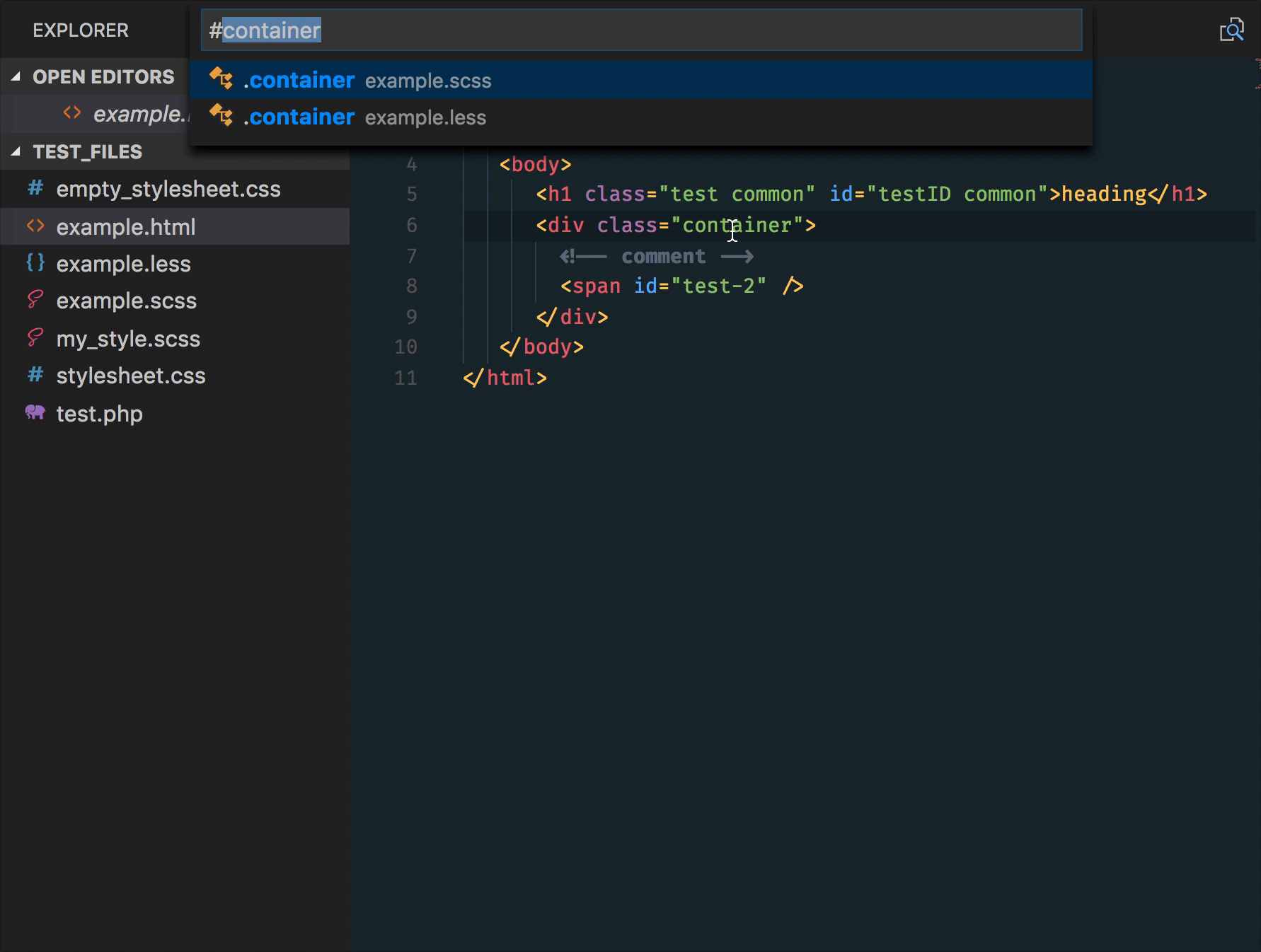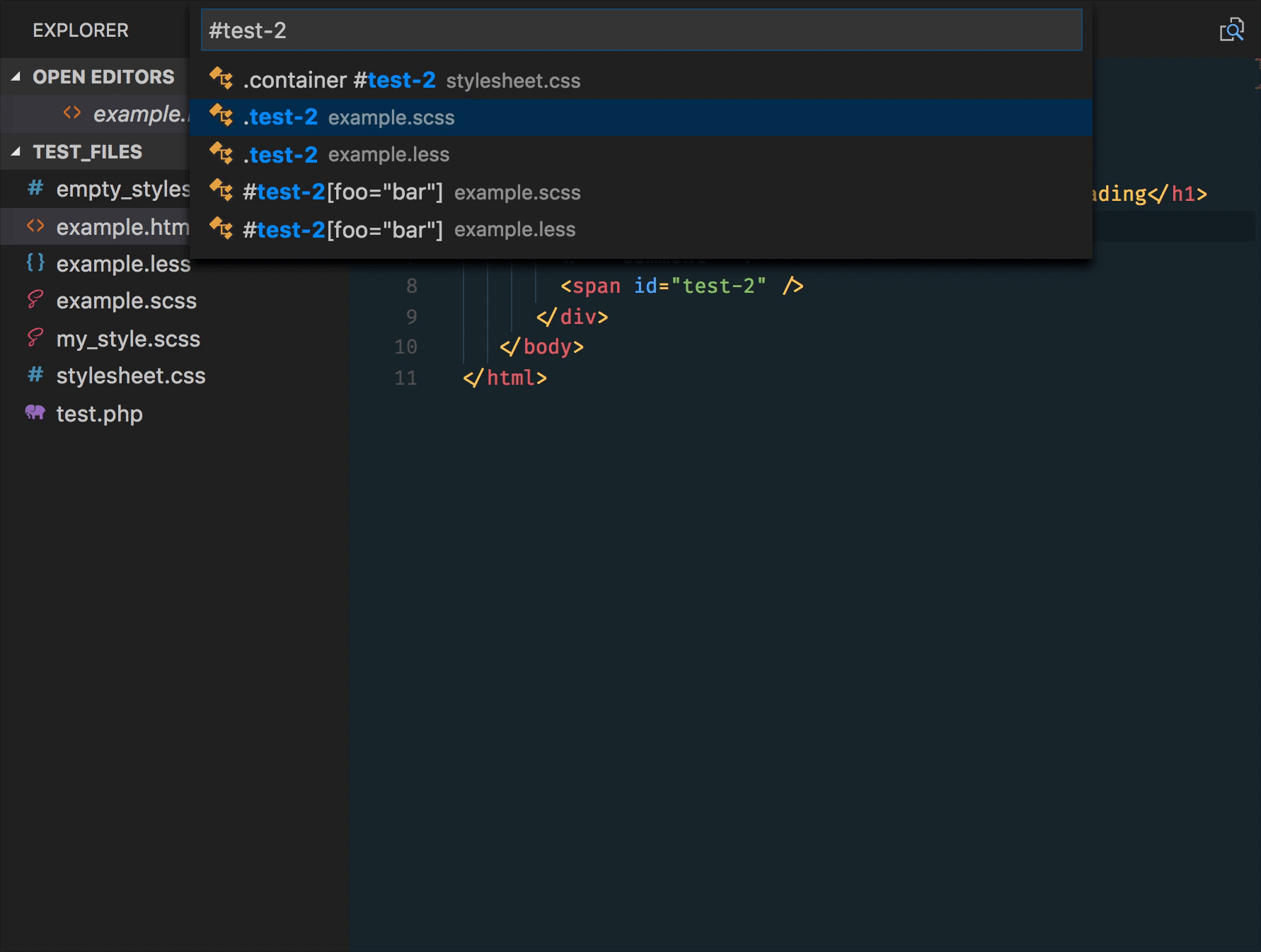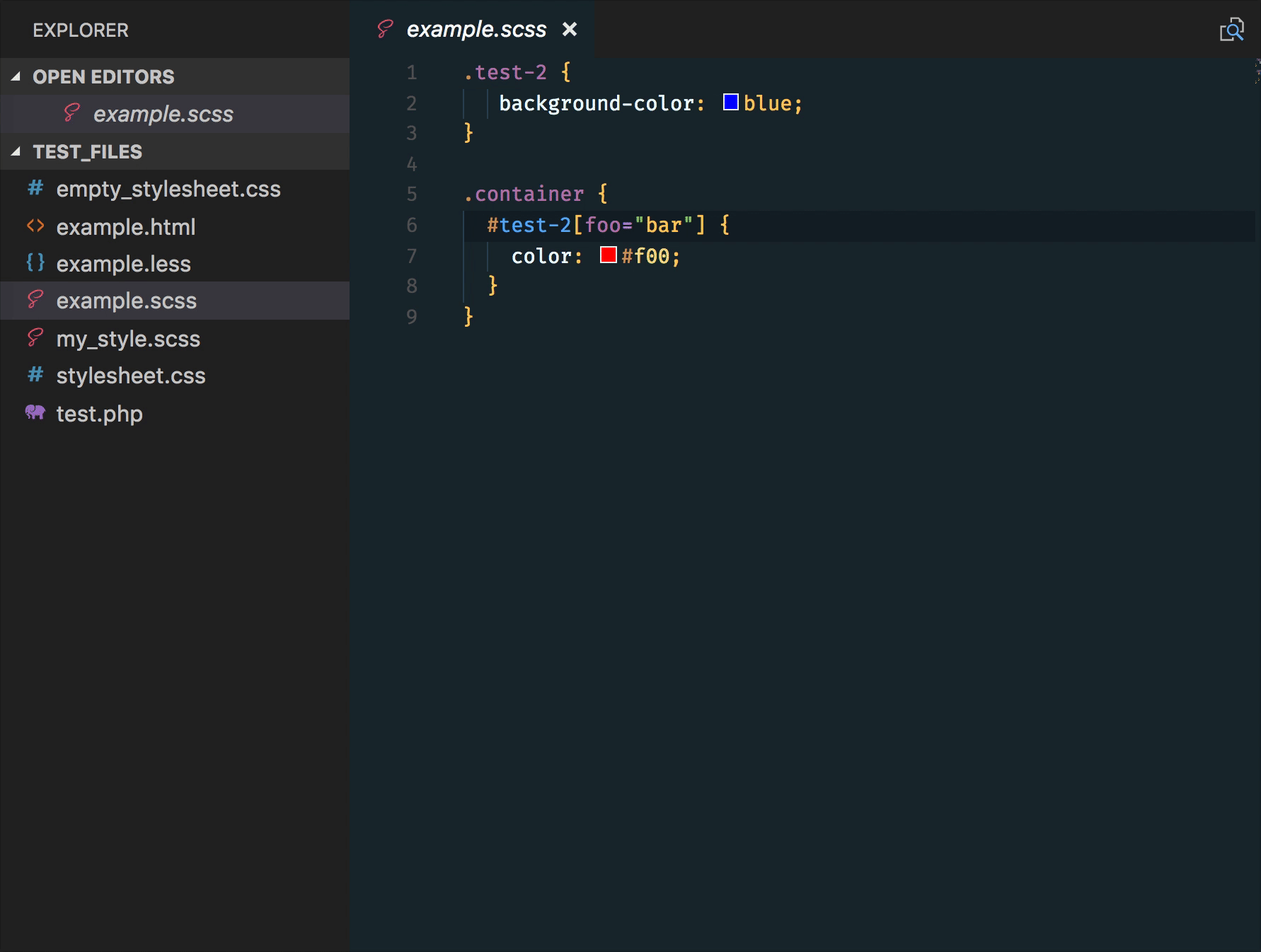
- stylelint — Lint CSS/SCSS.
- Autoprefixer Parse CSS,SCSS, LESS and add vendor prefixes automatically.
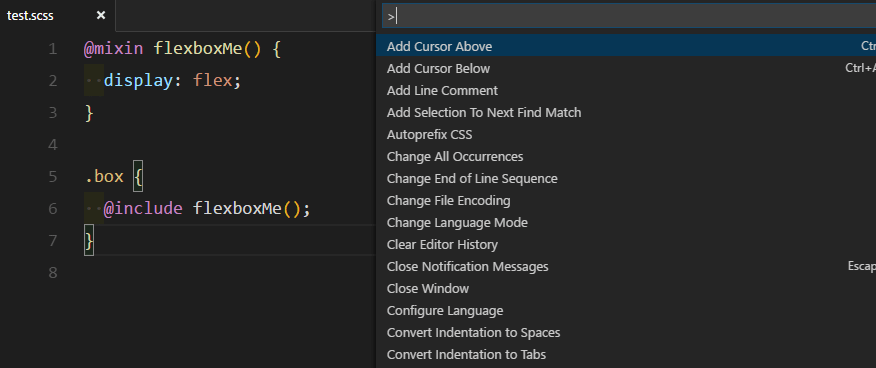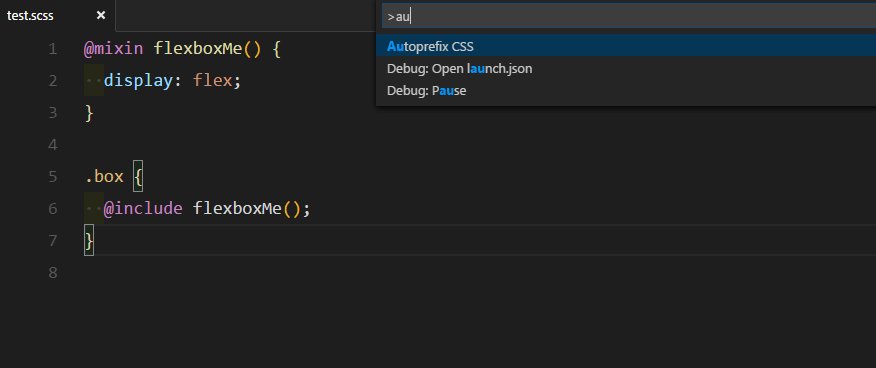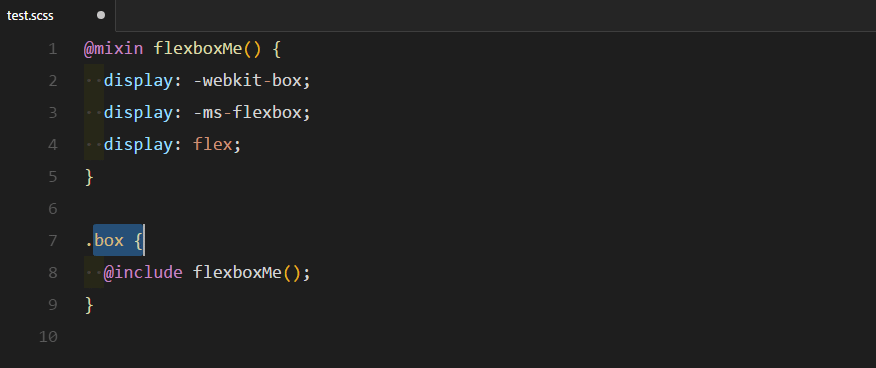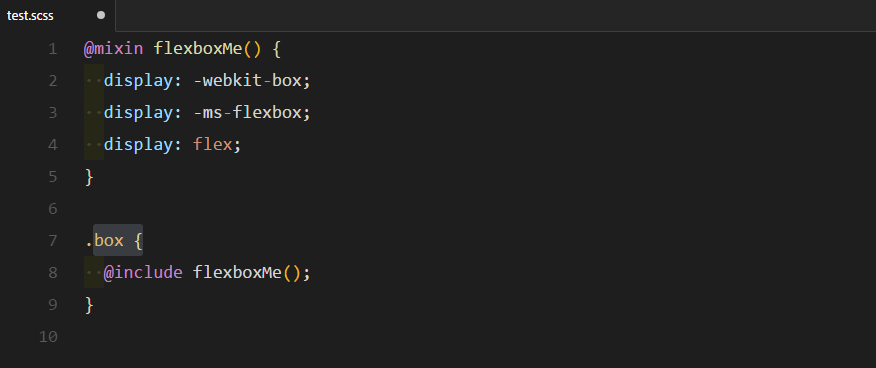
- Intellisense for CSS class names — Provides CSS class name completion for the HTML class attribute based on the CSS files in your workspace. Also supports React’s className attribute.
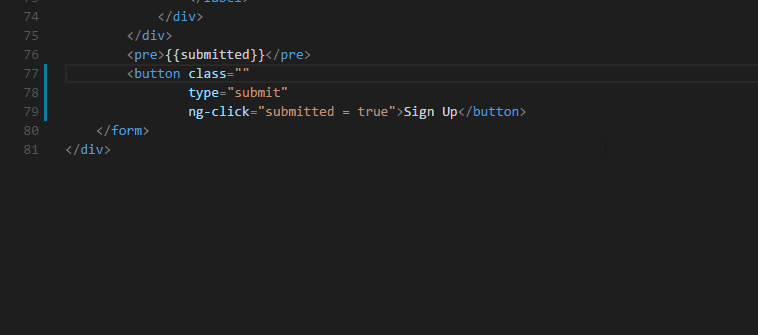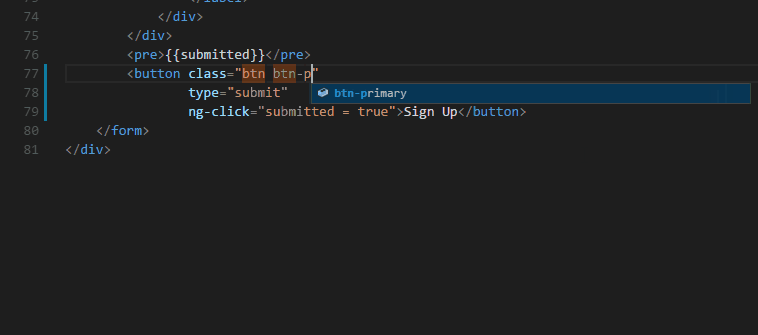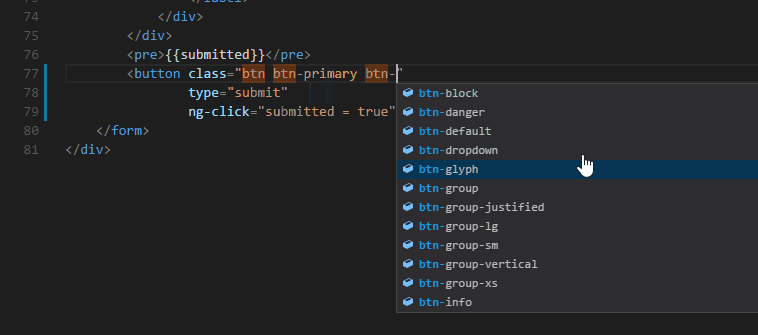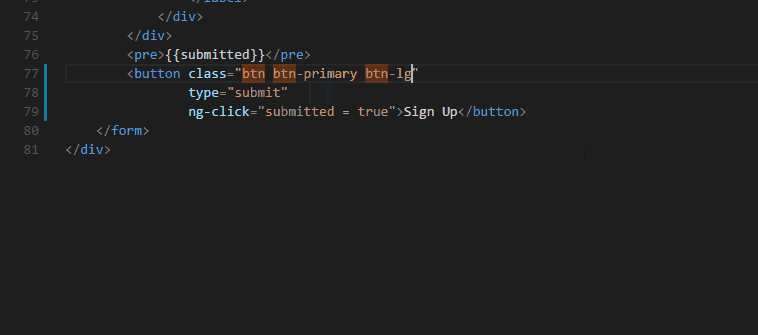
Groovy
- VsCode Groovy Lint — Groovy lint, format, prettify and auto-fix
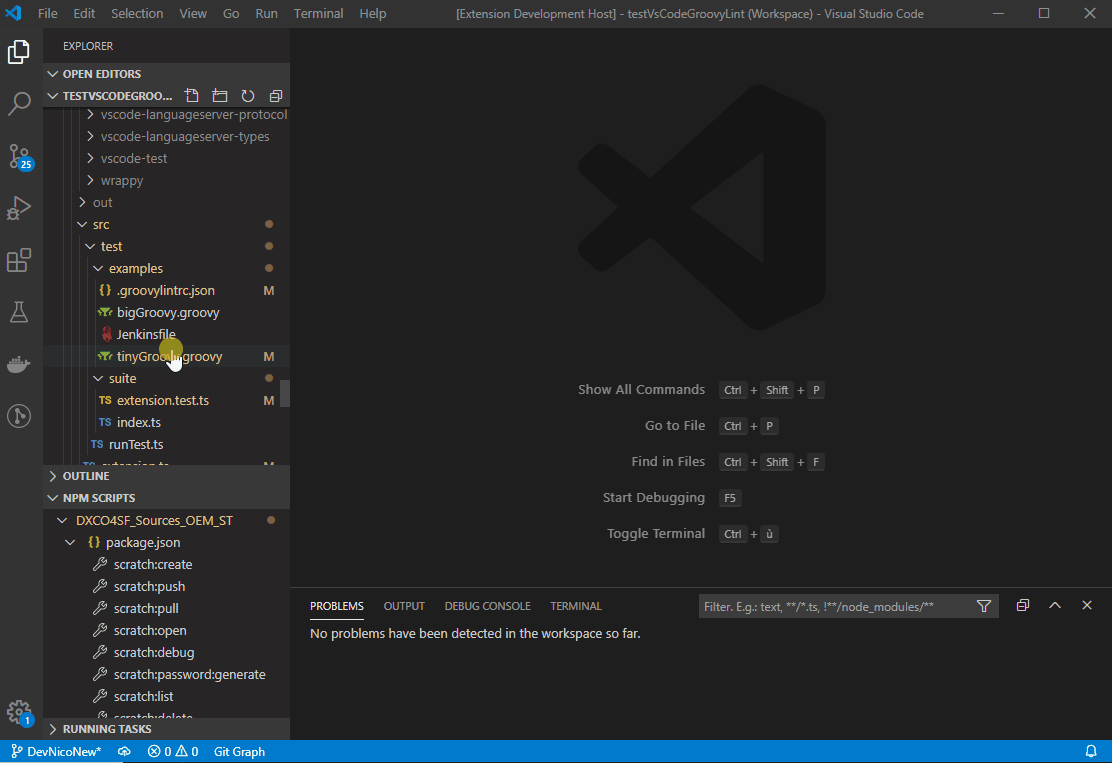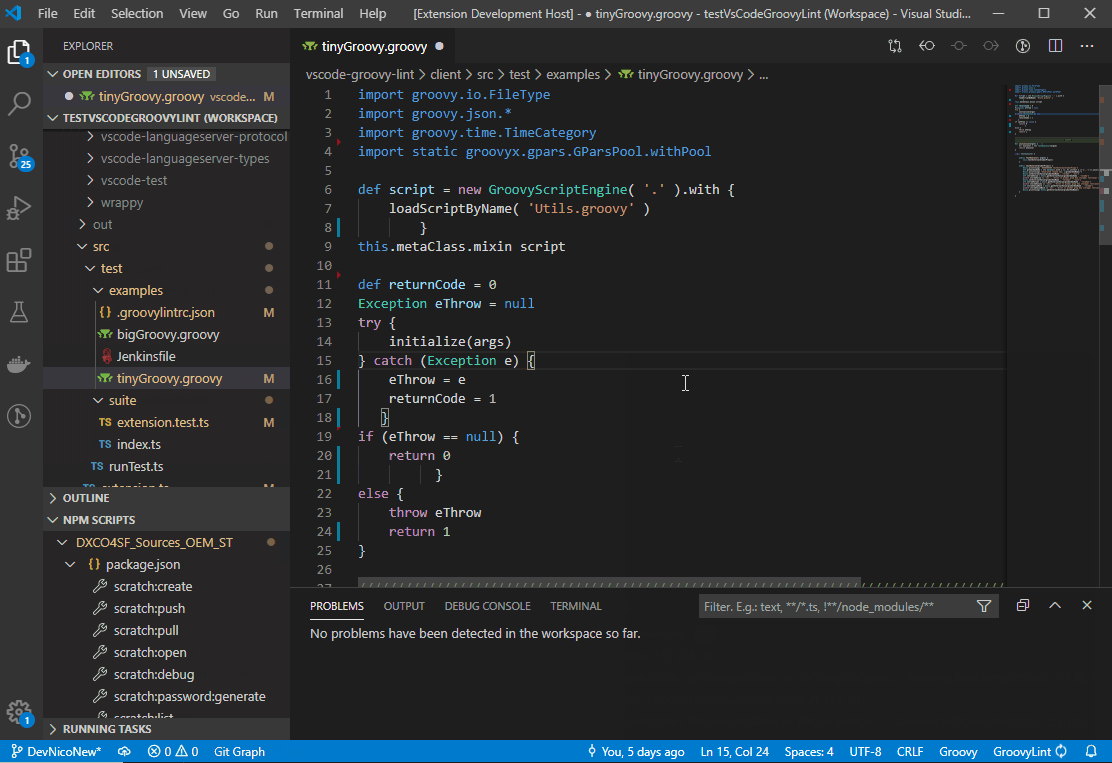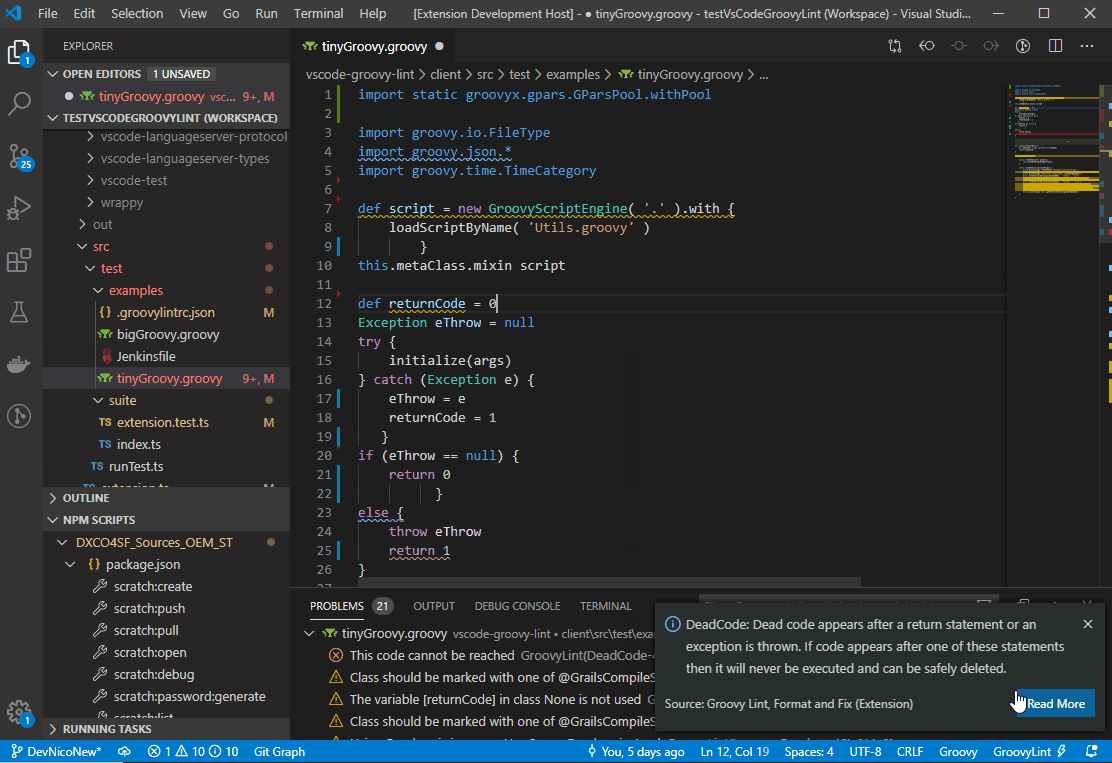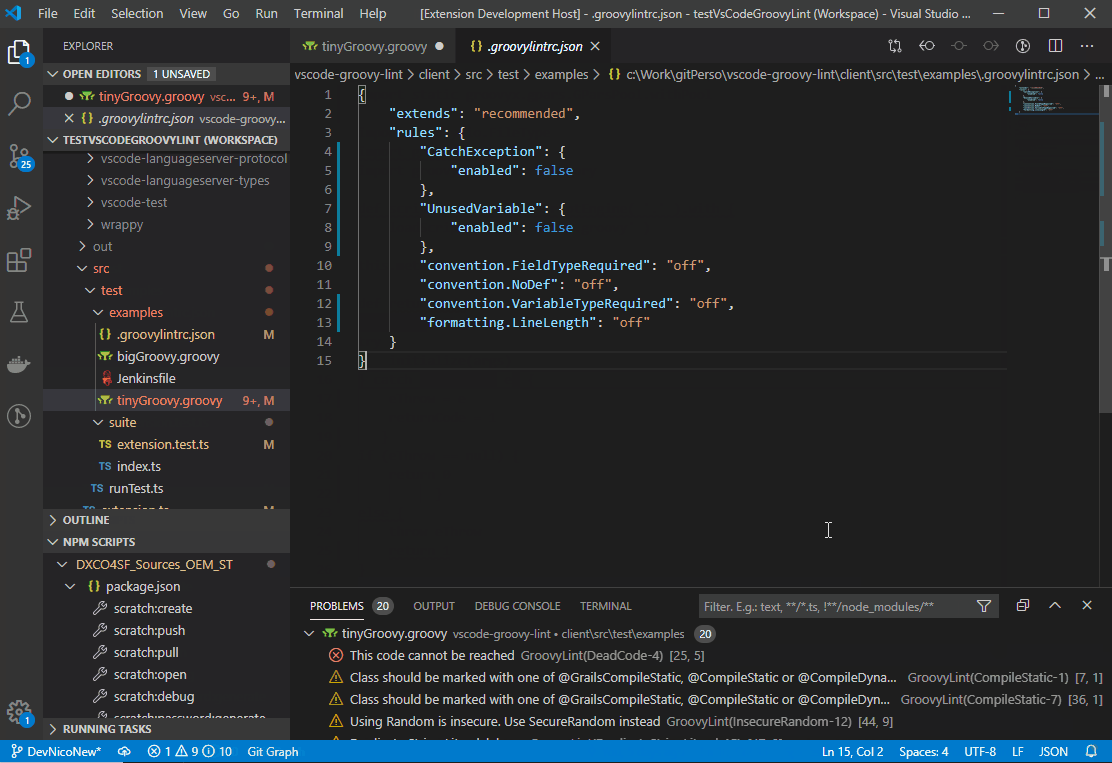
Haskell
- haskell-linter
- Haskell IDE engine — provides language server for stack and cabal projects.
- autocomplate-shell
Java
JavaScript
- Babel JavaScript
- Visual Studio IntelliCode — This extension provides AI-assisted development features including autocomplete and other insights based on understanding your code context.
See the difference between these two here
tslint — TSLint for Visual Studio Code (with
"tslint.jsEnable": true).
Prettier — Linter, Formatter and Pretty printer for Prettier.
Schema.org Snippets — Snippets for Schema.org.
Code Spell Checker — Spelling Checker for Visual Studio Code.
Framework-specific:
Vetur — Toolkit for Vue.js
Debugger for Chrome
A VS Code extension to debug your JavaScript code in the Chrome browser, or other targets that support the Chrome Debugging Protocol.
Facebook Flow
- Flow Language Support — provides all the functionality you would expect — linting, intellisense, type tooltips and click-to-definition
- vscode-flow-ide — an alternative Flowtype extension for Visual Studio Code
TypeScript
- tslint — TSLint for Visual Studio Code
- TypeScript Hero — Code outline view of your open TS, sort and organize your imports.
Markdown
markdownlint
Linter for markdownlint.
Markdown All in One
All-in-one markdown plugin (keyboard shortcuts, table of contents, auto preview, list editing and more)
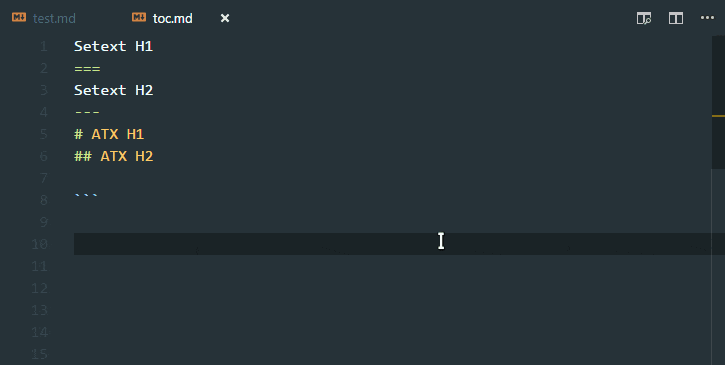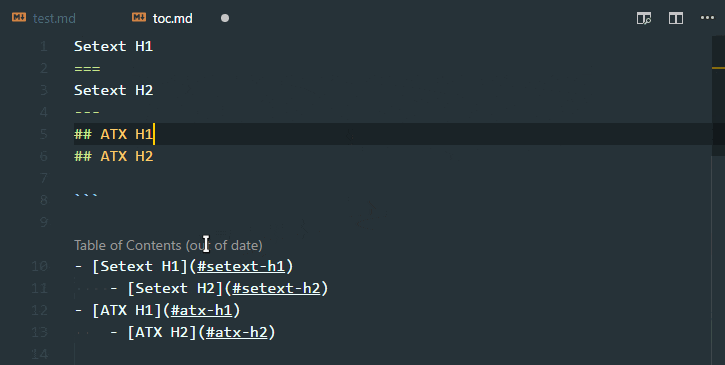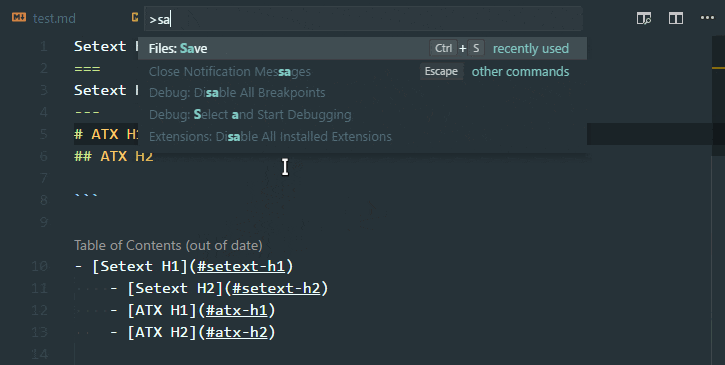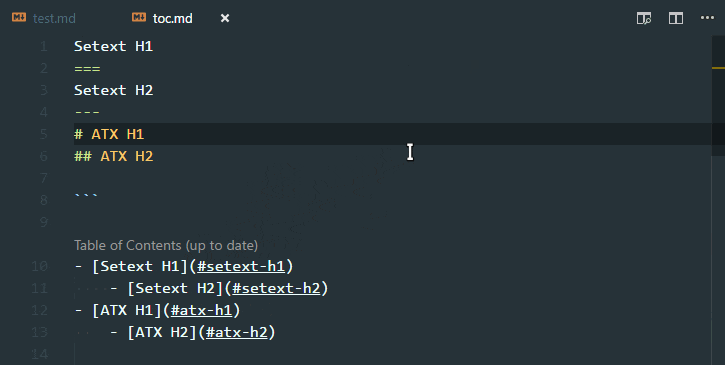
Markdown Emoji
Adds emoji syntax support to VS Code’s built-in Markdown preview
PHP
IntelliSense
These extensions provide slightly different sets of features. While the first one offers better autocompletion support, the second one seems to have more features overall.
Laravel
- Laravel 5 Snippets — Laravel 5 snippets for Visual Studio Code
- Laravel Blade Snippets — Laravel blade snippets and syntax highlight support
- Laravel Model Snippets — Quickly get models up and running with Laravel Model Snippets.
- Laravel Artisan — Laravel Artisan commands within Visual Studio Code

- DotENV — Support for dotenv file syntax
Other extensions
- Format HTML in PHP — Formatting for the HTML in PHP files. Runs before the save action so you can still have a PHP formatter.
- Composer
- PHP Debug — XDebug extension for Visual Studio Code
- PHP DocBlocker
- php cs fixer — PHP CS Fixer extension for VS Code, php formatter, php code beautify tool
- phpcs — PHP CodeSniffer for Visual Studio Code
- phpfmt — phpfmt for Visual Studio Code
Python
- Python — Linting, Debugging (multi threaded, web apps), Intellisense, auto-completion, code formatting, snippets, unit testing, and more.
TensorFlow
- TensorFlow Snippets — This extension includes a set of useful code snippets for developing TensorFlow models in Visual Studio Code.
Rust
- Rust — Linting, auto-completion, code formatting, snippets and more
Productivity
ARM Template Viewer
Displays a graphical preview of Azure Resource Manager (ARM) templates. The view will show all resources with the official Azure icons and also linkage between the resources.
Azure Cosmos DB
Browse your database inside the vs code editor
Azure IoT Toolkit
Everything you need for the Azure IoT development: Interact with Azure IoT Hub, manage devices connected to Azure IoT Hub, and develop with code snippets for Azure IoT Hub
Bookmarks
Mark lines and jump to them
Color Tabs
An extension for big projects or monorepos that colors your tab/titlebar based on the current package
Create tests
An extension to quickly generate test files.
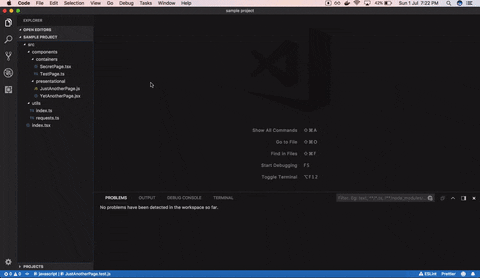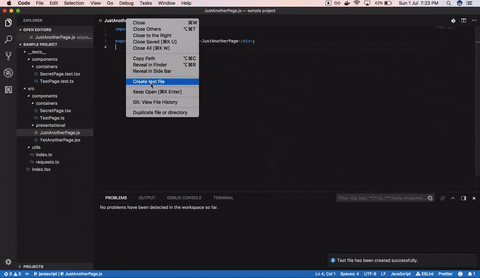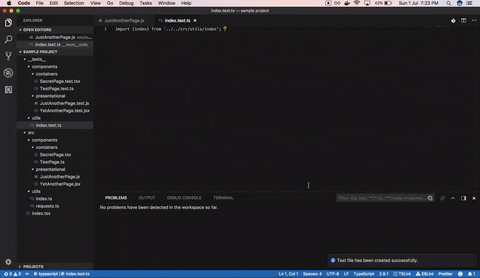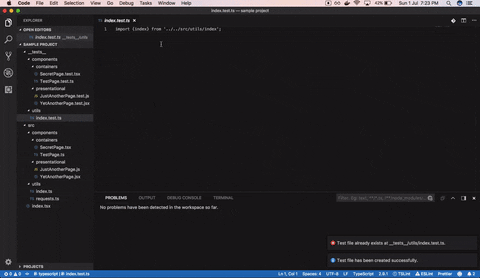
Deploy
Commands for upload or copy files of a workspace to a destination.
Duplicate Action
Ability to duplicate files and directories.
Error Lens
Show language diagnostics inline (errors/warnings/…).

ES7 React/Redux/GraphQL/React-Native snippets
Provides Javascript and React/Redux snippets in ES7
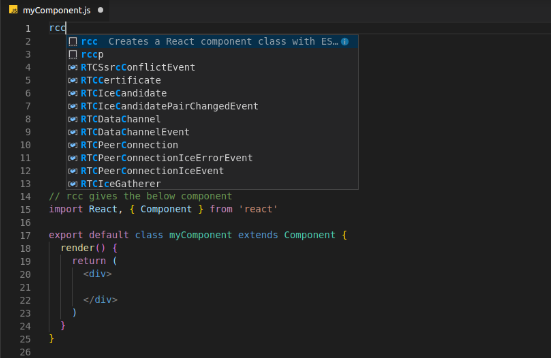
Gi
Generating .gitignore files made easy
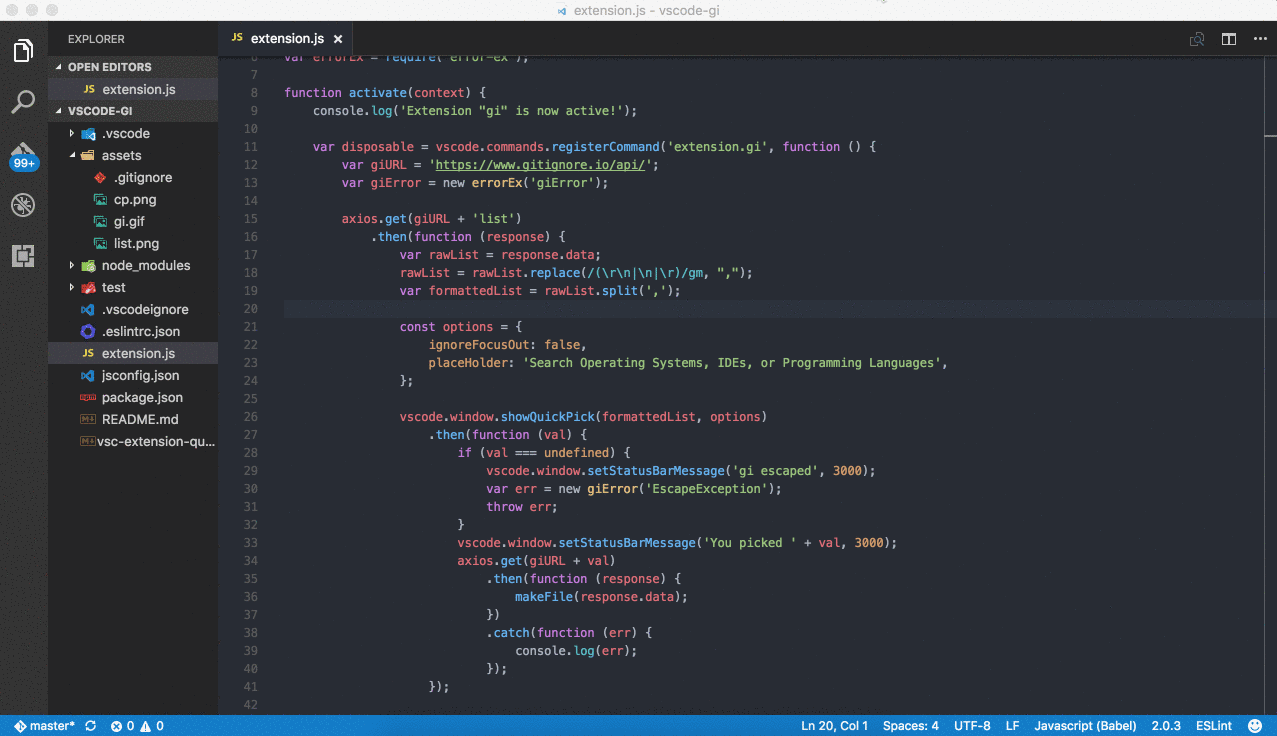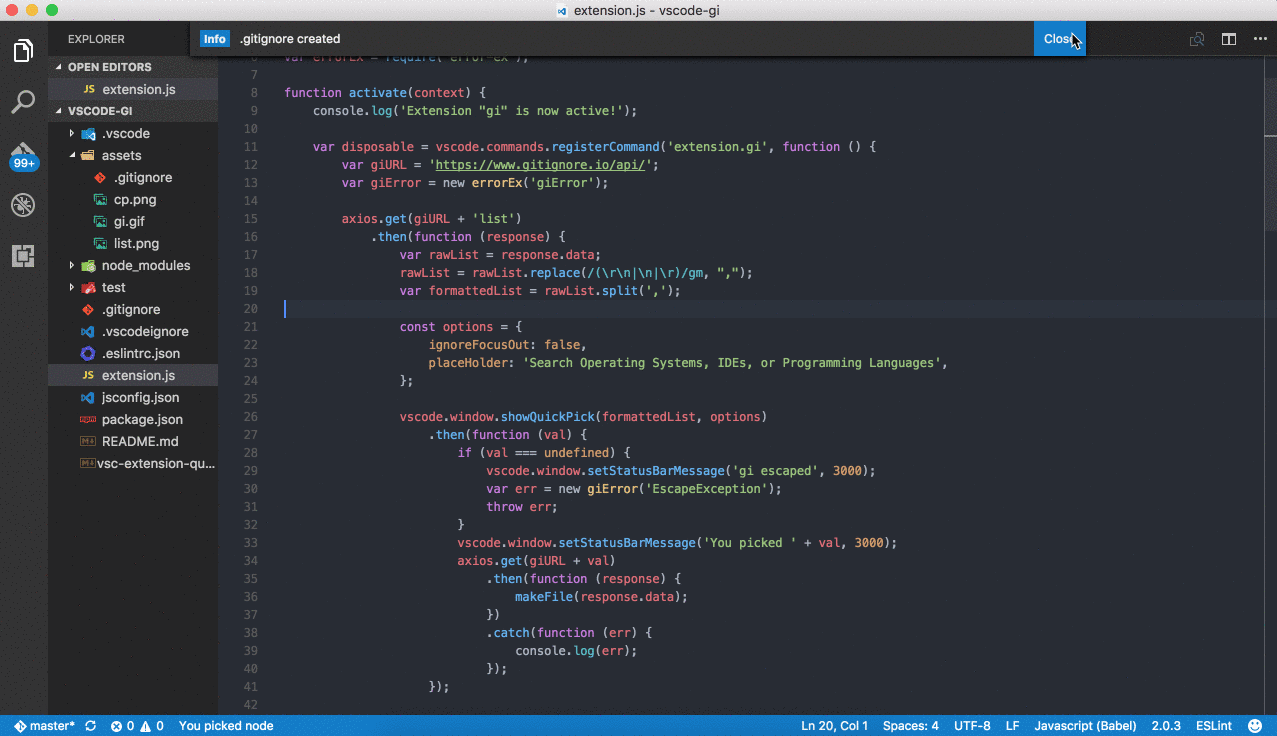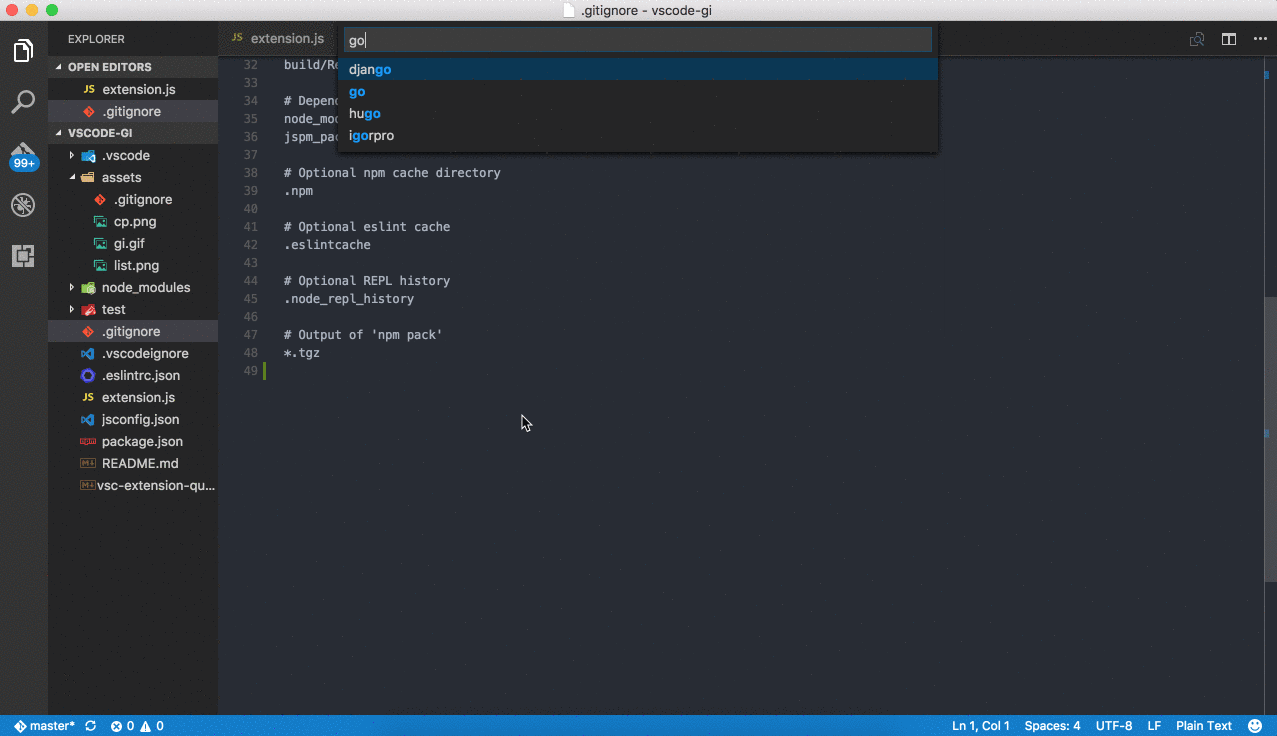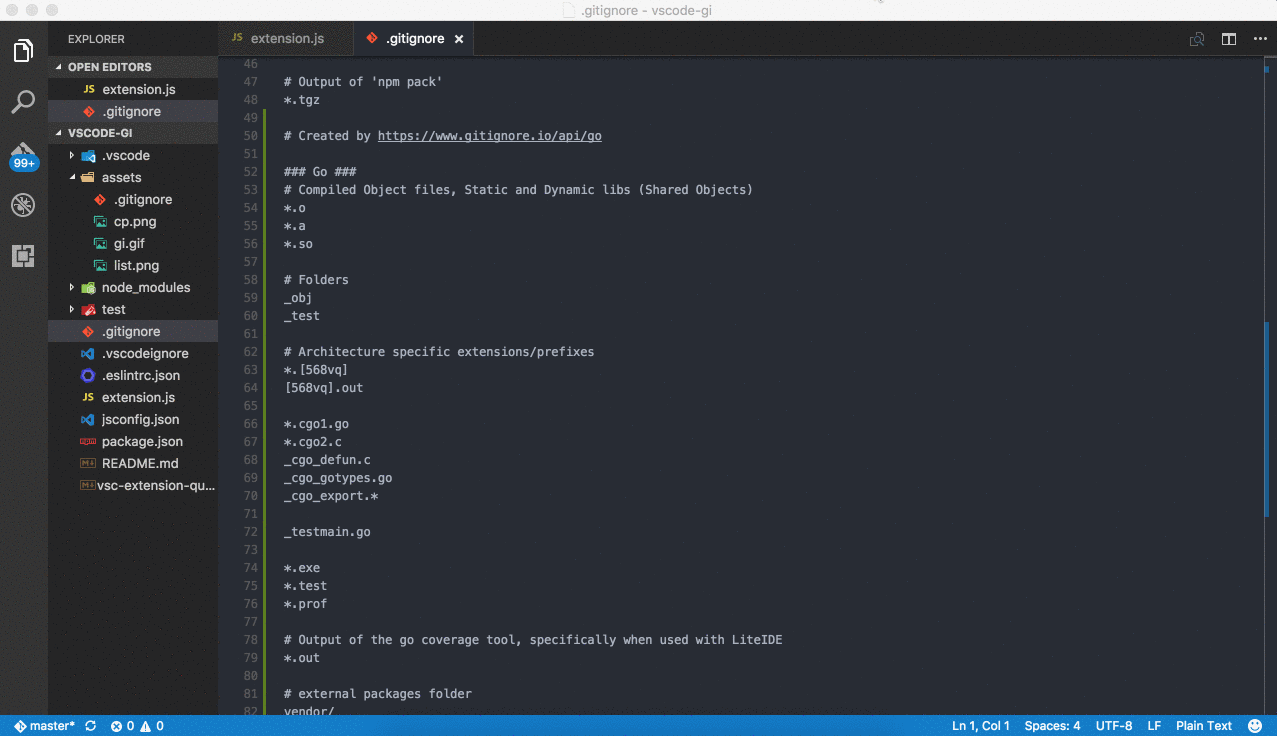
GistPad
Allows you to manage GitHub Gists entirely within the editor. You can open, create, delete, fork, star and clone gists, and then seamlessly begin editing files as if they were local. It’s like your very own developer library for building and referencing code snippets, commonly used config/scripts, programming-related notes/documentation, and interactive samples.
Git History
View git log, file or line History
Git Project Manager
Automatically indexes your git projects and lets you easily toggle between them
GitLink
GoTo current file’s online link in browser and Copy the link in clipboard.
GitLens
Provides Git CodeLens information (most recent commit, # of authors), on-demand inline blame annotations, status bar blame information, file and blame history explorers, and commands to compare changes with the working tree or previous versions.
Git Indicators
Atom-like git indicators on active panel



GitHub
Provides GitHub workflow support. For example browse project, issues, file (the current line), create and manage pull request. Support for other providers (e.g. gitlab or bitbucket) is planned. Have a look at the README.md on how to get started with the setup for this extension.
GitHub Pull Request Monitor
This extension uses the GitHub api to monitor the state of your pull requests and let you know when it’s time to merge or if someone requested changes.

GitLab Workflow
Adds a GitLab sidebar icon to view issues, merge requests and other GitLab resources. You can also view the results of your GitLab CI/CD pipeline and check the syntax of your
_.gitlab-ci.yml_.
Gradle Tasks
Run gradle tasks in VS Code.
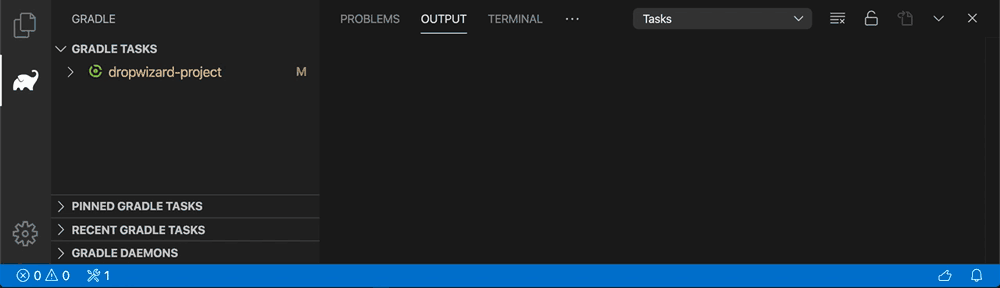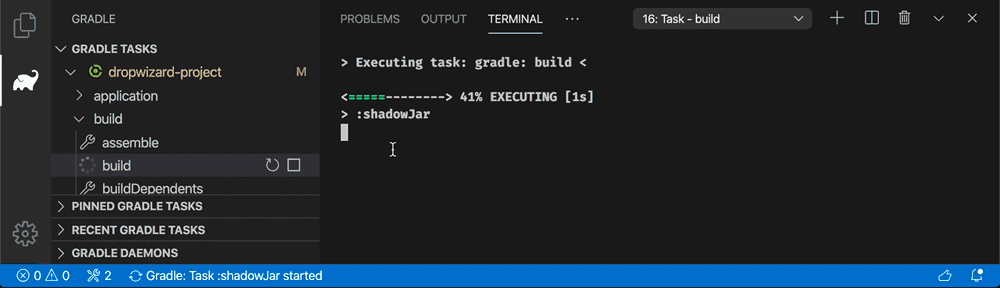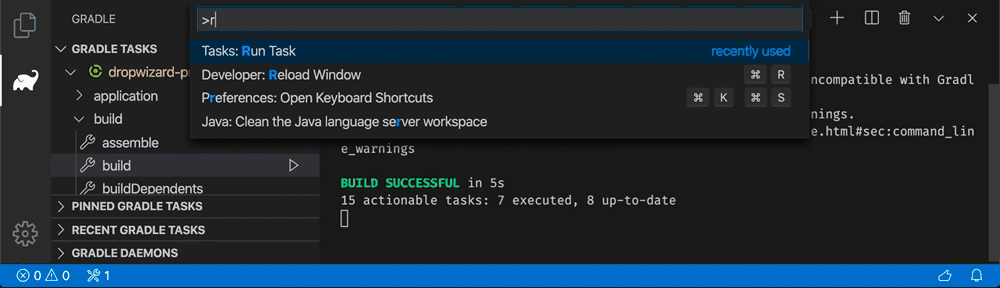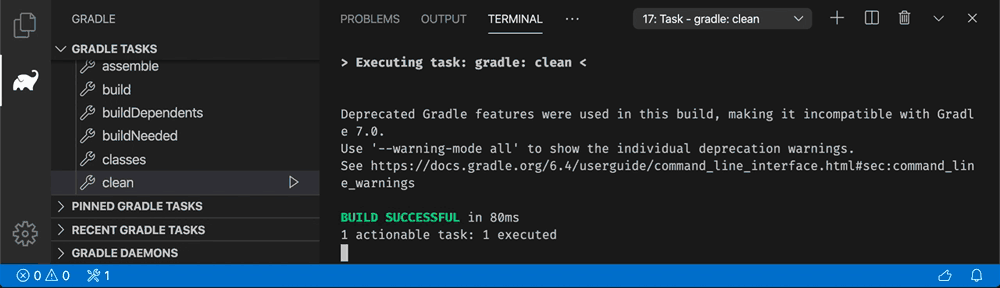
Icon Fonts
Snippets for popular icon fonts such as Font Awesome, Ionicons, Glyphicons, Octicons, Material Design Icons and many more!
Import Cost
This extension will display inline in the editor the size of the imported package. The extension utilizes webpack with babili-webpack-plugin in order to detect the imported size.
Jira and Bitbucket
Bringing the power of Jira and Bitbucket to VS Code — With Atlassian for VS Code you can create and view issues, start work on issues, create pull requests, do code reviews, start builds, get build statuses and more!
JS Parameter Annotations
Provides annotations on function calls in JS/TS files to provide parameter names to arguments.
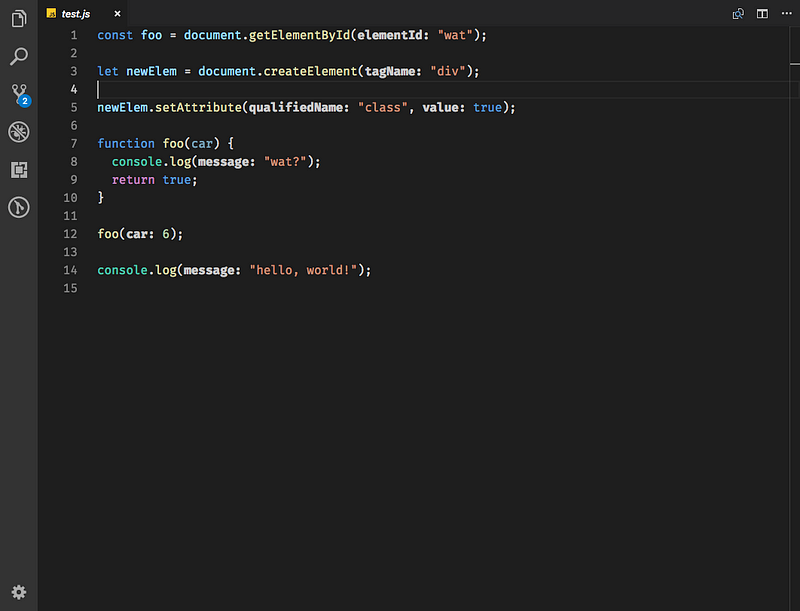
Jumpy
Provides fast cursor movement, inspired by Atom’s package of the same name.
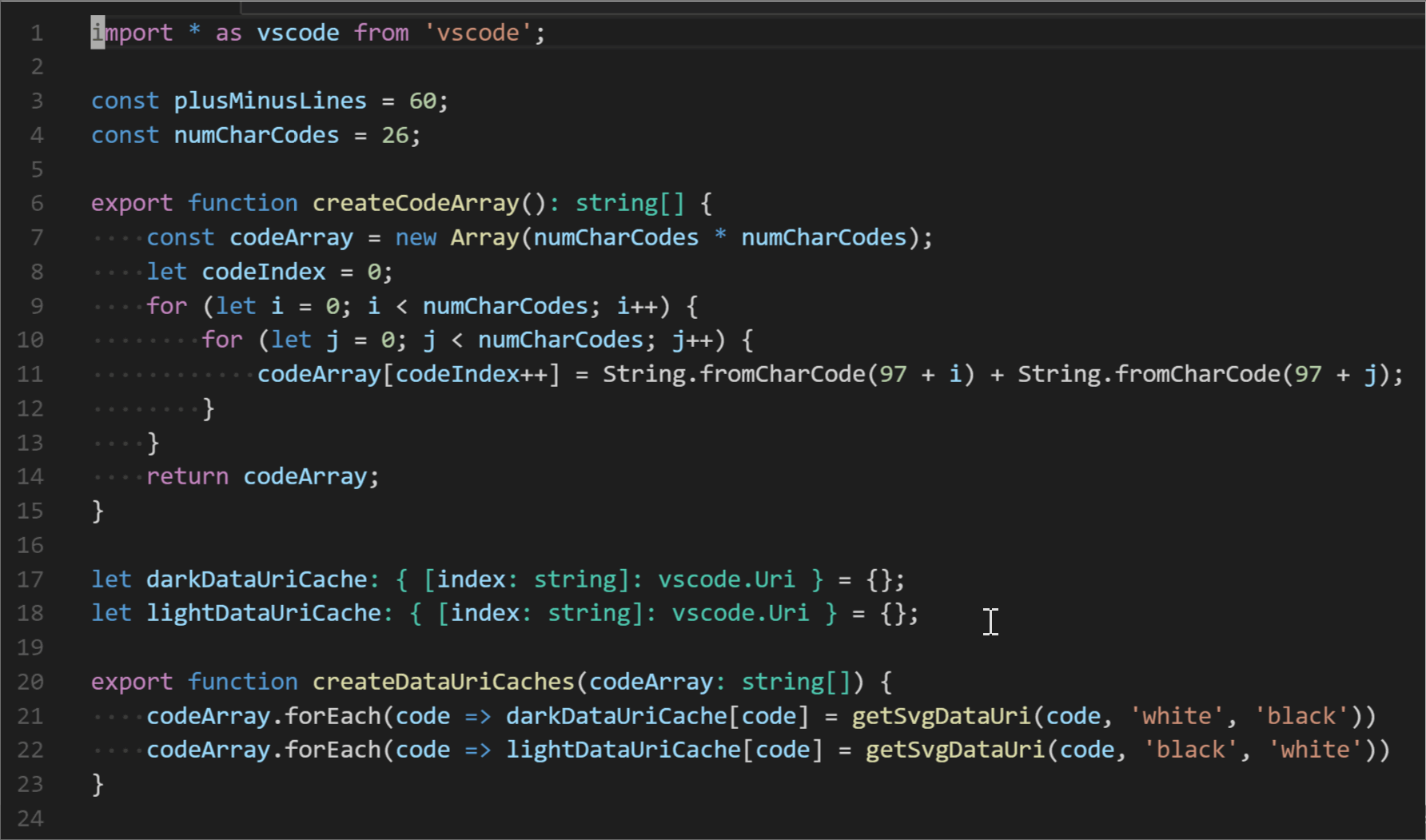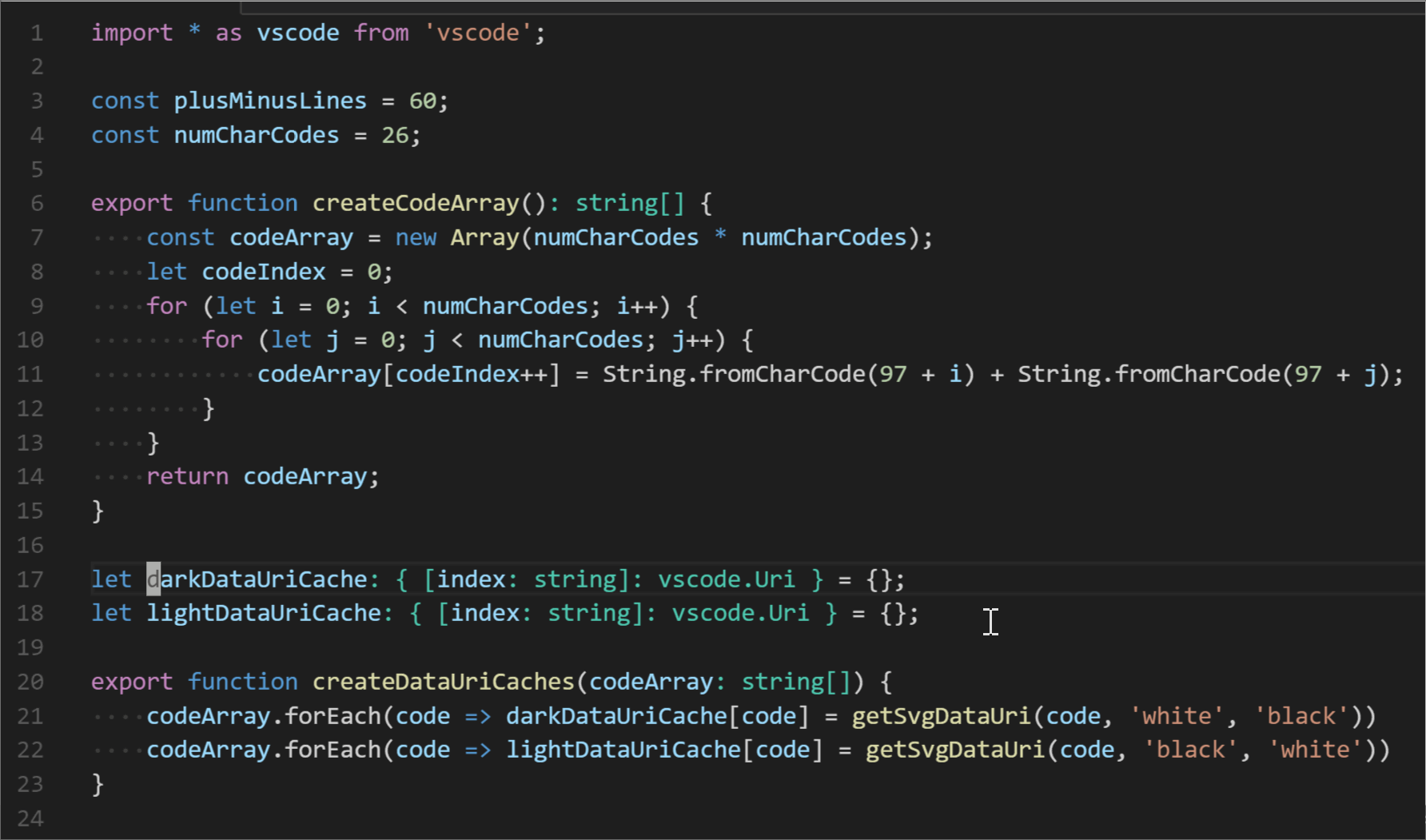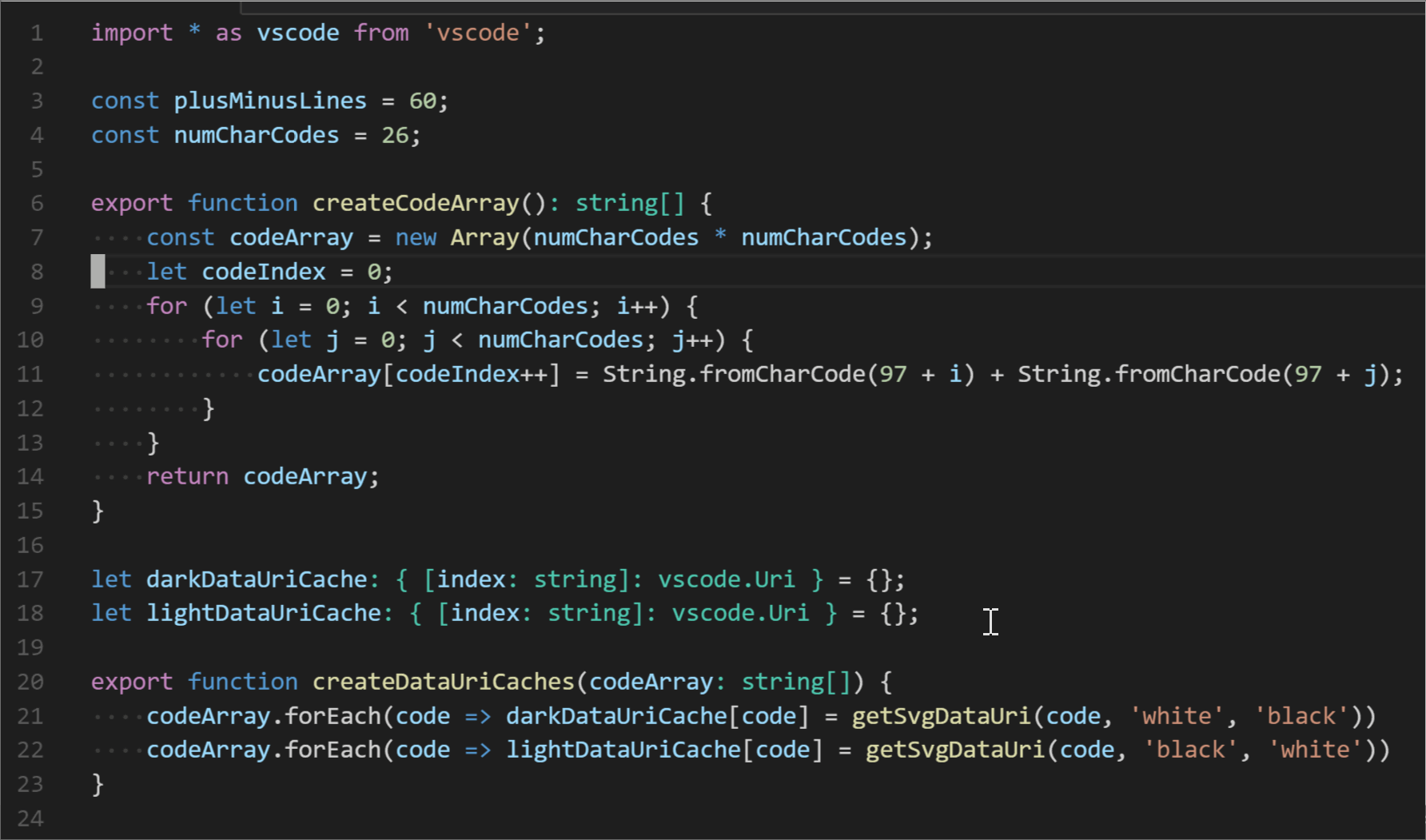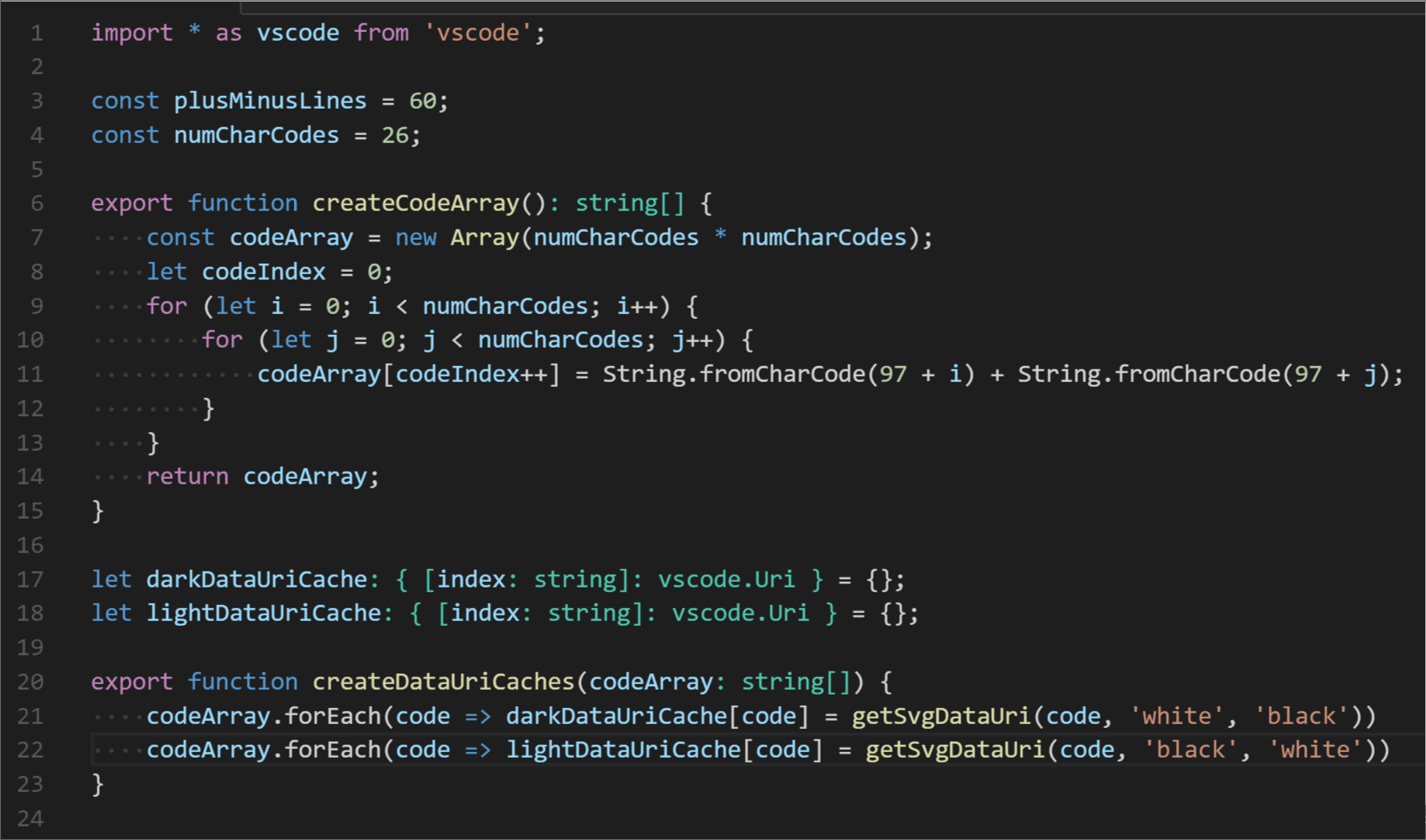
Kanban
Simple Kanban board for use in Visual Studio Code, with time tracking and Markdown support.
Live Server
Launch a development local Server with live reload feature for static & dynamic pages.
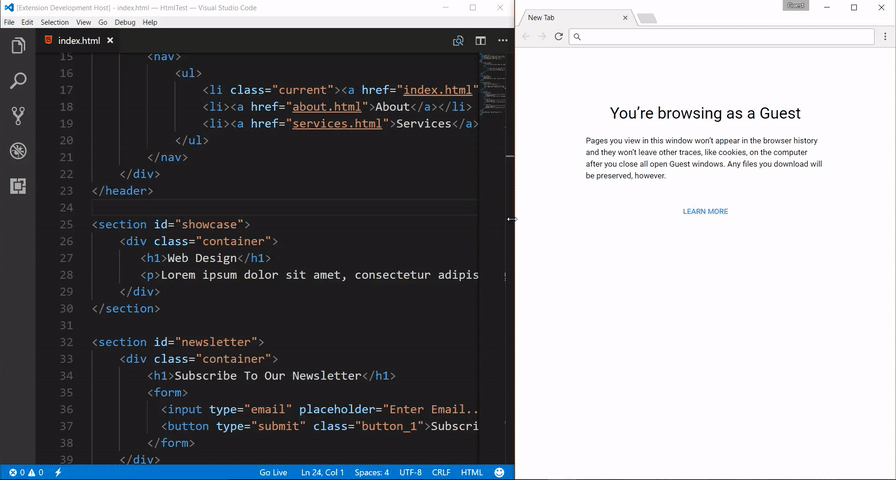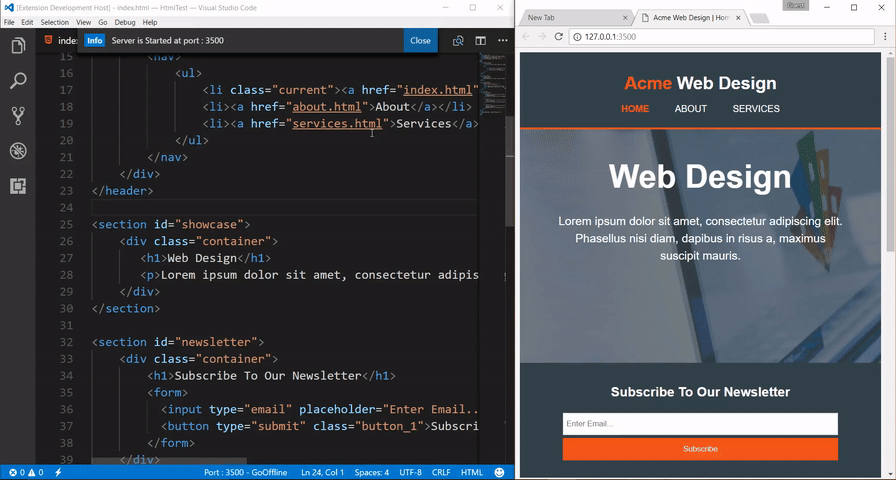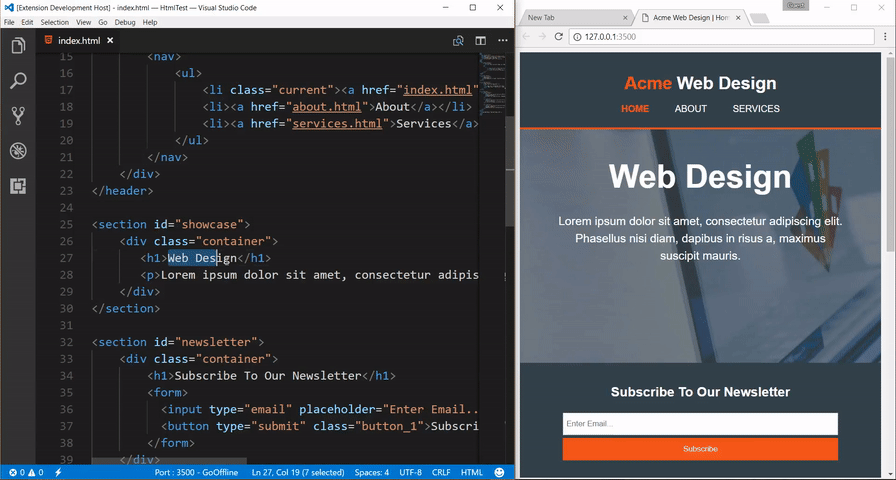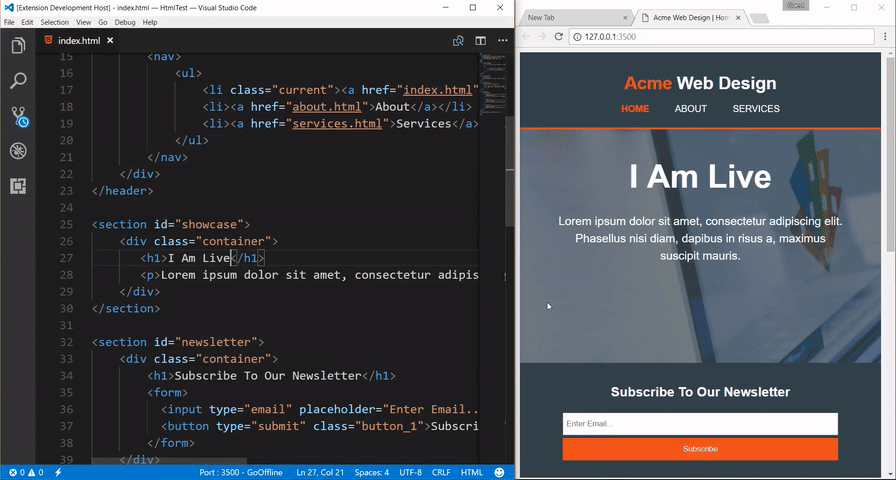
Multiple clipboards
Override the regular Copy and Cut commands to keep selections in a clipboard ring
ngrok for VSCode
ngrok allows you to expose a web server running on your local machine to the internet. Just tell ngrok what port your web server is listening on. This extension allows you to control ngrok from the VSCode command palette
Instant Markdown
Simply, edit markdown documents in vscode and instantly preview it in your browser as you type.
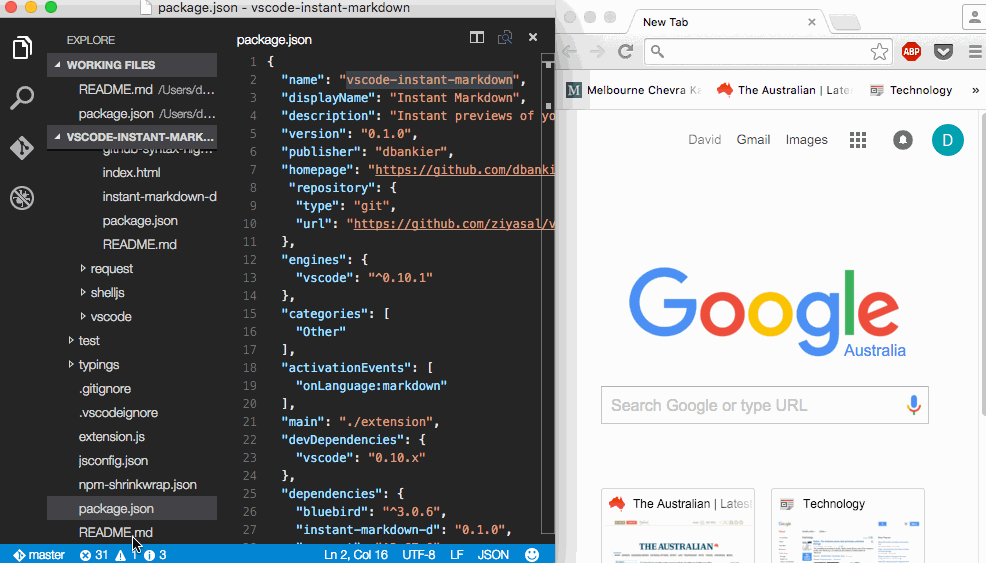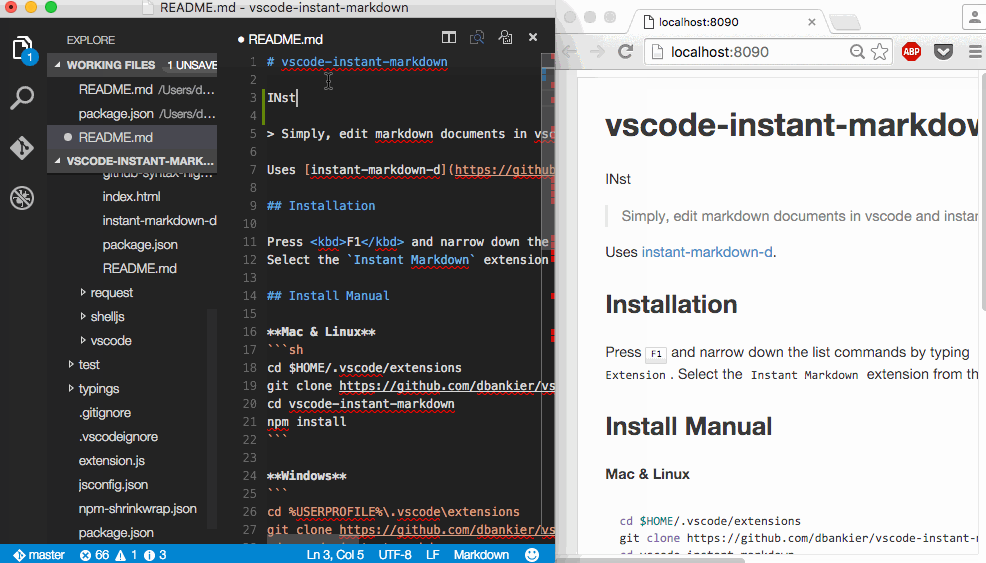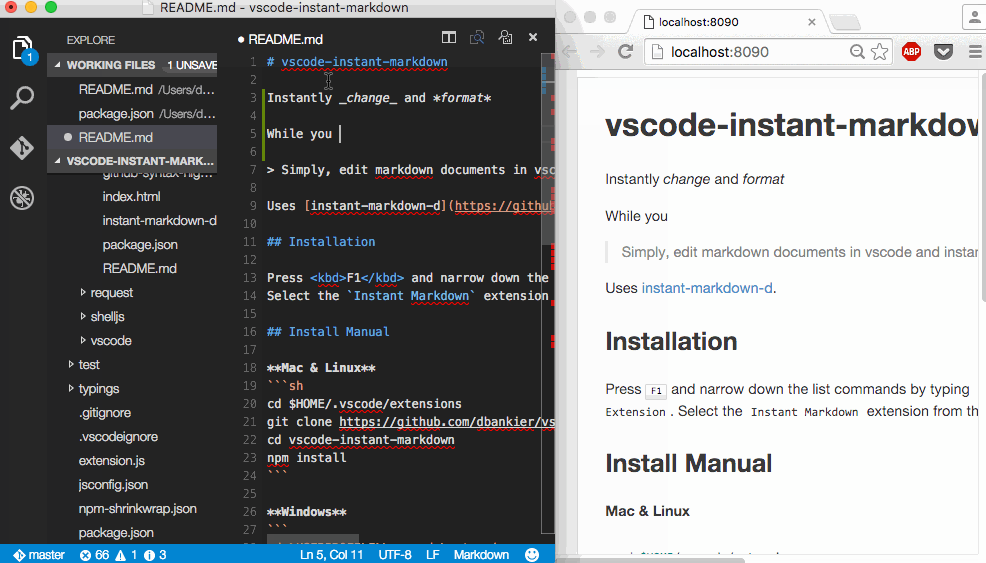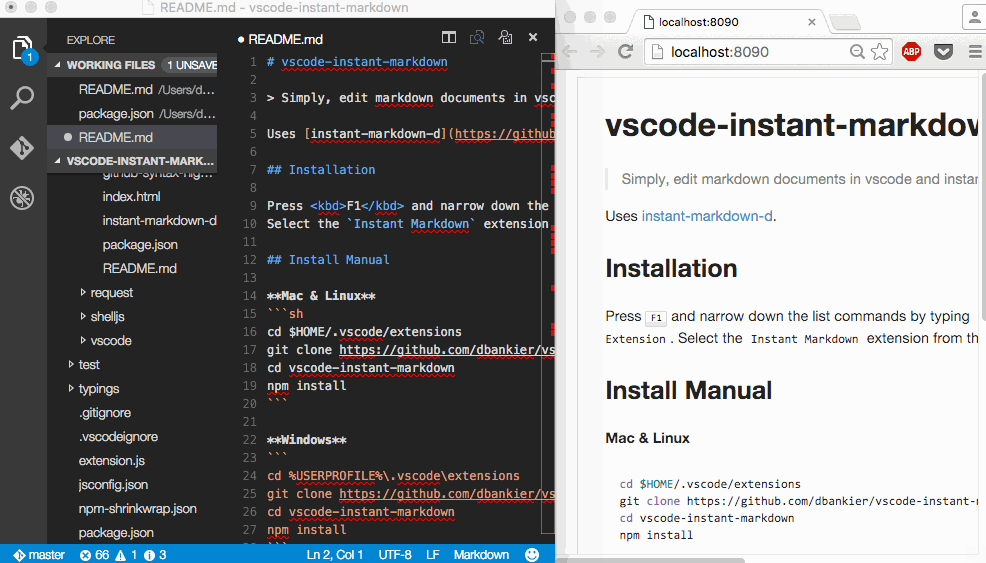
npm Intellisense
Visual Studio Code plugin that autocompletes npm modules in import statements.
Parameter Hints
Provides parameter hints on function calls in JS/TS/PHP files.
Partial Diff
Compare (diff) text selections within a file, across different files, or to the clipboard
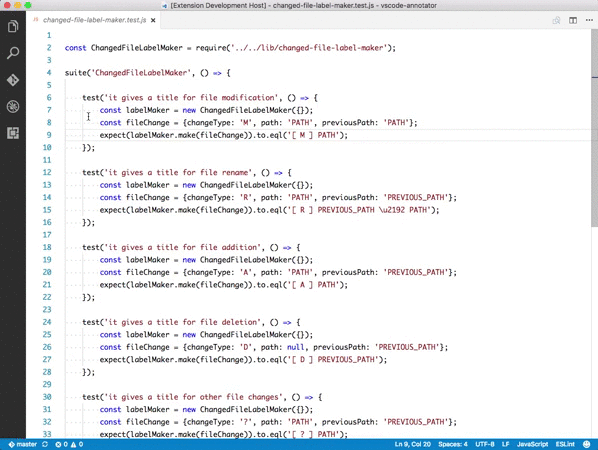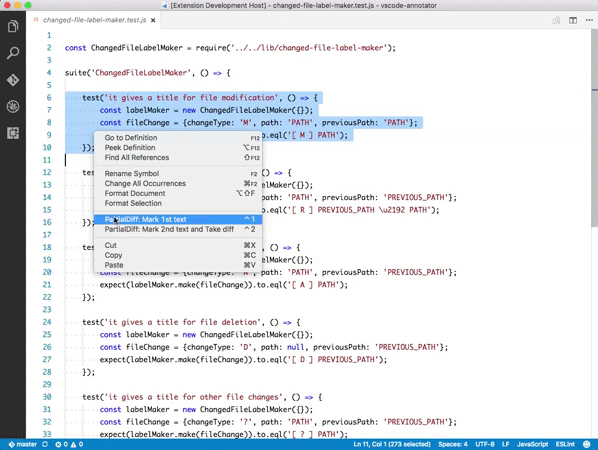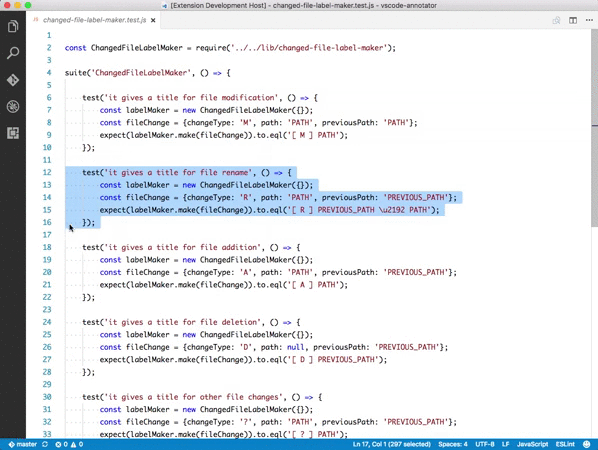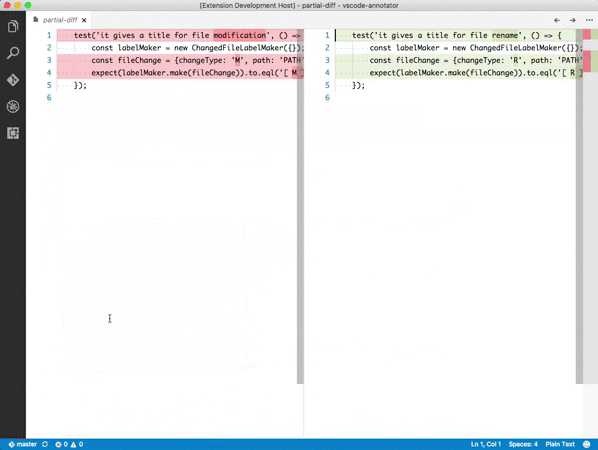
Paste JSON as Code
Infer the structure of JSON and paste is as types in many programming languages
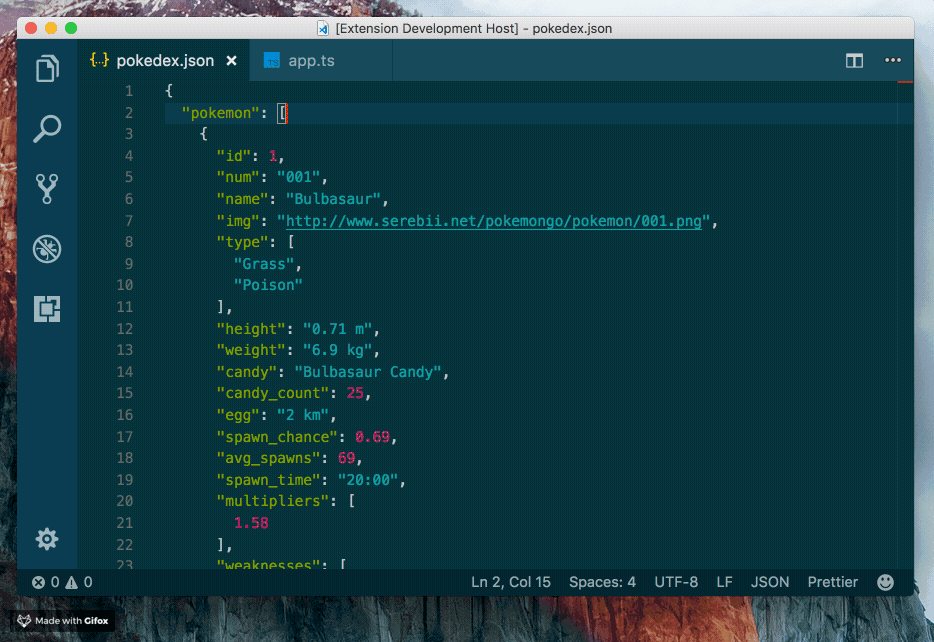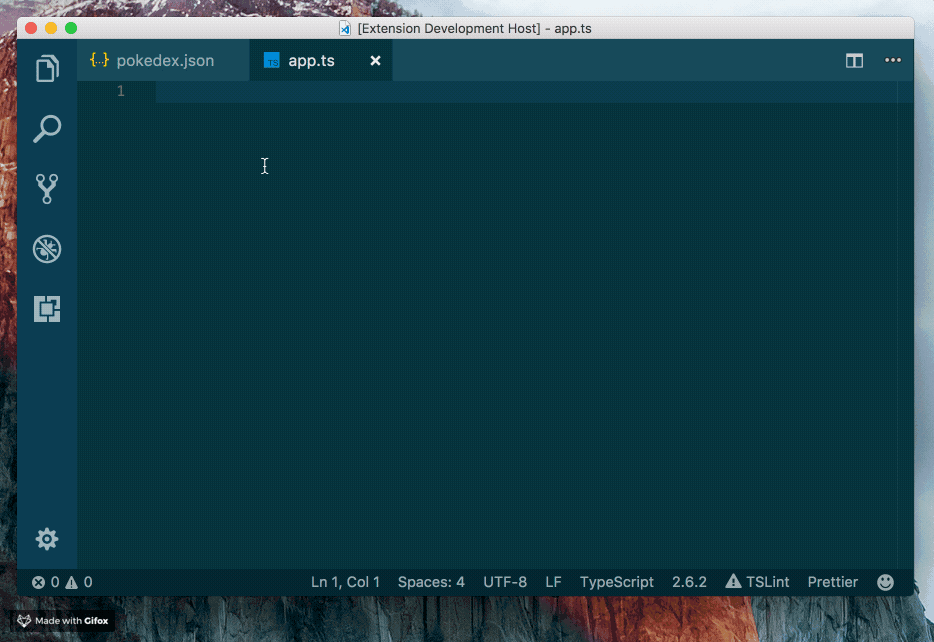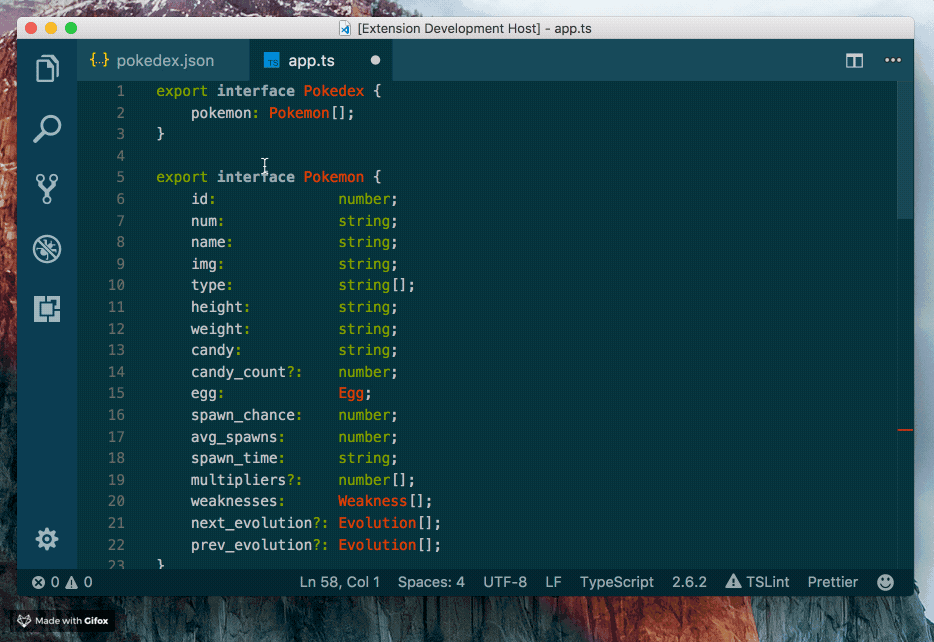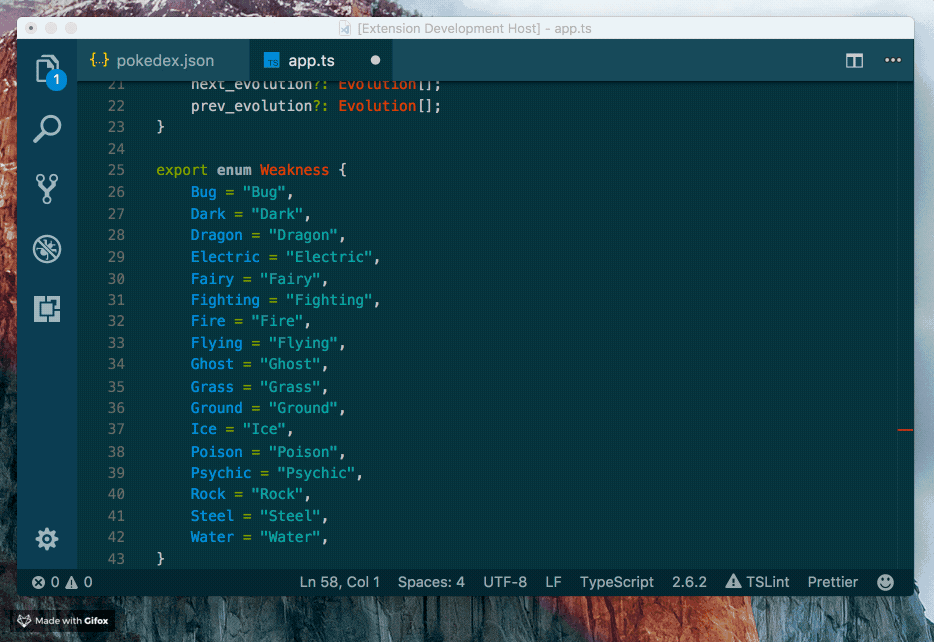
Path IntelliSense
Visual Studio Code plugin that autocompletes filenames
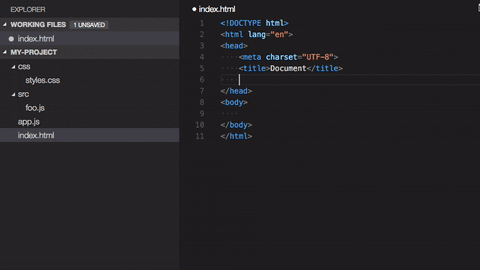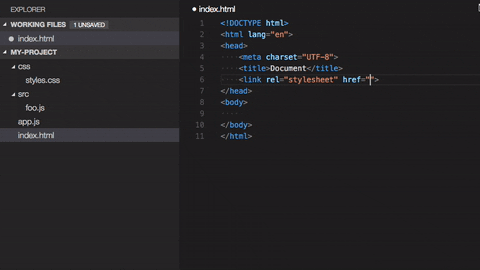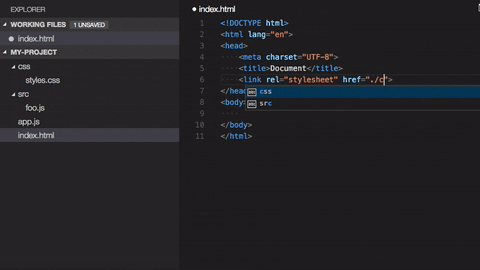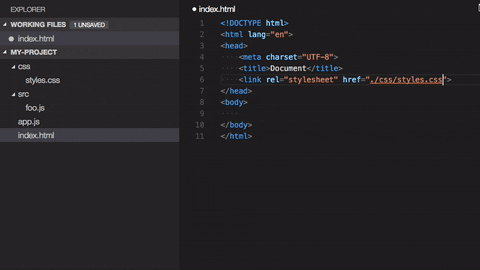
Power Tools
Extends Visual Studio Code via things like Node.js based scripts or shell commands, without writing separate extensions
PrintCode
PrintCode converts the code being edited into an HTML file, displays it by browser and prints it.
Project Manager
Easily switch between projects.
Project Dashboard
VSCode Project Dashboard is a Visual Studio Code extension that lets you organize your projects in a speed-dial like manner. Pin your frequently visited folders, files, and SSH remotes onto a dashboard to access them quickly.
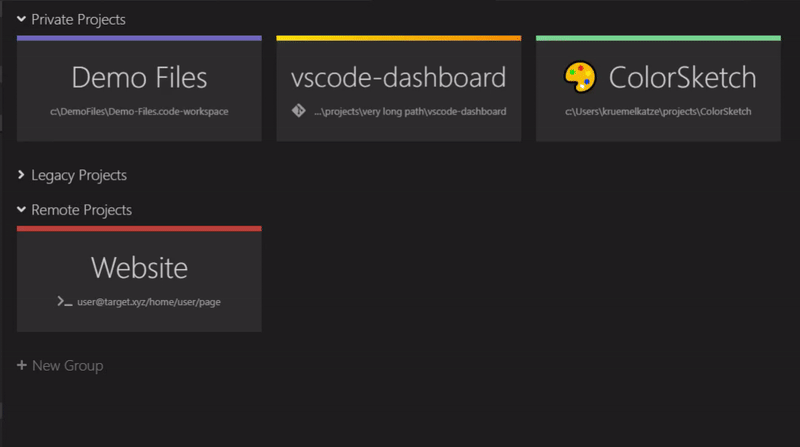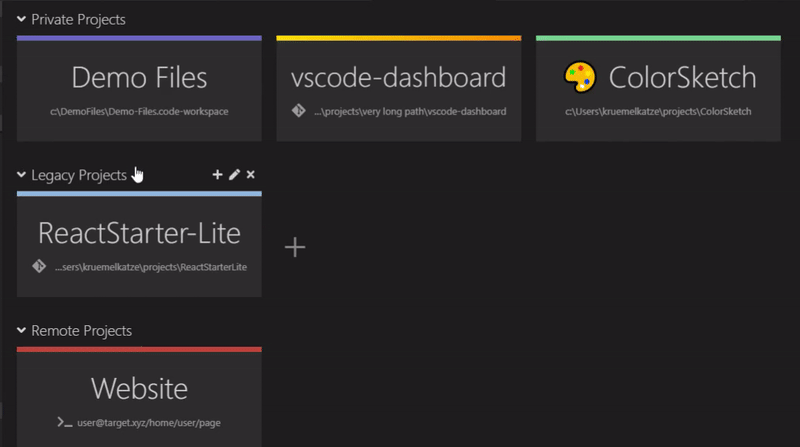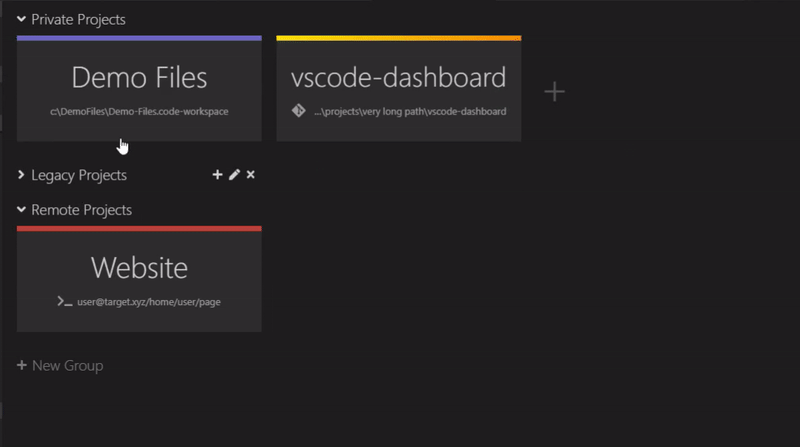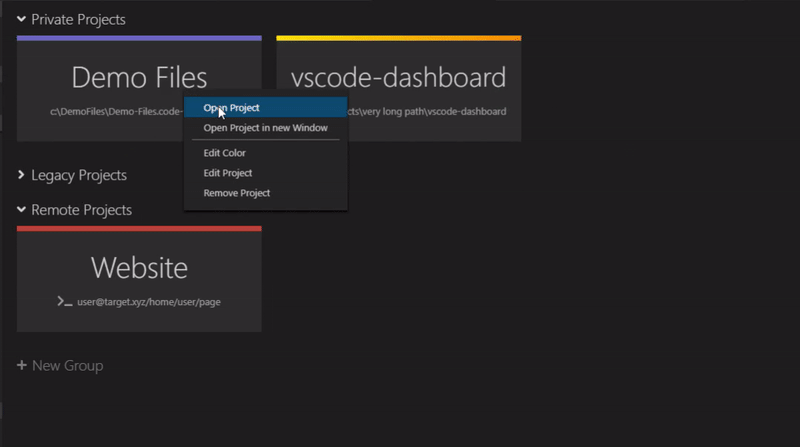
Rainbow CSV
Highlight columns in comma, tab, semicolon and pipe separated files, consistency check and linting with CSVLint, multi-cursor column editing, column trimming and realignment, and SQL-style querying with RBQL.
Remote Development
Allows users to open any folder in a container, on a remote machine, container or in Windows Subsystem for Linux(WSL) and take advantage of VS Code’s full feature set.
Remote VSCode
Allow user to edit files from Remote server in Visual Studio Code directly.
REST Client
Allows you to send HTTP request and view the response in Visual Studio Code directly.
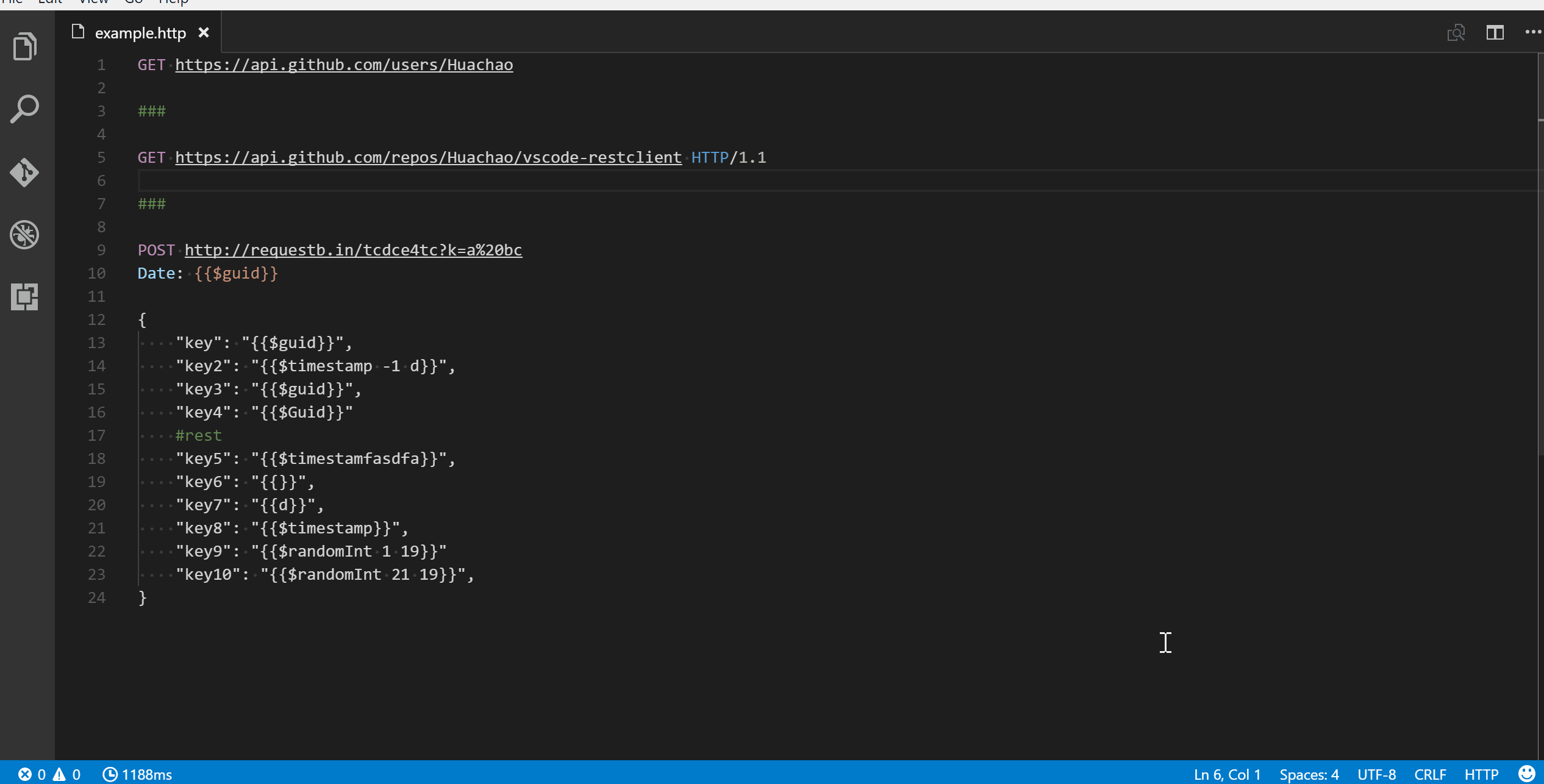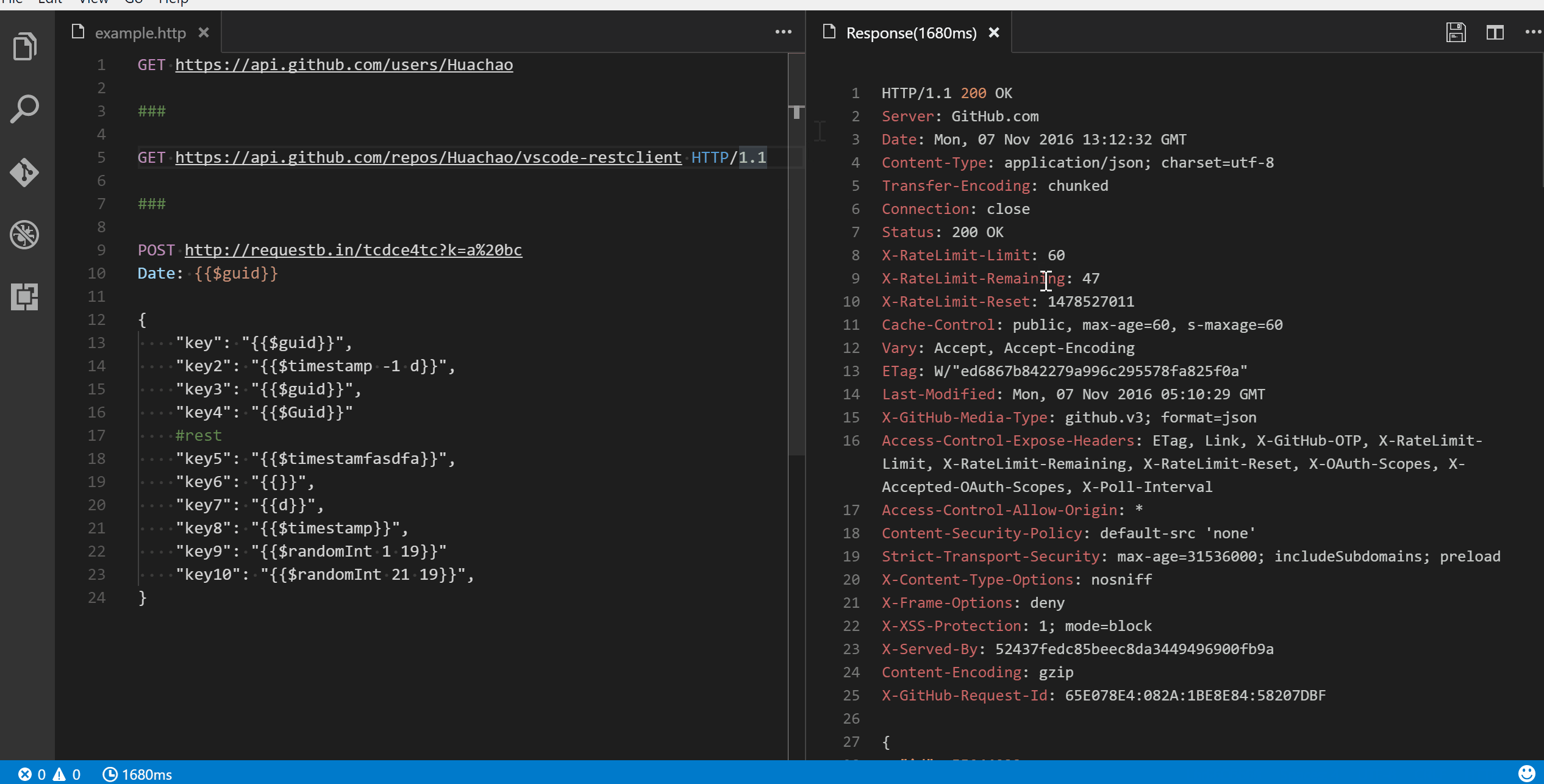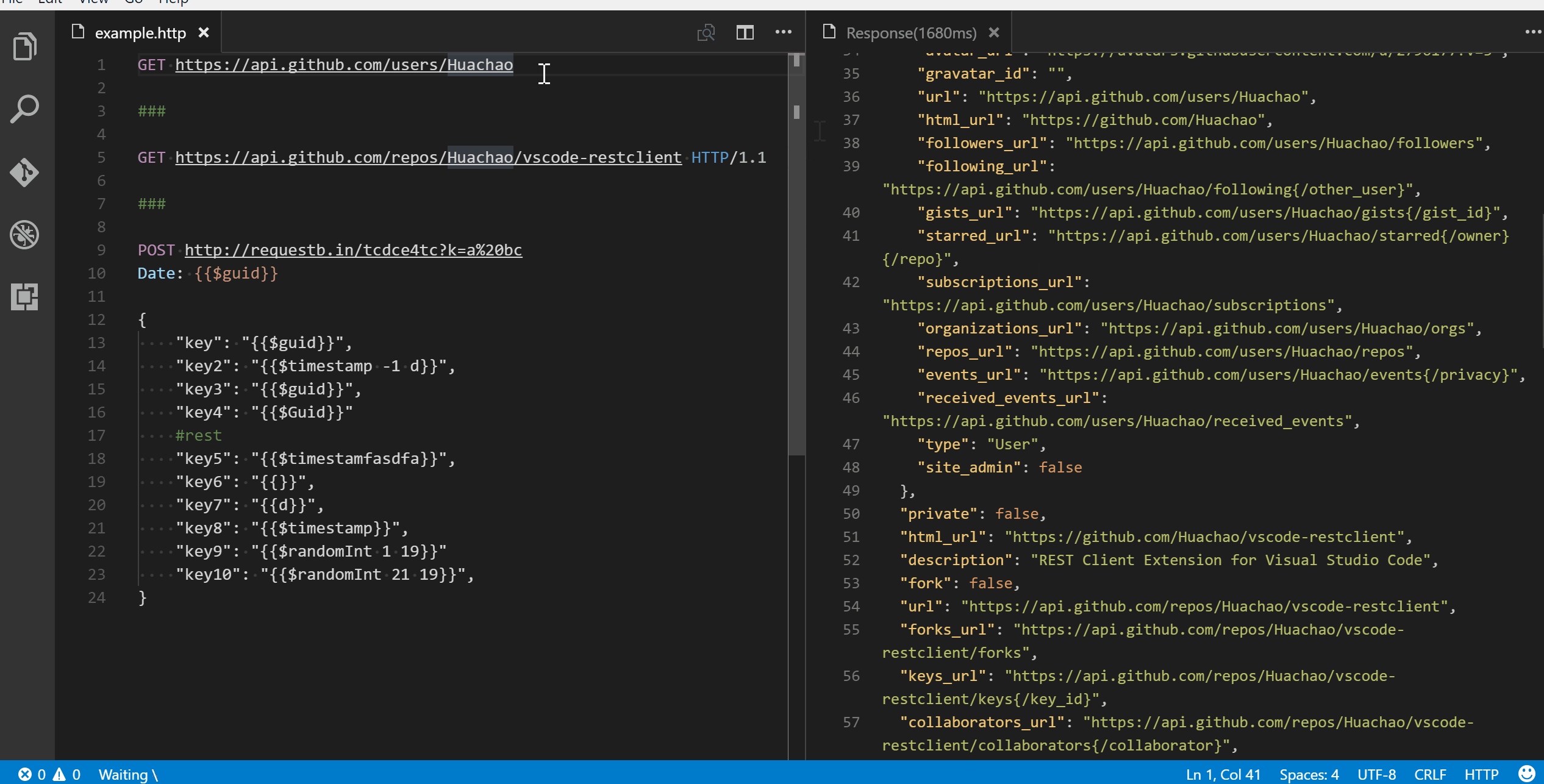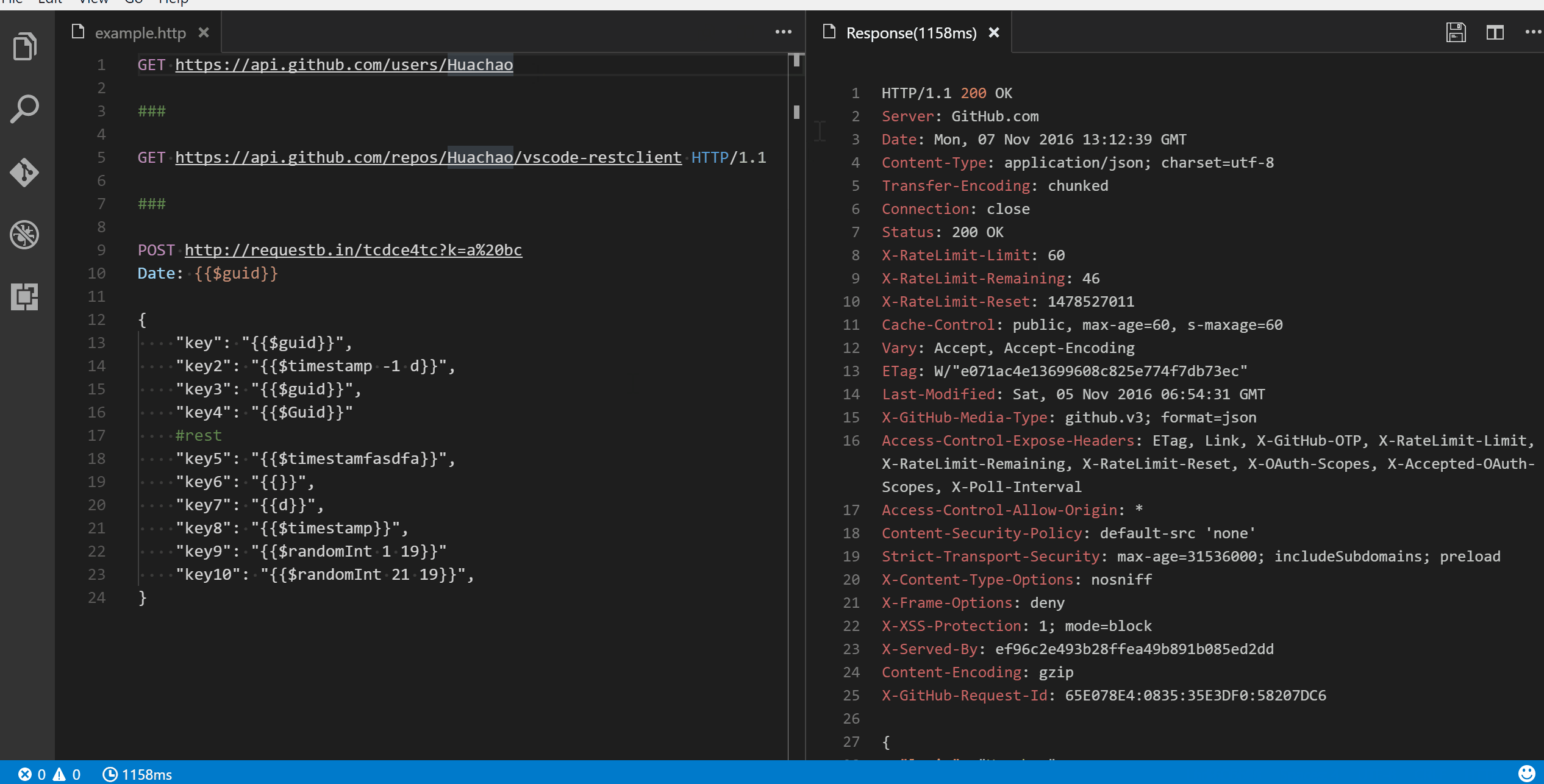
Settings Sync
Synchronize settings, snippets, themes, file icons, launch, key bindings, workspaces and extensions across multiple machines using GitHub Gist
Text Power Tools
All-in-one extension for text manipulation: filtering (grep), remove lines, insert number sequences and GUIDs, format content as table, change case, converting numbers and more. Great for finding information in logs and manipulating text.
Todo Tree
Custom keywords, highlighting, and colors for TODO comments. As well as a sidebar to view all your current tags.
Toggle Quotes
Cycle between single, double and backtick quotes

Typescript Destructure
TypeScript Language Service Plugin providing a set of source actions for easy objects destructuring
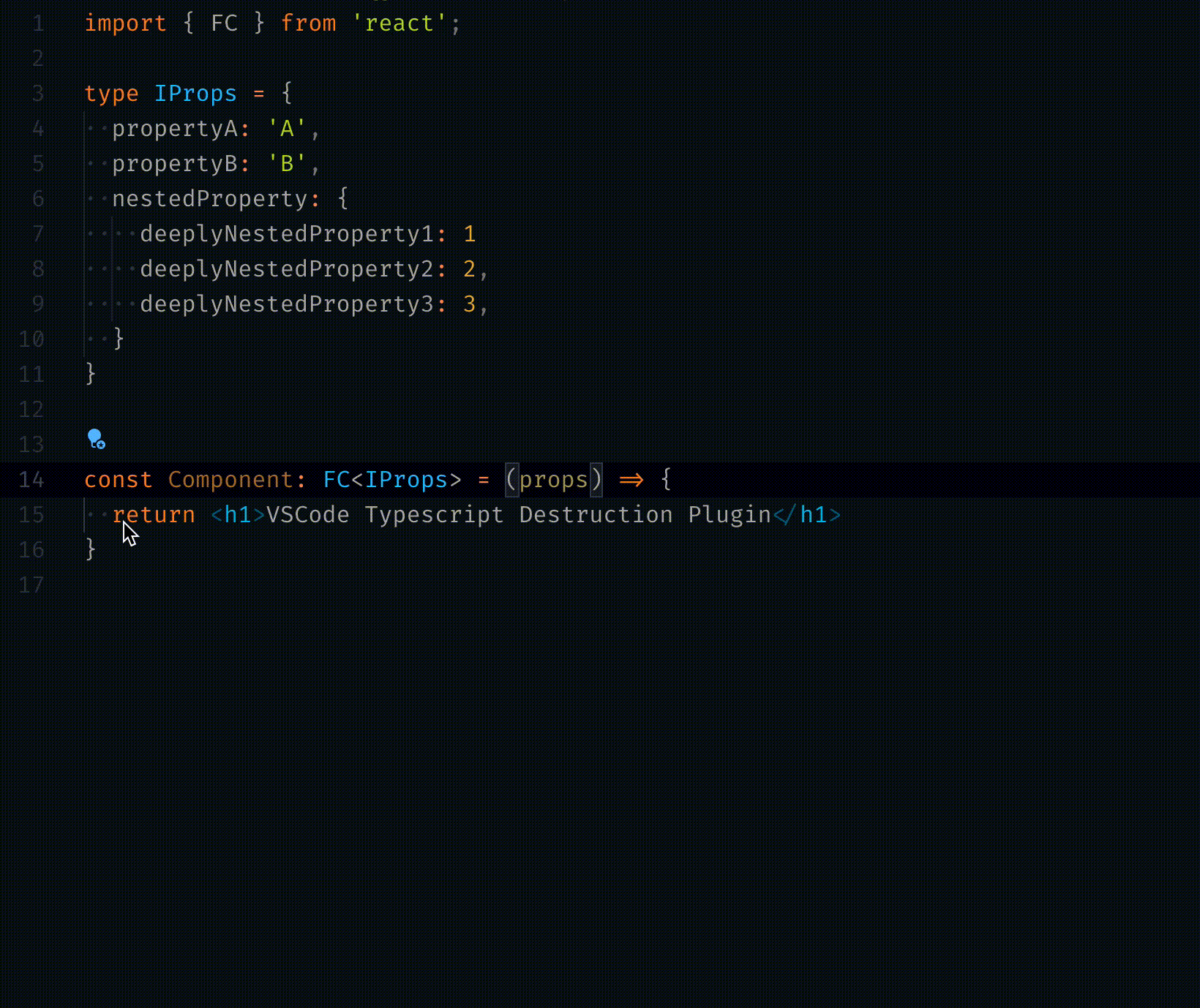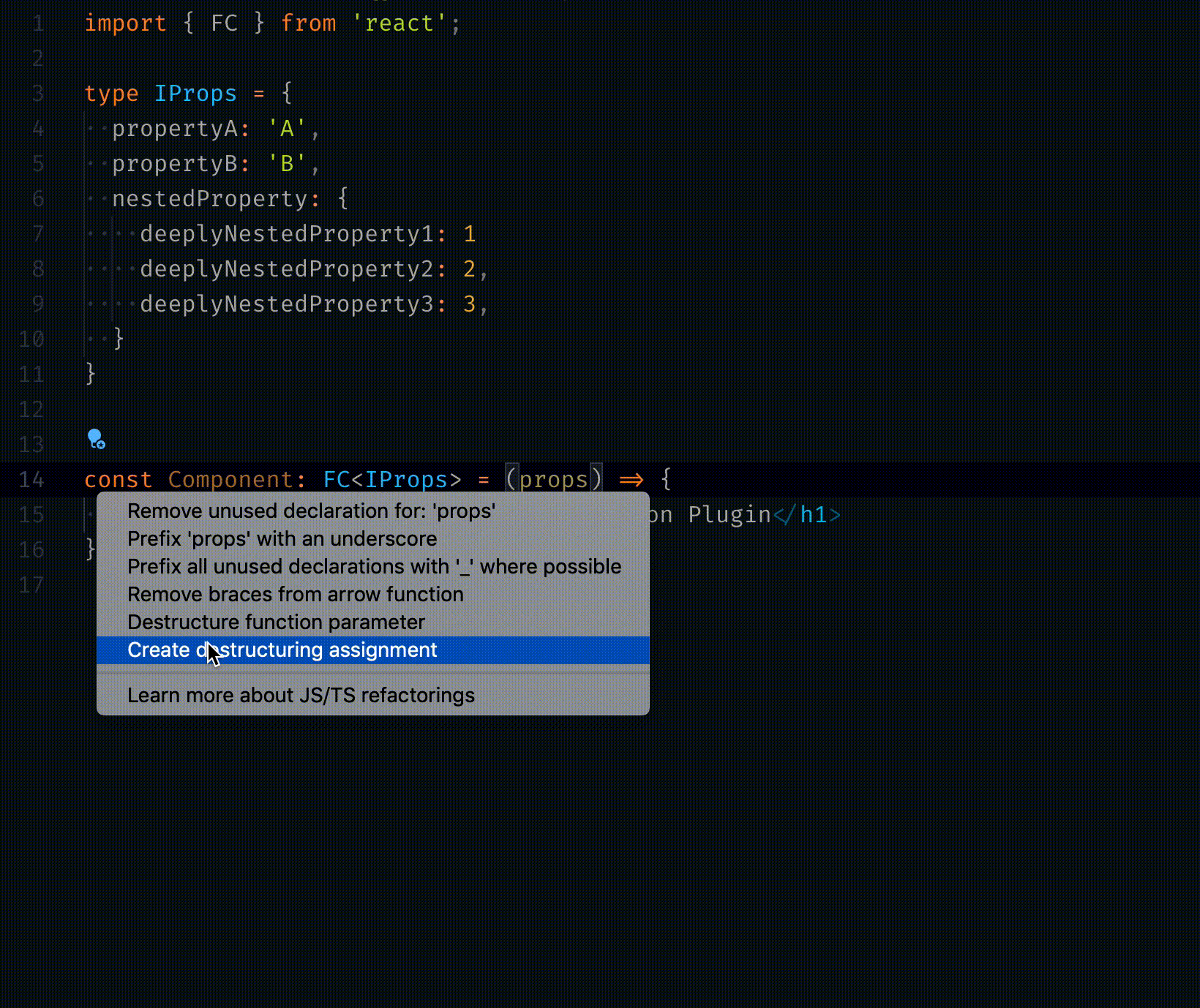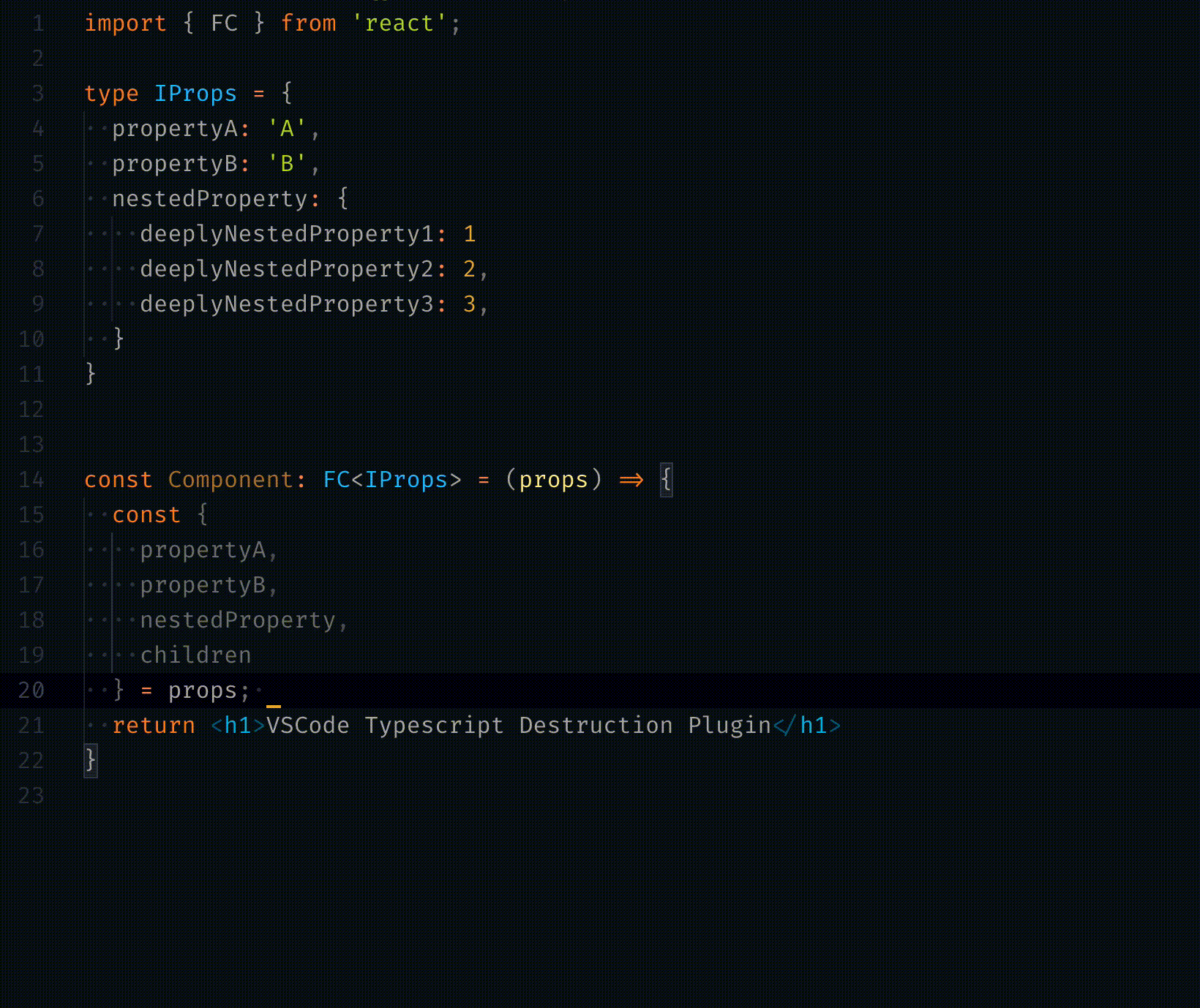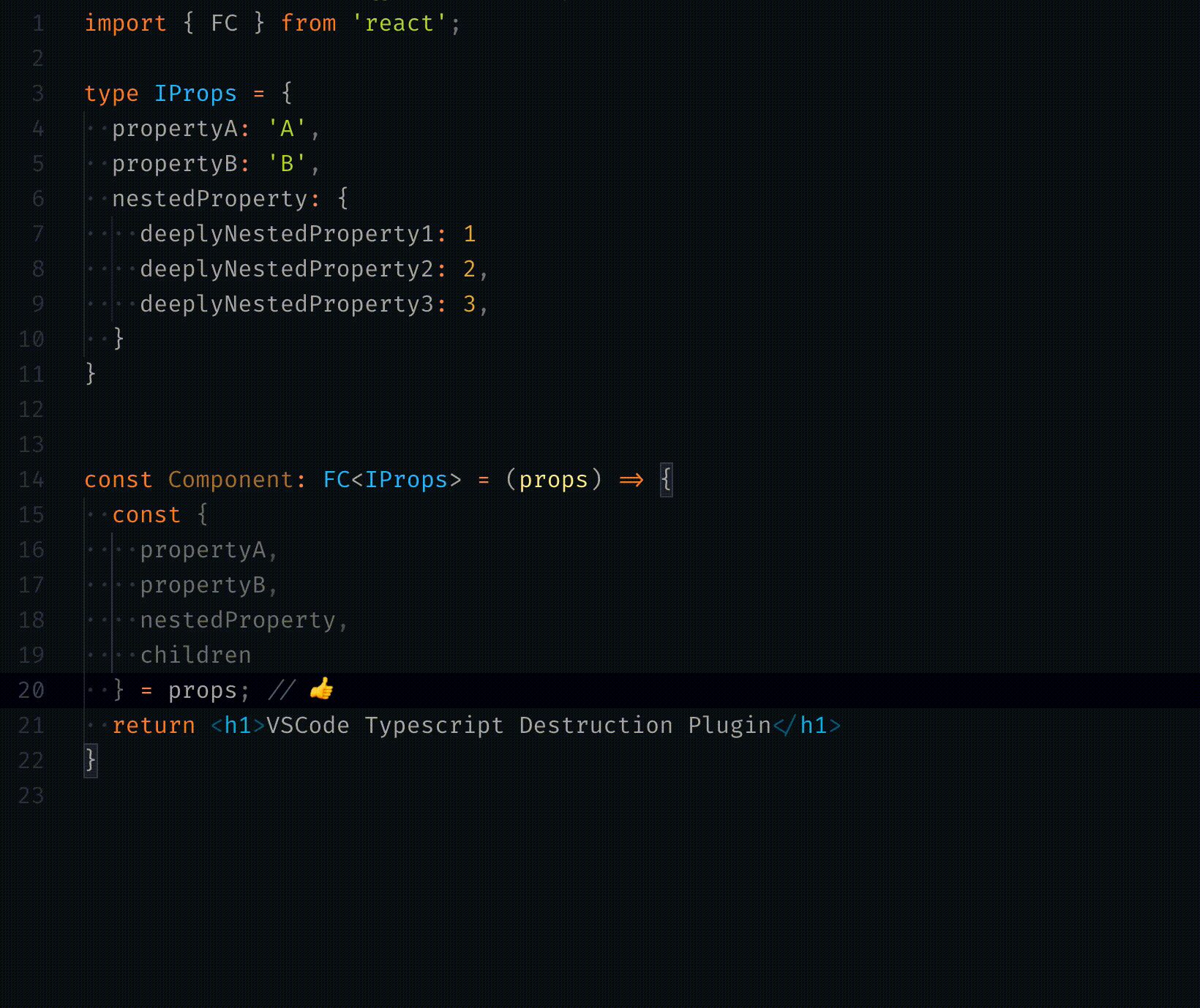
WakaTime
Automatic time tracker and productivity dashboard showing how long you coded in each project, file, branch, and language.
Formatting & Beautification
Better Align
Align your code by colon(:), assignment(=,+=,-=,*=,/=) and arrow(=>). It has additional support for comma-first coding style and trailing comment.
And it doesn’t require you to select what to be aligned, the extension will figure it out by itself.
Auto Close Tag
Automatically add HTML/XML close tag, same as Visual Studio IDE or Sublime Text
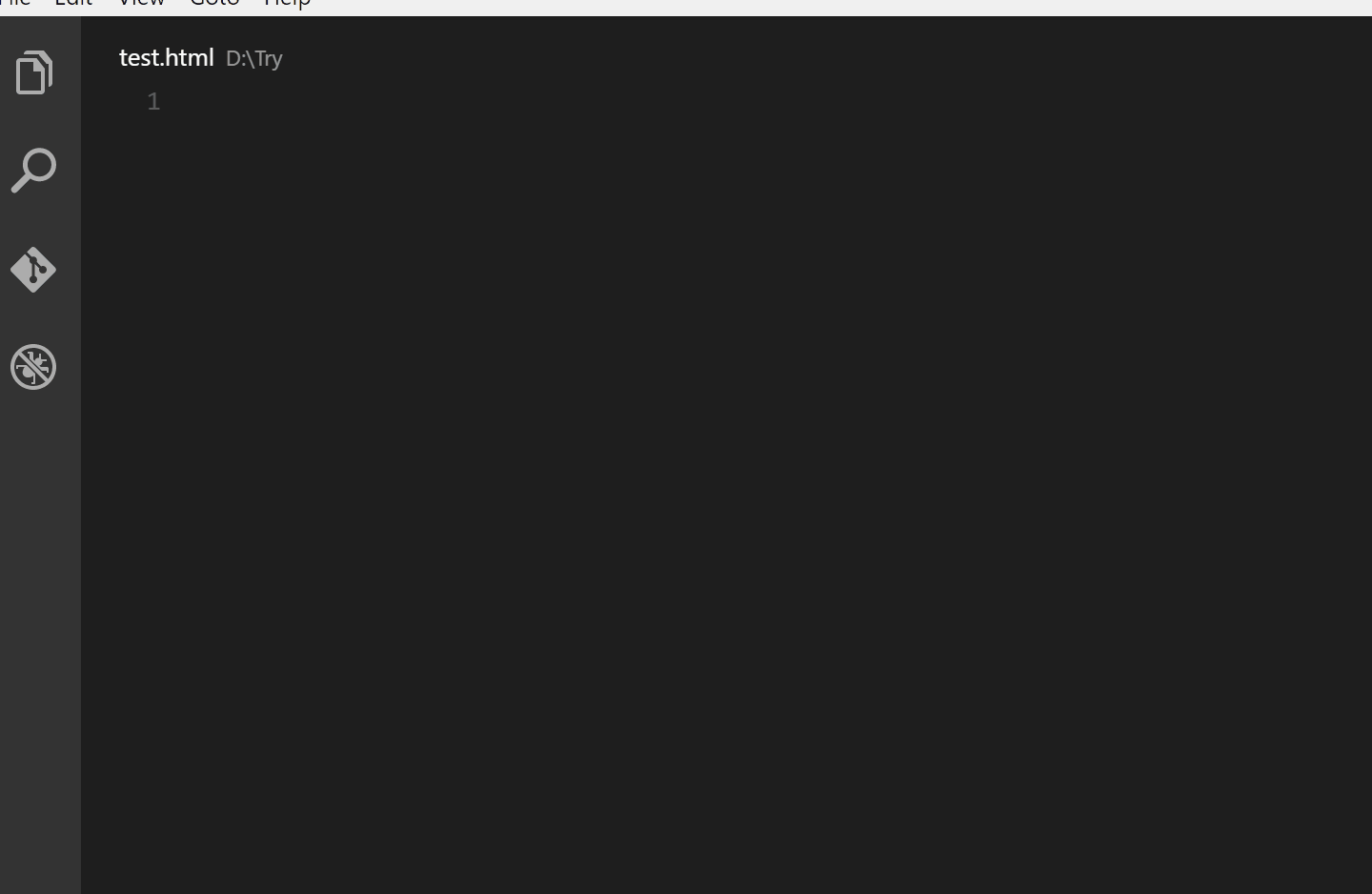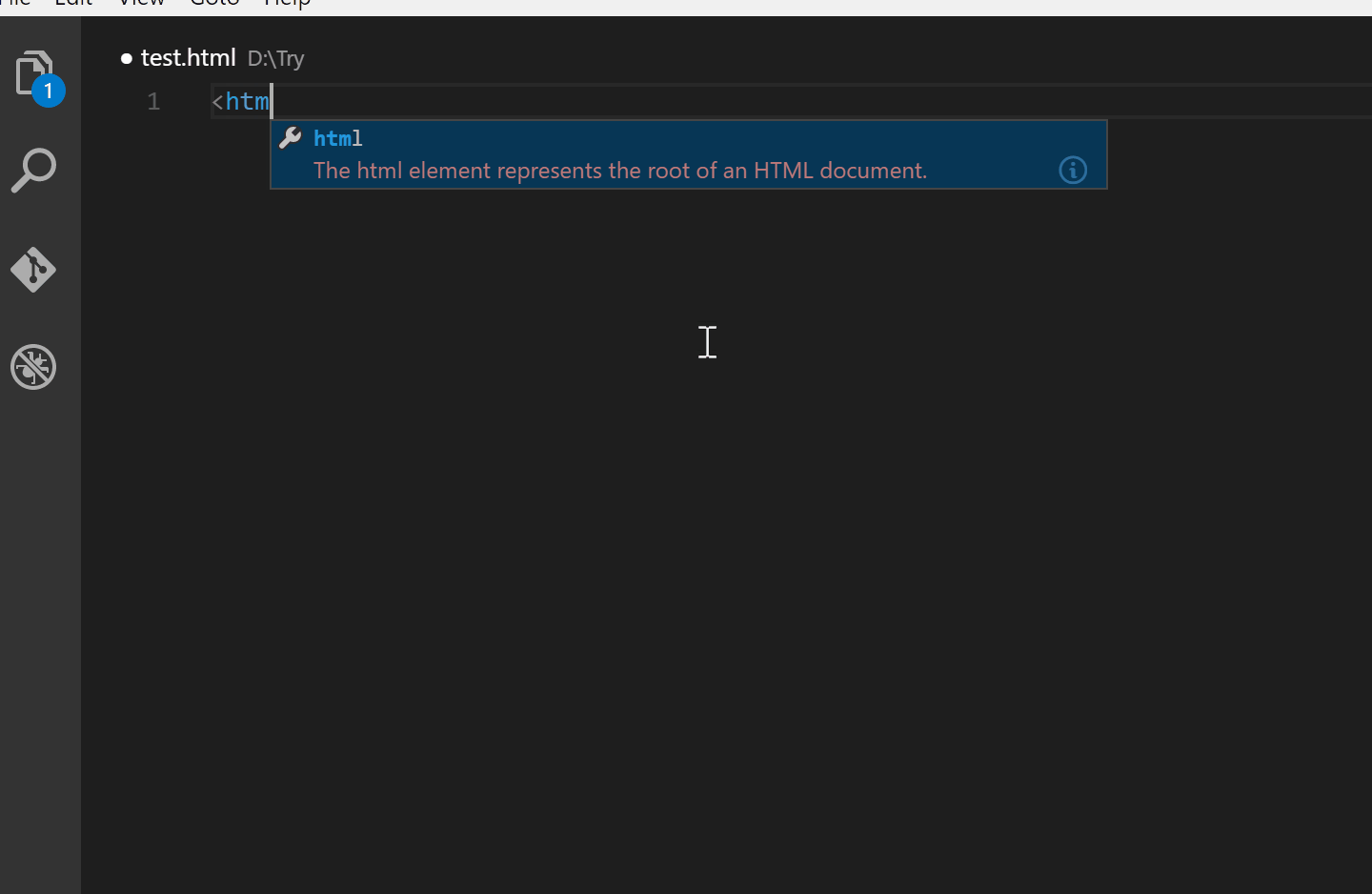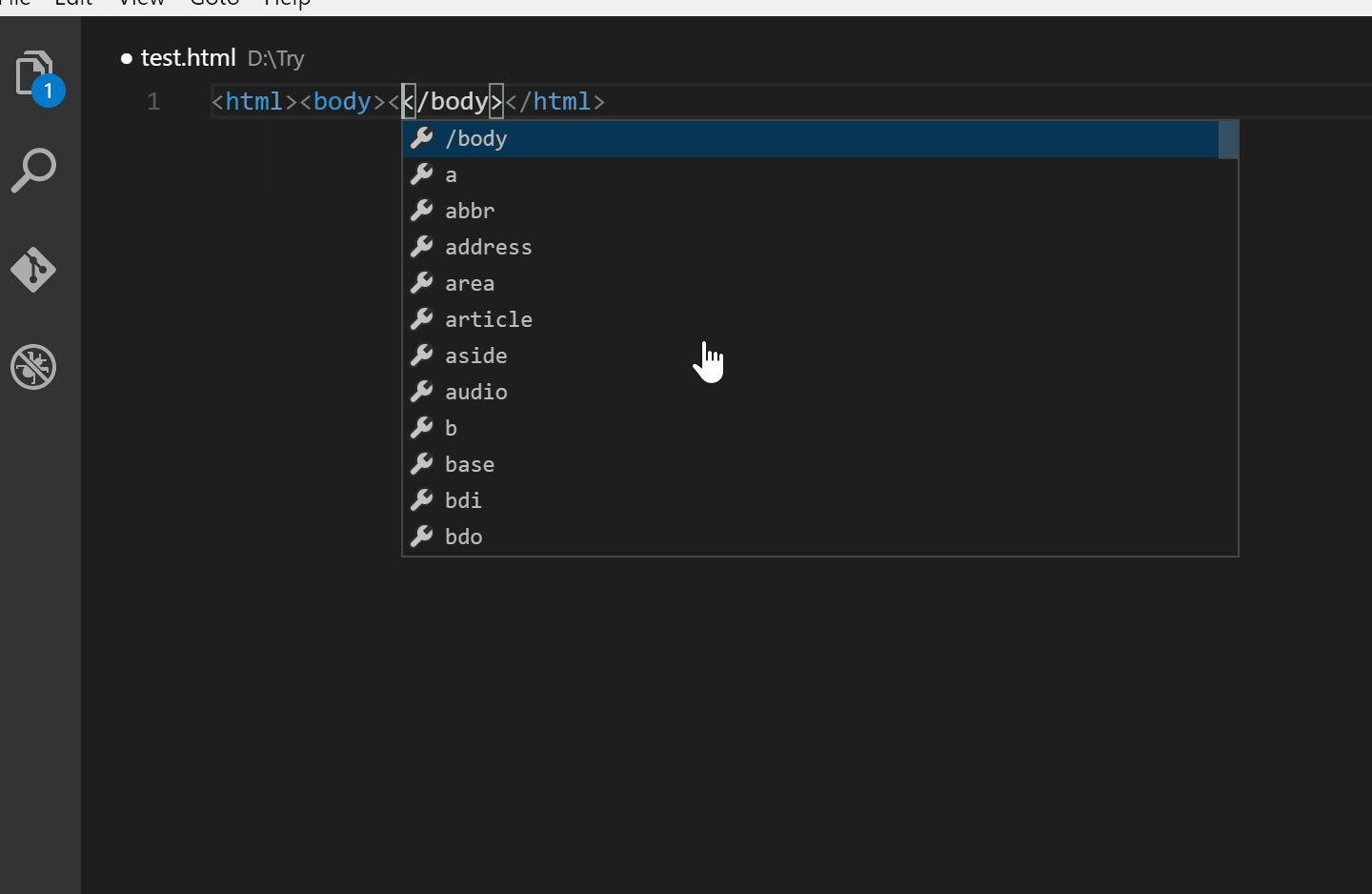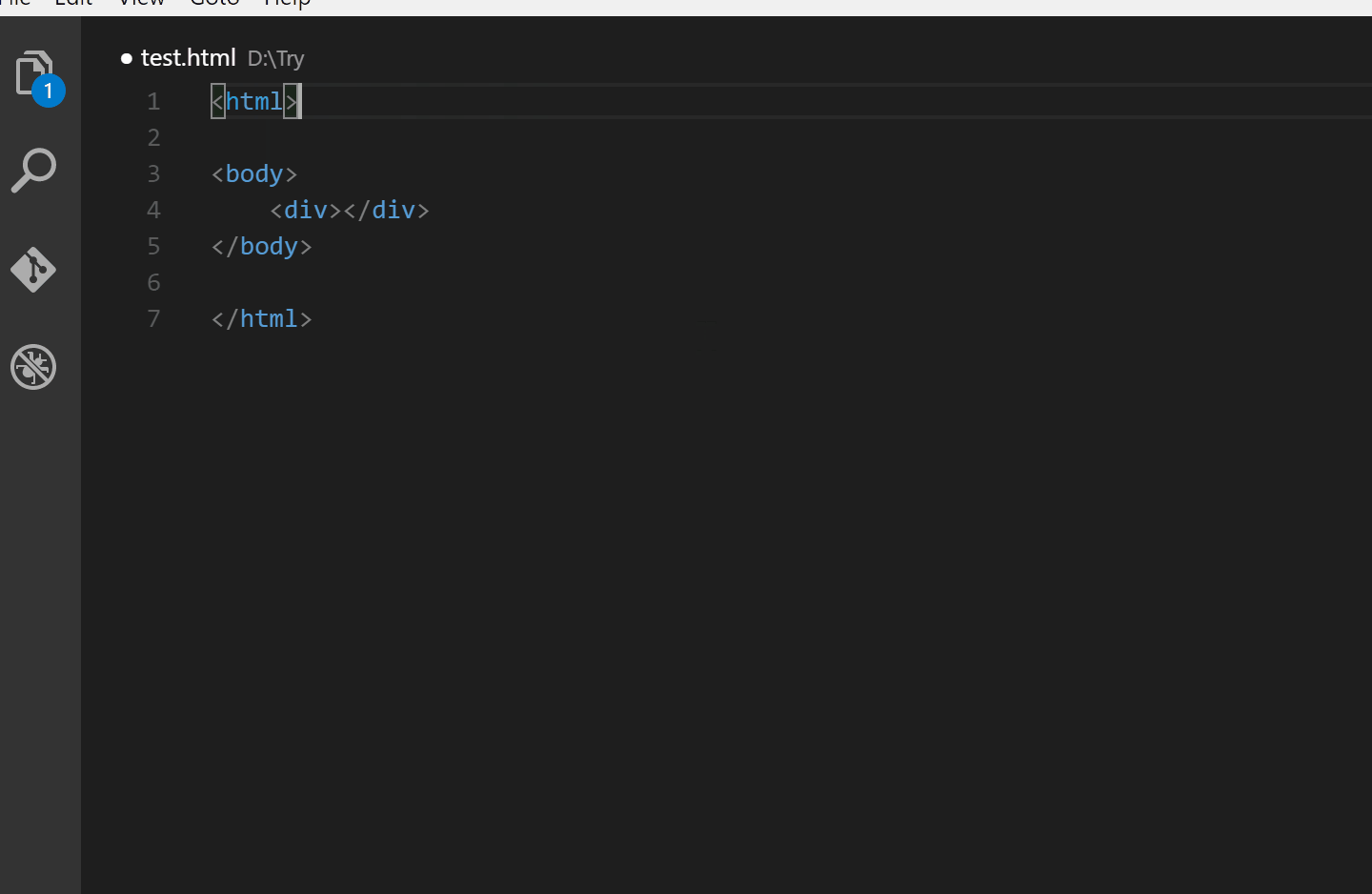
Auto Rename Tag
Auto rename paired HTML/XML tags
beautify
Beautify code in place for VS Code
html2pug
Transform html to pug inside your Visual Studio Code, forget about using an external page anymore.
ECMAScript Quotes Transformer
Transform quotes of ECMAScript string literals
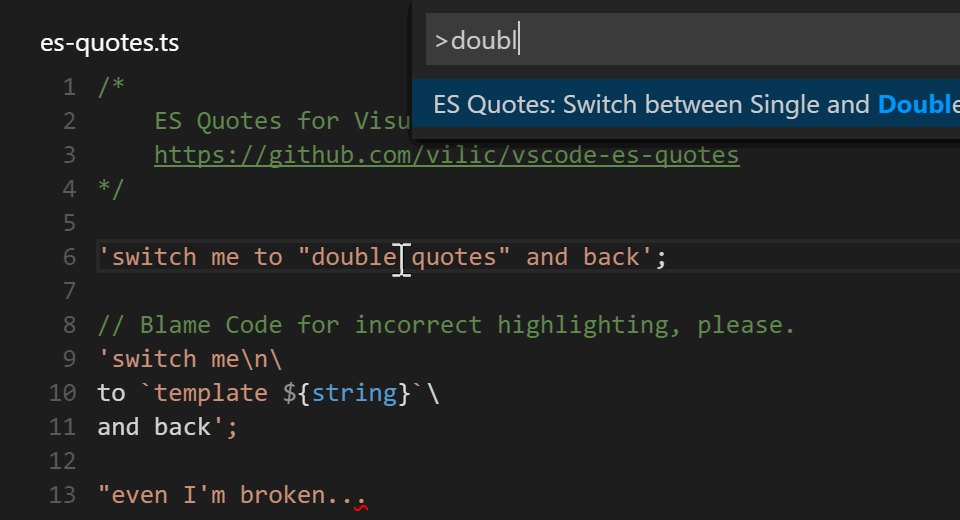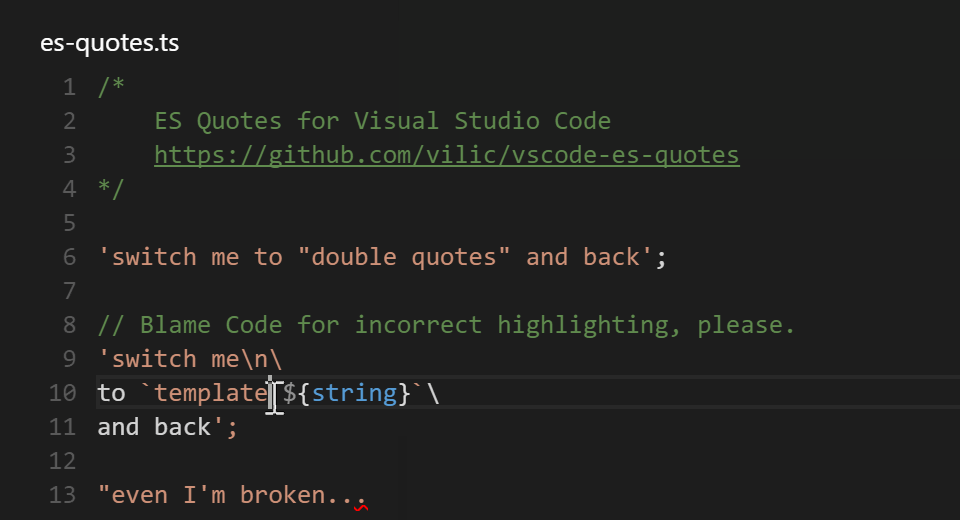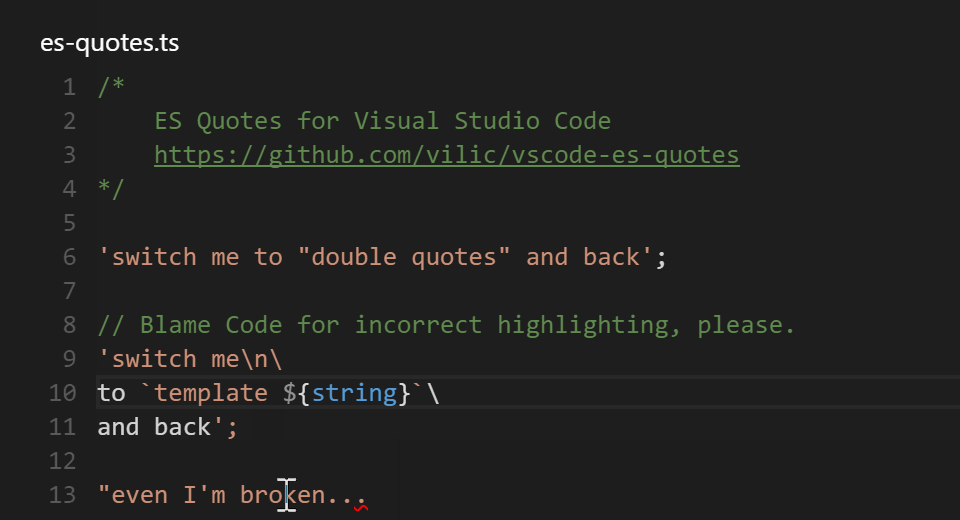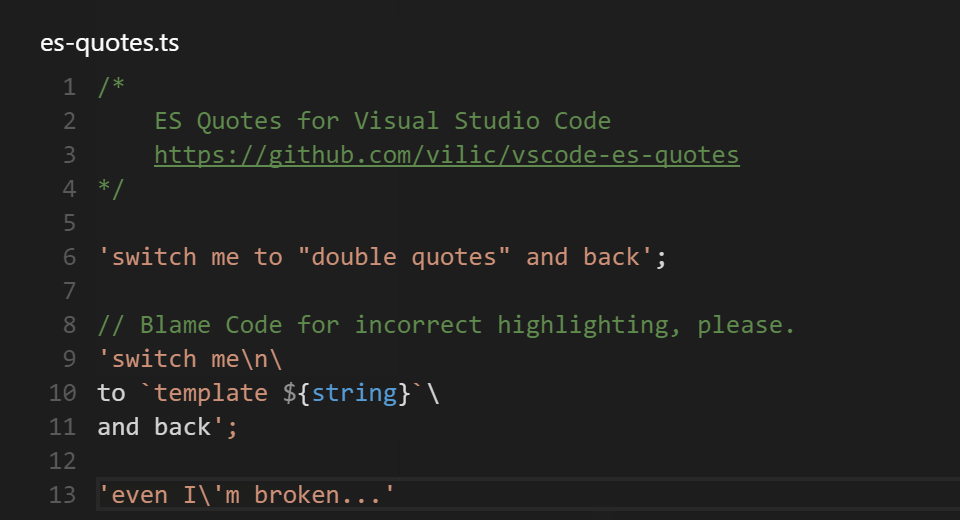
Paste and Indent
Paste code with “correct” indentation
Sort Lines
Sorts lines of text in specific order
Surround
A simple yet powerful extension to add wrapper templates around your code blocks.
Wrap Selection
Wraps selection or multiple selections with symbol or multiple symbols
Formatting Toggle
Allows you to toggle your formatter on and off with a simple click
Bracket Pair Colorizer
This extension allows matching brackets to be identified with colours. The user can define which characters to match, and which colours to use.

Auto Import
Automatically finds, parses and provides code actions and code completion for all available imports. Works with Typescript and TSX.
shell-format
shell script & Dockerfile & dotenv format
Vscode Google Translate
Quickly translate selected text right in your code
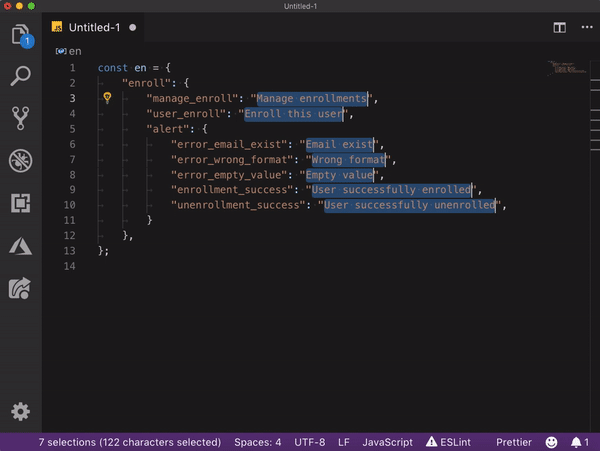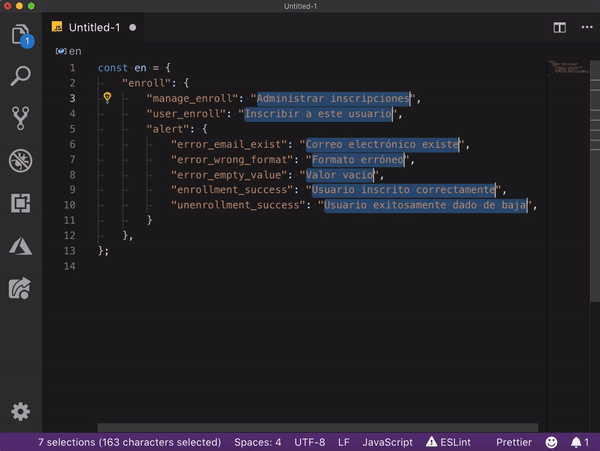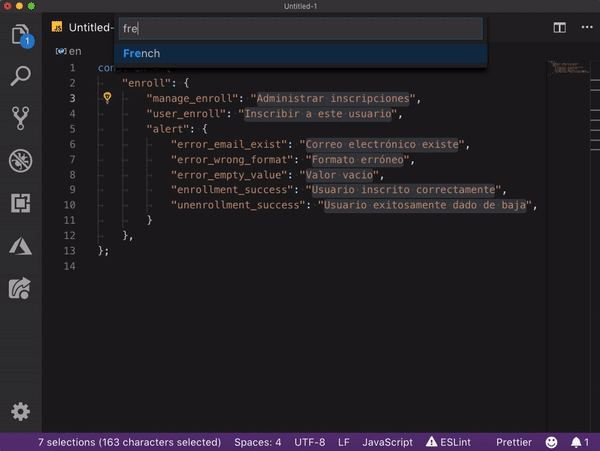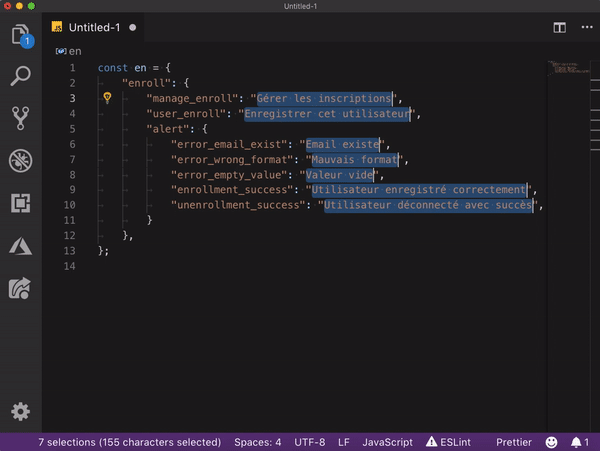
Explorer Icons
Material Icon Theme
Uncategorized
Browser Preview
Browser Preview for VS Code enables you to open a real browser preview inside your editor that you can debug. Browser Preview is powered by Chrome Headless, and works by starting a headless Chrome instance in a new process. This enables a secure way to render web content inside VS Code, and enables interesting features such as in-editor debugging and more!
FYI:… I HAVE TRIED ENDLESSLEY TO GET THE DEBUGGER TO WORK IN VSCODE BUT IT DOES NOT… I SUSPECT THAT’S WHY IT HAS A 3 STAR RATING FOR AN OTHERWISE PHENOMINAL EXTENSION.
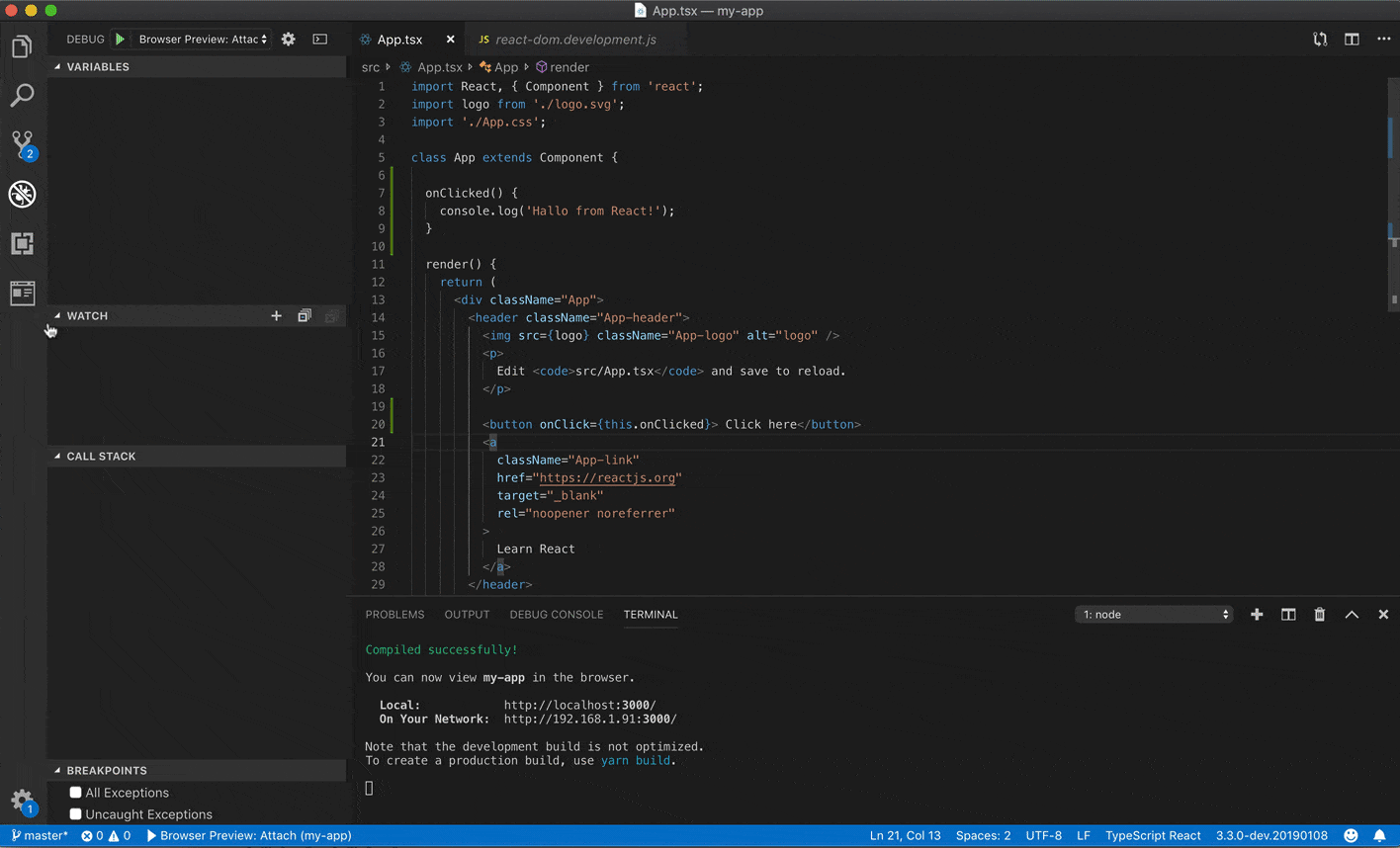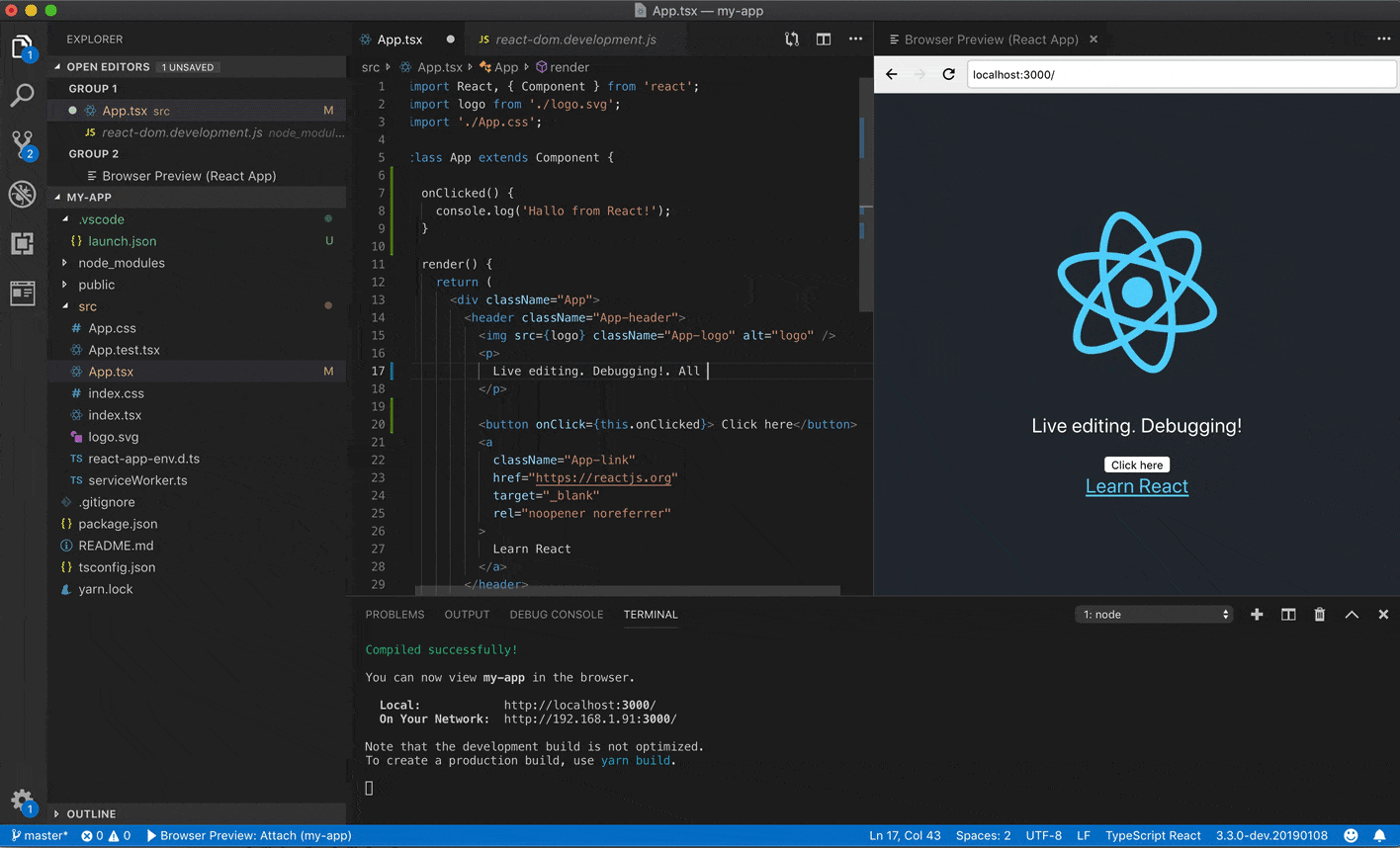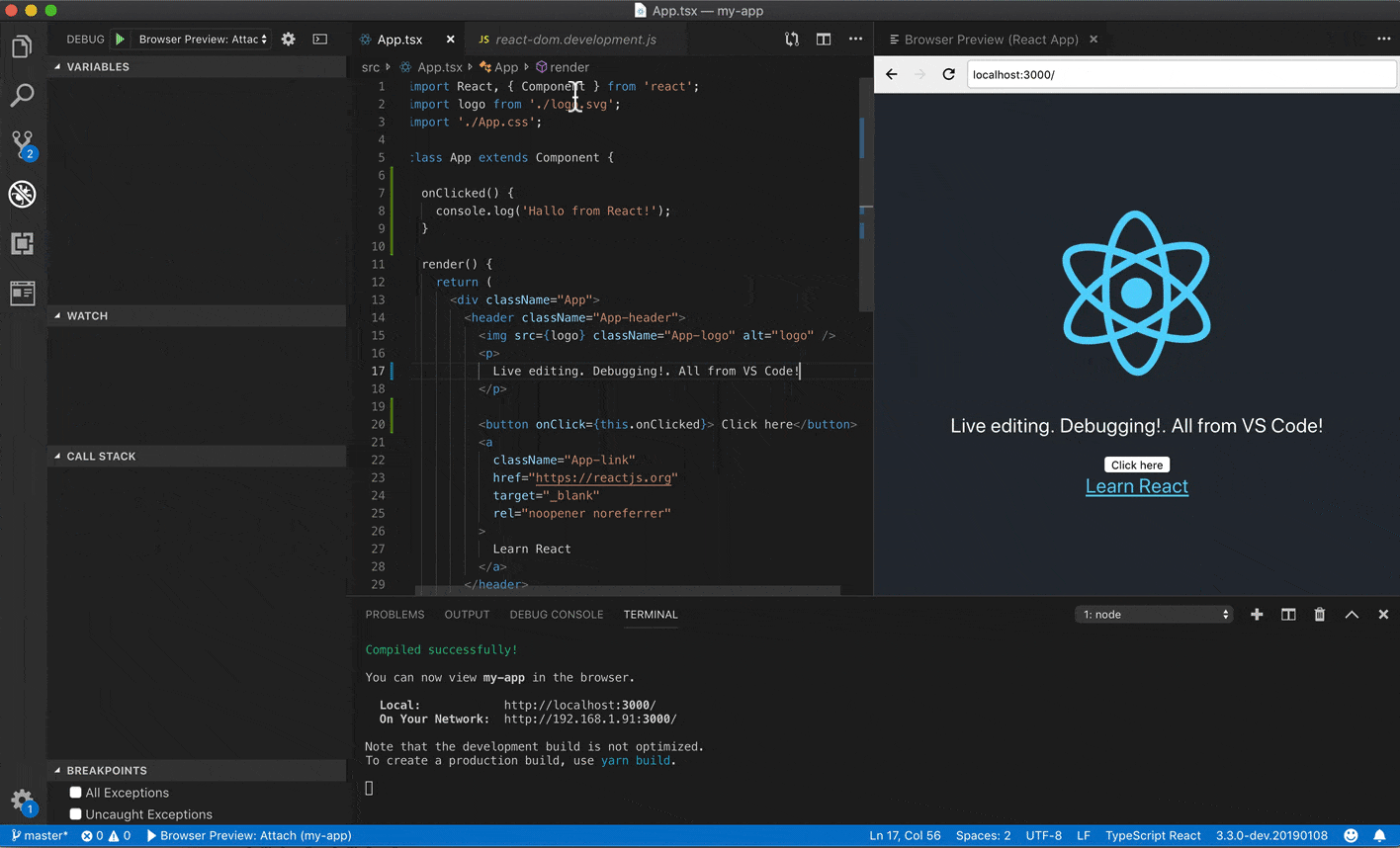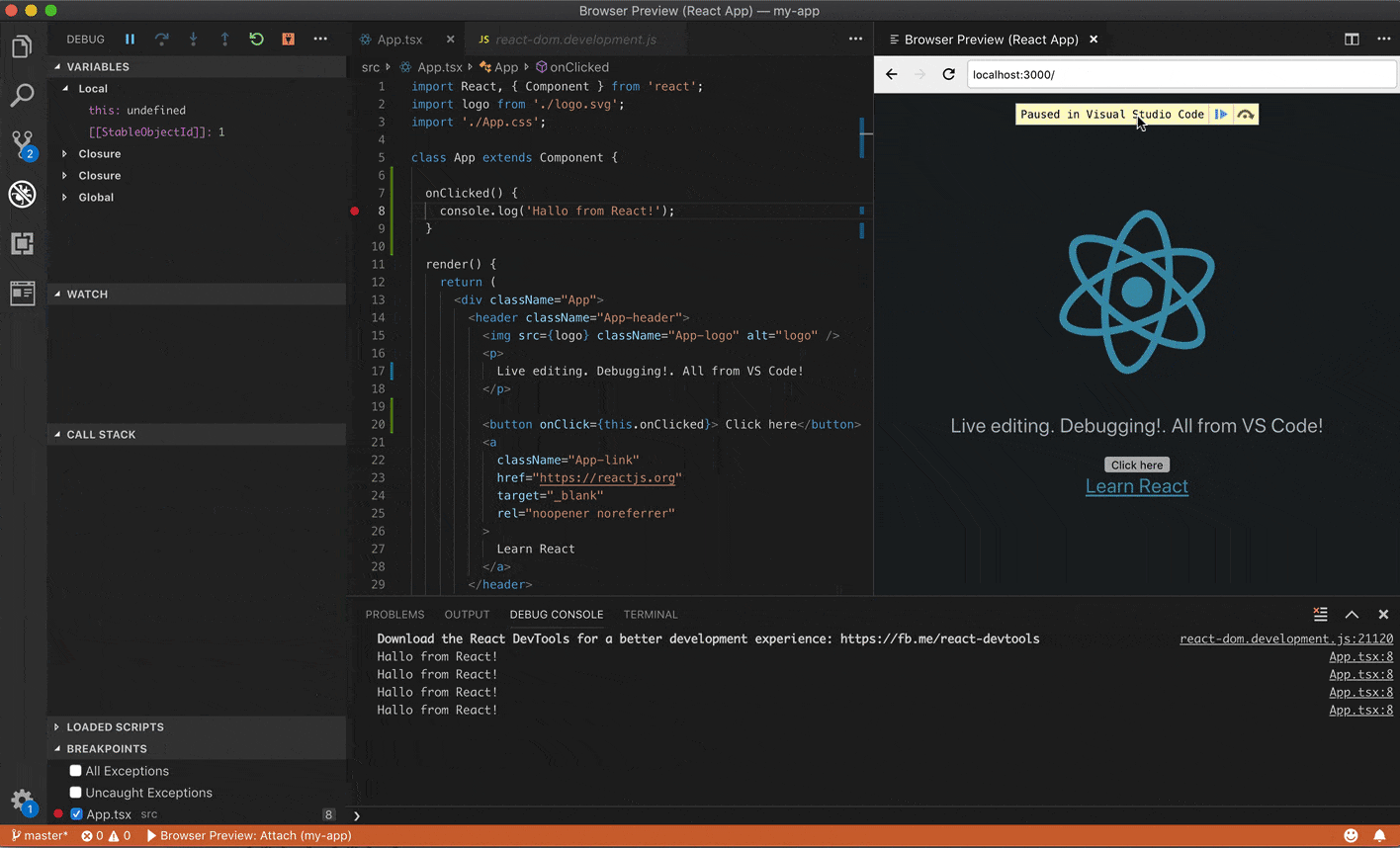
CodeRoad
Play interactive tutorials in your favorite editor.
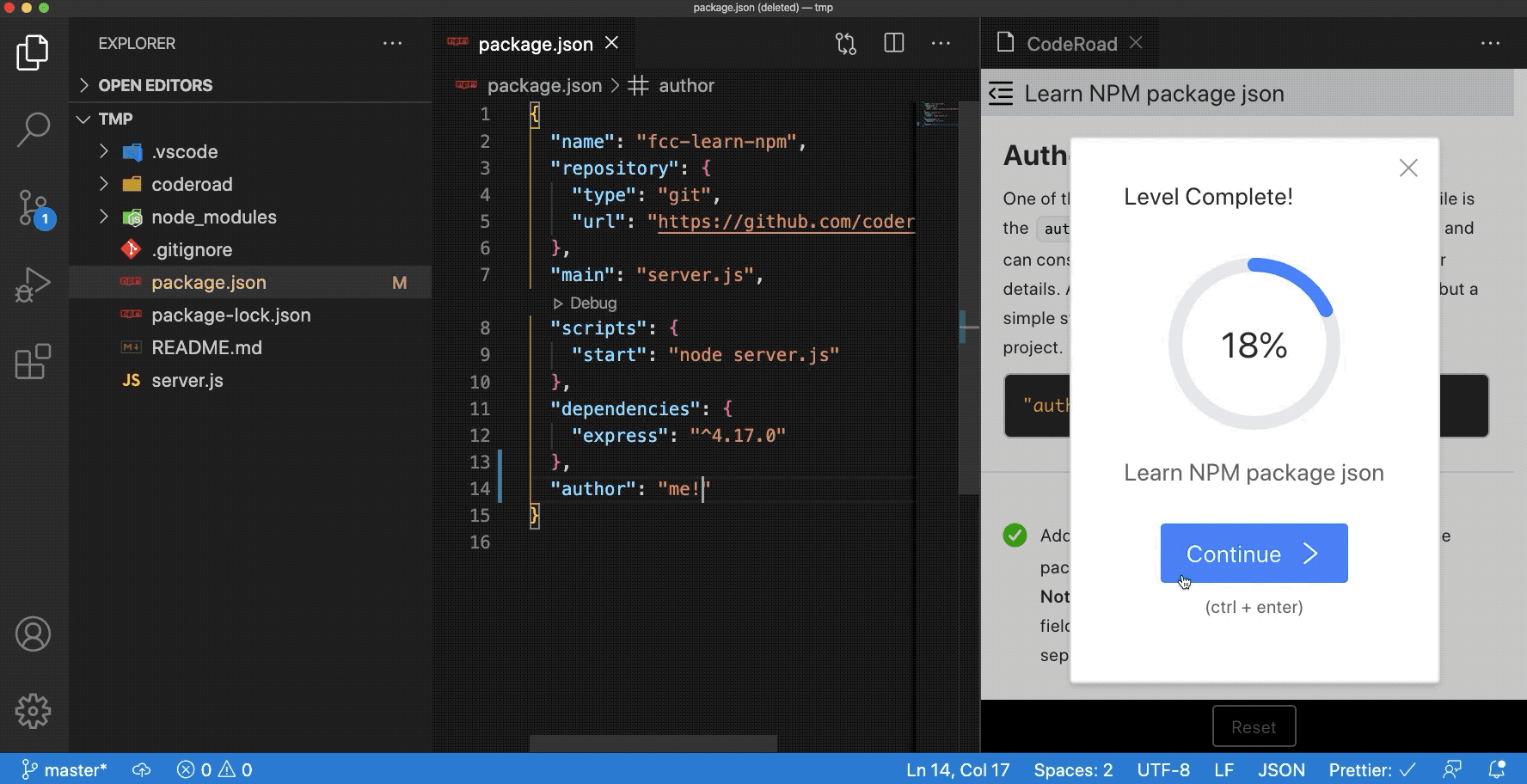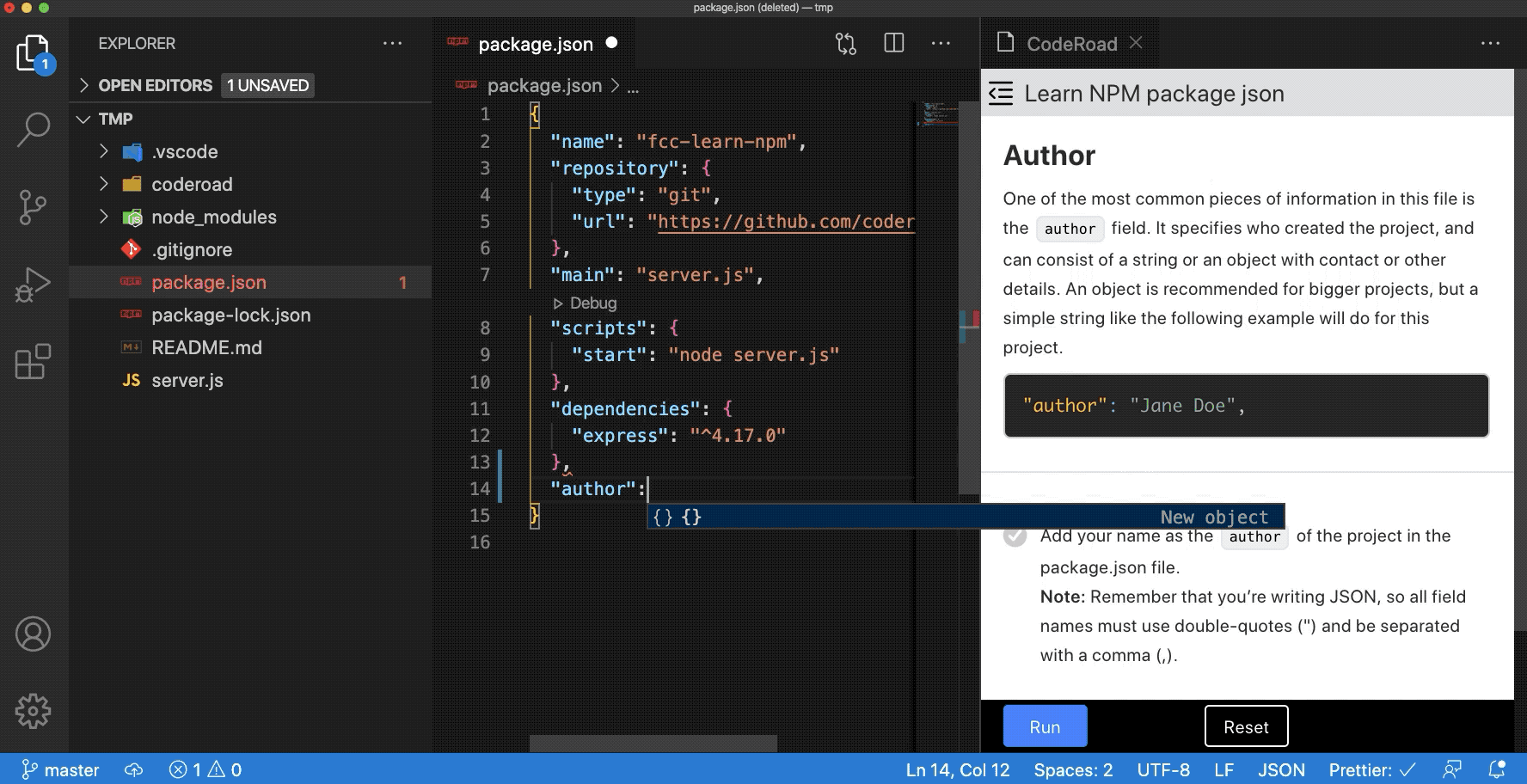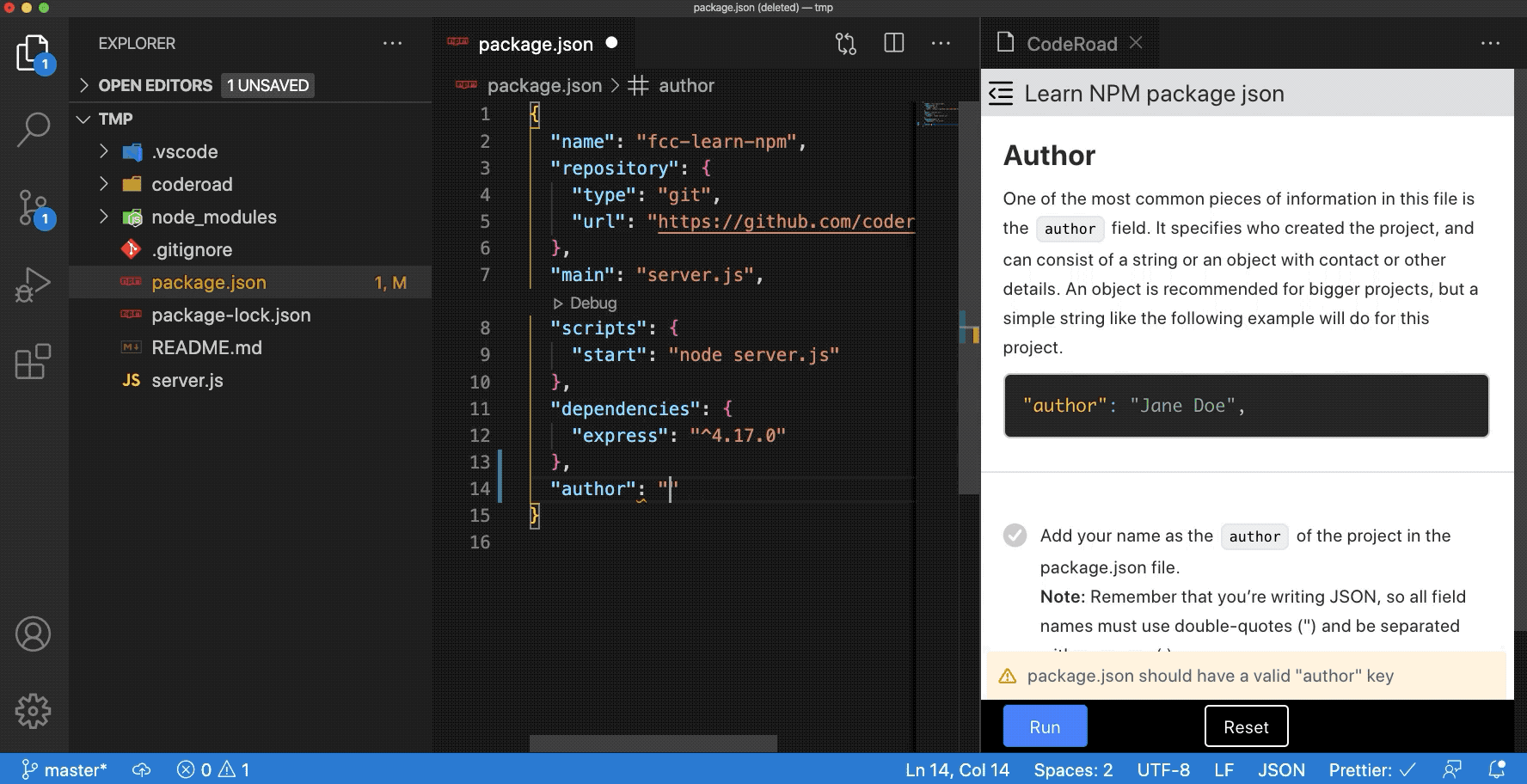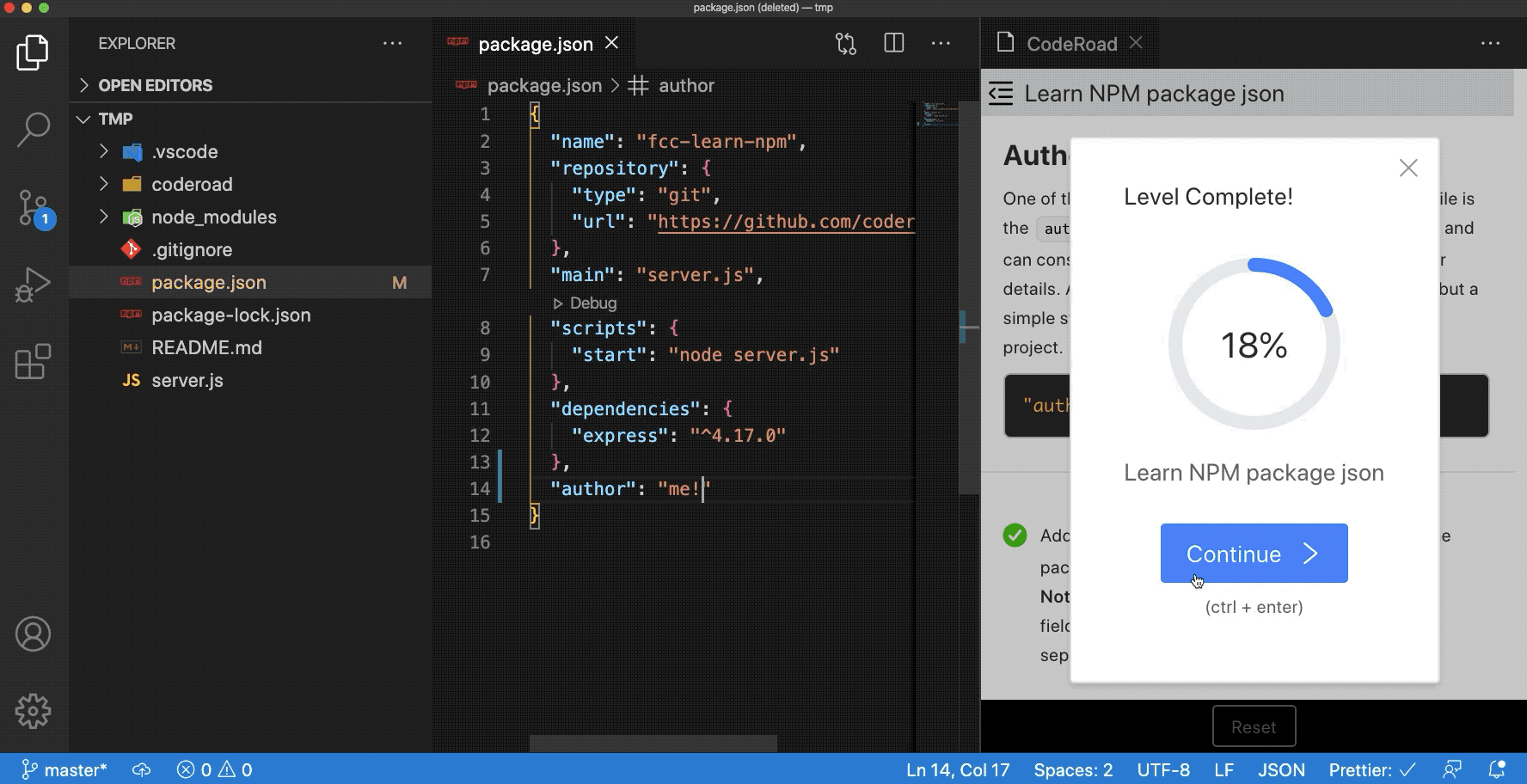
Code Runner
Run code snippet or code file for multiple languages: C, C++, Java, JavaScript, PHP, Python, Perl, Ruby, Go, Lua, Groovy, PowerShell, BAT/CMD, BASH/SH, F# Script, C# Script, VBScript, TypeScript, CoffeeScript, Scala, Swift, Julia, Crystal, OCaml Script
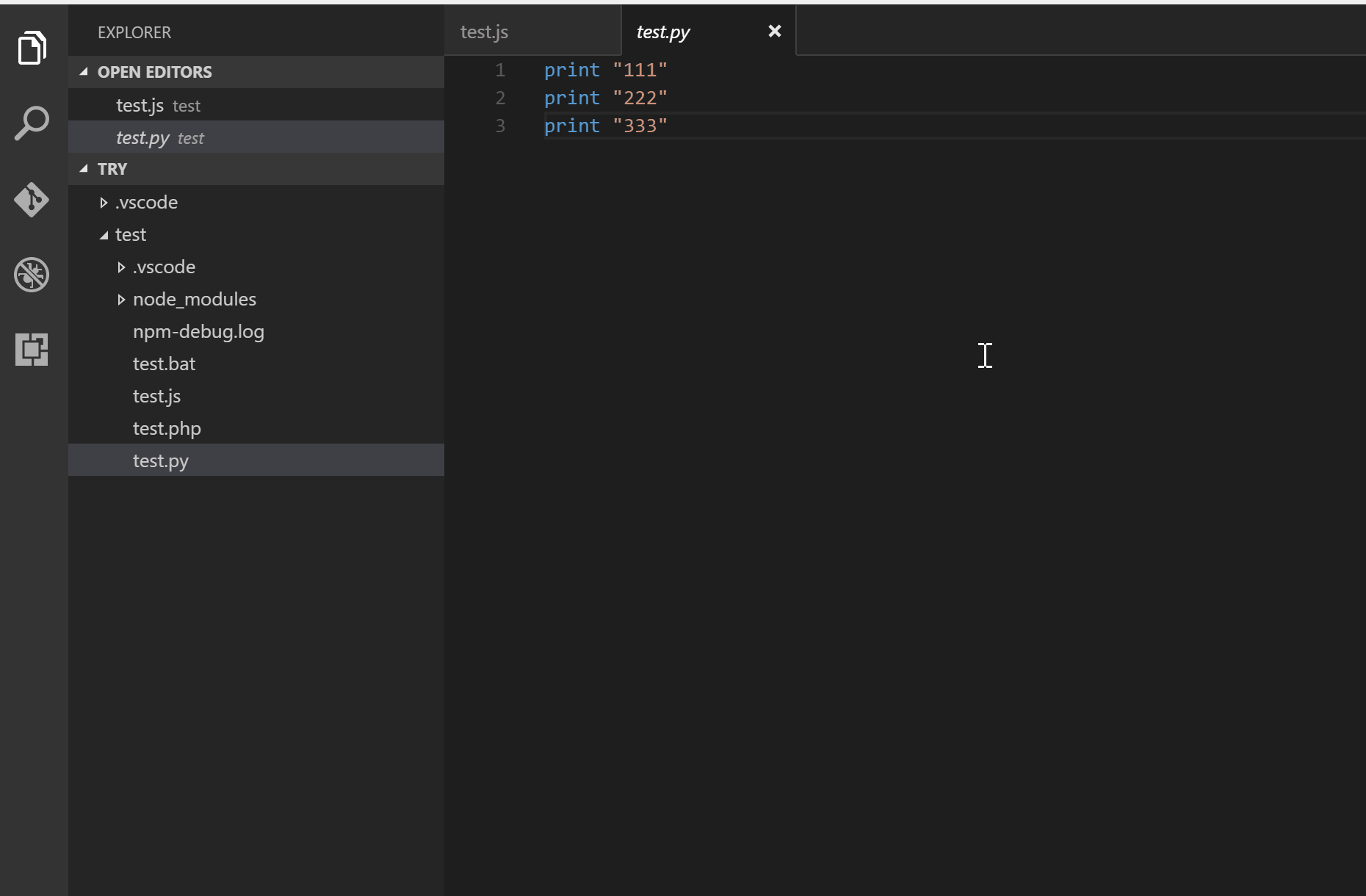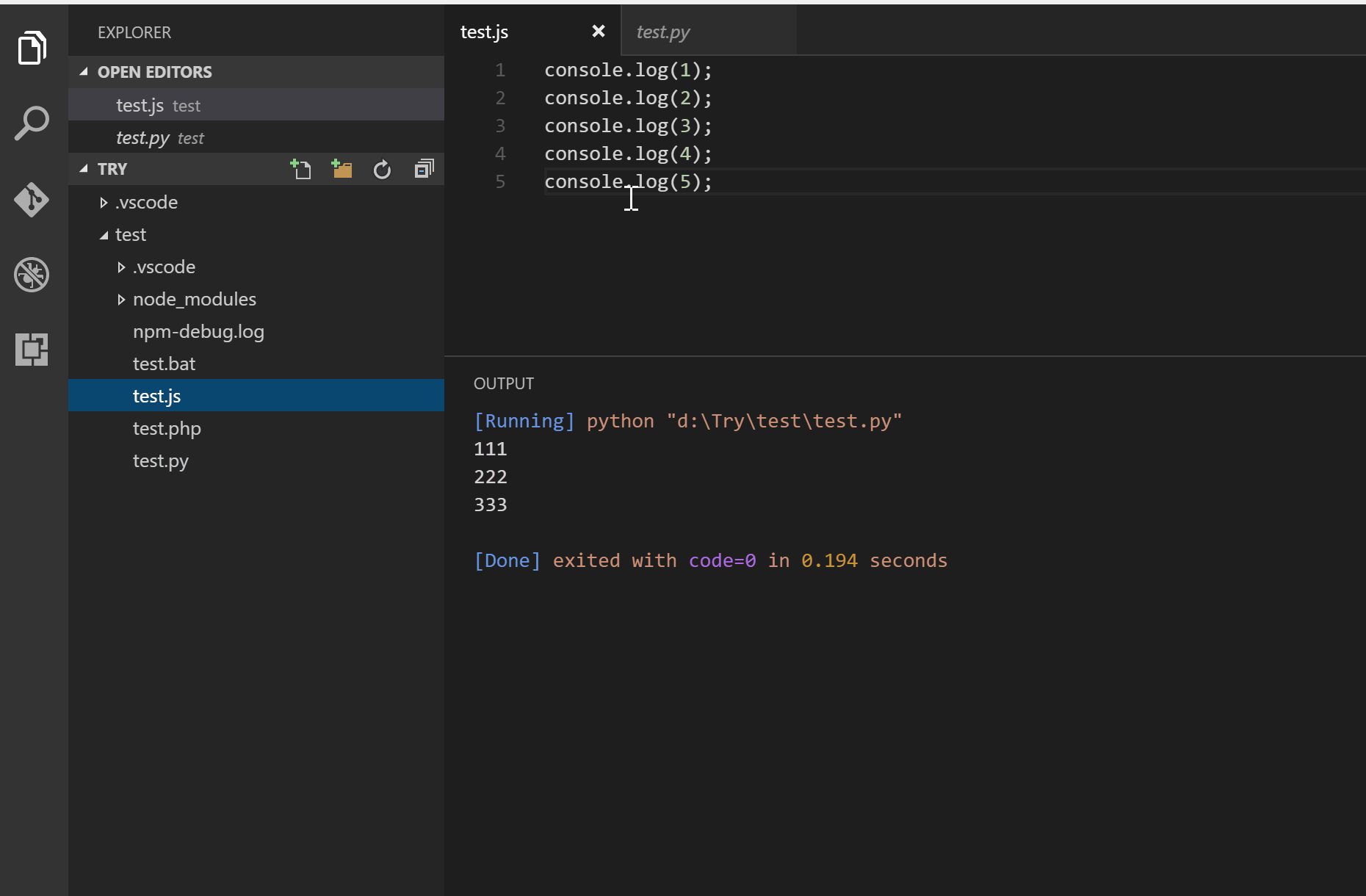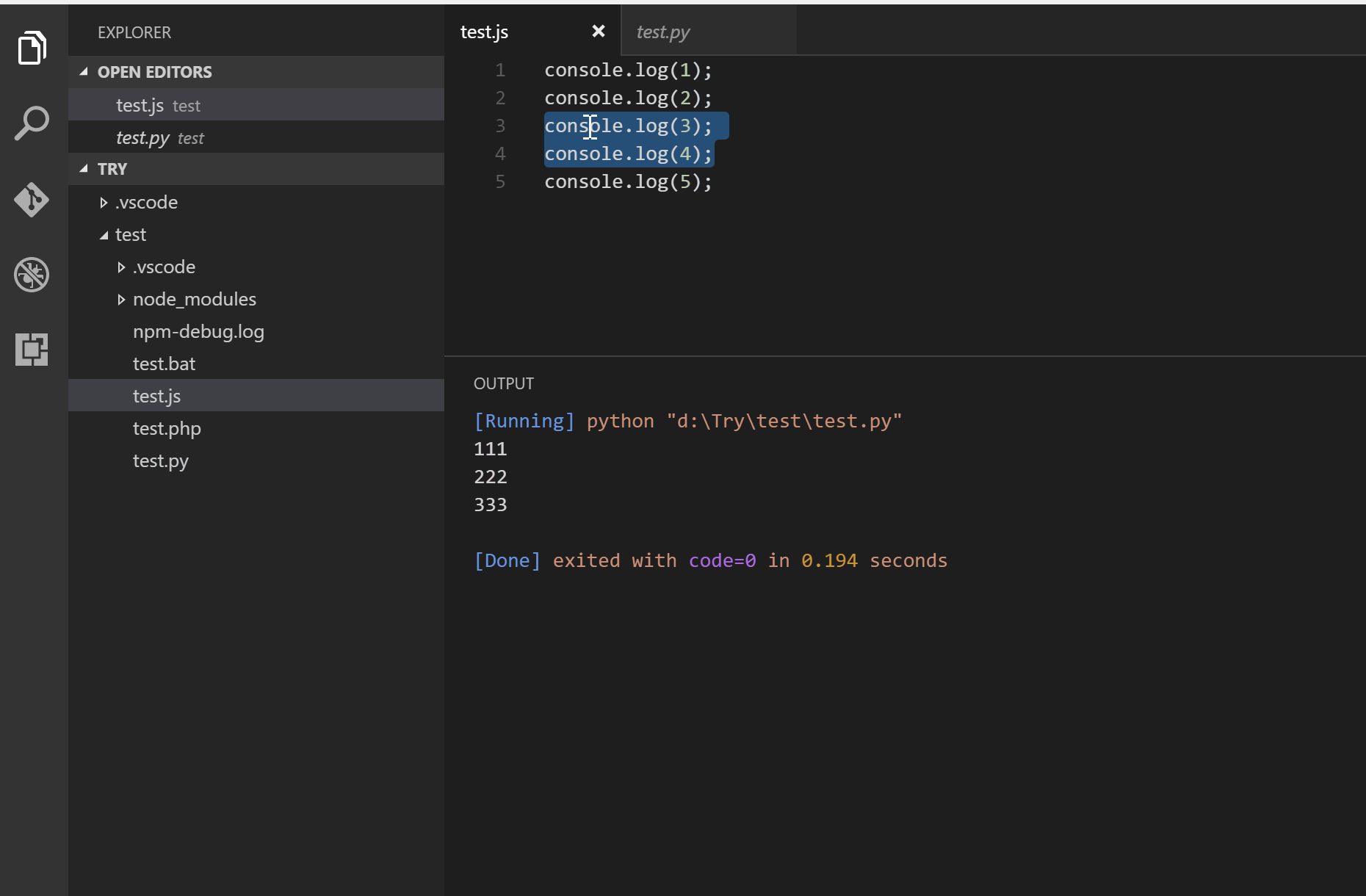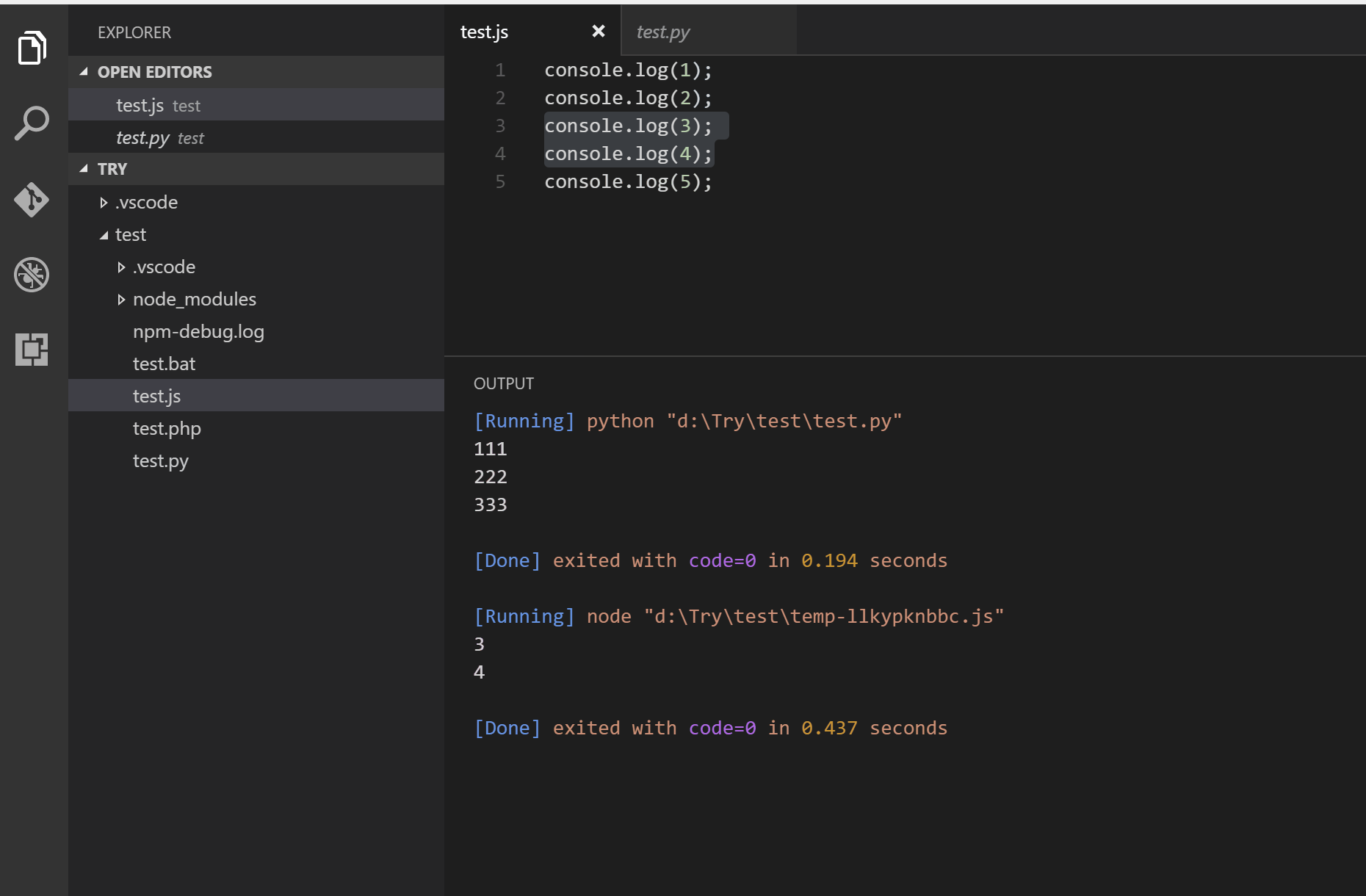
Code Time
Automatic time reports by project and other programming metrics right in VS Code.
Color Highlight
Highlight web colors in your editor
Output Colorizer
Syntax highlighting for the VS Code Output Panel and log files
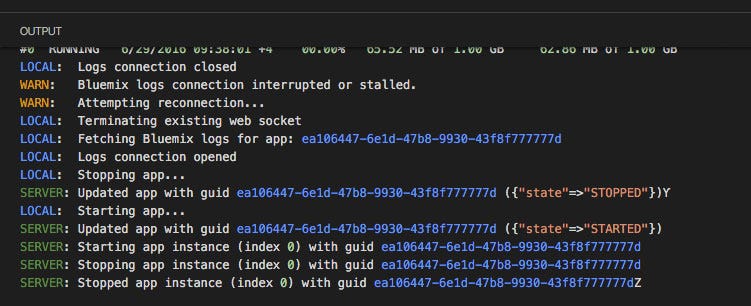
Dash
Dash integration in Visual Studio Code
Edit with Shell Command
Leverage your favourite shell commands to edit text
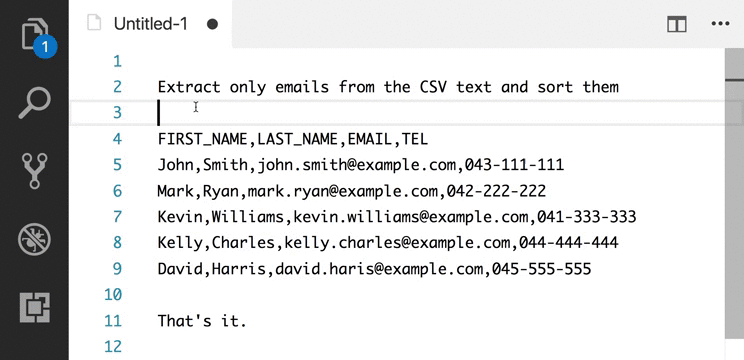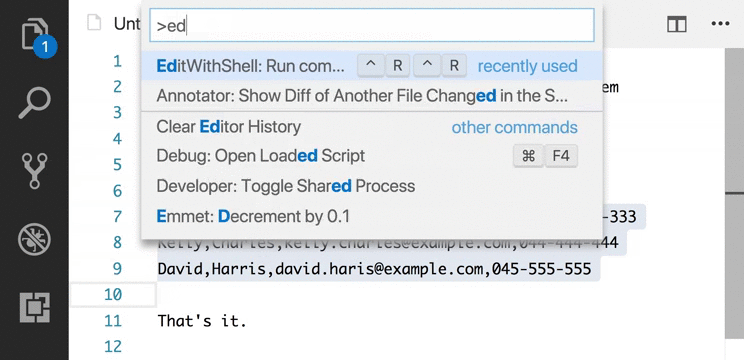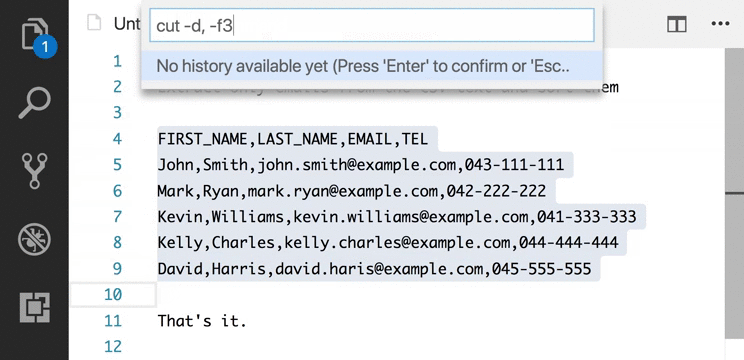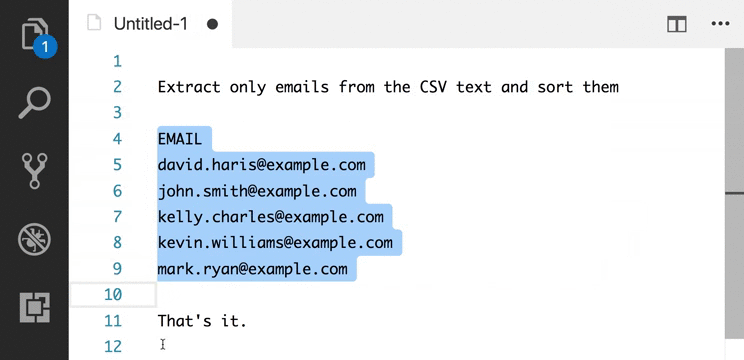
Editor Config for VS Code
Editor Config for VS Code
ftp-sync
Auto-sync your work to remote FTP server
Highlight JSX/HTML tags
Highlights matching tags in the file.
Indent Rainbow
A simple extension to make indentation more readable.
Password Generator
Create a secure password using our generator tool. Help prevent a security threat by getting a strong password today.
PlatformIO
An open source ecosystem for IoT development: supports 350+ embedded boards, 20+ development platforms, 10+ frameworks. Arduino and ARM mbed compatible.
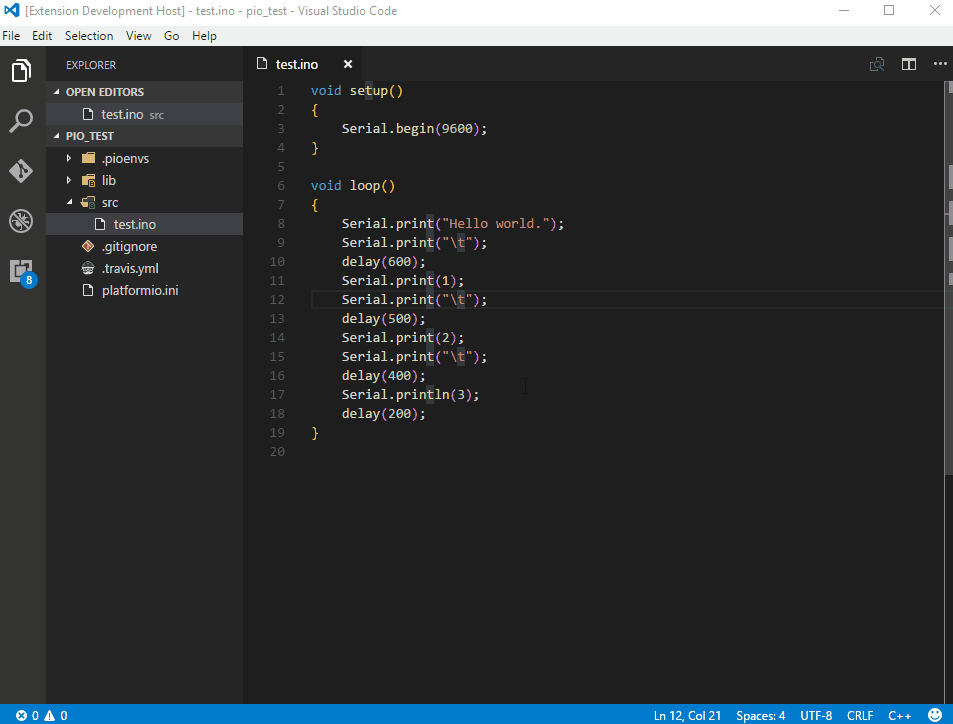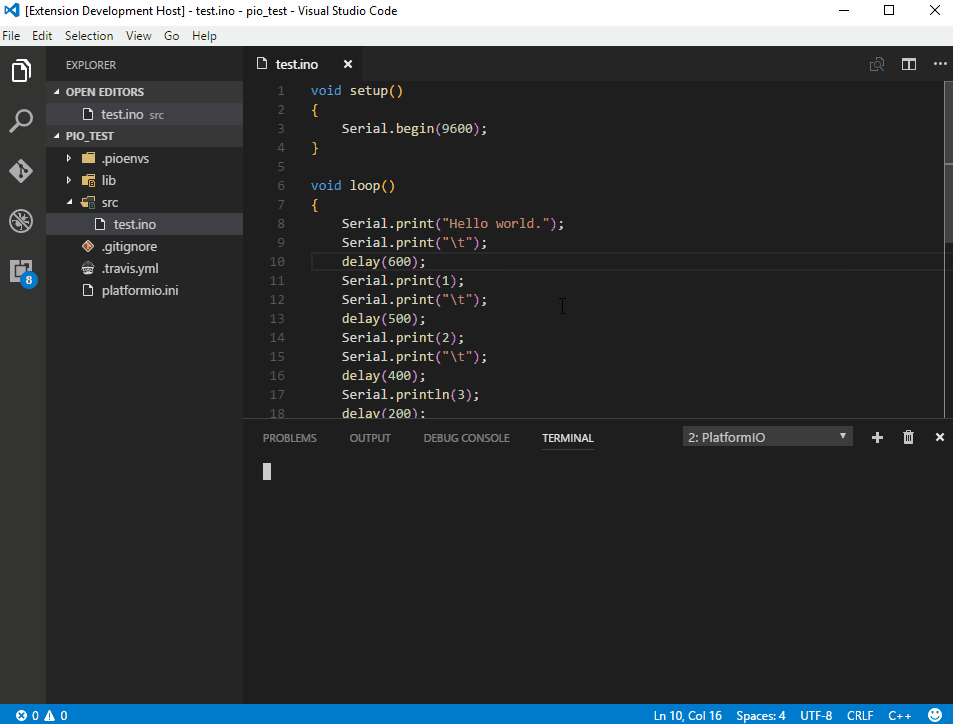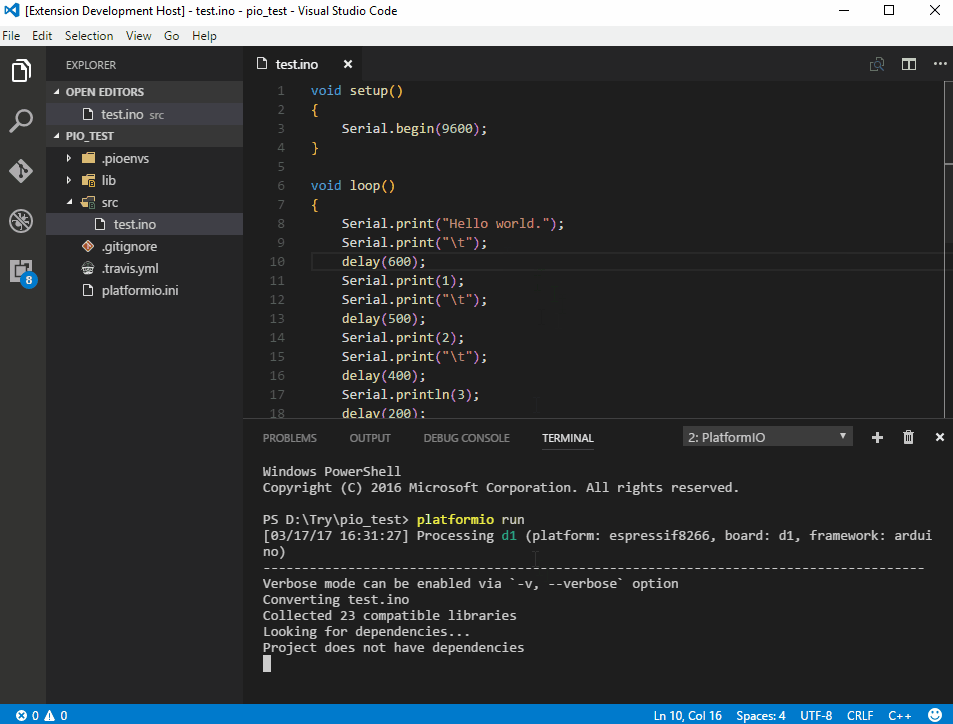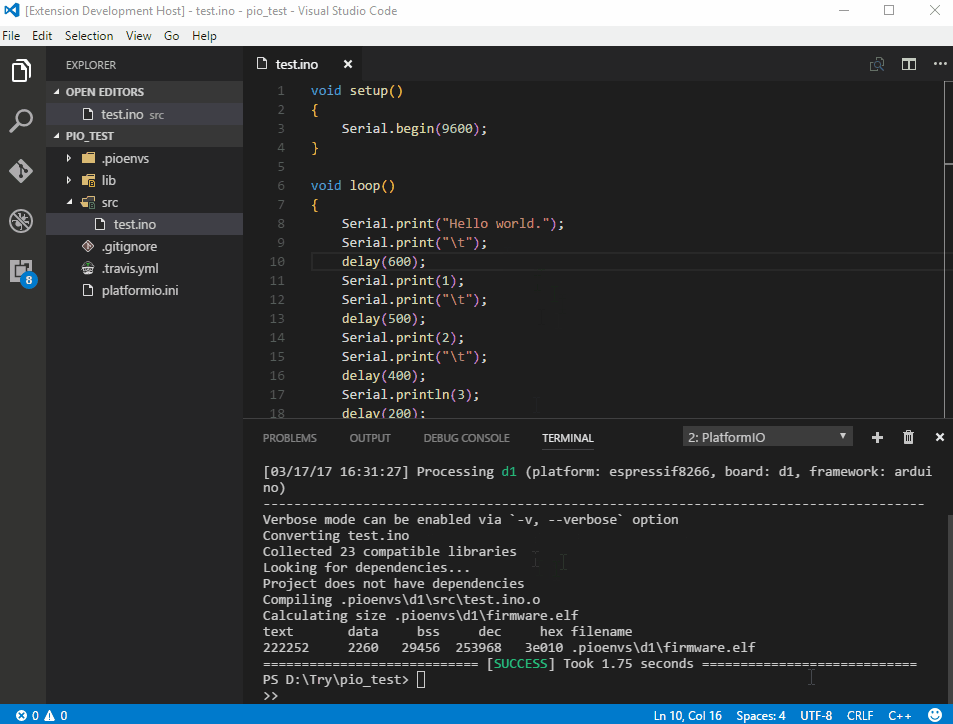
Polacode
Polaroid for your code
.
Note: Polacode no longer works as of the most recent update… go for Polacode2020 or CodeSnap…
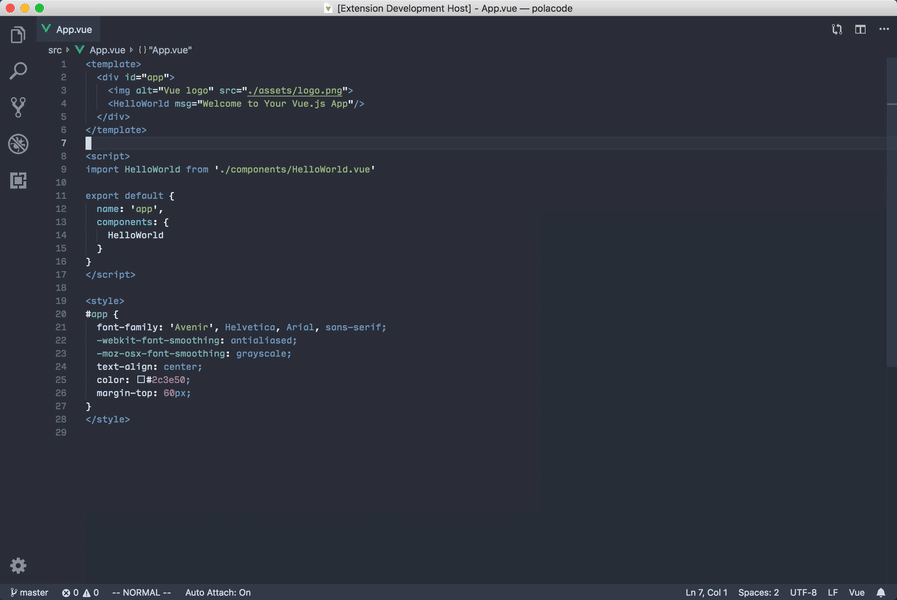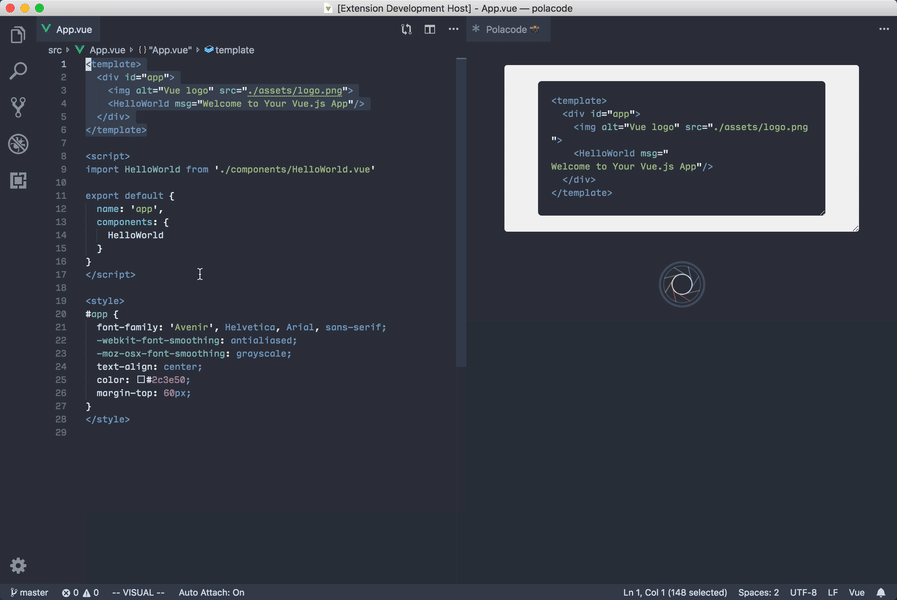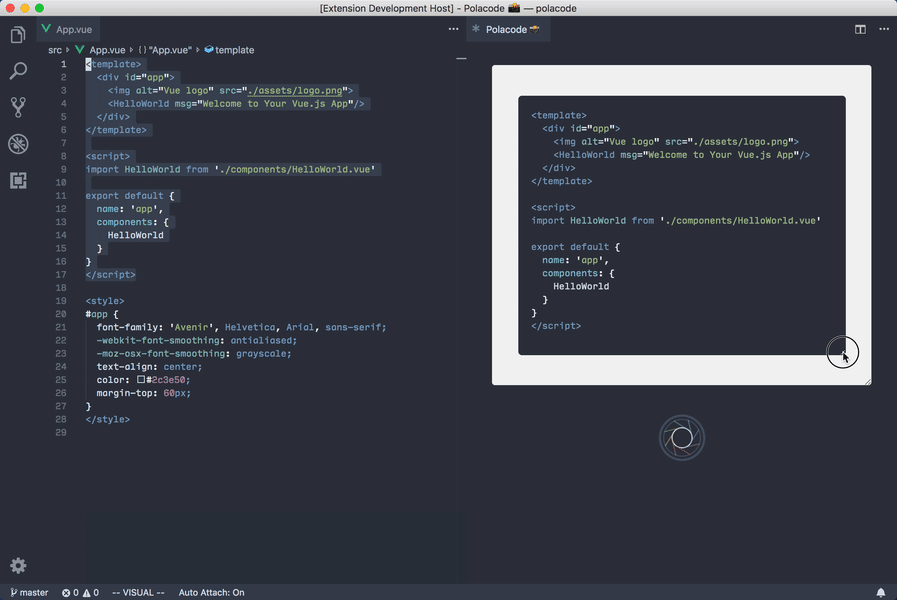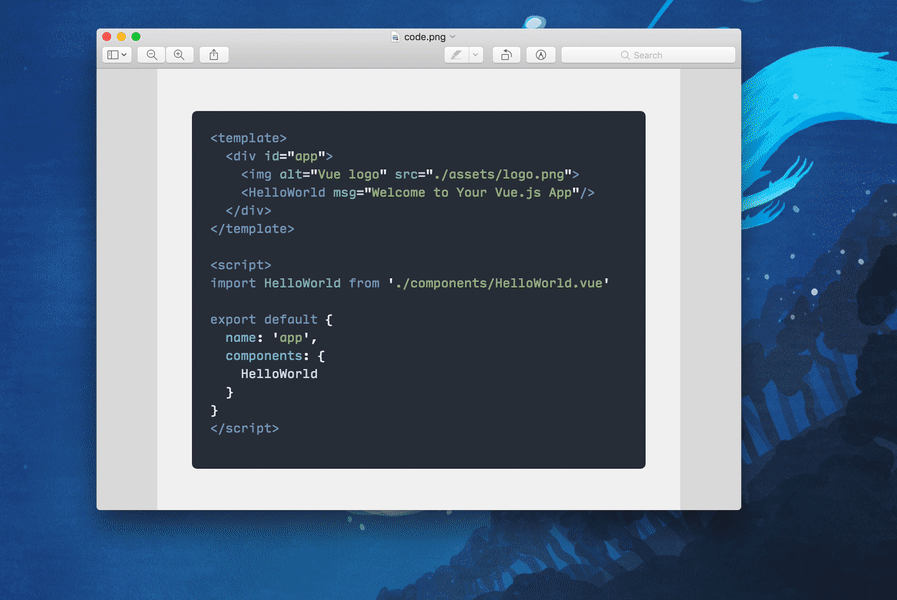
Quokka
This one is super cool!
Rapid prototyping playground for JavaScript and TypeScript in VS Code, with access to your project’s files, inline reporting, code coverage and rich output formatting.

Slack
Send messages and code snippets, upload files to Slack
Personally I found this extension to slow down my editor in addition to confliction with other extensions: (I have over 200 as of this writing)….. yes I have been made fully aware that I have a problem and need to get help
Spotify
No real advantage over just using Spotify normally… it’s problematic enough in implementation that you won’t save any time using it. Further, it’s a bit tricky to configure … or at least it was the last time I tried syncing it with my spotify account.
Provides integration with Spotify Desktop client. Shows the currently playing song in status bar, search lyrics and provides commands for controlling Spotify with buttons and hotkeys.
SVG
A Powerful SVG Language Support Extension(beta). Almost all the features you need to handle SVG.
SVG Viewer
View an SVG in the editor and export it as data URI scheme or PNG.
Text Marker (Highlighter)
Highlight multiple text patterns with different colors at the same time. Highlighting a single text pattern can be done with the editor’s search functionality, but it cannot highlight multiple patterns at the same time, and this is where this extension comes handy.
ESDOC MDN
THIS IS A MUST HAVE
Quickly bring up helpful MDN documentation in the editor
Themes:
In the interest of not making the reader scroll endlessly as I often do… I’ve made a separate post for that here. If you’ve made it this far, I thank you!
https://5fff5b9a2430bb564bfd451d–stoic-mccarthy-2c335f.netlify.app/#h18
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://5fff5b9a2430bb564bfd451d–stoic-mccarthy-2c335f.netlify.app/#h18https://5fff5b9a2430bb564bfd451d–stoic-mccarthy-2c335f.netlify.app/#h18
Or Checkout my personal Resource Site:
https://5fff5b9a2430bb564bfd451d–stoic-mccarthy-2c335f.netlify.app/#h18
Product Icon Themes:
Fluent Icons
A product icon theme for Visual Studio Code
Product icons themes allow theme authors to customize the icons used in VS Code’s built-in views: all icons except file icons (covered by file icon themes) and icons contributed by extensions. This extension uses Fluent Icons.
Install
- Install the icon theme from the Marketplace
- Open the command palette (
Ctrl/Cmd + Shift + P) and search forPreferences: Product Icon Theme - Select
Fluent Icons
TBC…
Monokai Oblique by pushqrdx
Monokai inspired theme for Visual Studio Code and Visual Studio IDE.
Monokai Pro by monokai (commercial)
Beautiful functionality for professional developers, from the author of the original Monokai color scheme.
Night Owl by Sarah Drasner
A VS Code theme for the night owls out there. Works well in the daytime, too, but this theme is fine-tuned for those of us who like to code late into the night. Color choices have taken into consideration what is accessible to people with color blindness and in low-light circumstances. Decisions were also based on meaningful contrast for reading comprehension and for optimal razzle dazzle. 
Plastic by Will Stone
A simple theme.
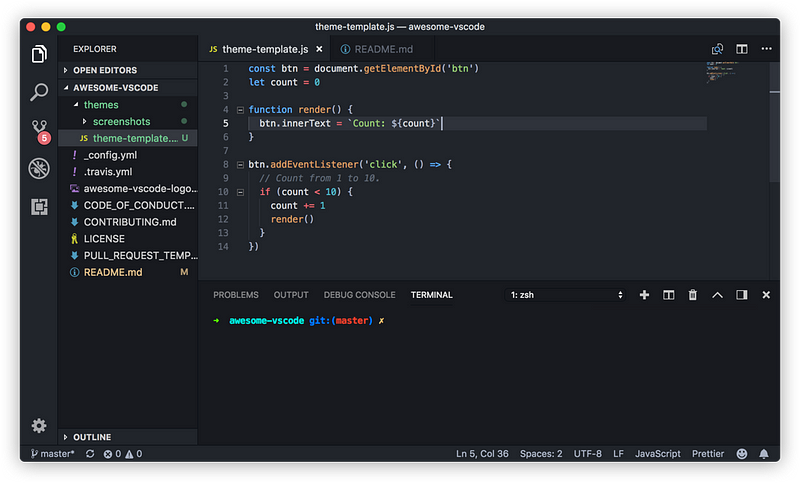
Nord by arcticicestudio
An arctic, north-bluish clean and elegant Visual Studio Code theme.
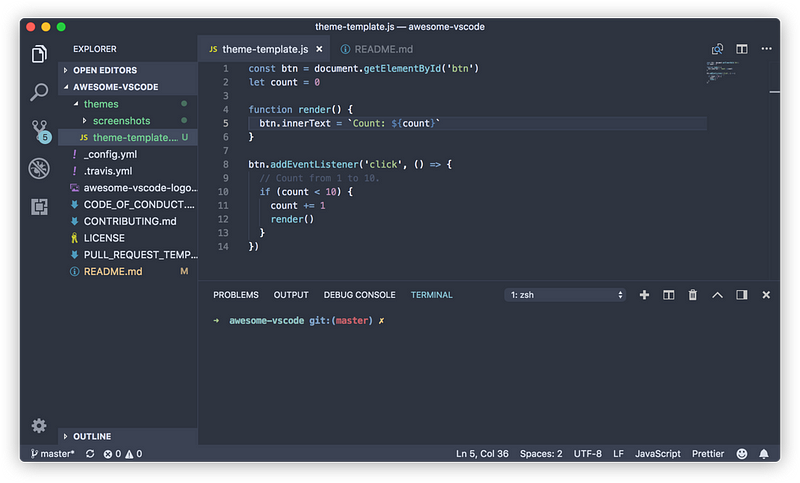
Rainglow by Dayle Rees
Collection of 320+ beautiful syntax and UI themes.
Relaxed Theme by Michael Kühnel
A relaxed theme to take a more relaxed view of things.
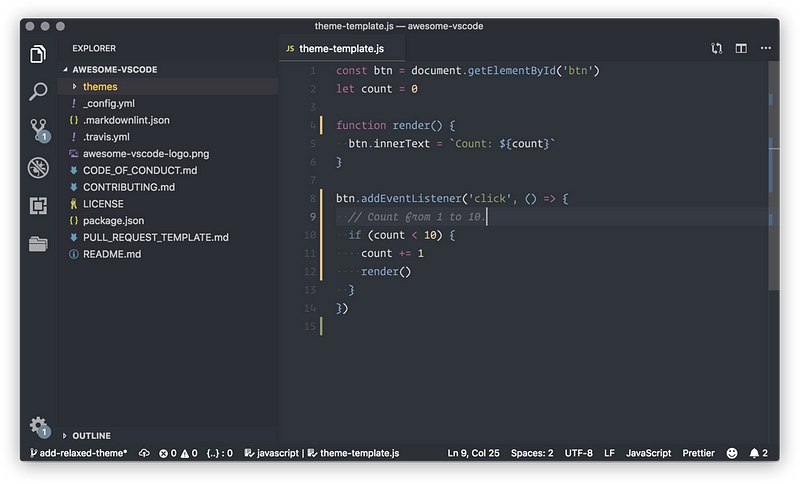
Shades of Purple by Ahmad Awais
 A professional theme with hand-picked & bold shades of purple
A professional theme with hand-picked & bold shades of purple  to go along with your VS Code. A custom VS Code theme with style.
to go along with your VS Code. A custom VS Code theme with style.
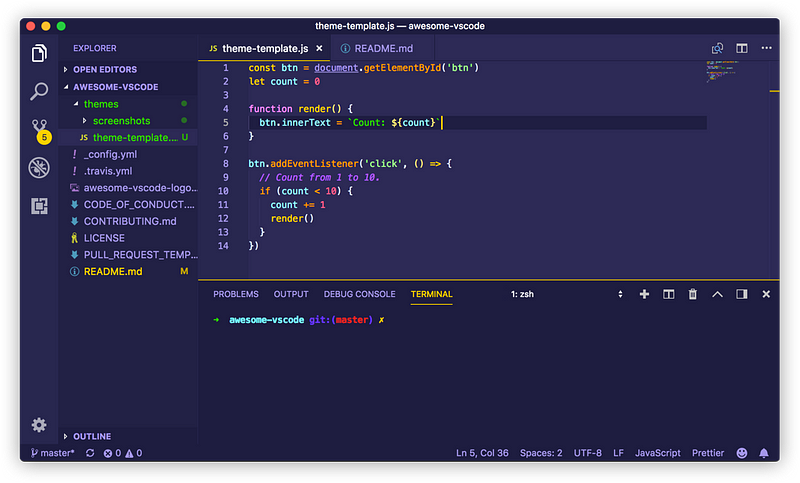
2077 theme by Endormi
Cyberpunk 2077 inspired theme
An Old Hope Theme by Dustin Sanders
VSCode theme inspired by a galaxy far far away…
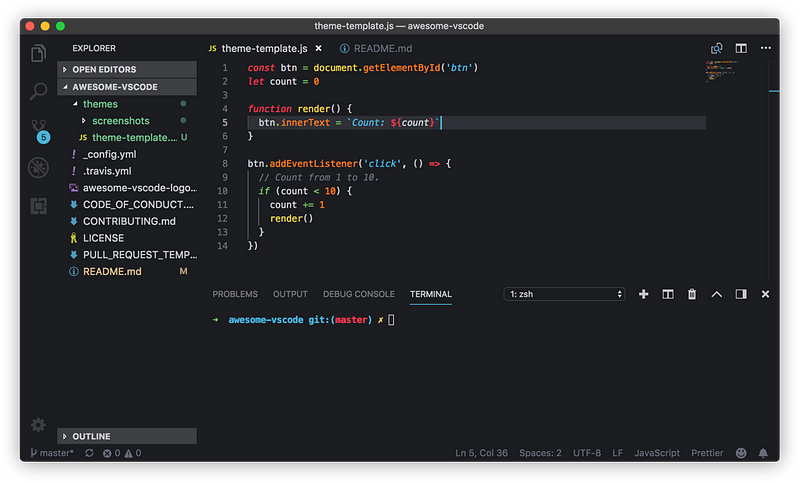
Ariake Dark by wart
Dark VSCode theme inspired by Japanese traditional colors and the poetry composed 1000 years ago.
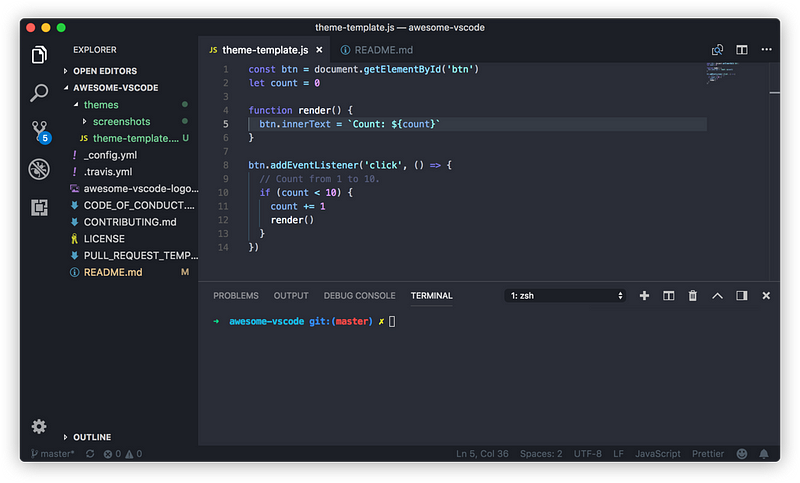
Atom One Dark Theme by Mahmoud Ali
One Dark Theme based on Atom.
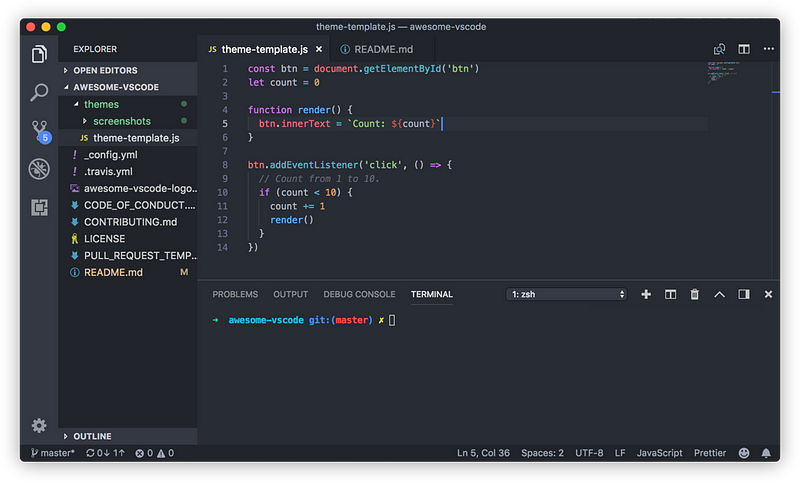
Atomize by emroussel
A detailed and accurate Atom One Dark Theme.
Ayu by teabyii
A simple theme with bright colors and comes in three versions — dark, light and mirage for all day long comfortable work.
Borealis Theme by Alexander Eckert
VS Code theme inspired by the calm colors of the aurora borealis in Alaska.
Captain Sweetheart by ultradracula
Tuff but sweet theme.
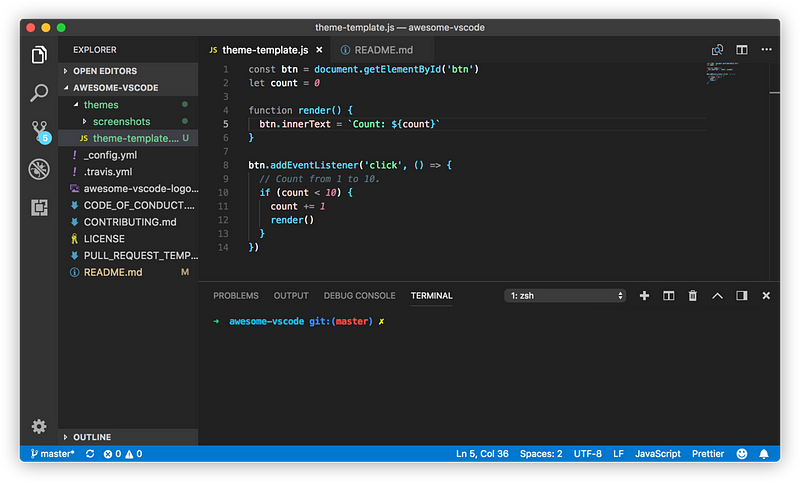
City Lights by Yummygum
 Yummygum’s Official City Lights suite
Yummygum’s Official City Lights suite
Cobalt2 Theme Official by Wes Bos
Official theme by Wes Bos.
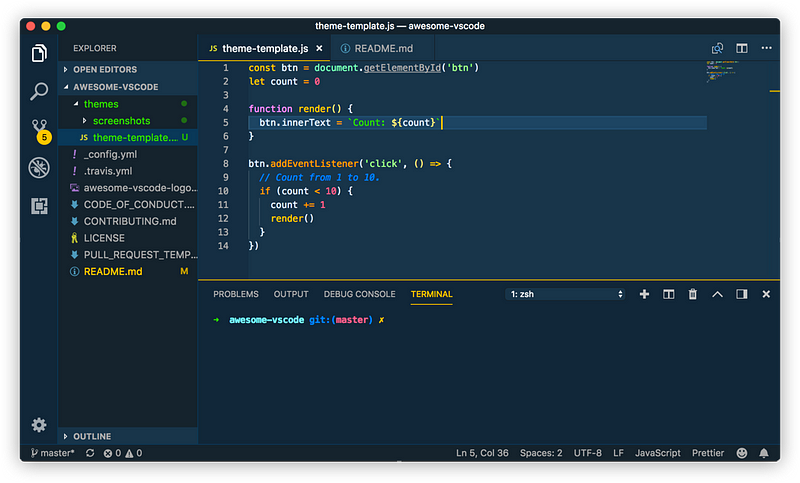
Dracula Official by Dracula Theme
Official Dracula Theme. A dark theme for many editors, shells, and more.
Edge by Bogdan Lazar
A simple theme with bright colors in three variants — Night Sky, Serene and Ocean for all day long comfortable work.
Eva Theme by fisheva
A colorful and semantic coloring code theme.
Fairy Floss by nopjmp and sailorhg
A fun, purple-based pastel/candy/daydream fairyfloss theme made by sailorhg.
GitHub Theme by Thomas Pink
GitHub Theme for Visual Studio Code.
Jellybeans Theme by Dimitar Nonov
Jellybeans Theme for Visual Studio Code.
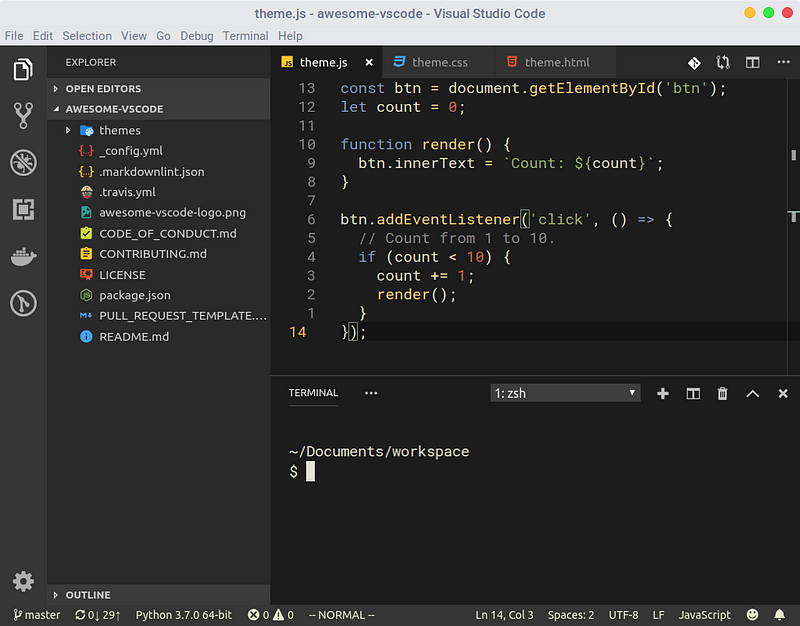
Material Palenight Theme by whizkydee
An elegant and juicy material-like theme for Visual Studio Code.
Material Theme by Mattia Astorino
The most epic theme now for Visual Studio Code.
Mno by u29dc
Minimal monochrome theme.
Slime Theme by smlombardi
A dark syntax/workbench theme for Visual Studio Code — optimized for SCSS, HTML, JS, TS, Markdown, and PHP files.
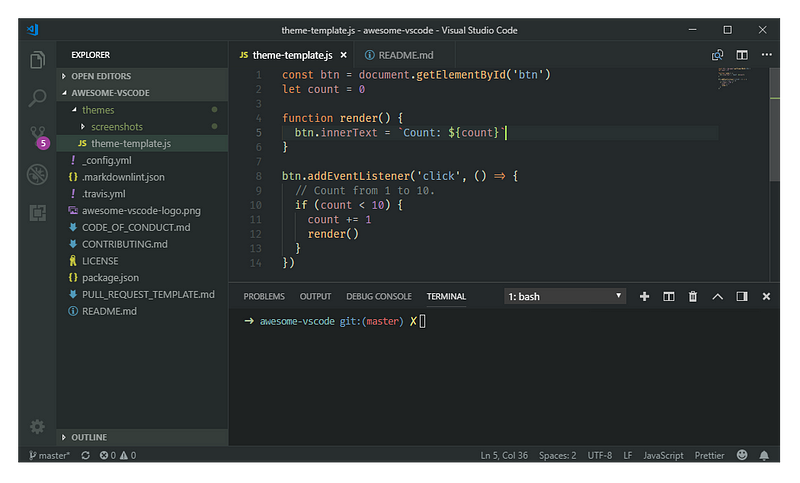
Niketa Theme by Dejan Toteff
Collection of 18 light themes separated in 4 groups by background’s brightness.
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://gist.github.com/bgoonzhttps://gist.github.com/bgoonz
Or Checkout my personal Resource Site:
==> currently under development & very buggy
https://gist.github.com/bgoonz
Object-Oriented Programming
Overview:
Encapsulation
- The mechanism that puts behavior and data together behind methods that hide the specific implementation of a class.
How can a CommonJS Module import functionality from another module?
- Through the use of the require function.
How can an ES6 module import functionality from another module?
- Through the use of the import-from syntax that looks like this:
import SymbolName from './relative-path.js';
How do CommonJS Modules allow other modules to access exported symbols?
- Through the use of the module.exports property.
How do ES6 Modules export functionality so other modules can use them?
- Through the use of the export keyword.
Implementation inheritance
- The data and methods defined on a parent class are available on objects created from classes that inherit from those parent classes
Inheritance
- The mechanism that passes traits of a parent class to its descendants.
Prototypal inheritance
- A method of realizing implementation inheritance through process of finding missing properties on an object by delegating the resolution to a prototype object.
The constructor method
- The special method of a class that is called to initialize an object when code uses the new keyword to instantiate an object from that class.
The Dependency Inversion Principle
- Functionality that your class depends on should be provided as parameters to methods rather than using new in the class to create a new instance of a dependency.
The extends keyword
- The keyword in JavaScript that allows one class to inherit from another.
The Interface Segregation Principle
- Method names should be grouped together into granular collections called “interfaces”
The Law Of Demeter
- Don’t use more than one dot (not counting the one after “this”).
- A method of an object can only invoke the methods (or use the properties) of the following kinds of objects: Methods on the object itself Any of the objects passed in as parameters to the method And object created in the method Any values stored in the instance variables of the object Any values stored in global variables
The Liskov Substitution Principle
- You can substitute child class objects for parent class objects and not cause errors.
The Open-Close Principle
- A class is open for extension and closed for modification.
The Single-Responsibility Principle
- Any one of the following:
- A class should do one thing and do it well.
- A class should have only one reason to change.
- Gather together the things that change for the same reasons. Separate those things that change for different reasons.
Background:
Constructor Functions
Defining a constructor function Example of an object using object initialization
const fellowshipOfTheRing = {
title: "The Fellowship of the Ring",
series: "The Lord of the Rings",
author: "J.R.R. Tolkien",
};
- The above literal is a “Book” object type.
Object Typeis defined by it’s attributes and behaviors.
**Behaviors**are represented by methods.
Constructor Functions: Handle the creation of an object – it’s a factory for creating objects of a specific type.- There are a few specific things to constructors worth noting:
- The name of the constructor function is capitalized
- The Function does not explicitly return a value
- Within the body, the this keyword references the newly created object
function Book(title, series, author) {
this.title = title;
this.series = series;
this.author = author;
}
Invoking a constructor function
- We can invoke a constructor function using the
newkeyword.
function Book(title, series, author) {
this.title = title;
this.series = series;
this.author = author;
}
const fellowshipOfTheRing = new Book(
"The Fellowship of the Ring",
"The Lord of the Rings",
"J.R.R. Tolkien"
);
console.log(fellowshipOfTheRing); // Book { title: 'The Fellowship of the Ring', ... }
Four Things will happen when invoking a constructor function
- A new empty object is created {};
- The new obj’s
prototypeis set to the object referenced by the constructors prototype property. Thisis bound to the new object.- The new object is returned after the constructor function has completed.
Understanding New Object Instances
Instance: term to describe an objected created from a constructor function.- Every instance created is a unique object and therefore not equal to each other.
Using the instanceof operator to check an object’s type
console.log(fellowshipOfTheRing instanceof Book); // true
- By using the
instanceofoperator we can verify that an object was created from a certain object type. - The instanceOf operator works by checking to see if the prototype object of the left side of the operator is the same as the prototype object of the right side of the operator.
Invoking a constructor function without the new keyword
- If we invoke a constructor function without the
newkeyword, we may result in one of two unexpected outcomes: - In non-strict mode, this will be bound to the global object instead.
- In
strictmode, this will become undefined. - You can enable strict mode by typing
"use strict"at the top of your file.
Defining Sharable Methods
- Avoid the temptation to store an object method inside a constructor function, it is inefficient with computer memory usage b/c each object instance would have it’s own method definition.
Prototype: An object that is delegated to when a reference to an object property or method can’t be resolved.- Every instance created by a constructor function shares the same prototype.
Object.setPrototypeOf()andObject.getPrototypeOf()are just used to set a prototype of one object to another object; and also the verify a prototype.proto: aka “dunder proto” is a property used to gain easy access to an object’s prototype – it is widely supported by browsers but is considered deprecated.
function Book(title, series, author) {
this.title = title;
this.series = series;
this.author = author;
}
// Any method defined on the `Book.prototype` property
// will be shared across all `Book` instances.
Book.prototype.getInformation = function () {
return `${this.title} by ${this.author}`;
};
const fellowshipOfTheRing = new Book(
"The Fellowship of the Ring",
"The Lord of the Rings",
"J.R.R. Tolkien"
);
console.log(fellowshipOfTheRing.getInformation());
- Every method we define on a constructor function’s prototype property will be shared across all instances of that object type.
The Problem with Arrow Functions
- We cannot use arrow functions when defining methods on a constructor function’s prototype property.
- Arrow functions don’t include their own this binding; therefore it will not reference the current instance — always stick with the function () keyword.
Putting the Class in JavaScript Classes
In ES2015, JS gained the class keyword – replacing the need to use only constructor functions & prototypes to mimic classes!
class: keyword that gives developers a formal way to create a class definition to specify an object type’s attributes and behavior; also used to create objects of that specific type.
Defining a ES2015 class
class Book {
constructor(title, series, author) {
this.title = title;
this.series = series;
this.author = author;
}
}
- Class names also begin only with capital letters.
- Although not required, class definitions can include a
class constructor function– these are similar to regular constructors in that: - They don’t explicitly return a value.
- The this keyword references the newly created object instance.
Instantiating an instance of a class
We can also use the
new.
Four things occur when instantiating an instance of a class:
- New empty object is created {};
- The new obj’s prototype is set to the class prototype’s property value.
Thisis bound to the new object.- After the constructor method has completed, the new obj is returned.
- Don’t try to instatiate a class object without the new keyword.
Class Definitions are NOT hoisted
test();
function test() {
console.log("This works!");
}
- In JS you can call a function before it’s declared — this is known as
hoisting. - Class definitions are NOT hoisted, so just get in the habit of declaring them before you use them.
Defining Methods
- A class can contain two types of methods:
Instance Method: Methods that are invoked on an instance of the class – useful for performing an action on a specific instance.- Instance methods are also sometimes referred to as
prototypemethods because they are defined on a shared prototype object. Static Method: Methods that invoked directly on a class, not on an instance.Important: Invoking a static method on an instance will result in a runtime error.- Prepending the
statickeyword at the beginning on the method name will make it static.
class Book {
constructor(title, series, author) {
this.title = title;
this.series = series;
this.author = author;
}
// Notice the use of a rest parameter (...books)
// to capture the passed parameters as an array of values.
static getTitles(...books) {
return books.map((book) => book.title);
}
getInformation() {
return `${this.title} by ${this.author}`;
}
}
const fellowshipOfTheRing = new Book(
"The Fellowship of the Ring",
"The Lord of the Rings",
"J.R.R. Tolkien"
);
const theTwoTowers = new Book(
"The Two Towers",
"The Lord of the Rings",
"J.R.R. Tolkien"
);
const bookTitles = Book.getTitles(fellowshipOfTheRing, theTwoTowers);
console.log(bookTitles.join(", ")); // The Fellowship of the Ring, The Two Towers
- If we go back to an example of how constructor functions also use static methods — we see that static methods are defined directly on the constructor function — whereas instance methods need to be defined on the prototype object.
function Book(title, series, author) {
this.title = title;
this.series = series;
this.author = author;
}
// Static methods are defined
// directly on the constructor function.
Book.getTitles = function (...books) {
return books.map((book) => book.title);
};
// Instance methods are defined
// on the constructor function's `prototype` property.
Book.prototype.getInformation = function () {
return `${this.title} by ${this.author}`;
};
const fellowshipOfTheRing = new Book(
"The Fellowship of the Ring",
"The Lord of the Rings",
"J.R.R. Tolkien"
);
const theTwoTowers = new Book(
"The Two Towers",
"The Lord of the Rings",
"J.R.R. Tolkien"
);
console.log(fellowshipOfTheRing.getInformation()); // The Fellowship of the Ring by J.R.R. Tolkien
console.log(theTwoTowers.getInformation()); // The Two Towers by J.R.R. Tolkien
// Call the static `Book.getTitles()` method
// to get an array of the book titles.
const bookTitles = Book.getTitles(fellowshipOfTheRing, theTwoTowers);
console.log(bookTitles.join(", ")); // The Fellowship of the Ring, The Two Towers
Comparing Classes to Constructor Functions
ES2015 Classes are essentially syntactic sugar over traditional constructor functions and prototypes.
Javascript Inheritance
Child Class: Class that is based upon another class and inherits properties and methods from that other class.Parent Class: Class that is being inherited downwards.Inheritance: The process of basing a class upon another class.
class CatalogItem {
constructor(title, series) {
this.title = title;
this.series = series;
}
getInformation() {
if (this.series) {
return `${this.title} (${this.series})`;
} else {
return this.title;
}
}
}
class Book extends CatalogItem {
constructor(title, series, author) {
super(title, series);
this.author = author;
}
}
class Movie extends CatalogItem {
constructor(title, series, director) {
super(title, series);
this.director = director;
}
}
const theGrapesOfWrath = new Book(
"The Grapes of Wrath",
null,
"John Steinbeck"
);
const aNewHope = new Movie(
"Episode 4: A New Hope",
"Star Wars",
"George Lucas"
);
console.log(theGrapesOfWrath.getInformation()); // The Grapes of Wrath
console.log(aNewHope.getInformation()); // Episode 4: A New Hope (Star Wars)
console.log(Catalogitem instanceof Function); // true
console.log(Book instanceof Function); // true
- A
prototype chaindefines a series of prototype objects that are delegated to one by one, when a property or method can’t be found on an instance object.
console.log(theGrapesOfWrath.getInformation()); // The Grapes of Wrath
- When the
getInformation()method is invoked: - JS looks for get() on the current object.
- If it isn’t found, the method call is delegated to the object’s prototype.
- It continues up the prototype chain until the method is found.
Overriding a method in a parent class
Method Overriding: when a child class provides an implementation of a method that’s already defined in a parent class.
class Movie extends CatalogItem {
constructor(title, series, director) {
super(title, series);
this.director = director;
}
getInformation() {
let result = super.getInformation();
if (this.director) {
result += \` \[directed by ${this.director}\]\`;
}
return result;
}
}
- We can simply declare our own method of the same name in our child class to override our parent’s version of
getInformation()
JavaScript Modules
Introducing Node.js modules
- In Node.js, each JS file in a project defines a
module. - Module’s contents are private by default.
Local Modules: Modules defined within your project.Core Modules: Native modules contained within Node.js that you can use to perform tasks or to add functionality to your application.CommonJS: A legacy module system.ES Modules: Newer module sysem that will eventually replace CommonJS.Entry Point: JS File that is passed to Node for access to the entire application.
Syntax for exporting modules:
module.exports.Book = Book; module.exports.Movie = Movie;
module.exports = { Book, Movie, };
Syntax for importing modules:
const classes = require(“./classes”);
const { Book, Movie } = require(“./classes”);
Using Single Item Modules
- Following the convention of a single exported item per module helps to keep modules focused and less likely to become bloted with too much code.
Understanding Module Loading
- When loading a module, Node will examine the identifier passed to the require() function to determine if our module is local, core, or third-party:
Local Module: identifier starts with ./ ../ or /Node.js Core: identifier matches nameThird-Party: identifier matches a module in the node modules folder (installed package)
Encapsulation
- Puts the behavior and data together behind methods that hide the specific implementation so that code that uses it doesn’t need to worry about the details of it.
Inheritance
**Implementation Inheritance**: Means that data and methods defined on a parent class are available on objects created from classes that inherit from those parent classes.**Prototypal Inheritance**: Means that JS uses prototype objects to make its**implementation inheritance**actually work.- Parent Class === Prototype === Super Class === Base Class
- Inheritance === Subtyping
class MyClass {}
// is the same as
class MyClass extends Object {}
- When you declare a class with no explicit parent class, JS will make it a child of Object.
class Charity {}
class Business {
toString() {
return "Give us your money.";
}
}
class Restaurant extends Business {
toString() {
return "Eat at Joe's!";
}
}
class AutoRepairShop extends Business {}
class Retail extends Business {
toString() {
return "Buy some stuff!";
}
}
class ClothingStore extends Retail {}
class PhoneStore extends Retail {
toString() {
return "Upgrade your perfectly good phone, now!";
}
}
console.log(new PhoneStore().toString()); // 'Upgrade your perfectly good phone, now!'
console.log(new ClothingStore().toString()); // 'Buy some stuff!';
console.log(new Restaurant().toString()); // 'Eat at Joe\'s!'
console.log(new AutoRepairShop().toString()); // 'Give us your money.'
console.log(new Charity().toString()); // [object object]
The nuts and bolts of prototypal inheritance

- When JavaScript uses a property (or method) from a prototype that it found through prototypal inheritance, then the this property points to the original object on which the first call was made.
class Parent {
constructor() {
this.name = "PARENT";
}
toString() {
return `My name is ${this.name}`;
}
}
class Child extends Parent {
constructor() {
super();
this.name = "CHILD";
}
}
const parent = new Parent();
console.log(parent.toString()); // my name is Parent
const child = new Child();
console.log(child.toString()); // my name is Child
Polymorphism
- The ability to treat an object as if it were an instance of one of its parent classes.
The SOLID Principles Explained
SOLID is an anagram for:
The Single-Responsibility PrincipleThe Open-Close PrincipleThe Liskov Substitution PrincipleThe Interface Segregation PrincipleThe Dependency Inversion Principle
Single-Responsibility Principle
A class should do one thing and do it well
- This principle is about limiting the impact of change.
The Liskov Substitution Principle:
Subtype Requirement: Let ϕ(x) be a property provable about objects x of type T. Then ϕ(y) should be true for objects y of type S where S is a subtype of T.
You can substitute child class objects for parent class objects and not cause errors.
The Other Three
- The remaining three principles are important for languages that have
static typing– which means a variable can have only one kind of thing in it. Open-Close Principle- A class is open for extension and closed for modification.
- Creating new functionality can happen in child classes, and not the original class.
Interface Segregation Principle- Method names should be grouped together into granular collections called “interfaces”.
Dependency Inversion Principle- Functionality that your class depends on should be provided as parameters to methods rather than using new in the class to create a new instance.
Controlling Coupling with The Law of Demeter
Coupling: The degree of interdependence between two or more classes.- The fewer the connections between classes, the less chance there is for the ripple effect.
- Here is the formal definition:
- A method of an object can only invoke the methods (or use the properties) of the following kind of objects:
- Methods on the object itself.
- Any of the objects passed in as parameters to the method.
- Any object created in the method.
- Any values stores in the instance variables of the object.
- Any values stored in global variables.
- Law of Demeter is more so of a guideline than a law.
- Easiest way to implement it is to not us more than one dot
- You cannot cheat by separating extra calls onto different lines.
When to ignore the Law of Demeter
- When you work with objects that come from code that you didn’t create — you will often have to break the LoD.
document
.getElementById("that-link")
.addEventListener("click", (e) => e.preventDefault());
- This breaks the law but there is way about it because your code needs to know about both elements and you have to use the API provided by the DOM.
- UI’s will break LoD because they are not object-oriented programs.
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://gist.github.com/bgoonzhttps://gist.github.com/bgoonz
Or Checkout my personal Resource Site:
https://gist.github.com/bgoonz
CODEX
Explanation for Rotate Right
Question
Write a function rotateRight(array, num) that takes in an array and a number as arguments.
The function should return a new array where the elements of the array are rotated to the right number times.
The function should not mutate the original array and instead return a new array.
Define this function using
[_function expression syntax_](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/function).
HINT: you can use Array#slice to create a copy of an array
JavaScript gives us four methods to add or remove items from the beginning or end of arrays:
pop(): Remove an item from the end of an array
let cats = ['Bob', 'Willy', 'Mini'];
cats.pop(); // ['Bob', 'Willy']
pop() returns the removed item.
push(): Add items to the end of an array
let cats = ['Bob'];
cats.push('Willy'); // ['Bob', 'Willy']
cats.push('Puff', 'George'); // ['Bob', 'Willy', 'Puff', 'George']
push() returns the new array length.
shift(): Remove an item from the beginning of an array
let cats = ['Bob', 'Willy', 'Mini'];
cats.shift(); // ['Willy', 'Mini']
shift() returns the removed item.
unshift(): Add items to the beginning of an array
let cats = ['Bob'];
cats.unshift('Willy'); // ['Willy', 'Bob']
cats.unshift('Puff', 'George'); // ['Puff', 'George', 'Willy', 'Bob']
unshift() returns the new array length.
We are being asked for two things:
- To return an array with all the elements shifted over ‘num’ times.
- To
NOTmutate the original array
Step 1.
We need to start the function and create a variable to hold a COPY of our input array.
https://gist.github.com/bgoonz/ca7a48c316345f6f7acd9383e13fb23ehttps://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/slice
- We assign array.slice(0) to a variable called result.
- Slicing our input array simply creates a sliced copy of the data.
- Remember that by excluding a second argument in our slice parameter allows us to slice from the first argument all the way to the end.
Step 2.
We need to create a for loop to tell our function how many times we want to rotate.
https://gist.github.com/bgoonz/b2a934289a677f337a72bcd7751a55df
- By setting our second delimiter to i < num we will ask our loops to run num times.
- Running num times is the same as executing the code block within num times.
Step 3.
We need to put some executable code within our for loop to be run during every cycle.
https://gist.github.com/bgoonz/44e66960ba5cc0ffe04ea0499f7c3134
- Since we are rotating to the right, every change to our result array under the hood will look like this (if we ref. our first test case):
['a', 'b', 'c', 'd', 'e'];(how it looks like at the start)['e', 'a', 'b', 'c', 'd'];(after one run of the for loop)['d', 'e', 'a', 'b', 'c'];(after second/last run of the for loop)- To accomplish this we first need to ‘
pop‘ off or remove our last element. - Two things happen when we use this built-in function.
- Our copied array is mutated to lose it’s last ele.
- The removed element is stored in the variable we assigned to the function.
- Our second step is to add it to the start of our array, to do this we can use
unshift. - By inputting the variable we are using to hold our removed element into the parameter of unshift we are adding our element to the front of the array.
Step 4.
Now that our for loop has ended and our copied array looks just like how the answer looks, we need to output the answer.
https://gist.github.com/bgoonz/b033f820c35869af0869ce712af68bda
- We accomplish this by creating a
returnline AFTER the for loop.
End Result
https://gist.github.com/bgoonz/4e2a040cd94006bb887a77a68f4287b9
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/slicehttps://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/slice
Or Checkout my personal Resource Site:
==>currently under development & very buggy
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/slice
What is HTML, CSS & JS and why do we need all three?

HTML stands for “Hypertext Markup Language”. Basically, HTML is the structure for the website, words, bullet points, data tables, etc. CSS stands for “Cascading Style Sheets” which means it’s the “Style” it’s how to make your website look professional, and look visually appealing. JS is how to make your website actually **work**.
For example, if you created something like YouTube and one of the options you can watch videos, you used HTML for the title, you used CSS for the color/s, and you have to make it actually work! So when you click on it it will run the video. This is an example of the three programming languages working in unison to form an experience you’re already familiar with if you’re reading this…
I mean most likely… unless you printed it because you hate trees.
— — — — — — — — — — -
What are Tags and Attributes?
Tags and attributes are the basis of HTML.
They work together but perform different functions — it is worth investing 2 minutes in differentiating the two.
What Are HTML Tags?
Tags are used to mark up the start of an HTML element and they are usually enclosed in angle brackets. An example of a tag is: <h1>.
Most tags must be opened <h1> and closed </h1> in order to function.
What are HTML Attributes?
Attributes contain additional pieces of information. Attributes take the form of an opening tag and additional info is placed inside.
An example of an attribute is:
<img src="mydog.jpg" alt="A photo of my dog.">
In this instance, the image source (src) and the alt text (alt) are attributes of the <img> tag.
Golden Rules To Remember
- The vast majority of tags must be opened (
<tag>) and closed (</tag>) with the element information such as a title or text resting between the tags. - When using multiple tags, the tags must be closed in the order in which they were opened. For example:
<strong><em>This is really important!</em></strong>
Let’s have a look at how CodePen works, firstly, you need to go to their website. After that, you must create an account. After you do that, You will see something like this
How to get started
If you’re using Visual Studio Code, congrats! There is Emmet support built into VSCode, so you won’t need to install any extensions. If you’re working in Atom you’ll need to install the Emmet plugin, which can be found here.
Basic Syntax
HTML Boilerplate
If you’ve been working in VSCode, you’ve probably seen Emmet syntax highlighting when working in HTML documents. In my opinion, the most convenient Emmet shortcut is html:5. This will create an HTML boilerplate, and fill out metadata tags in the head of your document.
html:5
Emmet Abbreviation for different HTML boilerplates.
When you see the auto complete as pictured above you can hit tab to auto fill the boilerplate html document.
That one small shortcut autogenerates all this metadata and head and body tags:
Here’s some slightly more advanced boilerplate for you to use as a starting point in your projects.
https://gist.github.com/bgoonz/b0aae5c4079596820e37c98265f45539
HTML Language
Chapter 1: Formatting text
Tags in HTML: Tags are one of the most important parts in an HTML document. (We will get to what HTML document is after we know what tags are). HTML uses some predefined tags which tells the browser about content display property, that is how to display a particular given content. For Example, to create a paragraph, one must use the paragraph tags(
) and to insert an image one must use the img tags(
There are generally two types of tags in HTML:
- Paired tags: These tags come in pairs. That is they have both opening (< >) and closing(</ >) tags.
- Singular tags: These tags do not required to be closed
i.e.
The tag above me is a horizontal line that doesn't need a closing tag
HTML tags have two main types: block-level and inline tags.
- Block-level elements take up the full available space and always start a new line in the document. Headings and paragraphs are a great example of block tags.
- Inline elements only take up as much space as they need and don’t start a new line on the page. They usually serve to format the inner contents of block-level elements. Links and emphasized strings are good examples of inline tags.
Block-Level Tags
The three block level tags every HTML document needs to contain are , , and .
- The tag is the highest level element that encloses every HTML page.
- The tag holds meta information such as the page’s title and charset.
- Finally, the tag encloses all the content that appears on the page.
- Paragraphs are enclosed by , while blockquotes use the tag.
- Divisions are bigger content sections that typically contain several paragraphs, images, sometimes blockquotes, and other smaller elements. We can mark them up using the tag. A div element can contain another div tag inside it as well.
- You may also use
- List item 1
- List item 2
- List item 3
Structure of an HTML Document
An HTML Document is mainly divided into two parts:
- HEAD: This contains the information about the HTML document. For Example, Title of the page, version of HTML, Meta-Data etc.
HTML TAG Specifies an html document. The HTML element (or HTML root element) represents the root of an HTML document. All other elements must be descendants of this element. Since the element is the first in a document, it is called the root element.
Although this tag can be implied, or not required, with HTML, it is required to be opened and closed in XHTML.
- Divisions are bigger content sections that typically contain several paragraphs, images, sometimes blockquotes, and other smaller elements. We can mark them up using the tag. A div element can contain another div tag inside it as well.
- You may also use
- List item 1
- List item 2
- List item 3
Inline Tags
Many inline tags are used to format text. For example, a tag would render an element in bold, whereas tags would show it in italics.
Hyperlinks are also inline elements that require tags and href attributes to indicate the link’s destination:
- <a href=”https://example.com/”**\>**Click me!
Images are inline elements too. You can add one using without any closing tag. But you will also need to use the src attribute to specify the image path, for example:
- <img src=”/images/example.jpg” alt=”Example image”>
BODY: This contains everything you want to display on the Web Page.
<! — Everything the user sees on the webpage goes here! — ps… this is a comment →
Let us now have a look on the basic structure of HTML. That is the code which is must for every webpage to have:
Here is some boilerplate html you can use as a starting point:!!Every Webpage must contain this code.!!
Below is the complete explanation of each of the tags used in the above piece of HTML code:
: This tag is used to tells the HTML version. This currently tells that the version is HTML 5.
: This is called HTML root element and used to wrap all the code.
: Head tag contains metadata, title, page CSS etc. All the HTML elements that can be used inside the
element are:
: Body tag is used to enclosed all the data which a web page has from texts to links. All of the content that you see rendered in the browser is contained within this element.
Bold Text:
this is bold
⇐ this is for strong, emergency emotions.
___________
HEADING/S:
6 types from largest(h1) to smallest (h6)
___________
ITALICS: There are two ways to use it, the first one is the tag and the second one is the tag. They both italicize the text
this is fancy text that’s too good to for us
___________
PARAGRAPHS: In order to make Paragraphs, just add
.
Hi there my name is Jason.
___________
TITLES: not the same thing as a heading (which renders on the html page) but instead the title element represents the title of the page as shown in the tab of the browser.
As such
Here’s a handy Cheat Sheet:

Below I am going to Include a gist that contains html code that uses pretty much every tag I could think of off the top of my head…
If it’s not included here I promise you it’s seldom used by most webpages.
Below that I will embed an image of the webpage that it renders too….
that super small text at the bottom is actually one giant button:
https://gist.github.com/bgoonz/b13743e00e7684ca220f66635803a7d5
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://gist.github.com/bgoonzhttps://gist.github.com/bgoonz
Or Checkout my personal Resource Site:
https://gist.github.com/bgoonz
CODEX
For Front end developers who like myself struggle with making the jump to fullstack.
You can access and query the data using the findByPk, findOne, and findAll methods.
Terminology:
- NodeJS We re going to use this to run JavaScript code on the server. I ve decided to use the latest version of Node, v6.3.0 at the time of writing, so that we ll have access to most of the new features introduced in ES6.
- Express As per their website, Express is a Fast, unopinionated, minimalist web framework for Node.js , that we re going to be building our Todo list application on.
- PostgreSQL This is a powerful open-source database that we re going to use. I ve attached an article I published on the setup below!
- However, if you face issues while installing PostgreSQL, or you don t want to dive into installing it, you can opt for a version of PostgreSQL hosted online. I recommend ElephantSQL. I found it s pretty easy to get started with. However, the free version will only give you a 20MB allowance.
- Sequelize In addition, we re going to use Sequelize, which is a database ORM that will interface with the Postgres database for us.
RDBMS and Database Entities
Define what a relational database management system is
- RDBMS stands for Relational Database Management System
- A software application that you run that your programs can connect to so that they can store, modify, and retrieve data.
- An RDBMS can track many databases. We will use PostgreSQL, or postgres , primarily for our RDBMS and it will be able to create individual databases for each of our projects.
Describe what relational data is
- In general, relational data is information that is connected to other pieces of information.
- When working with relational databases, we can connect two entries together utilizing foreign keys (explained below).
- In a pets database, we could be keeping track of dogs and cats as well as the toys that each of them own. That ownership of a cat to a toy is the relational aspect of relational data. Two pieces of information that can be connected together to show some sort of meaning.
Define what a database is
- The actual location that data is stored.
- A database can be made up of many tables that each store specific kinds of information.
- We could have a pets database that stores information about many different types of animals. Each animal type could potentially be represented by a different table.
Define what a database table is
- Within a database, a table stores one specific kind of information.
- The records (entries) on these tables can be connected to records on other tables through the use of foreign keys
- In our pets database, we could have a dogs table, with individual records
Describe the purpose of a primary key
- A primary key is used in the database as a unique identifier for the table.
- We often use an id field that simply increments with each entry. The incrementing ensures that each record has a unique identifier, even if their are other fields of the record that are repeated (two people with the same name would still need to have a unique identifier, for example).
- With a unique identifier, we can easily connect records within the table to records from other tables.
Describe the purpose of a foreign key
- A foreign key is used as the connector from this record to the primary key of another table s record.
- In our pets example, we can imagine two tables to demonstrate: a table to represent cats and a table to represent toys. Each of these tables has a primary key of id that is used as the unique identifier. In order to make a connection between a toy and a cat, we can add another field to the cat table called ownerid , indicating that it is a foreign key for the cat table. By setting a toy s ownerid to the same value as a particular cat s id , we can indicate that the cat is the owner of that toy.
Describe how to properly name things in PostgreSQL
- Names within postgres should generally consist of only lowercase letters, numbers, and underscores.
- Tables within a database are plural by convention, so a table for cats would typically be cats and office locations would be office_locations (all lowercase, underscores to replace spaces, plural)
Connect to an instance of PostgreSQL with the command line tool psql
- The psql command by default will try to connect to a database and username that matches your system s username
- We connect to a different database by providing an argument to the psql command
- psql pets
- To connect with a different username we can use the -U flag followed by the username we would like to use. To connect to the pets database as pets_user
- psql -U pets_user pets
- If there is a password for the user, we can tell psql that we would like a prompt for the password to show up by using the -W flag.
- psql -U petsuser -W pets (the order of our flags doesn t matter, as long as any arguments associated with them are together, such as petsuser directly following -U in this example)
Identify whether a user is a normal user or a superuser by the prompt in the psql shell
- You can tell if you are logged in as a superuser or normal user by the prompt in the terminal.
- If the prompt shows =>, the user is a normal user
- If the prompt show =#, the user is a superuser
Create a user for the relational database management system
- Within psql, we can create a user with the CREATE USER {username} {WITH options} command.
- The most common options we ll want to use are WITH PASSWORD ‘mypassword’ to provide a password for the user we are creating, CREATEDB to allow the user to create new databases, or SUPERUSER to create a user with all elevated permissions.
Create a database in the database management system
- We can use the command CREATE DATABASE {database name} {options} inside psql to create a new database.
- A popular option we may utilize is WITH OWNER {owner name} to set another user as the owner of the database we are making.
Configure a database so that only the owner (and superusers) can connect to it
- We can GRANT and REVOKE privileges from a database to users or categories of users.
- In order to remove connection privileges to a database from the public we can use REVOKE CONNECT ON DATABASE {db_name} FROM PUBLIC;, removing all public connection access.
- If we wanted to grant it back, or to a specific user, we could similarly do GRANT CONNECT ON DATABASE {db_name} FROM {specific user, PUBLIC, etc.};
View a list of databases in an installation of PostgreSQL
- To list all databases we can use the \l or \list command in psql.
Create tables in a database
CREATE TABLE {table name} (
{columnA} {typeA},
{columnB} {typeB},
etc…
);
- The whitespace does not matter. Creating the SQL statements on multiple lines is easier to read, but just like JavaScript, they can be presented differently.
- One common issue is that SQL does not like trailing commas, so the last column cannot have a comma after its type in this example.
View a list of tables in a database
- To list all database tables, use the \dt command.
Identify and describe the common data types used in PostgreSQL
- There are many different data types that we can use in our tables, here are some common examples:
- SERIAL: autoincrementing, very useful for IDs
- VARCHAR(n): a string with a character limit of n
- TEXT: doesn t have character limit, but less performant
- BOOLEAN: true/false
- SMALLINT: signed two-byte integer (-32768 to 32767)
- INTEGER: signed four-byte integer (standard)
- BIGINT: signed eight-byte integer (very large numbers)
- NUMERIC: or DECIMAL, can store exact decimal values
- TIMESTAMP: date and time
Describe the purpose of the UNIQUE and NOT NULL constraints, and create columns in database tables that have them
- In addition to the data type, we can provide flags for constraints to place on our column data.
- The UNIQUE flag indicates that the data for the column must not be repeated.
- By default we can create entries in our tables that are missing data from columns. When creating a pet, maybe we don t provide an age because we don t know it, for example. If we want to require that the data be present in order to create a new record, we can indicate that column must be NOT NULL.
- In the example below, we are requiring our pets to have unique names and for them to be present (both UNIQUE and NOT NULL). We have no such constraints on the age column, allowing repetition of ages or their complete absence.
CREATE TABLE pets (
id SERIAL PRIMARY KEY,
name VARCHAR(255) UNIQUE NOT NULL,
age SMALLINT
);
Create a primary key for a table
- When creating a table we can indicate the primary key by passing in the column name to parentheses like so:
CREATE TABLE people (
id SERIAL,
firstname VARCHAR(50),
lastname VARCHAR(50),
PRIMARY KEY (id)
);
- We could have also used the PRIMARY KEY flag on the column definition itself:
CREATE TABLE people (
id SERIAL PRIMARY KEY,
firstname VARCHAR(50),
lastname VARCHAR(50)
);
Create foreign key constraints to relate tables
- In our table definition, we can use the line FOREIGN KEY (foreignkeystoredinthistable) REFERENCE {other table} ({othertableskeyname}) to connect two tables.
- This is probably easier to see in an example:
CREATE TABLE people (
id SERIAL PRIMARY KEY,
firstname VARCHAR(50),
lastname VARCHAR(50)
);
CREATE TABLE pets (
id SERIAL PRIMARY KEY,
name VARCHAR(255),
age SMALLINT,
personid INTEGER,
FOREIGN KEY (personid) REFERENCES people (id)
);
SQL is not case sensitive for its keywords but is for its entity names
- Exactly as the LO states, CREATE TABLE and create table are interpreted the same way. Using capitalization is a good convention in order to distinguish your keywords.
- The entity names that we use ARE case-sensitive, however. So a table named pets is unique from a table named Pets. In general, we prefer to use all lowercase for our entities to avoid any of this confusion.
SQL
1. How to use the SELECT … FROM … statement to select data from a single table
- Supply the column names in the SELECT clause. If we want all columns, we can also use *
- Supply the table names in the FROM clause
— Selects all columns from the friends table
SELECT
*
FROM
friends;
— Selects the first_name column from the friends table (remember whitespace is ignored)
SELECT name
FROM friends;
- Sometimes we may need to specify what table we are selecting a column from, particulurly if we had joined multiple tables together.
— Notice here we are indicating that we want the “name” field from the “friends” table as well as the “name” field from the “puppies” table. We indicate the table name by table.column
— We are also aliasing these fields with the AS keyword so that our returned results have friendname and puppyname as field headers
SELECT
friends.name AS friendname , puppies.name AS puppyname
FROM
friends
JOIN
puppies ON friends.puppy_id = puppies.id
How to use the WHERE clause on SELECT, UPDATE, and DELETE statements to narrow the scope of the command
- The WHERE clause allows us to select or apply actions to records that match specific criteria instead of to a whole table.
- We can use WHERE with a couple of different operators when making our comparison
- WHERE {column} = {value} provides an exact comparison
- WHERE {column} IN ({value1}, {value2}, {value3}, etc.) matches any provided value in the IN statement. We can make this more complex by having a subquery inside of the parentheses, having our column match any values within the returned results.
- WHERE {column} BETWEEN {value1} AND {value2} can check for matches between two values (numeric ranges)
- WHERE {column} LIKE {pattern} can check for matches to a string. This is most useful when we use the wildcard %, such as WHERE breed LIKE ‘%Shepherd’, which will match any breed that ends in Shepherd
- The NOT operator can also be used for negation in the checks.
- Mathematical operators can be used when performing calculations or comparisons within a query as well, such as
SELECT name, breed, weightlbs FROM puppies WHERE weightlbs > 50; — OR SELECT name, breed, ageyrs FROM puppies WHERE ageyrs * 10 = 5;
How to use the JOIN keyword to join two (or more) tables together into a single virtual table
- When we want to get information from a related table or do querying based on related table values, we can join the connected table by comparing the foreign key to where it lines up on the other table:
— Here we are joining the puppies table on to the friends table. We are specifying that the comparison we should make is the foreign key puppy_id on the friends table should line up with the primary key id on the puppies table.
SELECT
*
FROM
friends
JOIN
puppies ON friends.puppy_id = puppies.id
How to use the INSERT statement to insert data into a table
- When a table is already created we can then insert records into it using the INSERT INTO keywords.
- We provide the name of the table that we would like to add records to, followed by the VALUES keyword and each record we are adding. Here s an example:
— We are providing the table name, then multiple records to insert
— The values are listed in the order that they are defined on the table
INSERT INTO tablename
VALUES
(column1value, colum2value, column3value),
(column1value, colum2value, column3value),
(column1value, colum2value, column3value);
- We can also specify columns when we are inserting data. This makes it clear which fields we are providing data for and allows us to provide them out of order, skip null or default values, etc.
— In this example, we want to use the default value for id since it is autoincremented, so we provide DEFAULT for this field
INSERT INTO friends (id, firstname, lastname)
VALUES
(DEFAULT, ‘Amy’, ‘Pond’);
— Alternatively, we can leave it out completely, since the default value will be used if none is provided
INSERT INTO friends (firstname, lastname)
VALUES
(‘Rose’, ‘Tyler’),
(‘Martha’, ‘Jones’),
(‘Donna’, ‘Noble’),
(‘River’, ‘Song’);
How to use an UPDATE statement to update data in a table
- The UPDATE keyword can be used to find records and change their values in our database.
- We generally follow the pattern of UPDATE {table} SET {column} = {new value} WHERE {match condition};.
- Without a condition to narrow our records down, we will update every record in the table, so this is an important thing to double check!
- We can update multiple fields as well by specifying each column in parentheses and their associated new values: UPDATE {table} SET ({column1}, {column2}) = ({value1}, {value2}) WHERE {match condition};
— Updates the pet with id of 4 to change their name and breed
UPDATE
pets
SET
(name, breed) = (‘Floofy’, ‘Fluffy Dog Breed’) WHERE id = 4;
How to use a DELETE statement to remove data from a table
- Similar to selecting records, we can delete records from a table by specifying what table we are deleting from and what criteria we would like to match in order to delete.
- We follow the general structure DELETE FROM {table} WHERE {condition};
- The condition here is also very important! Without a condition, all records match and will be deleted.
— Deletes from the pets table any record that either has a name Floofy, a name Doggo, or an id of 3.
DELETE FROM
pets
WHERE
name IN (‘Floofy’, ‘Doggo’) OR id = 3;
How to use a seed file to populate data in a database
- Seed files are a great way for us to create records that we want to start our database out with.
- Instead of having to individually add records to our tables or manually entering them in psql or postbird, we can create a file that has all of these records and then just pass this file to psql to run.
- Seed files are also great if we ever need to reset our database. We can clear out any records that we have by dropping all of our tables, then just run our seed files to get it into a predetermined starting point. This is great for our personal projects, testing environments, starting values for new tables we create, etc.
- There are two main ways we can use a seed file with psql, the < and the | operators. They perform the same function for us, just in slightly different orders, taking the content of a .sql file and executing in within the psql environment:
- psql -d {database} < {sql filepath}
- cat {sql filepath} | psql -d {database}
SQL (continued)
How to perform relational database design
- Steps to Designing the Database:
- Define the entities. What data are are you storing, what are the fields for each entity?
- You can think of this in similar ways to OOP (object oriented programming).
- If you wanted to model this information using classes, what classes would you make? Those are generally going to be the tables that are created in your database.
- The attributes of your classes are generally going to be the fields/columns that we need for each table.
- Identify primary keys. Most of the time these will be ids that you can generate as a serial field, incrementing with each addition to the database.
- Establish table relationships. Connect related data together with foreign keys. Know how we store these keys in a one-to-one, one-to-many, or many-to-many relationship.
- With a one-to-one or one-to-many relationship, we are able to use a foreign key on the table to indicate the other specific record that it is connected to.
- With a many-to-many relationship, each record could be connected to multiple records, so we have to create a join table to connect these entities. A record on this join table connects a record from one table to a record from another table.
How to use transactions to group multiple SQL commands into one succeed or fail operation
- We can define an explicit transaction using BEGIN and ending with either COMMIT or ROLLBACK.
- If any command inside the block fails, everything will be rolled back. We can also specify that we want to roll back at the end of the block instead of committing. We saw that this can be useful when analyzing operations that would manipulate our database.
BEGIN;
UPDATE accounts SET balance = balance — 100.00
WHERE name = ‘Alice’;
UPDATE branches SET balance = balance — 100.00
WHERE name = (SELECT branchname FROM accounts WHERE name = ‘Alice’);
UPDATE accounts SET balance = balance + 100.00
WHERE name = ‘Bob’;
UPDATE branches SET balance = balance + 100.00
WHERE name = (SELECT branchname FROM accounts WHERE name = ‘Bob’);
COMMIT;
BEGIN;
EXPLAIN ANALYZE
UPDATE cities
SET city = ‘New York City’
WHERE city = ‘New York’;
ROLLBACK;
How to apply indexes to tables to improve performance
- An index can help optimize queries that we have to run regularly. If we are constantly looking up records in a table by a particular field (such as username or phone number), we can add an index in order to speed up this process.
- An index maintains a sorted version of the field with a reference to the record that it points to in the table (via primary key). If we want to find a record based on a field that we have an index for, we can look through this index in a more efficient manner than having to scan through the entire table (generally O(log n) since the index is sorted, instead of O(n) for a sequential scan).
- To add an index to a field we can use the following syntax:
CREATE INDEX indexname ON tablename (column_name);
- To drop an index we can do the following:
DROP INDEX index_name
- Making an index is not always the best approach. Indices allow for faster lookup, but slow down record insertion and the updating of associated fields, since we not only have to add the information to the table, but also manipulate the index.
- We generally wouldn t care about adding an index if:
- The tables are small
- We are updating the table frequently, especially the associated columns
- The column has many NULL values
Explain what the EXPLAIN command is used for:
- EXPLAIN gives us information about how a query will run (the query plan)
- It gives us an idea of how our database will search for data as well as a qualitative comparitor for how expensive that operation will be. Comparing the cost of two queries will tell us which one is more efficient (lower cost).
- We can also use the ANALYZE command with EXPLAIN, which will actually run the specified query. Doing so gives us more detailed information, such as the milliseconds it took our query to execute as well as specifics like the exact number of rows filtered and returned.
1. Demonstrate how to install and use the node-postgres library and its Pool class to query a PostgreSQL-managed database
- We can add the node-postgres library to our application with npm install pg. From there we will typically use the Pool class associated with this library. That way we can run many SQL queries with one database connection (as opposed to Client, which closes the connection after a query).
const { Pool } = require(‘pg’);
// If we need to specify a username, password, or database, we can do so when we create a Pool instance, otherwise the default values for logging in to psql are used:
const pool = new Pool({ username: ‘<
- The query method on the Pool instance will allow us to execute a SQL query on our database. We can pass in a string that represents the query we want to run
const allAirportsSql = `
SELECT id, cityid, faaid, name
FROM airports;
`;
async function selectAllAirports() {
const results = await pool.query(allAirportsSql);
console.log(results.rows);
pool.end(); // invoking end() will close our connection to the database
}
selectAllAirports();
- The return value of this asynchronous function is an object with a rows key that points to an array of objects, each object representing a record with field names as keys.
Explain how to write prepared statements with placeholders for parameters of the form $1 , $2 , and so on
- The prepared statement (SQL string that we wrote) can also be made more dynamic by allowing for parameters to be passed in.
- The Pool instance s query function allows us to pass a second argument, an array of parameters to be used in the query string. The location of the parameter substitutions are designated with $1, $2, etc., to signify the first, second, etc., arguments.
const airportsByNameSql = `
SELECT name, faa_id
FROM airports
WHERE UPPER(name) LIKE UPPER($1)
`;
async function selectAirportsByName(name) {
const results = await pool.query(airportsByNameSql, [ `%${name}%` ]);
console.log(results.rows);
pool.end(); // invoking end() will close our connection to the database
}
// Get the airport name from the command line and store it
// in the variable “name”. Pass that value to the
// selectAirportsByName function.
const name = process.argv[2];
// console.log(name);
selectAirportsByName(name);
ORM
1. How to install, configure, and use Sequelize, an ORM for JavaScript
- To start a new project we use our standard npm initialize statement
- npm init -y
- Add in the packages we will need (sequelize, sequelize-cli, and pg)
- npm install sequelize@⁵.0.0 sequelize-cli@⁵.0.0 pg@⁸.0.0
- Initialize sequelize in our project
- npx sequelize-cli init
- Create a database user with credentials we will use for the project
- psql
- CREATE USER example_user WITH PASSWORD ‘badpassword’
- Here we can also create databases since we are already in postgres
CREATE DATABASE exampleappdevelopment WITH OWNER example_user
CREATE DATABASE exampleapptest WITH OWNER example_user
CREATE DATABASE exampleappproduction WITH OWNER example_user
- If we don t create these databases now, we could also create them after we make our changes to our config file. If we take this approach, we need to make sure our user that we created has the CREATEDB option when we make them, since sequelize will attempt to make the databases with this user. This other approach would look like:
- In psql: CREATE USER example_user WITH PASSWORD ‘badpassword’ CREATEDB
- In terminal: npx sequelize-cli db:create
- Double check that our configuration file matches our username, password, database, dialect, and seederStorage (these will be filled out for you in an assessment scenario):
{
“development”: {
“username”: “sequelizerecipeboxapp”,
“password”: “HfKfK79k”,
“database”: “recipeboxdevelopment”,
“host”: “127.0.0.1”,
“dialect”: “postgres”,
“seederStorage”: “sequelize”
},
“test”: {
“username”: “sequelizerecipeboxapp”,
“password”: “HfKfK79k”,
“database”: “recipeboxtest”,
“host”: “127.0.0.1”,
“dialect”: “postgres”,
“seederStorage”: “sequelize”
},
“production”: {
“username”: “sequelizerecipeboxapp”,
“password”: “HfKfK79k”,
“database”: “recipebox_production”,
“host”: “127.0.0.1”,
“dialect”: “postgres”,
“seederStorage”: “sequelize”
}
}
1. How to use database migrations to make your database grow with your application in a source-control enabled way
Migrations
- In order to make new database tables and sequelize models that reflect them, we want to generate a migration file and model file using model:generate
npx sequelize-cli model:generate — name Cat — attributes “firstName:string,specialSkill:string”
- Here we are creating a migration file and a model file for a Cat. We are specifying that we want this table to have fields for firstName and specialSkill. Sequelize will automatically make fields for an id, createdAt, and updatedAt, as well, so we do not need to specify these.
- Once our migration file is created, we can go in and edit any details that we need to. Most often we will want to add in database constraints such as allowNull: false, adding a uniqueness constraint with unique: true, adding in character limits to fields such as type: Sequelize.STRING(100), or specifying a foreign key with references to another table references: { model: ‘Categories’ }.
- After we make any necessary changes to our migration file, we need to perform the migration, which will run the SQL commands to actually create the table.
npx sequelize-cli db:migrate
- This command runs any migration files that have not been previously run, in the order that they were created (this is why the timestamp in the file name is important)
- If we realize that we made a mistake after migrating, we can undo our previous migration, or all of our migrations. After undoing them, we can make any changes necessary to our migration files (They won t be deleted from the undo, so we don t need to generate anything! Just make the necessary changes to the files that already exist and save the files.). Running the migrations again will make the tables with the updates reflected.
npx sequelize-cli db:migrate:undo
npx sequelize-cli db:migrate:undo:all
Models Validations and Associations
- In addition to the migration files, our model:generate command also created a model file for us. This file is what allows sequelize to transform the results of its SQL queries into useful JavaScript objects for us.
- The model is where we can specify a validation that we want to perform before trying to run a SQL query. If the validation fails, we can respond with a message instead of running the query, which can be an expensive operation that we know won t work.
// Before we make changes, sequelize generates the type that this field represents specification:
DataTypes.TEXT
// We can replace the generated format with an object to specify not only the type, but the validations that we want to implement. The validations can also take in messages the respond with on failure and arguments.
specification: {
type: DataTypes.TEXT,
validate: {
notEmpty: {
msg: 'The specification cannot be empty'
},
len: {
args: [10, 100]
msg: 'The specifcation must be between 10 and 100 characters'
}
}
}
- Another key part of the model file is setting up our associations. We can use the belongsTo, hasMany, and belongsToMany methods to set up model-level associations. Doing so is what creates the helpful functionality like addOwner that we saw in the pets example, a function that automatically generates the SQL necessary to create a petOwner record and supplies the appropriate petId and ownerId.
- In a one-to-many association, we need to have a belongsTo association on the many side, and a hasMany association on the one side:
- Instruction.belongsTo(models.Recipe, { foreignKey: ‘recipeId’ });
- Recipe.hasMany(models.Instruction, { foreignKey: ‘recipeId’ });
- In a many-to-many association, we need to have a belongsToMany on each side of the association. We generally specify a columnMapping object to show the association more clearly:
// In our Owner model
// To connect this Owner to a Pet through the PetOwner
const columnMapping = {
through: ‘PetOwner’,
// joins table
otherKey: ‘petId’,
// key that connects to other table we have a many association with foreignKey: ‘ownerId’
// our foreign key in the joins table
}
Owner.belongsToMany( models.Pet, columnMapping );
// In our Pet model
// To connect this Pet to an Owner through the PetOwner
const columnMapping = { through: ‘PetOwner’,
// joins table
otherKey: ‘ownerId’,
// key that connects to other table we have a many association with
foreignKey: ‘petId’
// our foreign key in the joins table
}
Pet.belongsToMany( models.Owner, columnMapping );
How to perform CRUD operations with Sequelize
- Seed Files
- Seed files can be used to populate our database with starter data.
- npx sequelize-cli seed:generate — name add-cats
- up indicates what to create when we seed our database, down indicates what to delete if we want to unseed the database.
- For our up, we use the queryInterface.bulkInsert() method, which takes in the name of the table to seed and an array of objects representing the records we want to create:
up: (queryInterface, Sequelize) => {
return queryInterface.bulkInsert('<
field1: value1a,
field2: value2a
}, {
field1: value1b,
field2: value2b
}, {
field1: value1c,
field2: value2c
}]);
}
- For our down, we use the queryInterface.bulkDelete() method, which takes in the name of the table and an object representing our WHERE clause. Unseeding will delete all records from the specified table that match the WHERE clause.
// If we want to specify what to remove:
down: (queryInterface, Sequelize) => {
return queryInterface.bulkDelete(‘<
field1: [value1a, value1b, value1c], //…etc.
});
};
// If we want to remove everything from the table:
down: (queryInterface, Sequelize) => {
return queryInterface.bulkDelete(‘<
};
- Running npx sequelize-cli db:seed:all will run all of our seeder files.
- npx sequelize-cli db:seed:undo:all will undo all of our seeding.
- If we omit the :all we can run specific seed files
- Inserting with Build and Create
- In addition to seed files, which we generally use for starter data, we can create new records in our database by using build and save, or the combined create
- Use the .build method of the Cat model to create a new Cat instance in index.js
// Constructs an instance of the JavaScript `Cat` class. **Does not
// save anything to the database yet**. Attributes are passed in as a
// POJO.
const newCat = Cat.build({
firstName: 'Markov',
specialSkill: 'sleeping',
age: 5
});
// This actually creates a new `Cats` record in the database. We must
// wait for this asynchronous operation to succeed.
await newCat.save();
// This builds and saves all in one step. If we don't need to perform any operations on the instance before saving it, this can optimize our code.
const newerCat = await Cat.create({
firstName: 'Whiskers',
specialSkill: 'sleeping',
age: 2
})
Updating Records
- When we have a reference to an instance of a model (i.e. after we have queried for it or created it), we can update values by simply reassigning those fields and using the save method
Deleting Records
- When we have a reference to an instance of a model, we can delete that record by using destroy
- const cat = await Cat.findByPk(1); // Remove the Markov record. await cat.destroy();
- We can also call destroy on the model itself. By passing in an object that specifies a where clause, we can destroy all records that match that query
- await Cat.destroy({ where: { specialSkill: ‘jumping’ } });
How to query using Sequelize
findAll
const cats = await Cat.findAll();
// Log the fetched cats.
// The extra arguments to stringify are a replacer and a space respectively
// Here we're specifying a space of 2 in order to print more legibly
// We don't want a replacer, so we pass null just so that we can pass a 3rd argument
console.log(JSON.stringify(cats, null, 2));
WHERE clause
- Passing an object to findAll can add on clauses to our query
- The where key takes an object as a value to indicate what we are filtering by
- { where: { field: value } } => WHERE field = value
const cats = await Cat.findAll({ where: { firstName: “Markov” } }); console.log(JSON.stringify(cats, null, 2));
OR in the WHERE clause
- Using an array for the value tells sequelize we want to match any of these values
{ where: { field: [value1, value2] } => WHERE field IN (value1, value2)
const cats = await Cat.findAll({ where: { firstName: [“Markov”, “Curie”] } });const cats = await Cat.findAll({
where: {
firstName: "Markov",
age: 4
}
});
console.log(JSON.stringify(cats, null, 2));
console.log(JSON.stringify(cats, null, 2));
AND in the WHERE clause
- Providing additional key/value pairs to the where object indicates all filters must match
- { where: { field1: value1, field2: value2 } } => WHERE field1 = value1 AND field2 = value2
Sequelize Op operator
- By requiring Op from the sequelize library we can provide more advanced comparison operators
- const { Op } = require(“sequelize”);
- Op.ne: Not equal operator
const cats = await Cat.findAll({
where: {
firstName: {
// All cats where the name is not equal to "Markov"
// We use brackets in order to evaluate Op.ne and use the value as the key
[Op.ne]: "Markov"
},
},
});
console.log(JSON.stringify(cats, null, 2));
Op.and: and operator
const cats = await Cat.findAll({
where: {
// The array that Op.and points to must all be true
// Here, we find cats where the name is not "Markov" and the age is 4
[Op.and]: [{
firstName: {
[Op.ne]: "Markov"
}
}, {
age: 4
}, ],
},
});
console.log(JSON.stringify(cats, null, 2));
Op.or: or operator
const cats = await Cat.findAll({
where: {
// One condition in the array that Op.or points to must be true
// Here, we find cats where the name is "Markov" or where the age is 4
[Op.or]: [{
firstName: "Markov"
}, {
age: 4
}, ],
},
});
console.log(JSON.stringify(cats, null, 2));
Op.gt and Op.lt: greater than and less than operators
const cats = await Cat.findAll({ where: { // Find all cats where the age is greater than 4 age: { [Op.gt]: 4 }, } }, }); console.log(JSON.stringify(cats, null, 2));
Ordering results
- Just like the where clause, we can pass an order key to specify we want our results ordered
- The key order points to an array with the fields that we want to order by
- By default, the order is ascending, just like standard SQL. If we want to specify descending, we can instead use a nested array with the field name as the first element and DESC as the second element. (We could also specify ASC as a second element in a nested array, but it is unnecessary as it is default)
- const cats = await Cat.findAll({ // Order by age descending, then by firstName ascending if cats have the same age order: [[“age”, “DESC”], “firstName”], }); console.log(JSON.stringify(cats, null, 2));
// Get a reference to the cat record that we want to update (here just the cat with primary key of 1)
const cat = await Cat.findByPk(1);
// Change cat's attributes.
cat.firstName = "Curie";
cat.specialSkill = "jumping";
cat.age = 123;
// Save the new name to the database.
await cat.save();
- Limiting results
- We can provide a limit key in order to limit our results to a specified number
const cats = await Cat.findAll({
order: [
["age", "DESC"]
],
// Here we are limiting our results to one record. It will still return an array, just with one object inside. We could have said any number here, the result is always an array.
limit: 1,
});
console.log(JSON.stringify(cats, null, 2));
findOne
- If we only want one record to be returned we can use findOne instead of findAll
- If multiple records would have matched our findOne query, it will return the first record
- Unlike findAll, findOne will return the object directly instead of an array. If no records matched the query it will return null.
// finds the oldest cat const cat = await Cat.findOne({ order: [[“age”, “DESC”]], }); console.log(JSON.stringify(cat, null, 2));
- Querying with Associations
We can include associated data by adding an include key to our options object
const pet = Pet.findByPk(1, {
include: [PetType, Owner]
});
console.log(pet.id, pet.name, pet.age, pet.petTypeId, pet.PetType.type, pet.Owners
We can get nested associations by having include point to an object that specifies which model we have an association with, then chaining an association on with another include
How to perform data validations with Sequelize
- See the database migrations section above.
- In general, we add in a validate key to each field that we want validations for. This key points to an object that specifies all of the validations we want to make on that field, such as notEmpty, notNull, len, isIn, etc.
specification: {
type: DataTypes.TEXT,
validate: {
notEmpty: {
msg: 'The specification cannot be empty'
},
len: {
args: [10, 100]
msg: 'The specifcation must be between 10 and 100 characters'
}
}
}
How to use transactions with Sequelize
- We can create a transaction block in order to make sure either all operations are performed or none of them are
- We use the .transaction method in order to create our block. The method takes in a callback with an argument to track our transaction id (typically just a simple tx variable).
- All of our sequelize operations can be passed a transaction key on their options argument which points to our transaction id. This indicates that this operation is part of the transaction block and should only be executed in the database when the whole block executes without error.
async function main() {
try {
// Do all database access within the transaction.
await sequelize.transaction(async (tx) => {
// Fetch Markov and Curie's accounts.
const markovAccount = await BankAccount.findByPk(
1, {
transaction: tx
},
);
const curieAccount = await BankAccount.findByPk(
2, {
transaction: tx
}
);
// No one can mess with Markov or Curie's accounts until the
// transaction completes! The account data has been locked!
// Increment Curie's balance by $5,000.
curieAccount.balance += 5000;
await curieAccount.save({
transaction: tx
});
// Decrement Markov's balance by $5,000.
markovAccount.balance -= 5000;
await markovAccount.save({
transaction: tx
});
});
} catch (err) {
// Report if anything goes wrong.
console.log("Error!");
for (const e of err.errors) {
console.log(
`${e.instance.clientName}: ${e.message}`
);
}
}
await sequelize.close();
}
main();
Sequelize Cheatsheet
Command Line
Sequelize provides utilities for generating migrations, models, and seed files. They are exposed through the sequelize-cli command.
Init Project
$ npx sequelize-cli init
You must create a database user, and update the config/config.json file to match your database settings to complete the initialization process.
Create Database
npx sequelize-cli db:create
Generate a model and its migration
npx sequelize-cli model:generate --name
Run pending migrations
npx sequelize-cli db:migrate
Rollback one migration
npx sequelize-cli db:migrate:undo
Rollback all migrations
npx sequelize-cli db:migrate:undo:all
Generate a new seed file
npx sequelize-cli seed:generate --name
Run all pending seeds
npx sequelize-cli db:seed:all
Rollback one seed
npx sequelize-cli db:seed:undo
Rollback all seeds
npx sequelize-cli db:seed:undo:all
Migrations
Create Table (usually used in the up() method)
// This uses the short form for references
return queryInterface.createTable(
type: Sequelize.
allowNull: <true|false>,
unique: <true|false>,
references: { model:
// that the column references.
}
});
// This the longer form for references that is less confusing
return queryInterface.createTable(
type: Sequelize.
allowNull: <true|false>,
unique: <true|false>,
references: {
model: {
tableName:
}
}
}
});
Delete Table (usually used in the down() function)
return queryInterface.dropTable(
Adding a column
return queryInteface.addColumn(
type: Sequelize.
allowNull: <true|false>,
unique: <true|false>,
references: { model:
// that the column references.
});
Removing a column
return queryInterface.removeColumn(
Model Associations
One to One between Student and Scholarship
student.js
Student.hasOne(models.Scholarship, { foreignKey: 'studentId' });
scholarship.js
Scholarship.belongsTo(models.Student, { foreignKey: 'studentId' });
One to Many between Student and Class
student.js
Student.belongsTo(models.Class, { foreignKey: 'classId' });
class.js
Class.hasMany(models.Student, { foreignKey: 'classId' });
Many to Many between Student and Lesson through StudentLessons table
student.js
const columnMapping = {
through: 'StudentLesson', // This is the model name referencing the join table.
otherKey: 'lessonId',
foreignKey: 'studentId'
}
Student.belongsToMany(models.Lesson, columnMapping);
lesson.js
const columnMapping = {
through: 'StudentLesson', // This is the model name referencing the join table.
otherKey: 'studentId',
foreignKey: 'lessonId'
}
Lesson.belongsToMany(models.Student, columnMapping);
Inserting a new item
// Way 1 - With build and save
const pet = Pet.build({
name: "Fido",
petTypeId: 1
});
await pet.save();
// Way 2 - With create
const pet = await Pet.create({
name: "Fido",
petTypeId: 1
});
Updating an item
// Find the pet with id = 1
const pet = await Pet.findByPk(1);
// Way 1
pet.name = "Fido, Sr."
await pet.save;
// Way 2
await pet.update({
name: "Fido, Sr."
});
Deleting a single item
// Find the pet with id = 1
const pet = await Pet.findByPk(1);
// Notice this is an instance method
pet.destroy();
Deleting multiple items
// Notice this is a static class method
await Pet.destroy({
where: {
petTypeId: 1 // Destorys all the pets where the petType is 1
}
});
Query Format
findOne
await
where: {
[Op.
}
},
});
findAll
await
where: {
[Op.
}
},
include: <include_specifier>,
offset: 10,
limit: 2
});
findByPk
await
include: <includespecifier>
});
Eager loading associations with include
Simple include of one related model.
await Pet.findByPk(1, {
include: PetType
})
Include can take an array of models if you need to include more than one.
await Pet.findByPk(1, {
include: [Pet, Owner]
})
Include can also take an object with keys model and include.
This is in case you have nested associations.
In this case Owner doesn’t have an association with PetType, but
Pet does, so we want to include PetType onto the Pet Model.
await Owner.findByPk(1, {
include: {
model: Pet
include: PetType
}
});
toJSON method
The confusingly named toJSON() method does not return a JSON string but instead
returns a POJO for the instance.
// pet is an instance of the Pet class
const pet = await Pet.findByPk(1);
console.log(pet) // prints a giant object with
// tons of properties and methods
// petPOJO is now just a plain old Javascript Object
const petPOJO = pet.toJSON();
console.log(petPOJO); // { name: "Fido", petTypeId: 1 }
Common Where Operators
const Op = Sequelize.Op
[Op.and]: [{a: 5}, {b: 6}] // (a = 5) AND (b = 6)
[Op.or]: [{a: 5}, {a: 6}] // (a = 5 OR a = 6)
[Op.gt]: 6, // > 6
[Op.gte]: 6, // >= 6
[Op.lt]: 10, // < 10
[Op.lte]: 10, // <= 10
[Op.ne]: 20, // != 20
[Op.eq]: 3, // = 3
[Op.is]: null // IS NULL
[Op.not]: true, // IS NOT TRUE
[Op.between]: [6, 10], // BETWEEN 6 AND 10
[Op.notBetween]: [11, 15], // NOT BETWEEN 11 AND 15
[Op.in]: [1, 2], // IN [1, 2]
[Op.notIn]: [1, 2], // NOT IN [1, 2]
[Op.like]: '%hat', // LIKE '%hat'
[Op.notLike]: '%hat' // NOT LIKE '%hat'
[Op.iLike]: '%hat' // ILIKE '%hat' (case insensitive) (PG only)
[Op.notILike]: '%hat' // NOT ILIKE '%hat' (PG only)
[Op.startsWith]: 'hat' // LIKE 'hat%'
[Op.endsWith]: 'hat' // LIKE '%hat'
[Op.substring]: 'hat' // LIKE '%hat%'
[Op.regexp]: '^[h|a|t]' // REGEXP/~ '^[h|a|t]' (MySQL/PG only)
[Op.notRegexp]: '^[h|a|t]' // NOT REGEXP/!~ '^[h|a|t]' (MySQL/PG only)
[Op.iRegexp]: '^[h|a|t]' // ~* '^[h|a|t]' (PG only)
[Op.notIRegexp]: '^[h|a|t]' // !~* '^[h|a|t]' (PG only)
[Op.like]: { [Op.any]: ['cat', 'hat']}
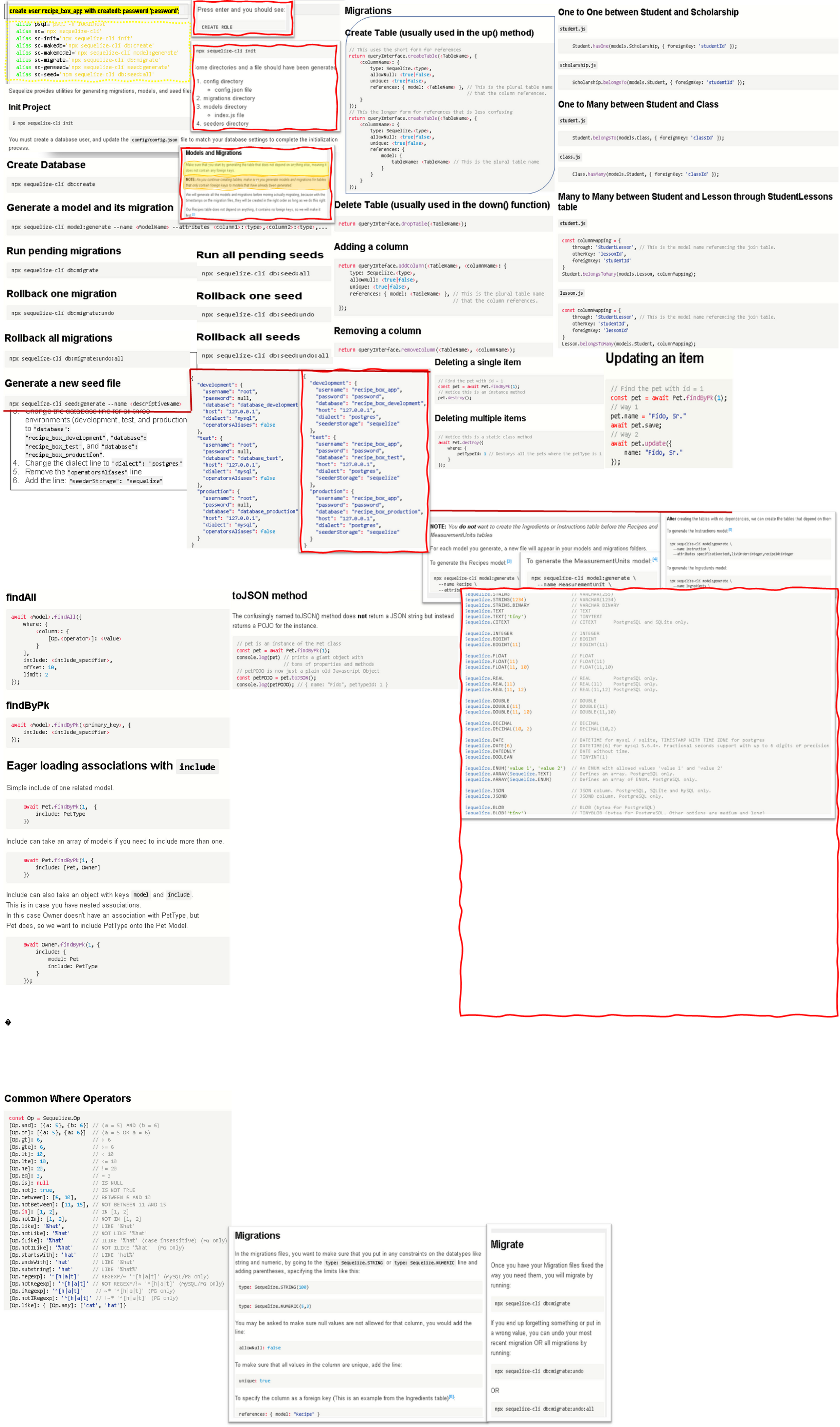
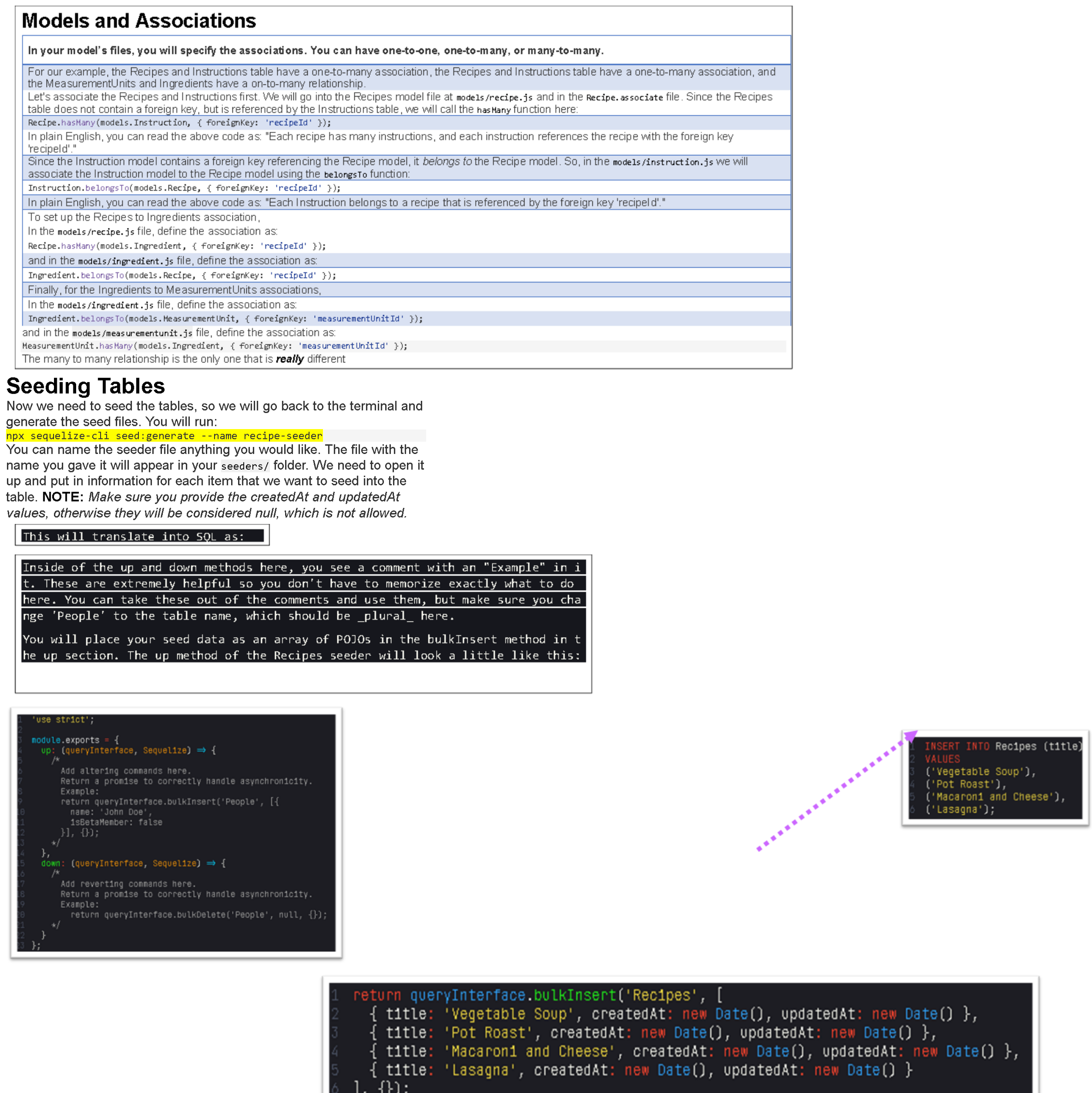
Accessing the Data
You can access and query the data using the findByPk, findOne, and findAll methods. First, make sure you import the models in your JavaScript file. In this case, we are assuming your JavaScript file is in the root of your project and so is the models folder.
const { Recipe, Ingredient, Instruction, MeasurementUnit } = require('./models');
The models folder exports each of the models that you have created. We have these four in our data model, so we will destructure the models to access each table individually. The associations that you have defined in each of your models will allow you to access data of related tables when you query your database using the include option.
If you want to find all recipes, for the recipe list, you would use the findAll method. You need to await this, so make sure your function is async.
async function findAllRecipes() {
return await Recipe.findAll();
}
If you would like to include all the ingredients so you can create a shopping list for all the recipes, you would use include. This is possible because of the association you have defined in your Recipe and Ingredient models.
async function getShoppingList() {
return await Recipe.findAll({ include: [ Ingredient ] });
}
If you only want to find one where there is chicken in the ingredients list, you would use findOne and findByPk.
async function findAChickenRecipe() {
const chickenRecipe = await Ingredient.findOne({
where: {
foodStuff: 'chicken'
}
});
return await Recipe.findByPk(chickenRecipe.recipeId);
}
Data Access to Create/Update/Delete Rows
You have two options when you want to create a row in a table (where you are saving one record into the table). You can either .build the row and then .save it, or you can .create it. Either way it does the same thing. Here are some examples:
Let’s say we have a form that accepts the name of the recipe (for simplicity). When we get the results of the form, we can:
const newRecipe = await Recipe.build({ title: 'Chicken Noodle Soup' });
await newRecipe.save();
This just created our new recipe and added it to our Recipes table. You can do the same thing like this:
await Recipe.create({ title: 'Chicken Noodle Soup' });
If you want to modify an item in your table, you can use update. Let’s say we want to change the chicken noodle soup to chicken noodle soup with extra veggies, first we need to get the recipe, then we can update it.
const modRecipe = await Recipe.findOne({ where: { title: 'Chicken Noodle Soup' } });
await modRecipe.update({ title: 'Chicken Noodle Soup with Extra Veggies' });
To delete an item from your table, you will do the same kind of process. Find the recipe you want to delete and destroy it, like this:
const deleteThis = await Recipe.findOne({ where: { title: 'Chicken Noodle Soup with Extra Veggies' } });
await deleteThis.destroy();
NOTE: If you do not await these, you will receive a promise, so you will need to use .then and .catch to do more with the items you are accessing and modifying.
Documentation
For the data types and validations in your models, here are the official docs. The sequelize docs are hard to look at, so these are the specific sections with just the lists:
Sequelize Data Types: https://sequelize.org/v5/manual/data-types.html
Validations: https://sequelize.org/v5/manual/models-definition.html#validations
When you access the data in your queries, here are the operators available, again because the docs are hard to navigate, this is the specific section with the list of operators.
Operators: https://sequelize.org/v5/manual/querying.html#operators
The documentation for building, saving, creating, updating and destroying is linked here, it does a pretty good job of explaining in my opinion, it just has a title that we have not been using in this course. When they talk about an instance, they mean an item stored in your table.
Create/Update/Destroy: https://sequelize.org/v5/manual/instances.html
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://gist.github.com/bgoonzhttps://gist.github.com/bgoonz
Or Checkout my personal Resource Site:
(Under construction… may be broken at any time)
https://gist.github.com/bgoonz
Resources, Cheat Sheets & Links @Bottom of the Page!
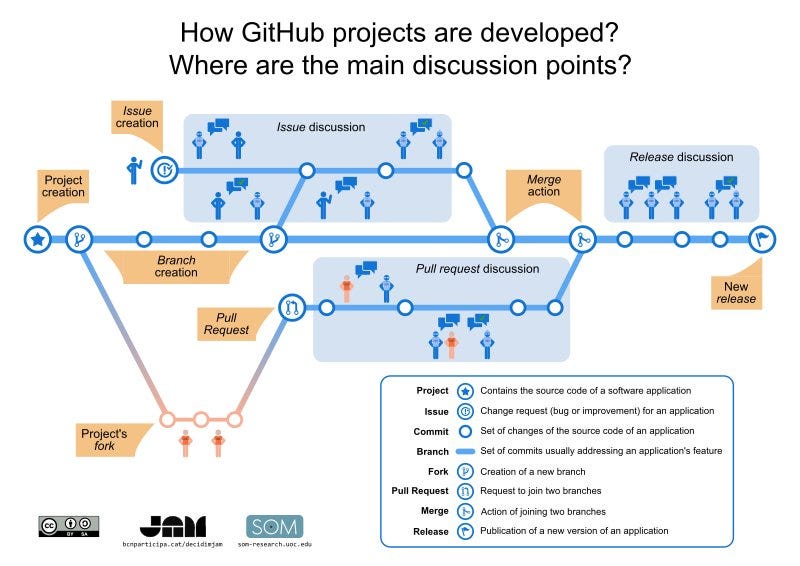
For More Advanced Readers, or those with very limited free time… here’s an abridged Git Reference.
https://bryanguner.medium.com/git-tricks-57e8d0292285
What’s a distributed version control system?
Git is an example of a distributed version control system (DVCS) commonly used for open source and commercial software development. DVCSs allow full access to every file, branch, and iteration of a project, and allows every user access to a full and self-contained history of all changes. Unlike once popular centralized version control systems, DVCSs like Git don’t need a constant connection to a central repository. Developers can work anywhere and collaborate asynchronously from any time zone.
Without version control, team members are subject to redundant tasks, slower timelines, and multiple copies of a single project. To eliminate unnecessary work, Git and other VCSs give each contributor a unified and consistent view of a project, surfacing work that’s already in progress. Seeing a transparent history of changes, who made them, and how they contribute to the development of a project helps team members stay aligned while working independently.
Why Git?
According to the latest Stack Overflow developer survey, more than 70 percent of developers use Git, making it the most-used VCS in the world. Git is commonly used for both open source and commercial software development, with significant benefits for individuals, teams and businesses.
- Git lets developers see the entire timeline of their changes, decisions, and progression of any project in one place. From the moment they access the history of a project, the developer has all the context they need to understand it and start contributing.
- Developers work in every time zone. With a DVCS like Git, collaboration can happen any time while maintaining source code integrity. Using branches, developers can safely propose changes to production code.
- Businesses using Git can break down communication barriers between teams and keep them focused on doing their best work. Plus, Git makes it possible to align experts across a business to collaborate on major projects.
Table Of Contents:
Editing Understanding Git (A Beginners Guide Containing Cheat Sheets & Resources) — Medium
5. Thats its! You can now run
[_git push_](#5-thats-its-you-can-now-run-git-push-and-it-will-push-to-your-newly-createdrepo)and it will push to your newly created repo.
I see you too like to live life Dangerously… tell me about Rebase..
[_working-on-the-header_](#working-on-the-header)
How 2’s
Further Reading & Resources
What’s a repository?
A repository, or Git project, encompasses the entire collection of files and folders associated with a project, along with each file’s revision history. The file history appears as snapshots in time called commits, and the commits exist as a linked-list relationship, and can be organized into multiple lines of development called branches. Because Git is a DVCS, repositories are self-contained units and anyone who owns a copy of the repository can access the entire codebase and its history. Using the command line or other ease-of-use interfaces, a git repository also allows for: interaction with the history, cloning, creating branches, committing, merging, comparing changes across versions of code, and more.
Working in repositories keeps development projects organized and protected. Developers are encouraged to fix bugs, or create fresh features, without fear of derailing mainline development efforts. Git facilitates this through the use of topic branches: lightweight pointers to commits in history that can be easily created and deprecated when no longer needed.
Git Flow
Cloning a repo and changing the remote url
(These steps are only for when you initially clone a project repo. Not when you clone your partners repo to collaborate together. To do that, you only have to complete step 1!)
1. The first step is to clone the repo!
- Navigate to the repo you want to clone and hit the big green code button. Copy the link given.

- Navigate in your terminal to the directory where you want this repo to live. I’ve chosen downloads
git clone [HTTPS://LINKTOURL/THATYOUCOPIED](http://https//LINKTOURL/THATYOUCOPIED)

2. Sweet, you have the cloned repo in your preferred directory. Now lets make your own repo. On github, create a new repository.
- Default settings are fine. Hit the big green button
Create Repository
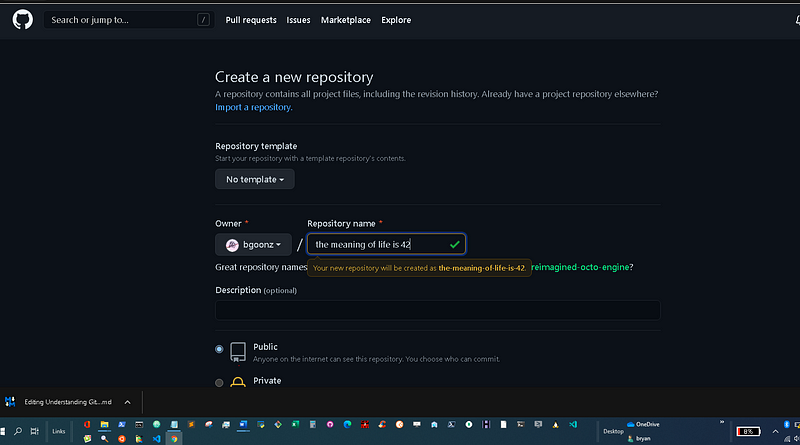
3. Next,
copy the .git link that is on the next page. Do not do any other steps on this page — That is for when you do not clone a repo.
These are the commands GitHub provides when you create a new Repo:
Quick setup — if you’ve done this kind of thing before
Set up in Desktop
or
HTTPSSSH
Get started by creating a new file or uploading an existing file. We recommend every repository include a README, LICENSE, and .gitignore.
…or create a new repository on the command line
echo "# the-meaning-of-life-is-42" >> README.md
git init
git add README.md
git commit -m "first commit"
git branch -M master
git remote add origin https://github.com/bgoonz/the-meaning-of-life-is-42.git
git push -u origin master
…or push an existing repository from the command line
git remote add origin https://github.com/bgoonz/the-meaning-of-life-is-42.git
git branch -M master
git push -u origin master
…or import code from another repository
You can initialize this repository with code from a Subversion, Mercurial, or TFS project.
4. Whenever you clone a repo:
It already has a .git directory with certain configurations set up. To be able to push this repo to your newly created GitHub repo we have to change the remote origin.
- To do that, just run this command: (Make sure you are inside the repo you cloned)
git remote set-url origin https://LINK/TO/YOUR/GIT/THAT/YOU/COPIED/FROM/PREVIOUS/STEP.git
OR:

5. You can now run git push and it will push to your newly created repo.
Basic Git Work Flow.
- After making changes to a file and you are ready to commit / push to your repo you can run the following commands:
git add .– stages modified files to be committed.git status– displays files that have been modifiedgit commit -m 'A helpfully commit message'– commits the changes to your local repo. Get in the habit now of making helpful commit messagesgit push– pushes your local commits to your GitHub repo!- To pull down changes that your partner pushed to the repo you simply have to run:
git pull– this will fetch the most recent updates!
Cheat Sheet:
https://gist.github.com/bgoonz/047223711786562db835107417130c28
My Git Reference Repo:
https://bryanguner.medium.com/git-tricks-57e8d0292285
Git basics
Like many disciplines, learning Git is just a matter of learning a new language. You’ll cover a lot of new vocabulary in this lesson! Remember that the vocabulary you’ll learn will allow you to communicate clearly with other developers worldwide, so it’s important to understand the meaning of each term.
It’s also important to note that Git is a complex and powerful tool. As such, its documentation and advanced examples may be tough to understand. As your knowledge grows, you may choose to dive deeper into Git. Today, you’ll focus on the commands you’ll use every day — possibly for the rest of your programming career! Get comfortable with these commands and resist the urge to copy/paste or create keyboard shortcuts as you’re getting started.
A glance into GIT
Before you look at any practical examples, let’s talk about how Git works behind the scenes.
Here is your first new word in Git-speak: repository, often shortened to repo. A Git repo comprises all the source code for a particular project. In the “dark ages” example above, the repo is the first directory you created, where work is saved to, and which acts as the source for code shared to others. Without a repo, Git has nothing to act on.
Git manages your project as a series of commits. A commit is a collection of changes grouped towards a shared purpose. By tracking these commits, you can see your project on a timeline instead of only as a finished project:
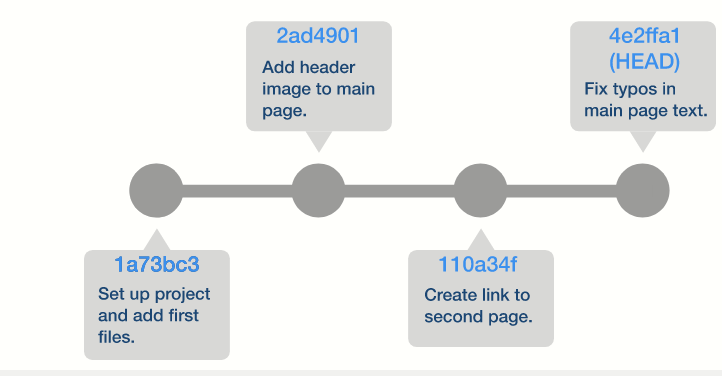
Notice the notes and seemingly random numbers by each commit? These are referred to as commit messages and commit hashes, respectively. Git identifies your commits by their hash, a specially-generated series of letters and numbers. You add commit messages to convey meaning and to help humans track your commits, as those hashes aren’t very friendly to read!
A Git hash is 40 characters long, but you only need the first few characters to identify which hash you’re referring to. By default, Git abbreviates hashes to 7 characters. You’ll follow this convention, too.
Git provides a helpful way for us to “alias” a commit in plain English as well. These aliases are called refs, short for “references”. A special one that Git creates for all repositories is HEAD, which references the most recent commit. You’ll learn more about creating your own refs when you learn about “branching”.
Git maintains three separate lists of changes: the working directory, the staging area, and the commit history. The working directory includes all of your in-progress changes, the staging area is reserved for changes you’re ready to commit, and the commit history is made up of changes you’ve already committed. You’ll look more at these three lists soon.
Git only cares about changes that are “tracked”. To track a file, you must add it to the commit history. The working directory will always show the changes, even if they aren’t tracked. In the commit history, you’ll only have a history of files that have been formally tracked by your repository.
Tracking changes in a repository
Now, let’s get practical!
You can create a repository with git init. Running this command will initialize a new Git repo in your current directory. It’s important to remember that you only want a repository for your project and not your whole hard drive, so always run this command inside a project folder and not your home folder or desktop. You can create a new repo in an empty folder or within a project directory you’ve already created.
What good is an empty repo? Not much! To add content to your repository, use git add. You can pass this command a specific filename, a directory, a “wildcard” to select a series of similarly-named files, or a . to add every untracked file in the current directory:
# This will add only my_app.js to the repo:
> git add my_app.js
# This will add all the files within ./objects:
> git add objects/
# This will add all the files in the current directory ending in `.js`:
> git add *.js
# This will add everything in your current directory:
> git add .
Adding a file (or files) moves them from Git’s working directory to the staging area. You can see what’s been “staged” and what hasn’t by using git status:
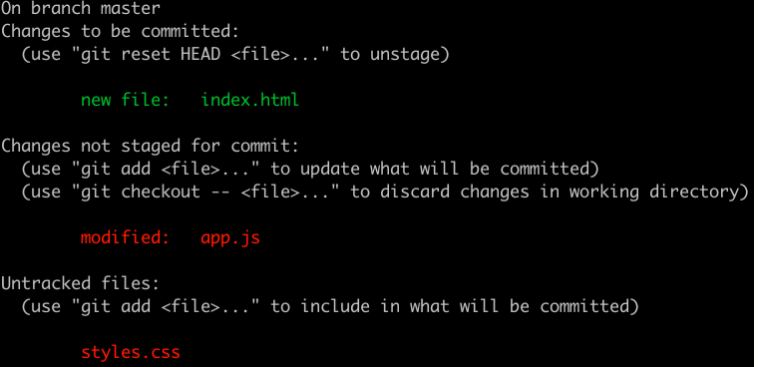
In this example, “Changes to be committed” is your staging area and “Changes not staged for commit” is your working directory. Notice that you also have “Untracked files”, Git’s way of reminding us that you may have forgotten to git add a file to your repo. Most Git commands will include a bit of help text in the output, so always read the messages carefully before moving forward. Thanks, Git!
Once you’re happy with your files and have staged them, you’ll use git commit to push them into the commit history. It’s significantly more work to make changes after a commit, so be sure your files are staged and exactly as you’d like them before running this command. Your default text editor will pop up, and you’ll be asked to enter a commit message for this group of changes.
Heads Up: You may find yourself in an unfamiliar place! The default text editor for MacOS (and many variants of Linux) is called Vim. Vim is a terminal-based text editor you’ll discuss in the near future. It’s visually bare and may just look like terminal text to you! If this happens, don’t worry — just type :q and press your “return” key to exit.
You’ll want to ensure that future commit messages open in a more familiar editor. You can run the following commands in your terminal to ensure that Visual Studio Code is your git commit editor from now on:
> git config --global core.editor "code --wait"
> git config --global -e
If you experience any issues, you may be missing Visual Studio Code’s command line tools. You can find more details and some troubleshooting tips on Microsoft’s official VS Code and macOS documentation.
Once you close your editor, the commit will be added to your repository’s commit history. Use git log to see this history at any time. This command will show all the commits in your repository’s history, beginning with the most recent:
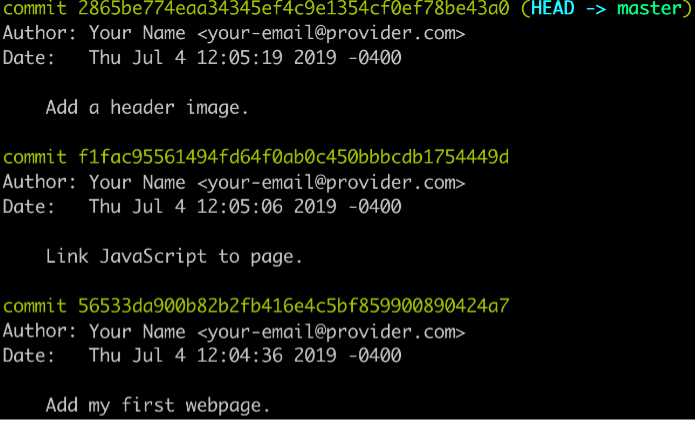
Like many Git commands, git commit includes some helpful shorthand. If you need a rather short commit message, you can use the -m flag to include the message inline. Here’s an example:
> git commit -m "Fix typo"
This will commit your changes with the message “Fix typo” and avoid opening your default text editor. Remember the commit messages are how you make your project’s history friendly to humans, so don’t use the -m flag as an excuse to write lame commit messages! A commit message should always explain why changes were made in clear, concise language. It is also best practice to use imperative voice in commit messages (i.e. use “Fix typo” instead of “Fixing the typo” or “Typo was fixed”).
Branches and workflow
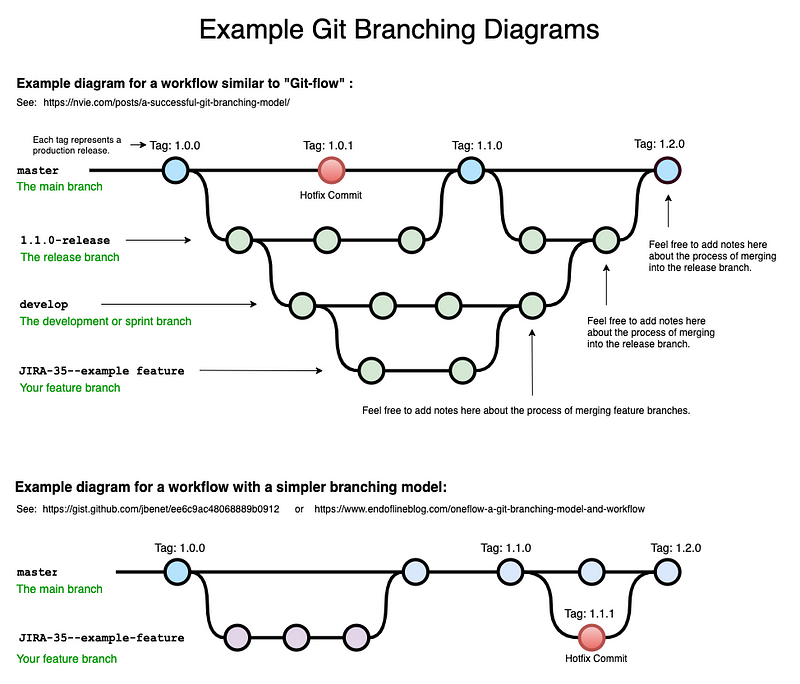
You’ve seen what a project looks like with a linear commit history, but that’s just scratching the surface of Git’s utility. Let’s explore a new realm with branches. A branch is a separate timeline in Git, reserved for its own changes. You’ll use branches to make your own changes independently of others. These branches can then be merged back into the main branch at a later time.
Let’s consider a common scenario: a school project. It’s a lot of extra hassle to schedule time together and argue over exactly what should be done next! Instead, group members will often assign tasks amongst themselves, work independently on their tasks, and reunite to bring it all together as a final report. Git branches let us emulate this workflow for code: you can make a copy of what’s been done so far, complete a task on your new branch, and merge that branch back into the shared repository for others to use.
By default, Git repos begin on the master branch. To create a new branch, use git branch <name-of-your-branch>. This will create a named reference to your current commit and let you add commits without affecting the master branch. Here’s what a branch looks like:
Notice how your refs help to identify branches here: master stays to itself and can have changes added to it independently of your new branch (footer). HEAD, Git’s special ref, follows us around, so you know that in the above diagram you’re working on the footer branch.
You can create a new branch or visit an existing branch in your repository. This is especially helpful for returning the master branch or for projects you’ve received from teammates. To open an existing branch, use git checkout <name-of-branch>.
Bringing it back together
Once you’re happy with the code in the branch you’ve been working on, you’ll likely want to integrate the code into the master branch. You can do this via git merge. Merging will bring the changes in from another branch and integrate them into yours. Here’s an example workflow:
> git branch my-changes
> git add new-file.js
> git commit -m "Add new file"
> git checkout master
> git merge my-changes
Following these steps will integrate the commit from my-changes over to master. Boom! Now you have your new-file.js on your default branch.
As you can imagine, branching can get very complicated. Your repository’s history may look more like a shrub than a beautiful tree! You’ll discuss advanced merging and other options in an upcoming lesson.
Connect-W-Github
Git can act as a great history tool and source code backup for your local projects, but it can also help you work with a team! Git is classified as a “DVCS”, or “Distributed Version Control System”. This means it has built-in support for managing code both locally and from a distant source.
You can refer to a repository source that’s not local as a remote. Your Git repository can have any number of remotes, but you’ll usually only have one. By default you’ll refer to the primary remote of a repo as the origin.
You can add a remote to an existing repository on your computer, or you can retrieve a repository from a remote source. You can refer to this as cloning the repo. Once you have a repository with a remote, you can update your local code from the remote by pulling code down, and you can push up your own code so others have access to it.
I Open Source
While a remote Git server can be run anywhere, there are a few places online that have become industry standards for hosting remote Git repositories. The best-known and most widely-used Git source is a website called GitHub. As the name suggests, GitHub is a global hub for Git repositories. It’s free to make a Github account, and you’ll find literally millions of public repositories you can browse.
GitHub takes a lot of work out of managing remote Git repositories. Instead of having to manage your own server, GitHub provides managed hosting and even includes some helpful graphical tools for complicated tasks like deployment, branch merging, and code review.
Let’s look at a typical workflow using Git and GitHub. Imagine it’s your first day on the job. How do you get access to your team’s codebase? By cloning the repository!
> git clone https://github.com/your-team/your-codebase.git
Using the git clone command will create a new folder in your current directory named after the repo you’re cloning (in this case, your-codebase). Inside that folder will be a git repository of your very own, containing the repo’s entire commit history.
You’ll likely start on the master branch, but remember that this is the default branch and it’s unlikely you want to make changes to it. Since you’re working on a team now, it’s important to think of how your changes to the repository might affect others.
The safest way to make changes is to create a new branch, make your changes there, and then push your branch up to the remote repository for review. You’ll use the git push command to do this. Let’s look at an example:
> git branch add-my-new-file
> git add my-new-file.js
> git commit -m "Add new file"
> git push -u origin add-my-new-file
Notice how you used the -u flag with git push. This flag, shorthand for --set-upstream, lets Git know that you want your local branch to follow a remote branch. You’ve passed the same name in, so you’ll now have two branches in your local repository: add-my-new-file, which is where your changes live after being committed, and origin/add-my-new-file, which keeps up with your remote branch and updates it after you use git push.
You only need to use the **-u** flag the first time you push each new branch – Git will know what to do with a simple **git push** from then on.
You now know how to push your changes up, but what about getting the changes your teammates have made? For this, you’ll use git pull. Pulling from the remote repo will update all of your local branches with the code from each branch’s remote counterpart.
Behind the scenes, Git is running two separate commands: git fetch and git merge.
Fetching retrieves the repository code and updates any remote tracking branches in your local repo, and merge does just you’ve already explored: integrates changes into the local branches. Here’s a graphic to explain this a little better:
It’s important to remember to use git pull often. A dynamic team may commit and push code many times during the day, and it’s easy to fall behind. The more often you pull, the more certain you can be that your own code is based on the “latest and greatest”.
Merging your code on GitHub
If you’re paying close attention, you may have noticed that there’s a missing step in your workflows so far: how do you get your code merged into your default branch? This is done by a process called a Pull Request.
A pull request (or “PR”) is a feature specific to GitHub, not a feature of Git. It’s a safety net to prevent bugs, and it’s a critical part of the collaboration workflow. Here’s a high-level of overview of how it works:
You push your code up to GitHub in its own branch.
You open a pull request against a base branch.
GitHub creates a comparison page just for your code, detailing the changes you’ve made.
Other members of the team can review your code for errors.
You make changes to your branch based on feedback and push the new commits up.
The PR automatically updates with your changes.
Once everyone is satisfied, a repo maintainer on GitHub can merge your branch.
Huzzah! Your code is in the main branch and ready for everyone else to git pull.
You’ll create and manage your pull requests via GitHub’s web portal, instead of the command line. You’ll walk through the process of creating, reviewing, and merging a pull request in an upcoming project.
Browsing Your Git Repository
Repositories can feel intimidating at first, but it won’t take you long to navigate code like you own the place — because you do! Let’s discuss a few tools native to Git that help us browse our changes over time.
We’ll be covering:
Comparing changes with git diff
Browsing through our code “checkpoints” with git checkout
Seeing changes in real time
Git is all about change tracking, so it makes sense that it would include a utility for visualizing a set of changes. We refer to a list of differences between two files (or the same file over time) as a diff, and we can use git diff to visualize diffs in our repo!
When run with no extra options, git diff will return any tracked changes in our working directory since the last commit. Tracked is a key word here; git diff won’t show us changes to files that haven’t been included in our repo via git add. This is helpful for seeing what you’ve changed before committing! Here’s an example of a small change:
![]()
Let’s break down some of the new syntax in this output.
The diff opens with some Git-specific data, including the branch/files we’re checking, and some unique hashes that Git uses to track each diff. You can skip past this to get to the important bits.
--- & +++ let us know that there are both additions and subtractions in the file “App.js”. A diff doesn’t have a concept of inline changes – it treats a single change as removing something old and replacing it with something new.
@@ lets us know that we’re starting a single “chunk” of the diff. A diff could have multiple chunks for a single file (for example: if you made changes far apart, like the header & footer). The numbers in between tell us how many lines we’re seeing and where they start. For example: @@ +1,3 -1,3 @@ means we’ll see three lines of significant content, including both addition & removal, beginning at line one.
In the code itself, lines that were removed are prefixed with a - and lines that were added are prefixed with a +. Remember that you won’t see these on the same lines. Even if you only changed a few words, Git will still treat it like the whole line was replaced.
Diff options
Remember that, by default, git diff compares the current working directory to the last commit. You can compare the staging area instead of the working directory with git diff --staged. This is another great way to double-check your work before pushing up to a remote branch.
You’re also not limited to your current branch — or even your current commit! You can pass a base & target branch to compare, and you can use some special characters to help you browse faster! Here are a few examples:
# See differences between the 'feature'
# branch and the 'master' branch.
> git diff master feature
# Compare two different commits
> git diff 1fc345a 2e3dff
# Compare a specific file across separate commits
> git diff 1fc345a 2e3dff my-file.js
Time travel
git diff gives us the opportunity to explore our code’s current state, but what if we wanted to see its state at a different point in time? We can use checkout! git checkout lets us take control of our HEAD to bounce around our timeline as we please.
Remember that HEAD is a special Git reference that usually follows the latest commit on our current branch. We can use git checkout to point our HEAD reference at a different commit, letting us travel to any commit in our repository’s history. By reading the commit message and exploring the code at the time of the commit, we can see not only what changed but also why it changed! This can be great for debugging a problem or understanding how an app evolved.
Let’s look at a diagram to understand what checkout does a little better:
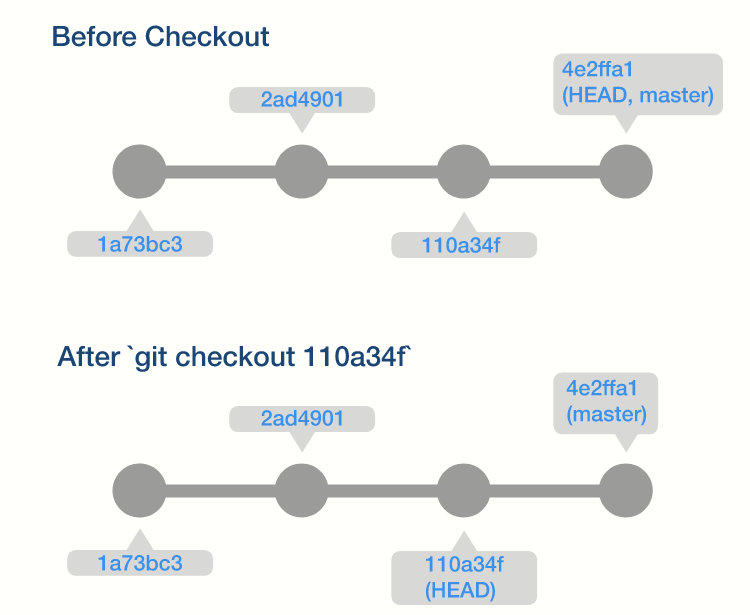
Notice that we haven’t lost any commits, commit messages, or code changes. Using git checkout is entirely non-destructive.
To browse to a different commit, simply pass in a reference or hash for the commit you’d like to explore. git checkout also supports a few special characters & reserved references:
# You can checkout a branch name.
# You'll be using this particular branch a lot!
> git checkout master
# You can also use commit hashes directly
> git checkout 7d3e2f1
# Using a hyphen instead of a hash will take
# you to the last branch you checked out
> git checkout -
# You can use "HEAD~N" to move N commits prior
# to the current HEAD
> git checkout HEAD~3
Once you’re done browsing the repo’s history, you can use git checkout <your-branch-name> to move HEAD back to the front of the line (your most recent commit). For example, in our diagram above, we could use git checkout master to take our HEAD reference back to commit 42ffa1.
Why checkout?
Most of Git’s power comes from a simple ability: viewing commits in the past and understanding how they connect. This is why mastering the git checkout command is so important: it lets you think more like Git and gives you full freedom of navigation without risking damage to the repo’s contents.
That said, you’ll likely use shortcuts like git checkout - far more often than specifically checking out commit hashes. Especially with the advent of user-friendly tools like GitHub, it’s much easier to visualize changes outside the command line. We’ll demonstrate browsing commit histories on GitHub in a future lesson.
Git ‘Do-Overs’: Reset & Rebase
Git is designed to protect you — not only from others, but also from yourself! Of course, there are times where you’d like to exercise your own judgement, even if it may not be the best thing to do. For this, Git provides some helpful tools to change commits and “time travel”.
Before we talk about these, a warning: The commands in this lesson are destructive! If used improperly, you could lose work, damage a teammate’s branch, or even rewrite the history of your entire project. You should exercise caution when using these on production code, and don’t hesitate to ask for help if you’re unsure what a command might do.
After this lesson, you should:
Be able to roll back changes to particular commit.
Have an understanding of how rebasing affects your commit history.
Know when to rebase/reset and when not to.
Resetting the past
Remember how our commits form a timeline? We can see the state of our project at any point using git checkout. What if we want to travel back in time to a point before we caused a new bug or chose a terrible font? git reset is the answer!
Resetting involves moving our
HEADref back to a different commit.
No matter how we reset, HEAD will move with us. Unlike git checkout, this will also destroy intermediate commits. We can use some additional flags to determine how our code changes are handled.
Soft resets
The least-dangerous reset of all is git reset --soft.
A soft reset will move our HEAD ref to the commit we’ve specified, and will leave any intermediate changes in the staging area.
This means you won’t lose any code, though you will lose commit messages.
A practical example of when a soft reset would be handy is joining some small commits into a larger one. We’ll pretend we’ve been struggling with “their”, “there”, and “they’re” in our app. Here’s our commit history:Those commit messages aren’t great: they’re not very explanatory, and they don’t provide a lot of value in our commit history. We’ll fix them with a soft reset:
git reset --soft 9c5e2fc
This moves our HEAD ref back to our first commit. Looking at our commit log now, we might be worried we’ve lost our changes:
Our changes are still present in the staging area, ready to be re-committed when we’re ready! We can use git commit to re-apply those changes to our commit history with a new, more helpful message instead:

Notice that the new commit has a totally new hash. The old commit messages (and their associated hashes) have been lost, but our code changes are safe and sound!
Risky Business: Mixed resets
If soft resets are the safest form of git reset, mixed resets are the most average! This is exactly why they’re the default: running git reset without adding a flag is the same as running git reset --mixed.
In a mixed reset, your changes are preserved, but they’re moved from the commit history directly to the working directory. This means you’ll have to use git add to choose everything you want in future commits.
Mixed resets are a good option when you want to alter a change in a previous commit. Let’s use a mixed reset with our “their”, “there”, “they’re” example again.
We’ll start with “they’re”:
Notice again that you don’t lose your code with a mixed reset, but you do lose your commit messages & hashes. The difference between --soft and --mixed comes down to whether you’ll be keeping the code exactly the same before re-committing it or making changes.
Hard resets
Hard resets are the most dangerous type of reset in Git. Hard resets adjust your HEAD ref and totally destroy any interim code changes. Poof. Gone forever.
There are very few good uses for a hard reset, but one is to get yourself out of a tight spot. Let’s say you’ve made a few changes to your repository but you now realize those changes were unnecessary. You’d like to move back in time so that your code looks exactly as it did before any changes were made. git reset --hard can take you there.
It’s our last round with “their”, “there”, and “they’re”. We’ve tried it all three ways and decided we don’t need to use that word at all! Let’s walk through a hard reset to get rid of our changes.
We’ll start in the same place we began for our soft reset:

It turns out that we’ll be using a video on our homepage and don’t need text at all! Let’s step back in time:
git reset --hard 9c5e2fc
Our Git log output is much simpler now:
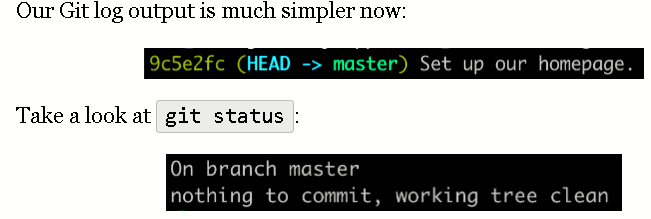
It’s empty — no changes in your working directory and no changes in your staging area. This is major difference between a hard reset and a soft/mixed reset: you will lose all your changes back to the commit you’ve reset to.
If your teammate came rushing in to tell you that the boss has changed their mind and wants that homepage text after all, you’re going to be re-doing all that work! Be very confident that the changes you’re losing are unimportant before embarking on a hard reset.
Rebase: ‘Alt-time travel’
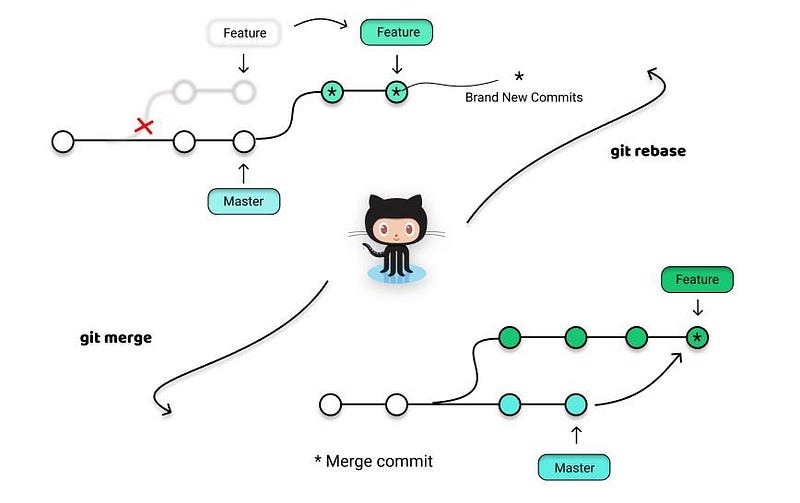
Sometimes we want to change more than a few commits on a linear timeline. What if we want to move multiple commits across branches? git rebase is the tool for us!
Rebasing involves changing your current branch’s base branch. We might do this if we accidentally started our branch from the wrong commit or if we’d like to incorporate changes from another branch into our own.
Isn’t that the same as git merge?
git merge?” In almost all cases, you’d be right. Rebasing is a dangerous process that effectively rewrites history.
I see you too like to live life Dangerously… tell me about Rebase..
Let’s look at a situation where we might be tempted to rebase. We’ve added a couple commits to a feature branch while other team members have been merging their code into the master branch. Once we’re ready to merge our own branch, we probably want to follow a tried-and-true procedure:
> git pull origin master
This will fetch our remote master branch and merge its changes into our own feature branch, so it’s safe to pull request or git push. However, every time we do that, a merge commit will be created! This can make a big mess of our Git commit history, especially if lots of people are making small changes.
We can use git rebase to move our changes silently onto the latest version of master. Here’s what the git log history of our two example branches looks like:

Notice that both branches start at 9c5e2fc. That’s our common ancestor commit, and is where git merge would start stitching these branches together! We’re going to avoid that entirely with a rebase. We’ll run this command while we have working-on-the-header checked out:
git rebase master
Here’s our new commit history:


working-on-the-header
See how we changed the color of our commits after the rebase? Take a close look at the commit history changes as well. Even though our commits have the same content, they have a new hash assigned, meaning they’re entirely new commits! This is what we mean by “rewriting history”: we’ve actually changed how Git refers to these changes now.
“Golden Rule of Git”
These tools can all feel pretty nifty, but be very wary of using them too much! While they can augment your Git skills from good to great, they can also have catastrophic side effects.
There’s a “Golden Rule of Git” you should know that directly relates to both git reset and git rebase:
Never change the history of a branch that’s shared with others.
That’s it! It’s simple and to the point. If you’re resetting or rebasing your own code and you make a mistake, your worst case scenario is losing your own changes. However, if you start changing the history of code that others have contributed or are relying on, your accidental loss could affect many others!
How to check your Git configuration:
The command below returns a list of information about your git configuration including user name and email:
git config -l
How to setup your Git username:
With the command below you can configure your user name:
git config --global user.name "Fabio"
How to setup your Git user email:
This command lets you setup the user email address you’ll use in your commits.
git config --global user.email "signups@fabiopacifici.com"
How to cache your login credentials in Git:
You can store login credentials in the cache so you don’t have to type them in each time. Just use this command:
git config --global credential.helper cache
How to initialize a Git repo:
Everything starts from here. The first step is to initialize a new Git repo locally in your project root. You can do so with the command below:
git init
How to add a file to the staging area in Git:
The command below will add a file to the staging area. Just replace filename_here with the name of the file you want to add to the staging area.
git add filename_here
How to add all files in the staging area in Git
If you want to add all files in your project to the staging area, you can use a wildcard . and every file will be added for you.
git add .
How to add only certain files to the staging area in Git
With the asterisk in the command below, you can add all files starting with ‘fil’ in the staging area.
git add fil*
How to check a repository’s status in Git:
This command will show the status of the current repository including staged, unstaged, and untracked files.
git status
How to commit changes in the editor in Git:
This command will open a text editor in the terminal where you can write a full commit message.
A commit message is made up of a short summary of changes, an empty line, and a full description of the changes after it.
git commit
How to commit changes with a message in Git:
You can add a commit message without opening the editor. This command lets you only specify a short summary for your commit message.
git commit -m "your commit message here"
How to commit changes (and skip the staging area) in Git:
You can add and commit tracked files with a single command by using the -a and -m options.
git commit -a -m"your commit message here"
How to see your commit history in Git:
This command shows the commit history for the current repository:
git log
How to see your commit history including changes in Git:
This command shows the commit’s history including all files and their changes:
git log -p
How to see a specific commit in Git:
This command shows a specific commit.
Replace commit-id with the id of the commit that you find in the commit log after the word commit.
git show commit-id
How to see log stats in Git:
This command will cause the Git log to show some statistics about the changes in each commit, including line(s) changed and file names.
git log --stat
How to see changes made before committing them using “diff” in Git:
You can pass a file as a parameter to only see changes on a specific file.git diff shows only unstaged changes by default.
We can call diff with the --staged flag to see any staged changes.
git diffgit diff all_checks.pygit diff --staged
How to see changes using “git add -p”:
This command opens a prompt and asks if you want to stage changes or not, and includes other options.
git add -p
How to remove tracked files from the current working tree in Git:
This command expects a commit message to explain why the file was deleted.
git rm filename
How to rename files in Git:
This command stages the changes, then it expects a commit message.
git mv oldfile newfile
How to ignore files in Git:
Create a .gitignore file and commit it.
How to revert unstaged changes in Git:
git checkout filename
How to revert staged changes in Git:
You can use the -p option flag to specify the changes you want to reset.
git reset HEAD filenamegit reset HEAD -p
How to amend the most recent commit in Git:
git commit --amend allows you to modify and add changes to the most recent commit.
git commit --amend
!!Note!!: fixing up a local commit with amend is great and you can push it to a shared repository after you’ve fixed it. But you should avoid amending commits that have already been made public.
How to rollback the last commit in Git:
git revert will create a new commit that is the opposite of everything in the given commit.
We can revert the latest commit by using the head alias like this:
git revert HEAD
How to rollback an old commit in Git:
You can revert an old commit using its commit id. This opens the editor so you can add a commit message.
git revert comit_id_here
How to create a new branch in Git:
By default, you have one branch, the main branch. With this command, you can create a new branch. Git won’t switch to it automatically — you will need to do it manually with the next command.
git branch branch_name
How to switch to a newly created branch in Git:
When you want to use a different or a newly created branch you can use this command:
git checkout branch_name
How to list branches in Git:
You can view all created branches using the git branch command. It will show a list of all branches and mark the current branch with an asterisk and highlight it in green.
git branch
How to create a branch in Git and switch to it immediately:
In a single command, you can create and switch to a new branch right away.
git checkout -b branch_name
How to delete a branch in Git:
When you are done working with a branch and have merged it, you can delete it using the command below:
git branch -d branch_name
How to merge two branches in Git:
To merge the history of the branch you are currently in with the branch_name, you will need to use the command below:
git merge branch_name
How to show the commit log as a graph in Git:
We can use --graph to get the commit log to show as a graph. Also,--oneline will limit commit messages to a single line.
git log --graph --oneline
How to show the commit log as a graph of all branches in Git:
Does the same as the command above, but for all branches.
git log --graph --online --all
How to abort a conflicting merge in Git:
If you want to throw a merge away and start over, you can run the following command:
git merge --abort
How to add a remote repository in Git
This command adds a remote repository to your local repository (just replace [https://repo_here](https://repo_here/) with your remote repo URL).
git add remote https://repo_here
How to see remote URLs in Git:
You can see all remote repositories for your local repository with this command:
git remote -v
How to get more info about a remote repo in Git:
Just replace origin with the name of the remote obtained by
running the git remote -v command.
git remote show origin
How to push changes to a remote repo in Git:
When all your work is ready to be saved on a remote repository, you can push all changes using the command below:
git push
How to pull changes from a remote repo in Git:
If other team members are working on your repository, you can retrieve the latest changes made to the remote repository with the command below:
git pull
How to check remote branches that Git is tracking:
This command shows the name of all remote branches that Git is tracking for the current repository:
git branch -r
How to fetch remote repo changes in Git:
This command will download the changes from a remote repo but will not perform a merge on your local branch (as git pull does that instead).
git fetch
How to check the current commits log of a remote repo in Git
Commit after commit, Git builds up a log. You can find out the remote repository log by using this command:
git log origin/main
How to merge a remote repo with your local repo in Git:
If the remote repository has changes you want to merge with your local, then this command will do that for you:
git merge origin/main
How to get the contents of remote branches in Git without automatically merging:
This lets you update the remote without merging any content into the
local branches. You can call git merge or git checkout to do the merge.
git remote update
How to push a new branch to a remote repo in Git:
If you want to push a branch to a remote repository you can use the command below. Just remember to add -u to create the branch upstream:
git push -u origin branch_name
How to remove a remote branch in Git:
If you no longer need a remote branch you can remove it using the command below:
git push --delete origin branch_name_here
How to use Git rebase:
You can transfer completed work from one branch to another using git rebase.
git rebase branch_name_here
Git Rebase can get really messy if you don’t do it properly. Before using this command I suggest that you re-read the official documentation here
How to run rebase interactively in Git:
You can run git rebase interactively using the -i flag.
It will open the editor and present a set of commands you can use.
git rebase -i master# p, pick = use commit# r, reword = use commit, but edit the commit message# e, edit = use commit, but stop for amending# s, squash = use commit, but meld into previous commit# f, fixup = like "squash", but discard this commit's log message# x, exec = run command (the rest of the line) using shell# d, drop = remove commit
How to force a push request in Git:
This command will force a push request. This is usually fine for pull request branches because nobody else should have cloned them.
But this isn’t something that you want to do with public repos.
git push -f
Git Alias Overview
It is important to note that there is no direct git alias command. Aliases are created through the use of the [git config](https://www.atlassian.com/git/tutorials/setting-up-a-repository/git-config) command and the Git configuration files. As with other configuration values, aliases can be created in a local or global scope.
To better understand Git aliases let us create some examples.
$ git config --global alias.co checkout$ git config --global alias.br branch$ git config --global alias.ci commit$ git config --global alias.st status
The previous code example creates globally stored shortcuts for common git commands. Creating the aliases will not modify the source commands. So git checkout will still be available even though we now have the git co alias. These aliases were created with the --global flag which means they will be stored in Git’s global operating system level configuration file. On linux systems, the global config file is located in the User home directory at /.gitconfig.
[alias] co = checkout br = branch ci = commit st = status
This demonstrates that the aliases are now equivalent to the source commands.
Usage
Git aliasing is enabled through the use of git config, For command-line option and usage examples please review the [git config](https://www.atlassian.com/git/tutorials/setting-up-a-repository/git-config) documentation.
Examples
Using aliases to create new Git commands
A common Git pattern is to remove recently added files from the staging area. This is achieved by leveraging options to the git reset command. A new alias can be created to encapsulate this behavior and create a new alias-command-keyword which is easy to remember:
git config --global alias.unstage 'reset HEAD --'
The preceding code example creates a new alias unstage. This now enables the invocation of git unstage. git unstage which will perform a reset on the staging area. This makes the following two commands equivalent.
git unstage fileA$ git reset HEAD -- fileA
My Default Gitignore:
https://gist.github.com/bgoonz/edf38d971ba96cbbe056d7afd4a5da2e
Troubleshooting Git
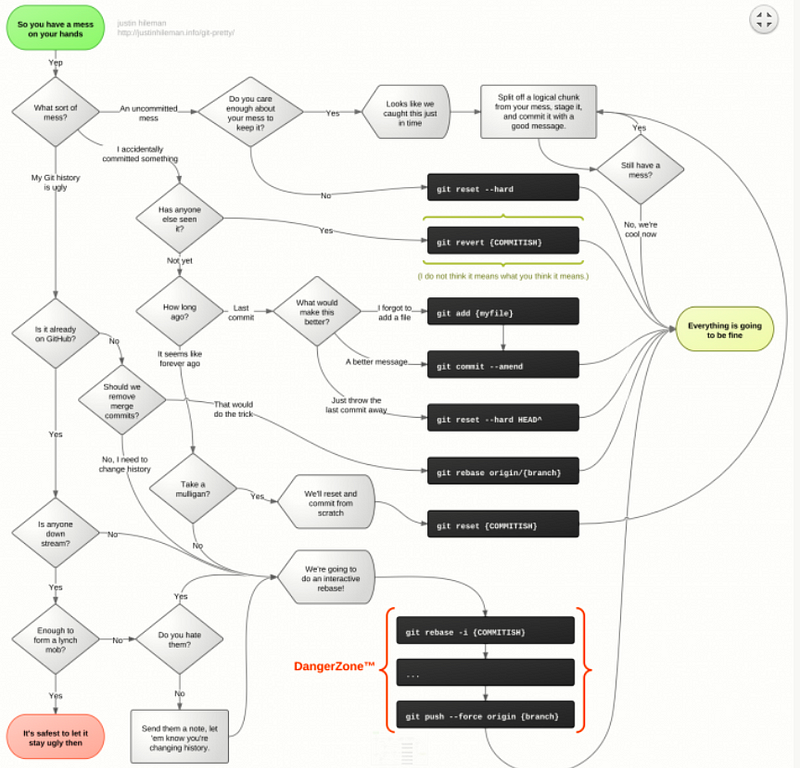
Here are some tips on troubleshooting and resolving issues with Git.
Broken pipe errors on git push
‘Broken pipe’ errors can occur when attempting to push to a remote repository. When pushing you usually see:
Write failed: Broken pipefatal: The remote end hung up unexpectedly
To fix this issue, here are some possible solutions.
Increase the POST buffer size in Git
If you’re using Git over HTTP instead of SSH, you can try increasing the POST buffer size in Git’s configuration.
Example of an error during a clone: fatal: pack has bad object at offset XXXXXXXXX: inflate returned -5
Open a terminal and enter:
git config http.postBuffer 52428800
The value is specified in bytes, so in the above case the buffer size has been set to 50MB. The default is 1MB.
Check your SSH configuration
If pushing over SSH, first check your SSH configuration as ‘Broken pipe’ errors can sometimes be caused by underlying issues with SSH (such as authentication). Make sure that SSH is correctly configured by following the instructions in the SSH troubleshooting documentation.
If you’re a GitLab administrator and have access to the server, you can also prevent session timeouts by configuring SSH keep alive either on the client or on the server.
Configuring both the client and the server is unnecessary.
To configure SSH on the client side:
- On UNIX, edit
~/.ssh/config(create the file if it doesn’t exist) and add or edit: Host your-gitlab-instance-url.com ServerAliveInterval 60 ServerAliveCountMax 5- On Windows, if you are using PuTTY, go to your session properties, then navigate to “Connection” and under “Sending of null packets to keep session active”, set
Seconds between keepalives (0 to turn off)to60.
To configure SSH on the server side, edit /etc/ssh/sshd_config and add:
ClientAliveInterval 60ClientAliveCountMax 5
Running a git repack
If ‘pack-objects’ type errors are also being displayed, you can try to run a git repack before attempting to push to the remote repository again:
git repackgit push
Upgrade your Git client
In case you’re running an older version of Git (< 2.9), consider upgrading to >= 2.9 (see Broken pipe when pushing to Git repository).
ssh_exchange_identification error
Users may experience the following error when attempting to push or pull using Git over SSH:
Please make sure you have the correct access rightsand the repository exists....ssh_exchange_identification: read: Connection reset by peerfatal: Could not read from remote repository.
or
ssh_exchange_identification: Connection closed by remote hostfatal: The remote end hung up unexpectedly
This error usually indicates that SSH daemon’s MaxStartups value is throttling SSH connections. This setting specifies the maximum number of concurrent, unauthenticated connections to the SSH daemon. This affects users with proper authentication credentials (SSH keys) because every connection is ‘unauthenticated’ in the beginning. The default value is 10.
Increase MaxStartups on the GitLab server by adding or modifying the value in /etc/ssh/sshd_config:
MaxStartups 100:30:200
100:30:200 means up to 100 SSH sessions are allowed without restriction, after which 30% of connections are dropped until reaching an absolute maximum of 200.
Once configured, restart the SSH daemon for the change to take effect.
# Debian/Ubuntusudo systemctl restart ssh
# CentOS/RHELsudo service sshd restart
Timeout during git push / git pull
If pulling/pushing from/to your repository ends up taking more than 50 seconds, a timeout is issued. It contains a log of the number of operations performed and their respective timings, like the example below:
remote: Running checks for branch: masterremote: Scanning for LFS objects... (153ms)remote: Calculating new repository size... (cancelled after 729ms)
This could be used to further investigate what operation is performing poorly and provide GitLab with more information on how to improve the service.
git clone over HTTP fails with transfer closed with outstanding read data remaining error
If the buffer size is lower than what is allowed in the request, the action fails with an error similar to the one below:
error: RPC failed; curl 18 transfer closed with outstanding read data remainingfatal: The remote end hung up unexpectedlyfatal: early EOFfatal: index-pack failed
This can be fixed by increasing the existing http.postBuffer value to one greater than the repository size. For example, if git clone fails when cloning a 500M repository, you should set http.postBuffer to 524288000. That setting ensures the request only starts buffering after the first 524288000 bytes.
The default value of http.postBuffer, 1 MiB, is applied if the setting is not configured.
git config http.postBuffer 524288000
Further Reading:
https://gist.github.com/bgoonz/140a268bdc42f03bbb4ab47a9cd11263https://gist.github.com/bgoonz/69bb5ef5e62f9350d2766df123cc6e54
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://bryanguner.medium.com/git-tricks-57e8d0292285https://bryanguner.medium.com/git-tricks-57e8d0292285
Or Checkout my personal Resource Site:
https://bryanguner.medium.com/git-tricks-57e8d0292285

How to learn effectively
Learning: The acquisition of skills and the ability to apply them in the future.
What makes an Effective learner?
- They are active listeners.
- They are engaged with the material.
- They are receptive of feedback.
- They are open to difficulty.
Why do active learning techniques feel difficult?
- It feels difficult because you are constantly receiving feedback, and so you are constantly adapting and perfecting the material.
Desirable Difficulty
- The skills we wish to obtain is often a difficult one.
- We want challenging but possible lessons based on current level of skill.
Effective learners space their practice
- Consistent effort > cramming => for durable knowledge
Getting visual feedback in your programs
The first command we’ll learn in JavaScript is console.log. This command is used to print something onto the screen. As we write our first lines of code, we’ll be using console.log frequently as a way to visually see the output of our programs. Let’s write our first program:
console.log("hello world");console.log("how are you?");
Executing the program above would print out the following:
hello worldhow are you?
Nothing too ground breaking here, but pay close attention to the exact way we wrote the program. In particular, notice how we lay out the periods, parentheses, and quotation marks. We’ll also terminate lines with semicolons (;).
Depending on how you structure your code, sometimes you’ll be able to omit semicolons at the end of lines. For now, you’ll want to include them just as we do.
Syntax
We refer to the exact arrangement of the symbols, characters, and keywords as syntax. These details matter — your computer will only be able to “understand” proper JavaScript syntax. A programming language is similar to a spoken language. A spoken language like English has grammar rules that we should follow in order to be understood by fellow speakers. In the same way, a programming language like JavaScript has syntax rules that we ought to follow!
As you write your first lines of code in this new language, you may make many syntax errors. Don’t get frustrated! This is normal — all new programmers go through this phase. Every time we recognize an error in our code, we have an opportunity to reinforce your understanding of correct syntax. Adopt a growth mindset and learn from your mistakes.
Additionally, one of the best things about programming is that we can get such immediate feedback from our creations. There is no penalty for making a mistake when programming. Write some code, run the code, read the errors, fix the errors, rinse and repeat!
Code comments
Occasionally we’ll want to leave comments or notes in our code. Commented lines will be ignored by our computer. This means that we can use comments to write plain english or temporarily avoid execution of some JavaScript lines. The proper syntax for writing a comment is to begin the line with double forward slashes (//):
// let's write another program!!!console.log("hello world");
// console.log("how are you?");
console.log("goodbye moon");
The program above would only print:
hello worldgoodbye moon
Comments are useful when annotating pieces of code to offer an explanation of how the code works. We’ll want to strive to write straightforward code that is self-explanatory when possible, but we can also use comments to add additional clarity. The real art of programming is to write code so elegantly that it is easy to follow.
The Number Data Type
The number data type in JS is used to represent any numerical values, including integers and decimal numbers.
Basic Arithmetic Operators
Operators are the symbols that perform particular operations.
- + (addition)
- – (subtraction)
- asterisk (multiplication)
- / (division)
- % (modulo)
JS evaluates more complex expressions using the general math order of operations aka PEMDAS.
- PEMDAS : Parentheses, Exponents, Multiplication, Division, Modulo, Addition, Subtraction.
- To force a specific order of operation, use the group operator ( ) around a part of the expression.
Modulo : Very useful operation to check divisibility of numbers, check for even & odd, whether a number is prime, and much more! (Discrete Math concept, circular problems can be solved with modulo)
- Whenever you have a smaller number % a larger number, the answer will just be the initial small number.
console.log(7 % 10) // => 7;
The String Data Type
The string data type is a primitive data type that used to represent textual data.
- can be wrapped by either single or double quotation marks, best to choose one and stick with it for consistency.
If your string contains quotation marks inside, can layer single or double quotation marks to allow it to work.
“That’s a great string”; (valid)‘Shakespeare wrote, “To be or not to be”’; (valid)
‘That’s a bad string’; (invalid)
- Alt. way to add other quotes within strings is to use template literals.
`This is a temp’l’ate literal ${function}` // use ${} to invoke functions within. - .length : property that can be appended to data to return the length.
- empty strings have a length of zero.
- indices : indexes of data that begin at 0, can call upon index by using the bracket notation [ ].
console.log(“bootcamp”[0]); // => “b”
console.log(“bootcamp”[10]); // => “undefined”
console.log(“boots”[1 * 2]); // => “o”
console.log(“boots”[“boot”.length-1]); // => “t” - we can pass expressions through the brackets as well since JS always evaluates expressions first.
- The index of the last character of a string is always one less than it’s length.
- indexOf() : method used to find the first index of a given character within a string.
console.log(“bagel”.indexOf(“b”)); // => 0
console.log(“bagel”.indexOf(“z”)); // => -1 - if the character inside the indexOf() search does not exist in the string, the output will be -1.
- the indexOf() search will return the first instanced index of the the char in the string.
- concatenate : word to describe joining strings together into a single string.
The Boolean Data Type
The Boolean data type is the simplest data type since there are only two values: true and false.
- Logical Operators (Boolean Operators) are used to establish logic in our code.
- ! (not) : reverses a Boolean value.
console.log(!true); // => false
console.log(!!false); // => false - Logical Order of Operations : JS will evaluate !, then &&, then ||.
- Short-Circuit Evaluation : Because JS evalutes from left to right, expressions can “short-circuit”. For example if we have true on the left of an || logical comparison, it will stop evaluating and yield true instead of wasting resources on processing the rest of the statement.
console.log(true || !false) // => stops after it sees “true ||”
Comparison Operators
All comparison operators will result in a boolean output.
The relative comparators
- > (greater than)
- < (less than)
- >= (greater than or equal to)
- <= (less than or equal to)
- === (equal to)
- !== (not equal to)
Fun Fact: “a” < “b” is considered valid JS Code because string comparisons are compared lexicographically (meaning dictionary order), so “a” is less than “b” because it appears earlier!
If there is ever a standstill comparison of two string lexicographically (i.e. app vs apple) the comparison will deem the shorter string lesser.
Difference between == and ===
===
Strict Equality, will only return true if the two comparisons are entirely the same.
==
Loose Equality, will return true even if the values are of a different type, due to coercion. (Avoid using this)
Variables
Variables are used to store information to be referenced and manipulated in a program.
- We initialize a variable by using the let keyword and a = single equals sign (assignment operator).
let bootcamp = “App Academy”;
console.log(bootcamp); // “App Academy” - JS variable names can contain any alphanumeric characters, underscores, or dollar signs (cannot being with a number).
- If you do not declare a value for a variable, undefined is automatically set.
let bootcamp;
console.log(bootcamp); // undefined - We can change the value of a previously declared variable (let, not const) by re-assigning it another value.
- let is the updated version of var; there are some differences in terms of hoisting and global/block scope
Assignment Shorthand
let num = 0;
num += 10; // same as num = num + 10
num -= 2; // same as num = num — 2
num /= 4; // same as num = num / 4
num *= 7; // same as num = num * 7
- In general, any nonsensical arithmetic will result in NaN ; usually operations that include undefined.
Functions
A function is a procedure of code that will run when called. Functions are used so that we do not have to rewrite code to do the same thing over and over. (Think of them as ‘subprograms’)
- Function Declaration : Process when we first initially write our function.
- Includes three things:
- Name of the function.
- A list of parameters ()
- The code to execute {}
- Function Calls : We can call upon our function whenever and wherever* we want. (*wherever is only after the initial declaration)
- JS evaluates code top down, left to right.
- When we execute a declared function later on in our program we refer to this as invoking our function.
- Every function in JS returns undefined unless otherwise specified.
- When we hit a return statement in a function we immediately exit the function and return to where we called the function.
- When naming functions in JS always use camelCase and name it something appropriate.
Greate code reads like English and almost explains itself. Think: Elegant, readable, and maintainable!
Parameters and Arguments
- Parameters : Comma seperated variables specified as part of a function’s declaration.
- Arguments : Values passed to the function when it is invoked.
- If the number of arguments passed during a function invocation is different than the number of paramters listed, it will still work.
- However, is there are not enough arguments provided for parameters our function will likely yield Nan.
Including Comments
Comments are important because they help other people understand what is going on in your code or remind you if you forgot something yourself. Keep in mind that they have to be marked properly so the browser won’t try to execute them.
In JavaScript you have two different options:
- Single-line comments — To include a comment that is limited to a single line, precede it with
// - Multi-line comments — In case you want to write longer comments between several lines, wrap it in
/*and*/to avoid it from being executed
Variables in JavaScript
Variables are stand-in values that you can use to perform operations. You should be familiar with them from math class.
var, const, let
You have three different possibilities for declaring a variable in JavaScript, each with their own specialties:
var— The most common variable. It can be reassigned but only accessed within a function. Variables defined withvarmove to the top when the code is executed.const— Can not be reassigned and not accessible before they appear within the code.let— Similar toconst, theletvariable can be reassigned but not re-declared.
Data Types
Variables can contain different types of values and data types. You use = to assign them:
- Numbers —
var age = 23 - Variables —
var x - Text (strings) —
var a = "init" - Operations —
var b = 1 + 2 + 3 - True or false statements —
var c = true - Constant numbers —
const PI = 3.14 - Objects —
var name = {firstName:"John", lastName:"Doe"}
There are more possibilities. Note that variables are case sensitive. That means lastname and lastName will be handled as two different variables.
Objects
Objects are certain kinds of variables. They are variables that can have their own values and methods. The latter are actions that you can perform on objects.
var person = {
firstName:”John”,
lastName:”Doe”,
age:20,
nationality:”German”
};
The Next Level: Arrays
Next up in our JavaScript cheat sheet are arrays. Arrays are part of many different programming languages. They are a way of organizing variables and properties into groups. Here’s how to create one in JavaScript:
var fruit = [“Banana”, “Apple”, “Pear”];
Now you have an array called fruit which contains three items that you can use for future operations.
Array Methods
Once you have created arrays, there are a few things you can do with them:
concat()— Join several arrays into oneindexOf()— Returns the first position at which a given element appears in an arrayjoin()— Combine elements of an array into a single string and return the stringlastIndexOf()— Gives the last position at which a given element appears in an arraypop()— Removes the last element of an arraypush()— Add a new element at the endreverse()— Sort elements in a descending ordershift()— Remove the first element of an arrayslice()— Pulls a copy of a portion of an array into a new arraysort()— Sorts elements alphabeticallysplice()— Adds elements in a specified way and positiontoString()— Converts elements to stringsunshift()—Adds a new element to the beginningvalueOf()— Returns the primitive value of the specified object
Operators
If you have variables, you can use them to perform different kinds of operations. To do so, you need operators.
Basic Operators
+— Addition-— Subtraction*— Multiplication/— Division(...)— Grouping operator, operations within brackets are executed earlier than those outside%— Modulus (remainder )++— Increment numbers--— Decrement numbers
Comparison Operators
==— Equal to===— Equal value and equal type!=— Not equal!==— Not equal value or not equal type>— Greater than<— Less than>=— Greater than or equal to<=— Less than or equal to?— Ternary operator
Logical Operators
&&— Logical and||— Logical or!— Logical not
Bitwise Operators
&— AND statement|— OR statement~— NOT^— XOR<<— Left shift>>— Right shift>>>— Zero fill right shift
Functions
JavaScript functions are blocks of code that perform a certain task. A basic function looks like this:
function name(parameter1, parameter2, parameter3) {
// what the function does
}
As you can see, it consists of the function keyword plus a name. The function’s parameters are in the brackets and you have curly brackets around what the function performs. You can create your own, but to make your life easier – there are also a number of default functions.
Outputting Data
A common application for functions is the output of data. For the output, you have the following options:
alert()— Output data in an alert box in the browser windowconfirm()— Opens up a yes/no dialog and returns true/false depending on user clickconsole.log()— Writes information to the browser console, good for debugging purposesdocument.write()— Write directly to the HTML documentprompt()— Creates a dialogue for user input
Global Functions
Global functions are functions built into every browser capable of running JavaScript.
decodeURI()— Decodes a Uniform Resource Identifier (URI) created byencodeURIor similardecodeURIComponent()— Decodes a URI componentencodeURI()— Encodes a URI into UTF-8encodeURIComponent()— Same but for URI componentseval()— Evaluates JavaScript code represented as a stringisFinite()— Determines whether a passed value is a finite numberisNaN()— Determines whether a value is NaN or notNumber()—- Returns a number converted from its argumentparseFloat()— Parses an argument and returns a floating-point numberparseInt()— Parses its argument and returns an integer
JavaScript Loops
Loops are part of most programming languages. They allow you to execute blocks of code desired number of times with different values:
for (before loop; condition for loop; execute after loop) {
// what to do during the loop
}
You have several parameters to create loops:
for— The most common way to create a loop in JavaScriptwhile— Sets up conditions under which a loop executesdo while— Similar to thewhileloop but it executes at least once and performs a check at the end to see if the condition is met to execute againbreak—Used to stop and exit the cycle at certain conditionscontinue— Skip parts of the cycle if certain conditions are met
If — Else Statements
These types of statements are easy to understand. Using them, you can set conditions for when your code is executed. If certain conditions apply, something is done, if not — something else is executed.
if (condition) {
// what to do if condition is met
} else {
// what to do if condition is not met
}
A similar concept to if else is the switch statement. However, using the switch you select one of several code blocks to execute.
Strings
Strings are what JavaScript calls to text that does not perform a function but can appear on the screen.
var person = “John Doe”;
In this case, John Doe is the string.
Escape Characters
In JavaScript, strings are marked with single or double-quotes. If you want to use quotation marks in a string, you need to use special characters:
\'— Single quote\"— Double quote
Aside from that you also have additional escape characters:
\\— Backslash\b— Backspace\f— Form feed\n— New line\r— Carriage return\t— Horizontal tabulator\v— Vertical tabulator
String Methods
There are many different ways to work with strings:
charAt()— Returns a character at a specified position inside a stringcharCodeAt()— Gives you the Unicode of a character at that positionconcat()— Concatenates (joins) two or more strings into onefromCharCode()— Returns a string created from the specified sequence of UTF-16 code unitsindexOf()— Provides the position of the first occurrence of a specified text within a stringlastIndexOf()— Same asindexOf()but with the last occurrence, searching backwardmatch()— Retrieves the matches of a string against a search patternreplace()— Find and replace specified text in a stringsearch()— Executes a search for a matching text and returns its positionslice()— Extracts a section of a string and returns it as a new stringsplit()— Splits a string object into an array of strings at a specified positionsubstr()— Similar toslice()but extracts a substring depending on a specified number of characterssubstring()— Also similar toslice()but can’t accept negative indicestoLowerCase()— Convert strings to lower casetoUpperCase()— Convert strings to upper casevalueOf()— Returns the primitive value (that has no properties or methods) of a string object
Regular Expression Syntax
Regular expressions are search patterns used to match character combinations in strings. The search pattern can be used for text search and text to replace operations.
Pattern Modifiers
e— Evaluate replacementi— Perform case-insensitive matchingg— Perform global matchingm— Perform multiple line matchings— Treat strings as a single linex— Allow comments and whitespace in the patternU— Ungreedy pattern
Brackets
[abc]— Find any of the characters between the brackets[^abc]— Find any character which is not in the brackets[0-9]— Used to find any digit from 0 to 9[A-z]— Find any character from uppercase A to lowercase z(a|b|c)— Find any of the alternatives separated with|
Metacharacters
.— Find a single character, except newline or line terminator\w— Word character\W— Non-word character\d— A digit\D— A non-digit character\s— Whitespace character\S— Non-whitespace character\b— Find a match at the beginning/end of a word\B— A match not at the beginning/end of a word\0— NUL character\n— A new line character\f— Form feed character\r— Carriage return character\t— Tab character\v— Vertical tab character\xxx— The character specified by an octal number xxx\xdd— Character specified by a hexadecimal number dd\uxxxx— The Unicode character specified by a hexadecimal number XXXX
Quantifiers
n+— Matches any string that contains at least one nn*— Any string that contains zero or more occurrences of nn?— A string that contains zero or one occurrence of nn{X}— String that contains a sequence of X n’sn{X,Y}— Strings that contain a sequence of X to Y n’sn{X,}— Matches any string that contains a sequence of at least X n’sn$— Any string with n at the end of it^n— String with n at the beginning of it?=n— Any string that is followed by a specific string n?!n— String that is not followed by a specific string ni
Numbers and Math
In JavaScript, you can also work with numbers, constants and perform mathematical functions.
Number Properties
MAX_VALUE— The maximum numeric value representable in JavaScriptMIN_VALUE— Smallest positive numeric value representable in JavaScriptNaN— The “Not-a-Number” valueNEGATIVE_INFINITY— The negative Infinity valuePOSITIVE_INFINITY— Positive Infinity value
Number Methods
toExponential()— Returns the string with a rounded number written as exponential notationtoFixed()— Returns the string of a number with a specified number of decimalstoPrecision()— String of a number written with a specified lengthtoString()— Returns a number as a stringvalueOf()— Returns a number as a number
Math Properties
E— Euler’s numberLN2— The natural logarithm of 2LN10— Natural logarithm of 10LOG2E— Base 2 logarithm of ELOG10E— Base 10 logarithm of EPI— The number PISQRT1_2— Square root of 1/2SQRT2— The square root of 2
Math Methods
abs(x)— Returns the absolute (positive) value of xacos(x)— The arccosine of x, in radiansasin(x)— Arcsine of x, in radiansatan(x)— The arctangent of x as a numeric valueatan2(y,x)— Arctangent of the quotient of its argumentsceil(x)— Value of x rounded up to its nearest integercos(x)— The cosine of x (x is in radians)exp(x)— Value of Exfloor(x)— The value of x rounded down to its nearest integerlog(x)— The natural logarithm (base E) of xmax(x,y,z,...,n)— Returns the number with the highest valuemin(x,y,z,...,n)— Same for the number with the lowest valuepow(x,y)— X to the power of yrandom()— Returns a random number between 0 and 1round(x)— The value of x rounded to its nearest integersin(x)— The sine of x (x is in radians)sqrt(x)— Square root of xtan(x)— The tangent of an angle
Dealing with Dates in JavaScript
You can also work with and modify dates and time with JavaScript. This is the next chapter in the JavaScript cheat sheet.
Setting Dates
Date()— Creates a new date object with the current date and timeDate(2017, 5, 21, 3, 23, 10, 0)— Create a custom date object. The numbers represent a year, month, day, hour, minutes, seconds, milliseconds. You can omit anything you want except for a year and month.Date("2017-06-23")— Date declaration as a string
Pulling Date and Time Values
getDate()— Get the day of the month as a number (1-31)getDay()— The weekday as a number (0-6)getFullYear()— Year as a four-digit number (yyyy)getHours()— Get the hour (0-23)getMilliseconds()— The millisecond (0-999)getMinutes()— Get the minute (0-59)getMonth()— Month as a number (0-11)getSeconds()— Get the second (0-59)getTime()— Get the milliseconds since January 1, 1970getUTCDate()— The day (date) of the month in the specified date according to universal time (also available for day, month, full year, hours, minutes etc.)parse— Parses a string representation of a date and returns the number of milliseconds since January 1, 1970
Set Part of a Date
setDate()— Set the day as a number (1-31)setFullYear()— Sets the year (optionally month and day)setHours()— Set the hour (0-23)setMilliseconds()— Set milliseconds (0-999)setMinutes()— Sets the minutes (0-59)setMonth()— Set the month (0-11)setSeconds()— Sets the seconds (0-59)setTime()— Set the time (milliseconds since January 1, 1970)setUTCDate()— Sets the day of the month for a specified date according to universal time (also available for day, month, full year, hours, minutes etc.)
DOM Mode
The DOM is the Document Object Model of a page. It is the code of the structure of a webpage. JavaScript comes with a lot of different ways to create and manipulate HTML elements (called nodes).
Node Properties
attributes— Returns a live collection of all attributes registered to an elementbaseURI— Provides the absolute base URL of an HTML elementchildNodes— Gives a collection of an element’s child nodesfirstChild— Returns the first child node of an elementlastChild— The last child node of an elementnextSibling— Gives you the next node at the same node tree levelnodeName—Returns the name of a nodenodeType— Returns the type of a nodenodeValue— Sets or returns the value of a nodeownerDocument— The top-level document object for this nodeparentNode— Returns the parent node of an elementpreviousSibling— Returns the node immediately preceding the current onetextContent— Sets or returns the textual content of a node and its descendants
Node Methods
appendChild()— Adds a new child node to an element as the last child nodecloneNode()— Clones an HTML elementcompareDocumentPosition()— Compares the document position of two elementsgetFeature()— Returns an object which implements the APIs of a specified featurehasAttributes()— Returns true if an element has any attributes, otherwise falsehasChildNodes()— Returns true if an element has any child nodes, otherwise falseinsertBefore()— Inserts a new child node before a specified, existing child nodeisDefaultNamespace()— Returns true if a specified namespaceURI is the default, otherwise falseisEqualNode()— Checks if two elements are equalisSameNode()— Checks if two elements are the same nodeisSupported()— Returns true if a specified feature is supported on the elementlookupNamespaceURI()— Returns the namespace URI associated with a given nodelookupPrefix()— Returns a DOMString containing the prefix for a given namespace URI if presentnormalize()— Joins adjacent text nodes and removes empty text nodes in an elementremoveChild()— Removes a child node from an elementreplaceChild()— Replaces a child node in an element
Element Methods
getAttribute()— Returns the specified attribute value of an element nodegetAttributeNS()— Returns string value of the attribute with the specified namespace and namegetAttributeNode()— Gets the specified attribute nodegetAttributeNodeNS()— Returns the attribute node for the attribute with the given namespace and namegetElementsByTagName()— Provides a collection of all child elements with the specified tag namegetElementsByTagNameNS()— Returns a live HTMLCollection of elements with a certain tag name belonging to the given namespacehasAttribute()— Returns true if an element has any attributes, otherwise falsehasAttributeNS()— Provides a true/false value indicating whether the current element in a given namespace has the specified attributeremoveAttribute()— Removes a specified attribute from an elementremoveAttributeNS()— Removes the specified attribute from an element within a certain namespaceremoveAttributeNode()— Takes away a specified attribute node and returns the removed nodesetAttribute()— Sets or changes the specified attribute to a specified valuesetAttributeNS()— Adds a new attribute or changes the value of an attribute with the given namespace and namesetAttributeNode()— Sets or changes the specified attribute nodesetAttributeNodeNS()— Adds a new namespaced attribute node to an element
Working with the User Browser
Besides HTML elements, JavaScript is also able to take into account the user browser and incorporate its properties into the code.
Window Properties
closed— Checks whether a window has been closed or not and returns true or falsedefaultStatus— Sets or returns the default text in the status bar of a windowdocument— Returns the document object for the windowframes— Returns all<iframe>elements in the current windowhistory— Provides the History object for the windowinnerHeight— The inner height of a window’s content areainnerWidth— The inner width of the content arealength— Find out the number of<iframe>elements in the windowlocation— Returns the location object for the windowname— Sets or returns the name of a windownavigator— Returns the Navigator object for the windowopener— Returns a reference to the window that created the windowouterHeight— The outer height of a window, including toolbars/scrollbarsouterWidth— The outer width of a window, including toolbars/scrollbarspageXOffset— Number of pixels the current document has been scrolled horizontallypageYOffset— Number of pixels the document has been scrolled verticallyparent— The parent window of the current windowscreen— Returns the Screen object for the windowscreenLeft— The horizontal coordinate of the window (relative to the screen)screenTop— The vertical coordinate of the windowscreenX— Same asscreenLeftbut needed for some browsersscreenY— Same asscreenTopbut needed for some browsersself— Returns the current windowstatus— Sets or returns the text in the status bar of a windowtop— Returns the topmost browser window
Window Methods
alert()— Displays an alert box with a message and an OK buttonblur()— Removes focus from the current windowclearInterval()— Clears a timer set withsetInterval()clearTimeout()— Clears a timer set withsetTimeout()close()— Closes the current windowconfirm()— Displays a dialogue box with a message and an OK and Cancel buttonfocus()— Sets focus to the current windowmoveBy()— Moves a window relative to its current positionmoveTo()— Moves a window to a specified positionopen()— Opens a new browser windowprint()— Prints the content of the current windowprompt()— Displays a dialogue box that prompts the visitor for inputresizeBy()— Resizes the window by the specified number of pixelsresizeTo()— Resizes the window to a specified width and heightscrollBy()— Scrolls the document by a specified number of pixelsscrollTo()— Scrolls the document to specified coordinatessetInterval()— Calls a function or evaluates an expression at specified intervalssetTimeout()— Calls a function or evaluates an expression after a specified intervalstop()— Stops the window from loading
Screen Properties
availHeight— Returns the height of the screen (excluding the Windows Taskbar)availWidth— Returns the width of the screen (excluding the Windows Taskbar)colorDepth— Returns the bit depth of the color palette for displaying imagesheight— The total height of the screenpixelDepth— The color resolution of the screen in bits per pixelwidth— The total width of the screen
JavaScript Events
Events are things that can happen to HTML elements and are performed by the user. The programming language can listen for these events and trigger actions in the code. No JavaScript cheat sheet would be complete without them.
Mouse
onclick— The event occurs when the user clicks on an elementoncontextmenu— User right-clicks on an element to open a context menuondblclick— The user double-clicks on an elementonmousedown— User presses a mouse button over an elementonmouseenter— The pointer moves onto an elementonmouseleave— Pointer moves out of an elementonmousemove— The pointer is moving while it is over an elementonmouseover— When the pointer is moved onto an element or one of its childrenonmouseout— User moves the mouse pointer out of an element or one of its childrenonmouseup— The user releases a mouse button while over an element
Keyboard
onkeydown— When the user is pressing a key downonkeypress— The moment the user starts pressing a keyonkeyup— The user releases a key
Frame
onabort— The loading of a media is abortedonbeforeunload— Event occurs before the document is about to be unloadedonerror— An error occurs while loading an external fileonhashchange— There have been changes to the anchor part of a URLonload— When an object has loadedonpagehide— The user navigates away from a webpageonpageshow— When the user navigates to a webpageonresize— The document view is resizedonscroll— An element’s scrollbar is being scrolledonunload— Event occurs when a page has unloaded
Form
onblur— When an element loses focusonchange— The content of a form element changes (for<input>,<select>and<textarea>)onfocus— An element gets focusonfocusin— When an element is about to get focusonfocusout— The element is about to lose focusoninput— User input on an elementoninvalid— An element is invalidonreset— A form is resetonsearch— The user writes something in a search field (for<input="search">)onselect— The user selects some text (for<input>and<textarea>)onsubmit— A form is submitted
Drag
ondrag— An element is draggedondragend— The user has finished dragging the elementondragenter— The dragged element enters a drop targetondragleave— A dragged element leaves the drop targetondragover— The dragged element is on top of the drop targetondragstart— User starts to drag an elementondrop— Dragged element is dropped on the drop target
Clipboard
oncopy— User copies the content of an elementoncut— The user cuts an element’s contentonpaste— A user pastes the content in an element
Media
onabort— Media loading is abortedoncanplay— The browser can start playing media (e.g. a file has buffered enough)oncanplaythrough— The browser can play through media without stoppingondurationchange— The duration of the media changesonended— The media has reached its endonerror— Happens when an error occurs while loading an external fileonloadeddata— Media data is loadedonloadedmetadata— Metadata (like dimensions and duration) are loadedonloadstart— The browser starts looking for specified mediaonpause— Media is paused either by the user or automaticallyonplay— The media has been started or is no longer pausedonplaying— Media is playing after having been paused or stopped for bufferingonprogress— The browser is in the process of downloading the mediaonratechange— The playing speed of the media changesonseeked— User is finished moving/skipping to a new position in the mediaonseeking— The user starts moving/skippingonstalled— The browser is trying to load the media but it is not availableonsuspend— The browser is intentionally not loading mediaontimeupdate— The playing position has changed (e.g. because of fast forward)onvolumechange— Media volume has changed (including mute)onwaiting— Media paused but expected to resume (for example, buffering)
Animation
animationend— A CSS animation is completeanimationiteration— CSS animation is repeatedanimationstart— CSS animation has started
Other
transitionend— Fired when a CSS transition has completedonmessage— A message is received through the event sourceonoffline— The browser starts to work offlineononline— The browser starts to work onlineonpopstate— When the window’s history changesonshow— A<menu>element is shown as a context menuonstorage— A Web Storage area is updatedontoggle— The user opens or closes the<details>elementonwheel— Mouse wheel rolls up or down over an elementontouchcancel— Screen-touch is interruptedontouchend— User’s finger is removed from a touch-screenontouchmove— A finger is dragged across the screenontouchstart— A finger is placed on the touch-screen
Errors
When working with JavaScript, different errors can occur. There are several ways of handling them:
try— Lets you define a block of code to test for errorscatch— Set up a block of code to execute in case of an errorthrow— Create custom error messages instead of the standard JavaScript errorsfinally— Lets you execute code, after try and catch, regardless of the result
Error Name Values
JavaScript also has a built-in error object. It has two properties:
name— Sets or returns the error namemessage— Sets or returns an error message in a string from
The error property can return six different values as its name:
EvalError— An error has occurred in theeval()functionRangeError— A number is “out of range”ReferenceError— An illegal reference has occurredSyntaxError— A syntax error has occurredTypeError— A type error has occurredURIError— AnencodeURI()error has occurred
https://gist.github.com/bgoonz/736fce1327efdde3afc50229f5ce51f6#file-javascript-cheat-sheet-js
Explicit Conversions
The simplest way to perform an explicit type conversion is to use the Boolean(), Number(), and String() functions.
Any value other than null or undefined has a toString() method.
n.toString(2);
binary
n.toString(8);
octal
n.toString(16);
hex
let n = 123456.789;
n.toFixed(0)
“123457”
n.toFixed(5)
“123456.78900”
n.toExponential(3)
“1.235e+5”
n.toPrecision(7)
“123456.8”
n.toPrecision(10)
“123456.7890”
parseInt("3 blind mice")
3
parseFloat(" 3.14 meters")
3.14
parseInt("-12.34")
-12
parseInt("0xFF")
255
Types, Values, and Variables
Links
Resource
URL
MDN
https://developer.mozilla.org/en-US/docs/Web/JavaScript
Run Snippets
https://developers.google.com/web/tools/chrome-devtools/javascript/snippets
Explicit Conversions
The simplest way to perform an explicit type conversion is to use the Boolean(), Number(), and String() functions.
Any value other than null or undefined has a toString() method.
n.toString(2);
binary
n.toString(8);
octal
n.toString(16);
hex
let n = 123456.789;
n.toFixed(0)
“123457”
n.toFixed(5)
“123456.78900”
n.toExponential(3)
“1.235e+5”
n.toPrecision(7)
“123456.8”
n.toPrecision(10)
“123456.7890”
parseInt("3 blind mice")
3
parseFloat(" 3.14 meters")
3.14
parseInt("-12.34")
-12
parseInt("0xFF")
255
parseInt("0xff")
255
parseInt("-0XFF")
-255
parseInt("0.1")
0
parseInt(".1")
NaN: integers can’t start with “.”
parseFloat("$72.47")
NaN: numbers can’t start with “$”
Supply Radix
parseInt("11", 2)
3
parseInt("ff", 16)
255
parseInt("077", 8)
63
Conversion Idioms
x + ""
String(x)
+x
Number(x)
x-0
Number(x)
!!x
Boolean(x)
Destructuring Assignment
let [x,y] = [1,2];
let x=1, y=2
[x,y] = [x + 1,y + 1];
x = x + 1, y = y + 1
[x,y] = [y,x];
Swap the value of the two variables
Destructuring assignment makes it easy to work with functions that return arrays of values:
let [r,theta] = toPolar(1.0, 1.0);
function toPolar(x, y) {
return [Math.sqrt(x*x+y*y), Math.atan2(y,x)];
}
Variable destructuring in loops:
let o = { x: 1, y: 2 };
for(const [name, value] of Object.entries(o)) {
console.log(name, value); // Prints "x 1" and "y 2"
}
Note: The Object.entries() method returns an array of a given object’s own enumerable string-keyed property [key, value] pairs, in the same order as that provided by a for...in loop. (The only important difference is that a for...in loop enumerates properties in the prototype chain as well).
The list of variables on the left can include extra commas to skip certain values on the right
[,x,,y] = [1,2,3,4];
x == 2; y == 4
Note: the last comma does not stand for a value.
To collect all unused or remaining values into a single variable when destructuring an array, use three dots (...) before the last variable name on the left-hand side
let [x, ...y] = [1,2,3,4];
y == [2,3,4]
let [first, ...rest] = "Hello";
first == “H”; rest ==[“e”,”l”,”l”,”o”]
Destructuring assignment can also be performed when the righthand side is an object value.
let transparent = {r: 0.0, g: 0.0, b: 0.0, a: 1.0};
let {r, g, b} = transparent;
r == 0.0; g == 0.0; b == 0.0
const {sin, cos, tan} = Math;
sin=Math.sin, cos=Math.cos, tan=Math.tan
Expressions and Operators
In JavaScript, the values null and undefined are the only two values that do not have properties. In a regular property access expression using . or [], you get a TypeError if the expression on the left evaluates to null or undefined. You can use ?. and ?.[] syntax to guard against errors of this type.
You can also invoke a function using ?.() instead of ().
With the new ?.() invocation syntax, if the expression to the left of the ?. evaluates to null or undefined, then the entire invocation expression evaluates to undefined and no exception is thrown.
Write the function invocation using ?.(), knowing that invocation will only happen if there is actually a value to be invoked
function square(x, log) {
log?.(x); // Call the function if there is one
return x * x;
}
Note that expression x++ is not always the same as x = x + 1.The ++ operator never performs string concatenation: it always converts its operand to a number and increments it. If x is the string “1”, ++x is the number 2, but x + 1 is the string “11”.
JavaScript objects are compared by reference, not by value. An object is equal to itself, but not to any other object. If two distinct objects have the same number of properties, with the same names and values, they are still not equal. Similarly, two arrays that have the same elements in the same order are not equal to each other.
NaN value is never equal to any other value, including itself! To check whether a value x is NaN, use x !== , or the global isNaN() function.
If both values refer to the same object, array, or function, they are equal. If they refer to different objects, they are not equal, even if both objects have identical properties.
Evaluating Expressions
JavaScript has the ability to interpret strings of JavaScript source code, evaluating them to produce a value.
eval("3+2")
Because of security issues, some web servers use the HTTP “Content-Security-Policy” header to disable eval() for an entire website.
First-Defined (??)
The first-defined operator ?? evaluates to its first defined operand: if its left operand is not null and not undefined, it returns that value.
a ?? b is equivalent to (a !== null && a !== undefined) ? a : b
?? is a useful alternative to ||. The problem with this idiomatic use is that zero, the empty string, and false are all falsy values that may be perfectly valid in some circumstances. In this code example, if maxWidth is zero, that value will be ignored. But if we change the || operator to ??, we end up with an expression where zero is a valid value.
let max = maxWidth || preferences.maxWidth || 500;
let max = maxWidth ?? preferences.maxWidth ?? 500;
delete Operator
Deleting an array element leaves a “hole” in the array and does not change the array’s length. The resulting array is sparse.
void Operator
Using the void operator makes sense only if the operand has side effects.
let counter = 0;
const increment = () => void counter++;
increment()
undefined
counter
1
Statements
Expressions are evaluated to produce a value, but statements are executed to make something happen.
Expressions with side effects, such as assignments and function invocations, can stand alone as statements, and when used this way are known as expression statements.
A similar category of statements are the declaration statements that declare new variables and define new functions.
If a function does not have any side effects, there is no sense in calling it, unless it is part of a larger expression or an assignment statement.
for/of
The for/of loop works with iterable objects. Arrays, strings, sets, and maps are iterable.
Array
let data = [1, 2, 3, 4, 5, 6, 7, 8, 9], sum = 0;
for(let element of data) {
sum += element;
}
let text = "Na na na na na na na na";
let wordSet = new Set(text.split(" "));
let unique = [];
for(let word of wordSet) {
unique.push(word);
}
String
let frequency = {};
for(let letter of "mississippi") {
if (frequency[letter]) {
frequency[letter]++;
}
else {
frequency[letter] = 1;
}
}
Map
let m = new Map([[1, "one"]]);
for(let [key, value] of m) {
key // => 1
value // => "one"
}
Objects are not (by default) iterable. Attempting to use for/of on a regular object throws a TypeError at runtime.
If you want to iterate through the properties of an object, you can use the for/in loop.
Note: for/of can be used on objects with Object.entries property, but it will not pick properties from object’s prototype.
for/in
for/in loop works with any object after the in.
for(let p in o) {
console.log(o[p]);
}
Note: this will enumerate array indexes, not values.
for(let i in a) console.log(i);
The for/in loop does not actually enumerate all properties of an object. It does not enumerate properties whose names are symbols. And of the properties whose names are strings, it only loops over the enumerableproperties.
with
The with statement runs a block of code as if the properties of a specified object were variables in scope for that code.
The with statement is forbidden in strict mode and should be considered deprecated in non-strict mode: avoid using it whenever possible.
document.forms[0].address.value
with(document.forms[0]) {
name.value = "";
address.value = "";
email.value = "";
}
debugger
If a debugger program is available and is running, then an implementation may (but is not required to) perform some kind of debugging action.
In practice, this statement acts like a breakpoint: execution of JavaScript code stops, and you can use the debugger to print variables’ values, examine the call stack, and so on.
Note that it is not enough to have a debugger available: the debugger statement won’t start the debugger for you. If you’re using a web browser and have the developer tools console open, however, this statement will cause a breakpoint.
use strict
Strict mode is a restricted subset of the language that fixes important language deficiencies and provides stronger error checking and increased security.
The differences between strict mode and non-strict mode are the following:
· The with statement is not allowed in strict mode.
· In strict mode, all variables must be declared: a ReferenceError is thrown if you assign a value to an identifier that is not a declared variable, function, function parameter, catch clause parameter, or property of the global object.
· In non-strict mode, this implicitly declares a global variable by adding a new property to the global object.
· In strict mode, functions invoked as functions (rather than as methods) have a this value of undefined. (In non-strict mode, functions invoked as functions are always passed the global object as their this value.)
· A function is invoked with call() or apply() , the this value is exactly the value passed as the first argument to call() or apply(). (In non-strict mode, null and undefined values are replaced with the global object and non-object values are converted to objects.)
· In strict mode, assignments to non-writable properties and attempts to create new properties on non-extensible objects throw a TypeError. (In non-strict mode, these attempts fail silently.)
· In strict mode, code passed to eval() cannot declare variables or define functions in the caller’s scope as it can in non-strict mode. Instead, variable and function definitions live in a new scope created for the eval(). This scope is discarded when the eval() returns.
· In strict mode, the Arguments object in a function holds a static copy of the values passed to the function. In non-strict mode, the Arguments object has “magical” behavior in which elements of the array and named function parameters both refer to the same value.
· In strict mode, a SyntaxError is thrown if the delete operator is followed by an unqualified identifier such as a variable, function, or function parameter. (In non-strict mode, such a delete expression does nothing and evaluates to false.)
· In strict mode, an attempt to delete a non-configurable property throws a TypeError. (In non-strict mode, the attempt fails and the delete expression evaluates to false.)
· In strict mode, it is a syntax error for an object literal to define two or more properties by the same name. (In non-strict mode, no error occurs.)
Objects
In addition to its name and value, each property has three property attributes:
· The writable attribute specifies whether the value of the property can be set.
· The enumerable attribute specifies whether the property name is returned by a for/in loop.
· The configurable attribute specifies whether the property can be deleted and whether its attributes can be altered.
Prototypes
All objects created by object literals have the same prototype object, Object.prototype.
Objects created using the new keyword and a constructor invocation use the value of the prototype property of the constructor function as their prototype.
Object created by new Object() inherits from Object.prototype, just as the object created by {} does. Similarly, the object created by new Array() uses Array.prototype as its prototype, and the object created by new Date() uses Date.prototype as its prototype.
Almost all objects have a prototype, but only a relatively small number of objects have a prototype property. It is these objects with prototype properties that define the prototypes for all the other objects.
Most built-in constructors (and most user-defined constructors) have a prototype that inherits from Object.prototype.
Date.prototype inherits properties from Object.prototype, so a Date object created by new Date() inherits properties from both Date.prototype and Object.prototype. This linked series of prototype objects is known as a prototype chain.
Creating Objects
Objects can be created with object literals, with the new keyword, and with the Object.create() function.
Literal
let empty = {};
let point = { x: 0, y: 0 };
let book = {
"main title": "JavaScript",
"sub-title": "The Definitive Guide",
for: "all audiences",
author: {
firstname: "David", .
surname: "Flanagan"
}
};
new
let o = new Object();let a = new Array();let d = new Date();let r = new Map();
Object.create
let o3 = Object.create(Object.prototype);
Use Object.create to guard against accidental modifications:
let o = { x: "don't change this value" };
library.function(Object.create(o));
Note: the library function can modify the passed in object, but not the original o object
Access Object Properties with an array ([]) notation
let addr = "";
for(let i = 0; i < 4; i++) {
addr += customer[`address${i}`] + "\n";
}
Inheritance
let o = {};
o.x = 1;
let p = Object.create(o);
p.y = 2;
let q = Object.create(p);
q.z = 3;
Property x and y available on object q
q.x + q.y
How to query for property which may be undefined
surname = book && book.author && book.author.surname;
let surname = book?.author?.surname;
Deleting properties
The delete operator only deletes own properties, not inherited ones. (To delete an inherited property, you must delete it from the prototype object in which it is defined. Doing this affects every object that inherits from that prototype.)
delete does not remove properties that have a configurable attribute of false.
Certain properties of built-in objects are non-configurable, as are properties of the global object created by variable declaration and function declaration.
delete Object.prototype
false: property is non-configurable
var x = 1;
delete globalThis.x
false: can’t delete this property
function f() {}
delete globalThis.f
false
globalThis.x = 1;
delete globalThis.x
true
Testing properties
To check whether an object has a property with a given name. You can do this with the in operator, with the hasOwnProperty() and propertyIsEnumerable() methods, or simply by querying the property
( != undefined).
in & query
let o = { x: 1 };
"x" in o
true
o.x !== undefined
"y" in o
false
o.y !== undefined
"toString" in o
true: o inherits a toString property
o.toString !== undefined
Advantage of using in: in can distinguish between properties that do not exist and properties that exist but have been set to undefined.
hasOwnProperty
let o = { x: 1 };
o.hasOwnProperty("x")
true
o.hasOwnProperty("y")
false
o.hasOwnProperty("toString")
false: toString is an inherited property
The propertyIsEnumerable() returns true only if the named property is an own property and its enumerable attribute is true.
let o = { x: 1 };
o.propertyIsEnumerable("x")
true
o.propertyIsEnumerable("toString")
false: not an own property
Object.prototype.propertyIsEnumerable("toString")
false: not enumerable
Enumerating properties
To guard against enumerating inherited properties with for/in, you can add an explicit check inside the loop body:
for(let p in o) {
if (!o.hasOwnProperty(p)) continue;
}
for(let p in o) {
if (typeof o[p] === "function") continue;
}
Functions you can use to get an array of property names
· Object.keys() returns an array of the names of the enumerable own properties of an object. It does not include non-enumerable properties, inherited properties, or properties whose name is a Symbol.
· Object.getOwnPropertyNames() works like Object.keys() but returns an array of the names of nonenumerable own properties as well.
· Object.getOwnPropertySymbols() returns own properties whose names are Symbols, whether or not they are enumerable.
· Reflect.ownKeys() returns all own property names, both enumerable and non-enumerable, and both string and Symbol.
Extending Objects
To copy the properties of one object to another object
let target = {x: 1}, source = {y: 2, z: 3};
for(let key of Object.keys(source)) {
target[key] = source[key];
}
One reason to assign properties from one object into another is when you have an object that defines default values for many properties and you want to copy those default properties into another object if a property by that name does not already exist in that object. Using Object.assign() naively will not do what you want:
Object.assign(o, defaults);
overwrites everything in o with defaults
Instead, use one of the following:,
o = Object.assign({}, defaults, o);
o = {...defaults, ...o};
Serializing Objects
The functions JSON.stringify() and JSON.parse() serialize and restore JavaScript objects.
let o = {x: 1, y: {z: [false, null, ""]}};
let s = JSON.stringify(o);
s == ‘{“x”:1,”y”:{“z”:[false,null,””]}}’
let p = JSON.parse(s);
p == {x: 1, y: {z: [false,null, “”]}}
Object methods
toString(), valueOf(), loLocaleString(), toJSON()
let s = { x: 1, y: 1 }.toString();
s == “[object Object]”
Extended Object Literal Syntax
Shorthand Properties
let x = 1, y = 2;
let o = {
x: x,
y: y
};
←>
let x = 1, y = 2;let o = { x, y };
Computer Property Names
const PROPERTY_NAME = "p1";function computePropertyName() { return "p" + 2; }
let o = {};
o[PROPERTY_NAME] = 1;
o[computePropertyName()] = 2;
←>
let p = {
[PROPERTY_NAME]: 1,
[computePropertyName()]: 2
};
Symbols as Property Names
const extension = Symbol("my extension symbol");
let o = {
[extension]: {}
};
o[extension].x = 0;
Two Symbols created with the same string argument are still different from one another.
The point of Symbols is not security, but to define a safe extension mechanism for JavaScript objects. If you get an object from third-party code that you do not control and need to add some of your own properties to that object but want to be sure that your properties will not conflict with any properties that may already exist on the object, you can safely use Symbols as your property names.
Spread Operator
You can copy the properties of an existing object into a new object using the “spread operator” … inside an object literal:
let position = { x: 0, y: 0 };let dimensions = { width: 100, height: 75 };let rect = { ...position, ...dimensions };rect.x + rect.y + rect.width + rect.height
Shorthand Methods
let square = {
area: function() {
return this.side * this.side; },
side: 10
};
←>
let square = {
area() {
return this.side * this.side; },
side: 10
};
When you write a method using this shorthand syntax, the property name can take any of the forms that are legal in an object literal: in addition to a regular JavaScript identifier like the name area above, you can also use string literals and computed property names, which can include Symbol property names:
const METHOD_NAME = "m";
const symbol = Symbol();
let weirdMethods = {
"method With Spaces"(x) { return x + 1; },
[METHOD_NAME](x) { return x + 2; },
[symbol](x) { return x + 3; }
};
weirdMethods["method With Spaces"](1)
2
weirdMethods[METHOD_NAME](1)
3
weirdMethods[symbol](1)
4
Property Getters and Setters
let o = {
dataProp: value,
get accessorProp() { return this.dataProp; },
set accessorProp(value) { this.dataProp = value; }
};
Arrays
Creating Arrays
· Array literals
· The … spread operator on an iterable object
· The Array() constructor
· The Array.of() and Array.from() factory methods
Array literals
let empty = [];
let primes = [2, 3, 5, 7, 11];
let misc = [ 1.1, true, "a", ];
let b = [[1, {x: 1, y: 2}], [2, {x: 3, y: 4}]];
If an array literal contains multiple commas in a row, with no value between, the array is sparse
let count = [1,,3];
let undefs = [,,];
Array literal syntax allows an optional trailing comma, so [,,] has a length of 2, not 3.
The Spread Operator
let a = [1, 2, 3];
let b = [0, ...a, 4];
[0, 1, 2, 3, 4]
create a copy of an array — modifying the copy does not change the original
let original = [1,2,3];let copy = [...original];
let digits = [..."0123456789ABCDEF"];
[“0”,”1″,”2″,”3″,”4″,”5″,”6″,”7″,”8″,”9″,”A”,”B”,”C”,”D”,”E”,”F”]
let letters = [..."hello world"];
[“h”,”e”,”l”,”l””o”,””,”w”,”o””r”,”l”,”d”]
[...new Set(letters)]
[“h”,”e”,”l”,”o”,””,”w”,”r”,”d”]
Array.of()
When the Array() constructor function is invoked with one numeric argument, it uses that argument as an array length. But when invoked with more than one numeric argument, it treats those arguments as elements for the array to be created. This means that the Array() constructor cannot be used to create an array with a single numeric element.
Array.of()
[]
Array.of(10)
[10]
Array.of(1,2,3)
[1, 2, 3]
Array.from()
It is also a simple way to make a copy of an array:
let copy = Array.from(original);
Array.from() is also important because it defines a way to make a true-array copy of an array-like object. Array-like objects are non-array objects that have a numeric length property and have values stored with properties whose names happen to be integers.
let truearray = Array.from(arraylike);
Array.from() also accepts an optional second argument. If you pass a function as the second argument, then as the new array is being built, each element from the source object will be passed to the function you specify, and the return value of the function will be stored in the array instead of the original value.
Reading and Writing Array Elements
What is special about arrays is that when you use property names that are non-negative integers , the array automatically maintains the value of the length property for you.
JavaScript converts the numeric array index you specify to a string — the index 1 becomes the string “1”, then uses that string as a property name.
It is helpful to clearly distinguish an array index from an object property name. All indexes are property names, but only property names that are integers between 0 and 231 are indexes. All arrays are objects, and you can create properties of any name on them. If you use properties that are array indexes, however, arrays have the special behavior of updating their length property as needed.
Note that you can index an array using numbers that are negative or that are not integers. When you do this, the number is converted to a string, and that string is used as the property name. Since the name is not a non-negative integer, it is treated as a regular object property, not an array index.
a[-1.23] = true;
This creates a property named “-1.23”
a["1000"] = 0;
This the 1001st element of the array
a[1.000] = 1;
Array index 1. Same as a[1] = 1;
The fact that array indexes are simply a special type of object property name means that JavaScript arrays have no notion of an “out of bounds” error. When you try to query a nonexistent property of any object, you don’t get an error; you simply get undefined.
Sparse Arrays
Sparse arrays can be created with the Array() constructor or simply by assigning to an array index larger than the current array length.
a[1000] = 0;
Assignment adds one element but sets length to 1001.
you can also make an array sparse with the delete operator.
Note that when you omit a value in an array literal (using repeated commas as in [1,,3]), the resulting array is sparse, and the omitted elements simply do not exist
Array Length
if you set the length property to a nonnegative integer n smaller than its current value, any array elements whose index is greater than or equal to n are deleted from the array.
a = [1,2,3,4,5];
a.length = 3;
a is now [1,2,3].
a.length = 0;
Delete all elements. a is [].
a.length = 5;
Length is 5, but no elements, like new Array(5)
You can also set the length property of an array to a value larger than its current value. Doing this does not actually add any new elements to the array; it simply creates a sparse area at the end of the array.
Adding and Deleting Array Elements
let a = [];
a[0] = "zero";
a[1] = "one";
add elements to it.
You can also use the push() method to add one or more values to the end of an array.
You can use the unshift() method to insert a value at the beginning of an array, shifting the existing array elements to higher indexes.
The pop() method is the opposite of push(): it removes the last element of the array and returns it, reducing the length of an array by 1.
Similarly, the shift() method removes and returns the first element of the array, reducing the length by 1 and shifting all elements down to an index one lower than their current index.
You can delete array elements with the delete operator
let a = [1,2,3];
delete a[2];
a now has no element at index 2
2 in a
false
a.length
3: delete does not affect array length
Iterating Arrays
The easiest way to loop through each of the elements of an array (or any iterable object) is with the for/ofloop
let letters = [..."Hello world"];
let string = "";
for(let letter of letters) {
string += letter;
}
It has no special behavior for sparse arrays and simply returns undefined for any array elements that do not exist.
If you want to use a for/of loop for an array and need to know the index of each array element, use the entries() method of the array
let letters = [..."Hello world"];
let everyother = "";
for(let [index, letter] of letters.entries()) {
if (index % 2 === 0) everyother += letter;
}
Another good way to iterate arrays is with forEach(). This is not a new form of the for loop, but an array method that offers a functional approach to array iteration.
let letters = [..."Hello world"];
let uppercase = "";
letters.forEach(letter => {
uppercase += letter.toUpperCase();
});
You can also loop through the elements of an array with a for loop.
for(let i = 0, len = letters.length; i < len; i++) {
// loop body
}
Multidimensional Arrays
Create a multidimensional array
let table = new Array(10);
for(let i = 0; i < table.length; i++) {
table[i] = new Array(10);
}
for(let row = 0; row < table.length; row++) {
for(let col = 0; col < table[row].length; col++) {
table[row][col] = row * col;
}
}
Array Methods
Array Iterator Methods
First, all of these methods accept a function as their first argument and invoke that function once for each element (or some elements) of the array. If the array is sparse, the function you pass is not invoked for nonexistent elements. In most cases, the function you supply is invoked with three arguments: the value of the array element, the index of the array element, and the array itself.
FOREACH()
let data = [1,2,3,4,5], sum = 0;
data.forEach(value => { sum += value; });
data.forEach(function(v, i, a) {
a[i] = v + 1;
});
15
[2,3,4,5,6]
MAP()
let a = [1, 2, 3];a.map(x => x*x)
[1, 4, 9]
FILTER()
let a = [5, 4, 3, 2, 1];a.filter(x => x < 3)a.filter((x,i) => i % 2 === 0)
[2, 1];
[5, 3, 1];
FIND()
FINDINDEX()
let a = [1,2,3,4,5];
a.findIndex(x => x === 3)
a.find(x => x % 5 === 0)
a.find(x => x % 7 === 0)
2
5
undefined
EVERY()
SOME()
let a = [1,2,3,4,5];
a.every(x => x < 10)
a.some(x => x % 2 === 0)
a.some(isNaN)
true
true
false
REDUCE()
ReduceRight()
let a = [1,2,3,4,5];
a.reduce((x,y) => x+y, 0)
a.reduce((x,y) => x*y, 1)
a.reduce((x,y) => (x > y) ? x : y)
15
120
5
Note that map() returns a new array: it does not modify the array it is invoked on. If that array is sparse, your function will not be called for the missing elements, but the returned array will be sparse in the same way as the original array: it will have the same length and the same missing elements.
To close the gaps in a sparse array, you can do this:
let dense = sparse.filter(() => true);
And to close gaps and remove undefined and null elements, you can use filter, like this:
a = a.filter(x => x !== undefined && x !== null);
Unlike filter(), however, find() and findIndex() stop iterating the first time the predicate finds an element. When that happens, find() returns the matching element, and findIndex() returns the index of the matching element. If no matching element is found, find() returns undefined and findIndex()returns -1.
When you invoke reduce() with no initial value, it uses the first element of the array as the initial value.
reduceRight() works just like reduce(), except that it processes the array from highest index to lowest (right-to-left), rather than from lowest to highest. You might want to do this if the reduction operation has right-to-left associativity
Flattening arrays with flat() and flatMap()
[1, [2, 3]].flat()
[1, 2, 3]
[1, [2, [3]]].flat()
[1, 2, [3]]
let a = [1, [2, [3, [4]]]];
a.flat(1)
a.flat(2)
a.flat(3)
a.flat(4)
[1, 2, [3, [4]]]
[1, 2, 3, [4]]
[1, 2, 3, 4]
[1, 2, 3, 4]
let phrases = ["hello world", "the definitive guide"];let words = phrases.flatMap(phrase => phrase.split(" "));
[“hello”, “world”, “the”, “definitive”, “guide”];
Calling a.flatMap(f) is the same as (but more efficient than) a.map(f).flat():
Adding arrays with concat()
let a = [1,2,3];
a.concat(4, 5)
[1,2,3,4,5]
a.concat([4,5],[6,7])
[1,2,3,4,5,6,7]
Stacks and Queues with push(), pop(), shift(), and unshift()
The push() and pop() methods allow you to work with arrays as if they were stacks. The push() method appends one or more new elements to the end of an array and returns the new length of the array.
The unshift() and shift() methods behave much like push() and pop(), except that they insert and remove elements from the beginning of an array rather than from the end.
You can implement a queue data structure by using push() to add elements at the end of an array and shift() to remove them from the start of the array. Note differences in unshift with single and multiple values.
let a = [];
a.unshift(1)
[1]
a.unshift(2)
[2, 1]
a = [];
a.unshift(1,2)
[1, 2]
Subarrays with slice(), splice(), fill(), and copyWithin()
SLICE()
let a = [1,2,3,4,5];
a.slice(0,3);
a.slice(3);
a.slice(1,-1);
a.slice(-3,-2);
[1,2,3]
[4,5]
[2,3,4]
[3]
SPLICE
let a = [1,2,3,4,5,6,7,8];
a.splice(4)
a.splice(1,2)
a.splice(1,1)
let a = [1,2,3,4,5];
a.splice(2,0,"a","b")
a.splice(2,2,[1,2],3)
[5,6,7,8]; a is now [1,2,3,4]
[2,3]; a is now [1,4]
[4]; a is now [1]
[]; a is now [1,2,”a”,”b”,3,4,5]
[“a”,”b”]; a is now [1,2,[1,2],3,3,4,5]
FILL()
let a = new Array(5);
a.fill(0)
a.fill(9, 1)
a.fill(8, 2, -1)
[0,0,0,0,0]
[0,9,9,9,9]
[0,9,8,8,9]
COPYWITHIN()
let a = [1,2,3,4,5];
a.copyWithin(1)
a.copyWithin(2, 3, 5)
a.copyWithin(0, -2)
[1,1,2,3,4]
[1,1,3,4,4]
[4,4,3,4,4]
splice() is a general-purpose method for inserting or removing elements from an array. splice() can delete elements from an array, insert new elements into an array, or perform both operations at the same time.
The first argument to splice() specifies the array position at which the insertion and/or deletion is to begin. The second argument specifies the number of elements that should be deleted from (spliced out of) the array.
Unlike concat(), splice() inserts arrays themselves, not the elements of those arrays.
copyWithin() copies a slice of an array to a new position within the array. It modifies the array in place and returns the modified array, but it will not change the length of the array.
Array Searching and Sorting Methods
INDEXOF()
LASTINDEXOF()
let a = [0,1,2,1,0];
a.indexOf(1)
a.lastIndexOf(1)
a.indexOf(3)
1
3
-1
SORT()
let a = [33, 4, 1111, 222];
a.sort();
a.sort((a,b) => a - b);
Case-insensitive sort
let a = ["ant", "Bug", "cat", "Dog"];
a.sort(); // a == ["Bug","Dog","ant","cat"];
a.sort(function(s,t) {
let a = s.toLowerCase();
let b = t.toLowerCase();
if (a < b) return -1;
if (a > b) return 1;
return 0;
});
[1111, 222, 33, 4];
[4, 33, 222, 1111]
REVERSE()
let a = [1,2,3];a.reverse();
[3,2,1]
indexOf() and lastIndexOf() compare their argument to the array elements using the equivalent of the === operator. If your array contains objects instead of primitive values, these methods check to see if two references both refer to exactly the same object. If you want to actually look at the content of an object, try using the find() method with your own custom predicate function instead.
indexOf() and lastIndexOf() take an optional second argument that specifies the array index at which to begin the search. Negative values are allowed for the second argument and are treated as an offset from the end of the array.
indexOf() will not detect the NaN value in an array, but includes() will
When sort() is called with no arguments, it sorts the array elements in alphabetical order. To sort an array into some order other than alphabetical, you must pass a comparison function as an argument to sort().
Array to String Conversions
The join() method converts all the elements of an array to strings and concatenates them, returning the resulting string.
let a = [1, 2, 3];
a.join()
a.join(" ")
a.join("")
“1,2,3”
“1 2 3”
“123”
let b = new Array(10);
b.join("-")
“ — — — — -”
Arrays, like all JavaScript objects, have a toString() method. For an array, this method works just like the join() method with no arguments:
[1,2,3].toString()
“1,2,3”
["a", "b", "c"].toString()
“a,b,c”
[1, [2,"c"]].toString()
“1,2,c”
Static Array Functions
Array.isArray([])
true
Array.isArray({})
false
Array-Like Objects
It is often perfectly reasonable to treat any object with a numeric length property and corresponding non-negative integer properties as a kind of array.
let a = {};
let i = 0;
while(i < 10) {
a[i] = i * i;
i++;
}
a.length = i;
// Now iterate through it as if it were a real array
let total = 0;
for(let j = 0; j < a.length; j++) {
total += a[j];
}
Since array-like objects do not inherit from Array.prototype, you cannot invoke array methods on them directly. You can invoke them indirectly using the Function.call method.
let a = {"0": "a", "1": "b", "2": "c", length: 3};
// An array-like object
Array.prototype.join.call(a, "+")
“a+b+c”
Array.prototype.join.call("JavaScript", " ")
“J a v a S c r i p t”
Array.prototype.map.call(a, x => x.toUpperCase())
[“A”,”B”,”C”]
Array.from(a)
[“a”,”b”,”c”]
Strings as Arrays
let s = "test";
s.charAt(0)
t
s[1]
e
Functions
In addition to the arguments, each invocation has another value — the invocation context — that is the value of the this keyword.
Function Declarations
function printprops(o) {
for(let p in o) {
console.log(`${p}: ${o[p]}\n`);
}
}
Function declaration statements are “hoisted” to the top of the enclosing script, function, or block so that functions defined in this way may be invoked from code that appears before the definition.
Function Expressions
const square = function(x) { return x*x; };
const f = function fact(x) {
if (x <= 1) return 1;
return x * fact(x-1);
}
Function expressions can include names, which is useful for recursion
[3,2,1].sort(function(a,b) { return a - b; });
Function expressions can also be used as arguments to other functions
let tensquared = (function(x) {return x*x;}(10));
Function expressions are sometimes defined and immediately invoked
Arrow Functions
const sum = (x, y) => { return x + y; };
const sum = (x, y) => x + y;
no need for return
const polynomial = x => x*x + 2*x + 3;
omit parens with single parameter
const constantFunc = () => 42;
usage for no params
If the body of your arrow function is a single return statement but the expression to be returned is an object literal, then you have to put the object literal inside parentheses to avoid syntactic ambiguity between the curly braces of a function body and the curly braces of an object literal
const f = x => { return { value: x }; };
good
const g = x => ({ value: x });
good
const h = x => { value: x };
returns nothing
const i = x => { v: x, w: x };
syntax error
Arrow functions differ from functions defined in other ways in one critical way: they inherit the value of the this keyword from the environment in which they are defined rather than defining their own invocation context as functions defined in other ways do.
Nested Functions
function hypotenuse(a, b) {
function square(x) { return x*x; }
return Math.sqrt(square(a) + square(b));
}
Invoking Functions
For function invocation in non-strict mode, the invocation context (the this value) is the global object. In strict mode, however, the invocation context is undefined.
const strict = (function() { return !this; }())
Determine if we’re in strict mode
Constructor Invocation
A constructor invocation creates a new, empty object that inherits from the object specified by the prototypeproperty of the constructor.
Indirect invocation
JavaScript functions are objects, and like all JavaScript objects, they have methods. Two of these methods, call() and apply(), invoke the function indirectly. Both methods allow you to explicitly specify the this value for the invocation, which means you can invoke any function as a method of any object, even if it is not actually a method of that object.
Function Arguments and Parameters
Optional Parameters and Defaults
When a function is invoked with fewer arguments than declared parameters, the additional parameters are set to their default value, which is normally undefined.
function getPropertyNames(o, a) {
a = a || [];
for(let property in o) a.push(property);
return a;
}
function getPropertyNames(o, a = []) {
for(let property in o) a.push(property);
return a;
}
One interesting case is that, for functions with multiple parameters, you can use the value of a previous parameter to define the default value of the parameters that follow it
const rectangle = (width, height = width*2) => ({width, height});
Rest Parameters and Variable-Length Argument Lists
Rest parameters enable us to write functions that can be invoked with arbitrarily more arguments than parameters.
function max(first=-Infinity, ...rest) {
let maxValue = first;
for(let n of rest) {
if (n > maxValue) {
maxValue = n;
}
}
return maxValue;
}
max(1, 10, 100, 2, 3, 1000, 4, 5, 6)
1000
within the body of a function, the value of a rest parameter will always be an array. The array may be empty, but a rest parameter will never be undefined.
This type of function is called variadic functions, variable arity functions, or vararg functions.
The Arguments Object
Within the body of any function, the identifier arguments refers to the Arguments object for that invocation.
function max(x) {
let maxValue = -Infinity;
for(let i = 0; i < arguments.length; i++) {
if (arguments[i] > maxValue)
maxValue = arguments[i];
}
return maxValue;
}
max(1, 10, 100, 2, 3, 1000, 4, 5, 6)
1000
you should avoid using it in any new code you write.
The Spread Operator for Function Calls
let numbers = [5, 2, 10, -1, 9, 100, 1];
Math.min(...numbers)
-1
function timed(f) {
return function(...args) {
console.log(`Entering function ${f.name}`);
let startTime = Date.now();
try {
return f(...args);
}
finally {
console.log(`Exiting ${f.name} after ${Date.now() - startTime}ms`);
}
};
}
// Compute the sum of the numbers between 1 and n by brute force
function benchmark(n) {
let sum = 0;
for(let i = 1; i <= n; i++) sum += i;
return sum;
}
// Now invoke the timed version of that test function
timed(benchmark)(1000000)
Destructuring Function Arguments into Parameters
function vectorAdd(v1, v2) {
return [v1[0] + v2[0], v1[1] + v2[1]];
}
vectorAdd([1,2], [3,4])
←>
function vectorAdd([x1,y1], [x2,y2]) {
return [x1 + x2, y1 + y2];
}
vectorAdd([1,2], [3,4])
function vectorMultiply({x, y}, scalar) {
return { x: x*scalar, y: y*scalar };
}
vectorMultiply({x: 1, y: 2}, 2)
←>
function vectorMultiply({x,y}, scalar) {
return { x: x*scalar, y: y*scalar};
}
vectorMultiply({x: 1, y: 2}, 2)
Argument Types
Adding code to check the types of arguments
function sum(a) {
let total = 0;
for(let element of a) {
if (typeof element !== "number") {
throw new TypeError("sum(): elements must be numbers");
}
total += element;
}
return total;
}
sum([1,2,3])
6
sum(1, 2, 3);
TypeError: 1 is not iterable
sum([1,2,"3"]);
TypeError: element 2 is not a number
Functions as Values
function square(x) { return x * x; }
let s = square;
square(4)
16
s(4)
16
Functions can also be assigned to object properties rather than variables.
let o = {square: function(x) { return x*x; }};
let y = o.square(16);
256
Functions don’t even require names at all, as when they’re assigned to array elements:
let a = [x => x*x, 20];
a[0](a[1])
400
a[0] accesses first element of the array, which is “x => x*x“, (a[1]) passes parameter, which is 20.
Examples of using functions as data
function add(x,y) { return x + y; }
function subtract(x,y) { return x - y; }
function multiply(x,y) { return x * y; }
function divide(x,y) { return x / y; }
function operate(operator, operand1, operand2) {
return operator(operand1, operand2);
}
let i = operate(add, operate(add, 2, 3), operate(multiply, 4,5));
(2+3) + (4*5):
or:
const operators = {
add: (x,y) => x+y,
subtract: (x,y) => x-y,
multiply: (x,y) => x*y,
divide: (x,y) => x/y,
pow: Math.pow
};
function operate2(operation, operand1, operand2) {
if (typeof operators[operation] === "function") {
return operators[operation](operand1, operand2);
}
else throw "unknown operator";
}
operate2("add", "hello", operate2("add", " ", "world"))
// “hello world”
operate2("pow", 10, 2)
100
Defining Your Own Function Properties
When a function needs a “static” variable whose value persists across invocations, it is often convenient to use a property of the function itself.
For example, suppose you want to write a function that returns a unique integer whenever it is invoked. The function must never return the same value twice. In order to manage this, the function needs to keep track of the values it has already returned, and this information must persist across function invocations.
uniqueInteger.counter = 0;
function uniqueInteger() {
return uniqueInteger.counter++;
}
uniqueInteger()
0
uniqueInteger()
1
Compute factorials and cache results as properties of the function itself.
function factorial(n) {
if (Number.isInteger(n) && n > 0) {
if (!(n in factorial)) {
factorial[n] = n * factorial(n-1);
}
return factorial[n];
}
else {
return NaN;
}
}
factorial[1] = 1;
Initialize the cache to hold this base case.
factorial(6)
720
factorial[5]
120; the call above caches this value
Functions as Namespaces
Variables declared within a function are not visible outside of the function. For this reason, it is sometimes useful to define a function simply to act as a temporary namespace in which you can define variables without cluttering the global namespace.
Variables that would have been global become local to the function. Following code defines only a single global variable: the function name chunkNamespace.
function chunkNamespace() {
// Chunk of code goes here
// Any variables defined in the chunk are local to this function
// instead of cluttering up the global namespace.
}
chunkNamespace();
If defining even a single property is too much, you can define and invoke an anonymous function in a single expression — IIEF (immediately invoked function expression)
(function() {
// chunkNamespace() function rewritten as an unnamed expression.
// Chunk of code goes here
}());
Closures
JavaScript uses lexical scoping. This means that functions are executed using the variable scope that was in effect when they were defined, not the variable scope that is in effect when they are invoked.
In order to implement lexical scoping, the internal state of a JavaScript function object must include not only the code of the function but also a reference to the scope in which the function definition appears.
This combination of a function object and a scope (a set of variable bindings) in which the function’s variables are resolved is called a closure.
Closures become interesting when they are invoked from a different scope than the one they were defined in. This happens most commonly when a nested function object is returned from the function within which it was defined.
let scope = "global scope";
function checkscope() {
let scope = "local scope";
function f() { return scope; }
return f();
}
checkscope()
“local scope”
let scope = "global scope";
function checkscope() {
let scope = "local scope";
function f() { return scope; }
return f;
}
let s = checkscope()();
“local scope”
Closures capture the local variables of a single function invocation and can use those variables as private state.
let uniqueInteger = (function() {
let counter = 0;
return function() { return counter++; };
}());
uniqueInteger()
0
uniqueInteger()
1
it is the return value of the function that is being assigned to uniqueInteger.
Private variables like counter need not be exclusive to a single closure: it is perfectly possible for two or more nested functions to be defined within the same outer function and share the same scope.
function counter() {
let n = 0;
return {
count: function() { return n++; },
reset: function() { n = 0; }
};
}
let c = counter(), d = counter();
c.count()
0
d.count()
0
c.reset();
c.count()
0
d.count()
1
You can combine this closure technique with property getters and setters
function counter(n) {
return {
get count() { return n++; },
set count(m) {
if (m > n) n = m;
else throw Error("count can only be set to a larger value")
}
};
}
let c = counter(1000);
c.count
1000
c.count
1001
c.count = 2000;
c.count
2000
c.count = 2000;
Error: count can only be set to a larger value
Define a private variable and two nested functions to get and set the value of that variable.
function addPrivateProperty(o, name, predicate) {
let value;
o[`get${name}`] = function() { return value; };
o[`set${name}`] = function(v) {
if (predicate && !predicate(v)) {
throw new TypeError(`set${name}: invalid value ${v}`);
}
else {
value = v;
}
};
}
let o = {};
addPrivateProperty(o, "Name", x => typeof x === "string");
o.setName("Frank");
o.getName()
“Frank”
o.setName(0);
TypeError: try to set a value ofthe wrong type
Function Properties, Methods, and Constructor
Since functions are objects, they can have properties and methods, just like any other object.
The length Property
The read-only length property of a function specifies the arity of the function — the number of parameters it declares in its parameter list, which is usually the number of arguments that the function expects.
The name Property
This property is primarily useful when writing debugging or error messages.
The prototype Property
When a function is used as a constructor, the newly created object inherits properties from the prototype object.
The call() and apply() Methods
call() and apply() allow you to indirectly invoke a function as if it were a method of some other object. The first argument to both call() and apply() is the object on which the function is to be invoked; this argument is the invocation context and becomes the value of the this keyword within the body of the function.
To invoke the function f() as a method of the object o (passing no arguments),
f.call(o);
f.apply(o);
To pass two numbers to the function f() and invoke it as if it were a method of the object o,
f.call(o, 1, 2);
The apply() method is like the call() method, except that the arguments to be passed to the function are specified as an array:
f.apply(o, [1,2]);
The trace() function defined uses the apply() method instead of a spread operator, and by doing that, it is able to invoke the wrapped method with the same arguments and the same this value as the wrapper method
function trace(o, m) {
let original = o[m];
o[m] = function(...args) {
console.log(new Date(), "Entering:", m);
let result = original.apply(this, args);
console.log(new Date(), "Exiting:", m);
return result;
};
}
The bind() Method
The primary purpose of bind() is to bind a function to an object.
function f(y) { return this.x + y; }
let o = { x: 1 };
let g = f.bind(o);
g(2)
3
let p = { x: 10, g };
p.g(2)
3 // g is still bound to o, not p.
The most common use case for calling bind() is to make non-arrow functions behave like arrow functions.
Partial application is a common technique in functional programming and is sometimes called currying.
let sum = (x,y) => x + y;
let succ = sum.bind(null, 1);
succ(2)
3
The toString() Method
Most (but not all) implementations of this toString() method return the complete source code for the function
The Function() Constructor
The Function() constructor is best thought of as a globally scoped version of eval() that defines new variables and functions in its own private scope. You will probably never need to use this constructor in your code.
Higher-Order Functions
A higher-order function is a function that operates on functions, taking one or more functions as arguments and returning a new function.
function not(f) {
return function(...args) {
let result = f.apply(this, args);
return !result;
};
}
const even = x => x % 2 === 0;
A function to determine if a number is even
const odd = not(even);
[1,1,3,5,5].every(odd)
true
Returns a new function that maps one array to another
const map = function(a, ...args) { return a.map(...args); };
function mapper(f) {
return a => map(a, f);
}
const increment = x => x + 1;
const incrementAll = mapper(increment);
incrementAll([1,2,3]
[2,3,4]
Example that takes two functions, f and g, and returns a new function that computes f(g()):
function compose(f, g) {
return function(...args) {
return f.call(this, g.apply(this, args));
};
}
const sum = (x,y) => x+y;
const square = x => x*x;
compose(square, sum)(2,3)
25
Memoization
We defined a factorial function that cached its previously computed results. In functional programming, this kind of caching is called memoization.
Classes
JavaScript’s classes and prototype-based inheritance mechanism are substantially different from the classes and class-based inheritance mechanism of Java.
Classes and Prototypes
If we define a prototype object and then use Object.create() to create objects that inherit from it, we have defined a JavaScript class.
Factory function that returns a new range object:
function range(from, to) {
let r = Object.create(range.methods);
r.from = from;
r.to = to;
return r;
}
range.methods = {
includes(x) { return this.from <= x && x <= this.to; },
*[Symbol.iterator]() {
for(let x = Math.ceil(this.from); x <= this.to; x++)
yield x;
},
toString() { return "(" + this.from + "..." + this.to +")"; }
};
let r = range(1,3);
r.includes(2)
true
r.toString()
“(1…3)”
[...r]
[1, 2, 3]
Classes and Constructors
A constructor is a function designed for the initialization of newly created objects.
The critical feature of constructor invocations is that the prototype property of the constructor is used as the prototype of the new object.
While almost all objects have a prototype, only a few objects have a prototype property. It is function objects that have a prototype property.
This means that all objects created with the same constructor function inherit from the same object and are therefore members of the same class.
A Range class using a constructor
function Range(from, to) {
this.from = from;
this.to = to;
}
Range.prototype = {
includes: function(x) { return this.from <= x && x <= this.to; },
[Symbol.iterator]: function*() {
for(let x = Math.ceil(this.from); x <= this.to; x++)
yield x;
},
toString: function() { return "(" + this.from + "..." + this.to + ")"; }
};
let r = new Range(1,3);
r.includes(2)
true
r.toString()
“(1…3)”
[...r]
[1, 2, 3]
Because the Range() constructor is invoked with new, it does not have to call Object.create() or take any action to create a new object.
In the first example, the prototype was range.methods. This was a convenient and descriptive name, but arbitrary. In the second example, the prototype is Range.prototype, and this name is mandatory.
An invocation of the Range() constructor automatically uses Range.prototype as the prototype of the new Range object.
Constructors, Class Identity, and instanceof
Two objects are instances of the same class if and only if they inherit from the same prototype object.
The instanceof operator is not checking whether r was actually initialized by the Range constructor. Instead, it is checking whether r inherits from Range.prototype.
function Strange() {}
Strange.prototype = Range.prototype;
new Strange() instanceof Range
true
If you want to test the prototype chain of an object for a specific prototype and do not want to use the constructor function as an intermediary, you can use the isPrototypeOf() method
range.methods.isPrototypeOf(r);
The constructor Property
Every regular JavaScript function automatically has a prototype property. The value of this property is an object that has a single, non-enumerable constructor property.
The value of the constructor property is the function object
let F = function() {};
let p = F.prototype;
let c = p.constructor;
c === F
true
let o = new F();
o.constructor === F
true
Instances of the Range class, as defined, do not have a constructor property. We can remedy this problem by explicitly adding a constructor to the prototype:
Range.prototype = {
constructor: Range
};
Another common technique that you are likely to see in older JavaScript code is to use the predefined prototype object with its constructor property and add methods to it one at a time with code like this:
Range.prototype.includes = function(x) {
return this.from <= x && x <= this.to;
};
Range.prototype.toString = function() {
return "(" + this.from + "..." + this.to + ")";
};
Classes with the class Keyword
class Range {
constructor(from, to) {
this.from = from;
this.to = to;
}
includes(x) { return this.from <= x && x <= this.to; }
*[Symbol.iterator]() {
for(let x = Math.ceil(this.from); x <= this.to; x++)
yield x;
}
toString() { return `(${this.from}...${this.to})`; }
}
let r = new Range(1,3);
r.includes(2)
true
r.toString()
(1…3)
[...r]
[1, 2, 3]
Although class bodies are superficially similar to object literals, they are not the same thing. In particular, they do not support the definition of properties with name/value pairs.
If your class does not need to do any initialization, you can omit the constructor keyword and its body, and an empty constructor function will be implicitly created for you.
If you want to define a class that subclasses — or inherits from — another class, you can use the extends keyword with the class keyword:
class Span extends Range {
constructor(start, length) {
if (length >= 0) {
super(start, start + length);
}
else {
super(start + length, start);
}
}
}
class declarations have both statement and expression forms
let Square = class { constructor(x) { this.area = x * x; } };
new Square(3).area
9
Static methods
You can define a static method within a class body by prefixing the method declaration with the static keyword. Static methods are defined as properties of the constructor function rather than properties of the prototype object.
static parse(s) {
let matches = s.match(/^\((\d+)\.\.\.(\d+)\)$/);
if (!matches) {
throw new TypeError(`Cannot parse Range from "${s}".`)
}
return new Range(parseInt(matches[1]),
parseInt(matches[2]));
}
The method defined by this code is Range.parse(), not Range.prototype.parse(), and you must invoke it through the constructor, not through an instance:
let r = Range.parse('(1...10)');
Getters, Setters, and other Method Forms
Within a class body, you can define getter and setter methods just as you can in object literals. The only difference is that in class bodies, you don’t put a comma after the getter or setter.
Public, Private, and Static Fields
The ES6 standard only allows the creation of methods (including getters, setters, and generators) and static methods; it does not include syntax for defining fields.
If you want to define a field on a class instance, you must do that in the constructor function or in one of the methods. And if you want to define a static field for a class, you must do that outside the class body, after the class has been defined.
Standardization is underway, however, for extended class syntax that allows the definition of instance and static fields, in both public and private forms.
class Buffer {
constructor() {
this.size = 0;
this.capacity = 4096;
this.buffer = new Uint8Array(this.capacity);
}
}
←>
class Buffer {
size = 0;
capacity = 4096;
buffer = new Uint8Array(this.capacity);
}
The same proposal that seeks to standardize these instance fields also defines private (with the # prefix) instance fields.
class Buffer {
size = 0;
get size() { return this.#size; }
}
A related proposal seeks to standardize the use of the static keyword for fields.
static integerRangePattern = /^\((\d+)\.\.\.(\d+)\)$/;
static parse(s) {
let matches = s.match(Range.integerRangePattern);
if (!matches) {
throw new TypeError(`Cannot parse Range from "${s}".`)
}
return new Range(parseInt(matches[1]), matches[2]);
}
Adding Methods to Existing Classes
We can augment JavaScript classes simply by adding new methods to their prototype objects.
if (!String.prototype.startsWith) {
String.prototype.startsWith = function(s) {
return this.indexOf(s) === 0;
};
}
Number.prototype.times = function(f, context) {
let n = this.valueOf();
for(let i = 0; i < n; i++) f.call(context, i);
};
Subclasses
Subclasses and Prototypes
Span subclass of the Range class. This subclass will work just like a Range, but instead of initializing it with a start and an end, we’ll instead specify a start and a distance, or span.
function Span(start, span) {
if (span >= 0) {
this.from = start;
this.to = start + span;
}
else {
this.to = start;
this.from = start + span;
}
}
Ensure that the Span prototype inherits from the Range
Span.prototype = Object.create(Range.prototype);
We don’t want to inherit Range.prototype.constructor, so we define our own constructor property:
Span.prototype.constructor = Span;
Span overrides the toString() method
Span.prototype.toString = function() {return `(${this.from}... +${this.to - this.from})`;};
A robust subclassing mechanism needs to allow classes to invoke the methods and constructor of their superclass, but prior to ES6, JavaScript did not have a simple way to do these things.
Subclasses with extends and super
class EZArray extends Array {
get first() { return this[0]; }
get last() { return this[this.length-1]; }
}
let a = new EZArray();
a instanceof EZArray
true
a instanceof Array
true
a.push(1,2,3,4);
a.pop()
4
a.first
1
a.last
3
Array.isArray(a)
true
EZArray.isArray(a)
true
Array.prototype.isPrototypeOf(EZArray.prototype
true
Array.isPrototypeOf(EZArray)
true
Example demonstrates the use of the super keyword to invoke the constructor and methods of the superclass
class TypedMap extends Map {
constructor(keyType, valueType, entries) {
if (entries) {
for(let [k, v] of entries) {
if (typeof k !== keyType || typeof v !== valueType) {
throw new TypeError(`Wrong type for entry [${k}, ${v}]`);
}
}
}
super(entries);
this.keyType = keyType;
this.valueType = valueType;
}
set(key, value) {
if (this.keyType && typeof key !== this.keyType) {
throw new TypeError(`${key} is not of type${this.keyType}`);
}
if (this.valueType && typeof value !== this.valueType)
{
throw new TypeError(`${value} is not of type ${this.valueType}`);
}
return super.set(key, value);
}
}
You may not use the this keyword in your constructor until after you have invoked the superclass constructor with super(). This enforces a rule that superclasses get to initialize themselves before subclasses do.
Once private fields are supported, we could change these properties to #keyType and #valueType so that they could not be altered from the outside.
Class Hierarchies and Abstract Classes
Define abstract classes — classes that do not include a complete implementation — to serve as a common superclass for a group of related subclasses.
Modules
Automating Closure-Based Modularity
Imagine a tool that takes a set of files, wraps the content of each of those files within an immediately invoked function expression, keeps track of the return value of each function, and concatenates everything into one big file.
const modules = {};
function require(moduleName) { return modules[moduleName]; }
modules["sets.js"] = (function() {
const exports = {};
exports.BitSet = class BitSet { ... };
return exports;
}());
modules["stats.js"] = (function() {
const exports = {};
const sum = (x, y) => x + y;
const square = x = > x * x;
exports.mean = function(data) { ... };
exports.stddev = function(data) { ... };
return exports;
}());
writing code like the following to make use of those modules
const stats = require("stats.js");
const BitSet = require("sets.js").BitSet;
// Now write code using those modules
let s = new BitSet(100);
s.insert(10);
s.insert(20);
s.insert(30);
let average = stats.mean([...s]);
Modules in ES6
ES6 adds import and export keywords to JavaScript and finally supports real modularity as a core language feature.
ES6 modularity is conceptually the same as Node modularity: each file is its own module, and constants, variables, functions, and classes defined within a file are private to that module unless they are explicitly exported.
ES6 Exports
To export a constant, variable, function, or class from an ES6 module, simply add the keyword export before the declaration
export const PI = Math.PI;
export function degreesToRadians(d) { return d * PI / 180; }
export class Circle {
constructor(r) { this.r = r; }
area() { return PI * this.r * this.r; }
}
or:
export { Circle, degreesToRadians, PI };
It is common to write modules that export only one value (typically a function or class), and in this case, we usually use export default instead of export
export default class BitSet {
// implementation omitted
}
ES6 Imports
import BitSet from './bitset.js';
import { mean, stddev } from "./stats.js";
When importing from a module that defines many exports, however, you can easily import everything with an import statement like this:
import * as stats from "./stats.js";
With the wildcard import shown in the previous example, the importing module would use the imported mean() and stddev() functions through the stats object, invoking them as stats.mean() and stats.stddev().
Note: not finished.
The JavaScript Standard Library
The Set Class
Sets are not ordered or indexed, and they do not allow duplicates.
let s = new Set();
let t = new Set([1, s]);
let t = new Set(s);
let unique = new Set("Mississippi");
The argument to the Set() constructor need not be an array: any iterable object (including other Set objects) is allowed.
The add() method takes a single argument; if you pass an array, it adds the array itself to the set, not the individual array elements. add() always returns the set it is invoked on, however, so if you want to add multiple values to a set, you can used chained method calls like.
it is very important to understand that set membership is based on strict equality checks, like the === operator performs.
The most important thing we do with sets is not to add and remove elements from them, but to check to see whether a specified value is a member of the set:
let oneDigitPrimes = new Set([2,3,5,7]);
oneDigitPrimes.has(2)
The Set class is iterable, which means that you can use a for/of loop to enumerate all of the elements of a set:
let sum = 0;
for(let p of oneDigitPrimes) {
sum += p; // and add them up
}
Because Set objects are iterable, you can convert them to arrays and argument lists with the … spread operator
[...oneDigitPrimes]
JavaScript Set class always remembers the order that elements were inserted in, and it always uses this order when you iterate a set: the first element inserted will be the first one iterated (assuming you haven’t deleted it first), and the most recently inserted element will be the last one iterated.
Set class also implements a forEach() method
let product = 1;
oneDigitPrimes.forEach(n => { product *= n; });
The Map Class
let m = new Map();
let n = new Map([["one", 1],["two", 2]]);
let copy = new Map(n);
let o = { x: 1, y: 2};
let p = new Map(Object.entries(o));
map is a set of keys, each of which has an associated value. This is not quite the same as a set of key/value pairs.
use has() to check whether a map includes the specified key; use delete() to remove a key (and its associated value) from the map; use clear() to remove all key/value pairs from the map; and use the size property to find out how many keys a map contains.
set() method of Map can be chained.
Any JavaScript value can be used as a key or a value in a Map. This includes null, undefined, and NaN, as well as reference types like objects and arrays.
Map compares keys by identity, not by equality.
let m = new Map();
m.set({}, 1);
m.set({}, 2);
Map a different empty object to the number 2.
m.get({})
undefined:
m.set(m, undefined);
m.has(m)
true
m.get(m)
undefined
Iterate over map:
let m = new Map([["x", 1], ["y", 2]]);
[...m]
[[“x”, 1], [“y”, 2]]
for(let [key, value] of m) {...}
Map class iterates in insertion order
If you want to iterate just the keys or just the associated values of a map, use the keys() and values() methods: these return iterable objects that iterate keys and values, in insertion order. (Theentries() method returns an iterable object that iterates key/value pairs, but this is exactly the same as iterating the map directly.)
[...m.keys()]
[...m.values()]
[...m.entries()]
Map objects can also be iterated using the forEach()
m.forEach((value, key) => {...}
Note that the value parameter comes before the key parameter.
WeakMap and WeakSet
The WeakMap class is a variant (but not an actual subclass) of the Map class that does not prevent its key values from being garbage collected.
WeakMap keys must be objects or arrays; primitive values are not subject to garbage collection and cannot be used as keys.
WeakMap implements only the get(), set(), has(), and delete() methods. In particular, WeakMap is not iterable and does not define keys(), values(), or forEach(). If WeakMap was iterable, then its keys would be reachable and it wouldn’t be weak.
Similarly, WeakMap does not implement the size property because the size of a WeakMap could change at any time as objects are garbage collected
Typed Arrays and Binary Data
They differ from regular arrays in some very important ways
· The elements of a typed array are all numbers. Unlike regular JavaScript numbers, however, typed arrays allow you to specify the type (signed and unsigned integers and IEEE-754 floating point) and size (8 bits to 64 bits) of the numbers to be stored in the array.
· You must specify the length of a typed array when you create it, and that length can never change.
· The elements of a typed array are always initialized to 0 when the array is created.
Int8Array()
Uint8Array()
Uint8ClampedArray()
Int16Array()
Uint32Array()
Uint16Array()
Int32Array()
BigInt64Array()
BigUint64Array()
Float32Array()
let bytes = new Uint8Array(1024);
let matrix = new Float64Array(9);
let sudoku = new Int8Array(81);
Initialize with values
let white = Uint8ClampedArray.of(255, 255, 255, 0);
let ints = Uint32Array.from(white);
one more way to create typed arrays that involves the ArrayBuffer type
let buffer = new ArrayBuffer(1024*1024);
buffer.byteLength
1024*1024
Typed arrays are not true arrays, but they re-implement most array methods, so you can use them pretty much just like you’d use regular arrays:
let ints = new Int16Array(10);
10 short integers
ints.fill(3).map(x=>x*x).join("")
“9999999999”
Remember that typed arrays have fixed lengths, so the length property is read-only, and methods that change the length of the array (such as push(), pop(), unshift(), shift(), and splice()) are not implemented for typed arrays. Methods that alter the contents of an array without changing the length (such as sort(), reverse(), and fill()) are implemented.
Determine Endianess and DataView
let littleEndian = new Int8Array(new Int32Array([1]).buffer)
[0] === 1;
You can use the DataView class, which defines methods for reading and writing values from an ArrayBuffer with explicitly specified byte ordering. Refer to book for more examples.
Pattern Matching with Regular Expressions
RegExp objects may be created with the RegExp() constructor, of course, but they are more often created using a special literal syntax.
let pattern = /s$/;
←>
let pattern = new RegExp("s$");
Regular expressions can also have one or more flag characters that affect how they work
let pattern = /s$/i;
i = case insensitive
Punctuation characters have special meanings in regular expressions: ^ $ . * + ? = ! : | \ / ( ) [ ] { }. Other punctuation characters, such as quotation marks and @, do not have special meaning and simply match themselves literally in a regular expression.
If you use the RegExp() constructor, keep in mind that any backslashes in your regular expression need to be doubled, since strings also use backslashes as an escape character.
Character
Matches
[...]
Any one character between the brackets.
[^...]
Any one character not between the brackets
.
Any character except newline or another Unicode line terminator. Or, if the RegExp uses the s flag, then a period matches any character, including line terminators.
\w
Any ASCII word character. Equivalent to [a-zA-Z0-9_].
\W
Equivalent to [^a-zA-Z0-9_]
\s
Any Unicode whitespace character.
\S
Any character that is not Unicode whitespace.
\d
Equivalent to [0-9].
\D
Equivalent to [⁰-9].
[\b]
A literal backspace (special case).
[\s\d]
Any one whitespace character or digit
REPETITIONS
Character
Meaning
{n,m}
Match the previous item at least n times but no more than m times
{n,}
Match the previous item n or more times.
{n}
Match exactly n occurrences of the previous item.
?
Equivalent to {0,1}.
+
Equivalent to {1,}
*
Equivalent to {0,}.
Example
Description
let r = /\d{2,4}/;
Match between two and four digits
r = /\w{3}\d?/;
Match exactly three word characters and an optional digit
r = /\s+java\s+/;
Match “java” with one or more spaces before and after
r = /[^(]*/;
Match zero or more characters that are not open parens
If you want to match repetitions of more complicated expressions, you’ll need to define a group with parentheses
Be careful when using the * and ? repetition characters. Since these characters may match zero instances of whatever precedes them, they are allowed to match nothing.
NON-GREEDY REPETITION
It is also possible to specify that repetition should be done in a non-greedy way. Simply follow the repetition character or characters with a question mark: ??, +?, *?, or even {1,5}?.
String
Pattern
Match
"aaa"
/a+/
"aaa"
"aaa"
/a+?/
"a"
Note that using non-greedy repetition may not always produce the results you expect. This is because regular expression pattern matching is done by findingthe first position in the string at which a match is possible. Since a match is possible starting at the first character of the string, shorter matches starting at subsequent characters are never even considered.
ALTERNATION, GROUPING, AND REFERENCES
Char
Pattern
Pattern
|
/ab|cd|ef/
“ab” or the string “cd” or the string “ef”.
/\d{3}|[a-z]{4}/
either three digits or four lowercase letters.
/a|ab/
matches only the first letter “a”
()
/java(script)?/
matches “java” followed by the optional “script”
/(ab|cd)+|ef/
matches “java” followed by the optional “script”
If the left alternative matches, the right alternative is ignored, even if it would have produced a “better” match
Another purpose of parentheses in regular expressions is to define subpatterns within the complete pattern. When a regular expression is successfully matched against a target string, it is possible to extract the portions of the target string that matched any particular parenthesized subpattern. For example, suppose you are looking for one or more lowercase letters followed by one or more digits. You might use the pattern /[a-z]+\d+/. But suppose you only really care about the digits at the end of each match. If you put that part of the pattern in parentheses (/[a-z]+(\d+)/), you can extract the digits from any matches you find,
A related use of parenthesized subexpressions is to allow you to refer back to a subexpression later in the same regular expression. This is done by following a \ character by a digit or digits. The digits refer to the position of the parenthesized subexpression within the regular expression. For example, \1 refers back to the first subexpression, and \3 refers to the third.
Match
Pattern
zero or more characters within single or double quotes. However, it does not
require the opening and closing quotes to match
/['"][^'"]*['"]/
To require the quotes to match,use a reference
/(['"])[^'"]*\1/
Character
Meaning
|
match either the subexpression to the left or the subexpression to the right.
(…)
Grouping: group items into a single unit that can be used with *, +, ?, |, and so on. Also remember the characters that match this group for use with later references
(?:…)
group items into a single unit, but do not remember the characters that match this group.
Note (?:...) syntax:
In pattern "/([Jj]ava(?:[Ss]cript)?)\sis\s(fun\w*)/” \2 refers to the text matched by (fun\w*) since (?:[Ss]cript)?) in not remembered.
SPECIFYING MATCH POSITION
regular expression anchors because they anchor the pattern to a specific position in the search string. The most commonly used anchor elements are ^, which ties the pattern to the beginning of the string, and $, which anchors the pattern to the end of the string.
Example
Pattern
match the word “JavaScript” on a line by itself
/^JavaScript$/
To search for “Java” as a word by itself you can try the pattern /\sJava\s/, which requires a space before and after the word. But there are two problems with this solution. First, it does not match “Java” at the beginning or the end of a string, but only if it appears with space on either side. Second, when this pattern does find a match, the matched string it returns has leading and trailing spaces, which is not quite what’s needed. So instead of matching actual space characters with \s, match (or anchor to) word boundaries with \b. The resulting expression is /\bJava\b/.
The element \B anchors the match to a location that is not a word boundary. Thus, the pattern /\B[Ss]cript/ matches “JavaScript” and “postscript”, but not “script” or “Scripting”.
You can also use arbitrary regular expressions as anchor conditions.
If you include an expression within (?= and ) characters, it is a lookahead assertion, and it specifies that the enclosed characters must match, without actually matching them.
Example
Pattern
Matches
to match the name of a common programming language, but only if it is followed by a colon
/[Jj]ava([Ss]cript)?(?=\:)/
matches the word “JavaScript” in “JavaScript: The DefinitiveGuide”
does not match “Java” in “Java in a Nutshell”
If you instead introduce an assertion with (?!, it is a negative lookahead assertion.
FLAGS
Flags are specified after the second / character of a regular expression literal or as a string passed as the second argument to the RegExp() constructor.
Flag
Meaning
g
“global” — that is,that we intend to use it to find all matches within a string rather than just finding the first match.it does alter the behavior of the String match() method and the RegExp exec() method in important ways.
i
case-insensitive
m
“multiline” mode
s
useful when working with text that includes newlines.Normally, a “.” in a regular expression matches any character except a line terminator. When the s flag is used, however, “.” will match any character, including line terminators.
u
Unicode.
Setting the u flag on a RegExp also allows you to use the new \u{...} escape sequence for Unicode character and also enables the \p{…} notation for Unicode character classes.
y
“sticky”. should match at the beginning of a string or at the first character following the previous match
String Methods for Pattern Matching
SEARCH()
Strings support four methods that use regular expressions.
"JavaScript".search(/script/ui)
4
"Python".search(/script/ui)
-1
search() does not support global searches; it ignores the g flag of its regular expression argument.
REPLACE()
text.replace(/javascript/gi, "JavaScript");
No matter how it is capitalized, replace it with the correct capitalization
parenthesized subexpressions of a regular expression are numbered from left to right and that the regular expression remembers the text that each subexpression matches.
to replace quotation marks in a string with other characters:
let quote = /"([^"]*)"/g;
'He said "stop"'.replace(quote, '«$1»')
‘He said «stop»’
If your RegExp uses named capture groups, then you can refer to the matching text by name rather than by number:
let quote = /"(?<quotedText>[^"]*)"/g;
'He said "stop"'.replace(quote, '«$<quotedText>»')
‘He said «stop»’
Instead of passing a replacement string as the second argument to replace(), you can also pass a function that will be invoked to compute the replacement value.
Example to convert decimal integers in a string to hexadecimal:
let s = "15 times 15 is 225";
s.replace(/\d+/gu, n => parseInt(n).toString(16))
“f times f is e1”
MATCH()
"7 plus 8 equals 15".match(/\d+/g)
[“7”, “8”, “15”]
If the regular expression does not have the g flag set, match() does not do a global search; it simply searches for the first match. In this nonglobal case, match() still returns an array, but the array elements are completely different.
Thus, if match() returns an array a, a[0] contains the complete match, a[1] contains the substring that matched the first parenthesized expression, and so on.
let url = /(\w+):\/\/([\w.]+)\/(\S*)/;
let text = "Visit my blog at http://www.example.com/~david";
let match = text.match(url);
let fullurl, protocol, host, path;
if (match !== null) {
fullurl = match[0];
“http://www.example.com/~david“
protocol = match[1];
“http”
host = match[2];
path = match[3];
“~david”
In this non-global case, the array returned by match() also has some object properties in addition to the numbered array elements.
input property refers to the string on which match() was called
The index property is the position within that string at which the match starts.
if the regular expression contains named capture groups, then the returned array also has a groups property whose value is an object.
let url = /(?<protocol>\w+):\/\/(?<host>[\w.]+)\/(?<path>\S*)/;
let text = "Visit my blog at [http://www.example.com/~david](http://www.example.com/~david)";
let match = text.match(url);
match[0]
“http://www.example.com/~david“
match.input
text
match.index
17
match.groups.protocol
“http”
match.groups.host
match.groups.path
“~david”
There are also important but less dramatic differences in behavior when the y flag is set. Refer to book for examples.
MATCHALL()
Instead of returning an array of matching substrings like match() does, however, it returns an iterator that yields the kind of match objects that match() returns when used with a non-global RegExp.
SPLIT()
"123,456,789".split(",")
[“123”, “456”,”789″]
"1, 2, 3,\n4, 5".split(/\s*,\s*/)
[“1”, “2”, “3”, “4”,”5″]
Surprisingly, if you call split() with a RegExp delimiter and the regular expression includes capturing groups, then the text that matches the capturing groups will be included in the returned array.
const htmlTag = /<([^>]+)>/;
"Testing<br/>1,2,3".split(htmlTag)
[“Testing”, “br/”,”1,2,3″]
The RegExp Class
The RegExp() constructor is useful when a regular expression is being dynamically created and thus cannot be represented with the regular expression literal syntax.
let zipcode = new RegExp("\\d{5}", "g");
let exactMatch = /JavaScript/;let caseInsensitive = new RegExp(exactMatch, "i");
TEST()
Returns true or false by calling exec().
EXEC()
let pattern = /Java/g;
let text = "JavaScript > Java";
let match;
while((match = pattern.exec(text)) !== null) {
console.log(`Matched ${match[0]} at ${match.index}`);
console.log(`Next search begins at ${pattern.lastIndex}`);
}
THE LASTINDEX PROPERTY AND REGEXP REUSE
The use of the lastIndex property with the g and y flags is a particularly awkward part of this API. When you use these flags, you need to be particularly careful when calling the match(), exec(), or test() methods because the behavior of these methods depends on lastIndex, and the value of lastIndex depends on what you have previously done with the RegExp object.
To find the index of all
tags within a string of HTML text:
let match, positions = [];
while((match = /
/g.exec(html)) !== null) {
positions.push(match.index);
}
If the html string contains at least one
tag, then it will loop forever. For each iteration of the loop, we’re creating a new RegExp object with lastIndex set to 0, so exec() always begins at the start of the string, and if there is a match, it will keep matching over and over. The solution, of course, is to define the RegExp once, and save it to a variable so that we’re using the same RegExp object for each iteration of the loop.
On the other hand, sometimes reusing a RegExp object is the wrong thing to do. Suppose, for example, that we want to loop through all of the words in a dictionary to find words that contain pairs of double letters.
let dictionary = [ "apple", "book", "coffee" ];
let doubleLetterWords = [];
let doubleLetter = /(\w)\1/g;
for(let word of dictionary) {
if (doubleLetter.test(word)) {
doubleLetterWords.push(word);
}
}
doubleLetterWords
[“apple”, “coffee”]: “book” is missing!
Because we set the g flag on the RegExp, the lastIndex property is changed after successful matches, and the test() method (which is based on exec()) starts searching for a match at the position specified by lastIndex. After matching the “pp” in “apple”, lastIndex is 3, and so we start searching the word “book” at position 3 and do not see the “oo” that it contains.
Dates and Times
let now = new Date();
The current time
let epoch = new Date(0);
Midnight, January 1st, 1970, GMT
let century = new Date(2100,
0,
1,
2, 3, 4, 5);
Year 2100
January
1st
02:03:04.005, local
let century = new Date(Date.UTC(2100, 0, 1));
Midnight in GMT, January 1, 2100
If you print a date (with console.log(century), for example), it will, by default, be printed in your local time zone. If you want to display a date in UTC, you should explicitly convert it to a string with toUTCString() or toISOString().
if you pass a string to the Date() constructor, it will attempt to parse that string as a date and time specification
let century = new Date("2100-01-01T00:00:00Z");
Once you have a Date object, various get and set methods allow you to query and modify the year, month, day-of-month, hour, minute, second, and millisecond fields of the Date. Each of these methods hastwo forms: one that gets or sets using local time and one that gets or sets using UTC time.
Note that the methods for querying the day-of-month are getDate() and getUTCDate(). The more natural-sounding functions getDay() and getUTCDay() return the day-of-week (0 for Sunday through 6 for Saturday). The day-of-week is read-only, so there is not a corresponding setDay() method.
Timestamps
JavaScript represents dates internally as integers that specify the number of milliseconds since (or before) midnight on January 1, 1970, UTC time.
For any Date object, the getTime() method returns this internal value, and the setTime() method sets it.
d.setTime(d.getTime() + 30000);
add 30 secs
The static Date.now() method returns the current time as a timestamp and is helpful when you want to measure how long your code takes to run
let startTime = Date.now();
reticulateSplines(); // Do some time-consuming operation
let endTime = Date.now();
console.log(`Spline reticulation took ${endTime -startTime}ms.`);
adds three months and two weeks to the current date:
let d = new Date();d.setMonth(d.getMonth() + 3, d.getDate() + 14);
Formatting and Parsing Date Strings
let d = new Date(2020, 0, 1, 17, 10, 30);
d.toString()
“Wed Jan 01 2020 17:10:30 GMT-0800 (Pacific Standard Time)”
d.toUTCString()
“Thu, 02 Jan 2020 01:10:30 GMT”
d.toLocaleDateString()
“1/1/2020”: ‘en-US’ locale
d.toLocaleTimeString()
“5:10:30 PM”: ‘en-US’ locale
d.toISOString()
“2020-01-02T01:10:30.000Z”
there is also a static Date.parse() method that takes a string as its argument, attempts to parse it as a date and time, and returns a timestamp representing that date. Date.parse() is able to parse the same strings that the Date() constructor can and is guaranteed to be able to parse the output of toISOString(), toUTCString(), and toString().
Error Classes
One good reason to use an Error object is that, when you create an Error, it captures the state of the JavaScript stack, and if the exception is uncaught, the stack trace will be displayed with the error message, which will help you debug the issue.
Error objects have two properties: message and name, and a toString() method. Node and all modern browsers also define a stack property on Error objects.
Subclasses are EvalError, RangeError, ReferenceError, SyntaxError, TypeError, and URIError.
You should feel free to define your own Error subclasses that best encapsulate the error conditions of your own program.
class HTTPError extends Error {
constructor(status, statusText, url) {
super(`${status} ${statusText}: ${url}`);
this.status = status;
this.statusText = statusText;
this.url = url;
}
get name() { return "HTTPError"; }
}
let error = new HTTPError(404, "Not Found", "http://example.com/");
error.status
404
error.message
“404 Not Found:http://example.com/“
error.name
HTTPError
JSON Serialization and Parsing
JavaScript supports JSON serialization and deserialization with the two functions JSON.stringify() and JSON.parse().
let o = {s: "", n: 0, a: [true, false, null]};
let s = JSON.stringify(o);
s == ‘{“s”:””,”n”:0,”a”:[true,false,null]}’
let copy = JSON.parse(s);
copy == {s: “”, n: 0, a:[true, false, null]}
Inefficient way of creating a deep copy of an object
function deepcopy(o) {
return JSON.parse(JSON.stringify(o));
}
Typically, you pass only a single argument to JSON.stringify() and JSON.parse(). Both functions accept an optional second argument that allows us to extend the JSON format.
JSON.stringify() also takes an optional third argument. If you would like your JSONformatted string to be human-readable (if it is being used as a configuration file, for example), then you should pass null as the second argument and pass a number or string as the third argument. If the third argument is a number, then it will use that number of spaces for each indentation level. If the third argument is a string of whitespace (such as ‘\t’), it will use that string for each level of indent.
JSON Customizations
If JSON.stringify() is asked to serialize a value that is not natively supported by the JSON format, it looks to see if that value has a toJSON() method, and if so, it calls that method and then stringifies the return value in place of the original value. Date objects implement toJSON(): it returns the same string that toISOString() method does.
If you need to re-create Date objects (or modify the parsed object inany other way), you can pass a “reviver” function as the second argument to JSON.parse().
let data = JSON.parse(text, function(key, value) {
if (key[0] === "_") return undefined;
if (typeof value === "string" && /^\d\d\d\d-\d\d-\d\dT\d\d:\d\d:\d\d.\d\d\dZ$/.test(value)) {
return new Date(value);
}
return value;
});
The Console API
Console functions that print their arguments like console.log() have a little-known feature: if the first argument is a string that includes %s, %i, %d, %f, %o, %O, or %c, then this first argument is treated as format string, and the values of subsequent arguments are substituted into the string in place of the two-character % sequences.
URL API
let url = new URL("https://example.com:8000/path/name?q=term#fragment");
url.href
“https://example.com:8000/path/name?q=term#fragment”
url.origin
url.protocol
“https:”
url.host
“example.com:8000”
url.hostname
url.port
“8000”
url.pathname
“/path/name”
url.search
“?q=term”
url.hash
“#fragment”
let url = new URL("https://example.com");
url.pathname = "api/search";
Add a path to an API endpoint
url.search = "q=test";
Add a query parameter
url.toString()
“https://example.com/api/search?q=test“
One of the important features of the URL class is that it correctly adds punctuation and escapes special characters in URLs when that is needed
let url = new URL("https://example.com");
url.pathname = "path with spaces";
url.pathname
“/path%20with%20spaces”
url.search = "q=foo#bar";
url.search
“?q=foo%23bar”
url.href
“https://example.com/path%20with%20spaces?q=foo%23bar“
Often, however, HTTP requests encode the values of multiple form fields or multiple API parameters into the query portion of a URL. In this format, the query portion of the URL is a question mark followed by one or more name/value pairs, which are separated from one another by ampersands.
If you want to encode these kinds of name/value pairs into the query portion of a URL, then the searchParams property will be more useful than the search property.
let url = new URL("https://example.com/search");
url.search
“”
url.searchParams.append("q", "term");
url.search
“?q=term”
url.searchParams.set("q", "x");
url.search
“?q=x”
url.searchParams.append("opts", "1");
url.search
“?q=x&opts=1”
The value of the searchParams property is a URLSearchParams object.
let url = new URL("http://example.com");
let params = new URLSearchParams();
params.append("q", "term");
params.append("opts", "exact");
params.toString()
“q=term&opts=exact”
url.search = params;
url.href
“http://example.com/?q=term&opts=exact”
Timers
setTimeout() and setInterval()—that allow programs to ask the browser to invoke a function after a specified amount of time has elapsed or to invoke the function repeatedly at a specified interval.
setTimeout(() => { console.log("Ready..."); }, 1000);
setTimeout(() => { console.log("set..."); }, 2000);
setTimeout(() => { console.log("go!"); }, 3000);
If you want to invoke a function repeatedly, use setInterval()
Both setTimeout() and setInterval() return a value. If you save this value in a variable, you can then use it later to cancel the execution of the function by passing it to clearTimeout() or clearInterval().
let clock = setInterval(() => {
console.clear();
console.log(new Date().toLocaleTimeString());
}, 1000);
setTimeout(() => { clearInterval(clock); }, 10000);
After 10 seconds: stop the repeating code above
Iterators and Generators
The iterator method of an iterable object does not have a conventional name but uses the Symbol, Symbol.iterator as its name. So a simple for/of loop over an iterable object iterable could also be written the hard way, like this:
let iterable = [99];
let iterator = iterable[Symbol.iterator]();
for(let result = iterator.next(); !result.done; result =iterator.next()) {
console.log(result.value) // result.value == 99
}
When you want to iterate though a “partially used” iterator:
let list = [1,2,3,4,5];let iter = list[Symbol.iterator]();
let head = iter.next().value;
head == 1
let tail = [...iter];
tail == [2,3,4,5]
Implementing Iterable Objects
we will implement the Range class one more time, making it iterable without relying on a generator.
In order to make a class iterable, you must implement a method whose name is the Symbol Symbol.iterator
class Range {
constructor (from, to) {
this.from = from;
this.to = to;
}
has(x) { return typeof x === "number" && this.from <= x && x <= this.to; }
toString() { return `{ x | ${this.from} ≤ x ≤ ${this.to}}`; }
[Symbol.iterator]() {
let next = Math.ceil(this.from);
let last = this.to;
return {
next() {
return (next <= last) ? { value: next++ } : { done: true };
},
[Symbol.iterator]() { return this; }
};
}
}
for(let x of new Range(1,10)) console.log(x);
Logs numbers 1 to 10
[...new Range(-2,2)]
[-2, -1, 0,1, 2]
In addition to making your classes iterable, it can be quite useful to define functions that return iterable values.
Return an iterable object that iterates the result of applying f() to each value from the source iterable
function map(iterable, f) {
let iterator = iterable[Symbol.iterator]();
return {
[Symbol.iterator]() { return this; },
next() {
let v = iterator.next();
if (v.done) {
return v;
}
else {
return { value: f(v.value) };
}
}
};
}
[...map(new Range(1,4), x => x*x)]
[1, 4, 9, 16]
Return an iterable object that filters the specified iterable, iterating only those elements for which the predicate returns true
function filter(iterable, predicate) {
let iterator = iterable[Symbol.iterator]();
return {
[Symbol.iterator]() { return this; },
next() {
for(;;) {
let v = iterator.next();
if (v.done || predicate(v.value)) {
return v;
}
}
}
};
}
[...filter(new Range(1,10), x => x % 2 === 0)]
[2,4,6,8,10]
Generators
Particularly useful when the values to be iterated are not the elements of a data structure, but the result of a computation.
To create a generator, you must first define a generator function — defined with the keyword function* rather than function
When you invoke a generator function, it does not actually execute the function body, but instead returns a generator object. This generator object is an iterator.
Calling its next() method causes the body of the generator function to run from the start (or whatever its current position is) until it reaches a yield statement.
The value of the yield statement becomes the value returned by the next() call on the iterator.
function* oneDigitPrimes() {
yield 2;
yield 3;
yield 5;
yield 7;
}
let primes = oneDigitPrimes();
we get a generator
primes.next().value
2
primes.next().value
3
primes.next().value
5
primes.next().value
7
primes.next().done
true
Generators have a Symbol.iterator method to make them iterable
primes[Symbol.iterator]()
[...oneDigitPrimes()]
[2,3,5,7]
let sum = 0;
for(let prime of oneDigitPrimes()) sum += prime;
sum
17
Like regular functions, however, we can also define generators in expression form.
const seq = function*(from,to) {
for(let i = from; i <= to; i++) yield i;
};
[...seq(3,5)]
[3, 4, 5]
In classes and object literals, we can use shorthand notation to omit the function keyword entirely when we define methods.
let o = {
x: 1, y: 2, z: 3,
*g() {
for(let key of Object.keys(this)) {
yield key;
}
}
};
[...o.g()]
[“x”, “y”, “z”, “g”]
Generators often make it particularly easy to define iterable classes.
*[Symbol.iterator]() {
for(let x = Math.ceil(this.from); x <= this.to; x++)
yield x;
}
Generator Examples
Generators are more interesting if they actually generate the values they yield by doing some kind of computation.
generator function that yields Fibonacci numbers
function* fibonacciSequence() {
let x = 0, y = 1;
for(;;) {
yield y;
[x, y] = [y, x+y];
}
}
If this generator is used with the … spread operator, it will loop until memory is exhausted and the program crashes.
Use it in a for/of loop, however
function fibonacci(n) {
for(let f of fibonacciSequence()) {
if (n-- <= 0) return f;
}
}
fibonacci(20)
10946
This kind of infinite generator becomes more useful with a take() generator like this
function* take(n, iterable) {
let it = iterable[Symbol.iterator]();
while(n-- > 0) {
let next = it.next();
if (next.done) return;
else yield next.value;
}
}
[...take(5, fibonacciSequence())]
[1, 1, 2, 3, 5]
Asynchronous Javascript
Promises, new in ES6, are objects that represent the not-yet-available result of an asynchronous operation.
The keywords async and await were introduced in ES2017 and provide new syntax that simplifies asynchronous programming by allowing you to structure your Promise based code as if it was synchronous.
Asynchronous iterators and the for/await loop were introduced in ES2018 and allow you to work with streams of asynchronous events using simple loops that appear synchronous.
Asynchronous Programming with Callbacks
Timers
setTimeout(checkForUpdates, 60000);
let updateIntervalId = setInterval(checkForUpdates, 60000);
function stopCheckingForUpdates() {
clearInterval(updateIntervalId);
}
Events
Event-driven JavaScript programs register callback functions for specified types of events in specified contexts, and the web browser invokes those functions whenever the specified events occur.
These callback functions are called event handlers or event listeners, and they are registered with addEventListener()
Ask the web browser to return an object representing the HTML
let okay = document.querySelector('#confirmUpdateDialogbutton.okay');
Now register a callback function to be invoked when the user clicks on that button
okay.addEventListener('click', applyUpdate);
Network Events
JavaScript running in the browser can fetch data from a web server with code like this:
function getCurrentVersionNumber(versionCallback) {
let request = new XMLHttpRequest();
request.open("GET", "http://www.example.com/api/version");
request.send();
request.onload = function() {
if (request.status === 200) {
let currentVersion = parseFloat(request.responseText);
versionCallback(null, currentVersion);
}
else {
versionCallback(response.statusText, null);
}
};
request.onerror = request.ontimeout = function(e) {
versionCallback(e.type, null);
};
}
Promises
Promises, a core language feature designed to simplify asynchronous programming.
A Promise is an object that represents the result of an asynchronous computation. That result may or may not be ready yet, and the Promise API is intentionally vague about this: there is no way to synchronously get the value of a Promise; you can only ask the Promise to call a callback function when the value is ready.
One real problem with callback-based asynchronous programming is that it is common to end up with callbacks inside callbacks inside callbacks, with lines of code so highly indented that it is difficult to read.
Promises allow this kind of nested callback to be re-expressed as a more linear Promise chain that tends to be easier to read and easier to reason about.
Another problem with callbacks is that they can make handling errors difficult. If an asynchronous function (or an asynchronously invoked callback) throws an exception, there is no way for that exception to propagate back to the initiator of the asynchronous operation. This is a fundamental fact about asynchronous programming: it breaks exception handling. Promises help here by standardizing a way to handle errors and providing a way for errors to propagate correctly through a chain of promises.
Note that Promises represent the future results of single asynchronous computations. They cannot be used to represent repeated asynchronous computations, however.
We can’t use Promises to replace setInterval() because that function invokes a callback function repeatedly, which is something that Promises are just not designed to do.
Using Promises
How we would use this Promise returning utility function
getJSON(url).then(jsonData => {
// callback function that will be asynchronously invoked with the parsed JSON value when it becomes available.
});
The Promise object defines a then() instance method. Instead of passing our callback function directly to getJSON(), we instead pass it to the then() method. When the HTTP response arrives, the body of that response is parsed as JSON, and the resulting parsed value is passed to the function that we passed to then().
If you call the then() method of a Promise object multiple times, each of the functions you specify will be called when the promised computation is complete.
Unlike many event listeners, though, a Promise represents a single computation, and each function registered with then() will be invoked only once.
function displayUserProfile(profile) { ...}
getJSON("/api/user/profile").then(displayUserProfile);
HANDLING ERRORS WITH PROMISES
Asynchronous operations, particularly those that involve networking, can typically fail in a number of ways, and robust code has to be written to handle the errors that will inevitably occur.
getJSON("/api/user/profile").then(displayUserProfile, handleProfileError);
if getJSON() runs normally, it passes its result to displayUserProfile(). If there is an error (the user is not logged in, the server is down, the user’s internet connection dropped, the request timed out, etc.), then getJSON() passes an Error object to handleProfileError().
In practice, it is rare to see two functions passed to then(). There is a better and more idiomatic way of handling errors when working with Promises.
To understand it, first consider what happens if getJSON() completes normally but an error occurs in displayUserProfile(). That callback function is invoked asynchronously when getJSON() returns, so it is also asynchronous and cannot meaningfully throw an exception (because there is no code on the call stack to handle it).
getJSON("/api/user/profile").then(displayUserProfile).catch(handleProfileError);
With this code, a normal result from getJSON() is still passed to displayUserProfile(), but any error in getJSON() or in displayUserProfile() (including any exceptions thrown by displayUserProfile) get passed to handleProfileError().
Chaining Promises
One of the most important benefits of Promises is that they provide a natural way to express a sequence of asynchronous operations as a linear chain of then() method invocations, without having to nest each operation within the callback of the previous one.
fetch(documentURL)
.then(response => response.json())
.then(document => {return render(document); })
.then(rendered => {cacheInDatabase(rendered); })
.catch(error => handle(error));
has largely been replaced by the newer, Promise-based Fetch API. In its simplest form, this new HTTP API is just the function fetch(). That promise is fulfilled when the HTTP response begins to arrive and the HTTP status and headers are available.
fetch("/api/user/profile")
.then(response => {
if (response.ok && response.headers.get("Content-Type") === "application/json") {
// What can we do here? We don't actually have the response body yet.
}
});
But although the initial Promise is fulfilled, the body of the response may not yet have arrived. So these text() and json() methods for accessing the body of the response themselves return Promises.
fetch("/api/user/profile")
.then(response => {
return response.json();
})
.then(profile => {
displayUserProfile(profile);
});
There is a second then() in the chain, which means that the first invocation of the then() method must itself return a Promise. That is not how Promises work, however.
When we write a chain of .then() invocations, we are not registering multiple callbacks on a single Promise object. Instead, each invocation of the then() method returns a new Promise object. That new Promise object is not fulfilled until the function passed to then() is complete.
fetch(theURL) // task 1; returns promise 1
.then(callback1) // task 2; returns promise 2
.then(callback2); // task 3; returns promise 3
Resolving Promises
There is actually a fourth Promise object involved as which brings up the point of what it means for a Promise to be “resolved.”
fetch() returns a Promise object which, when fulfilled, passes a Response object to the callback function we register. This Response object has .text(), .json(), and other methods to request the body of the HTTP response in various forms. But since the body may not yet have arrived, these methods must return Promise objects.
“task 2” calls the .json() method and returns its value. This is the fourth Promise object, and it is the return value of the callback1() function.
Let’s consider:
function c1(response) {
let p4 = response.json();
return p4;
}
// callback 1
// returns promise 4
function c2(profile) {
displayUserProfile(profile);
}
// callback 2
let p1 = fetch("/api/user/profile");
promise 1, task 1
let p2 = p1.then(c1);
promise 2, task 2
let p3 = p2.then(c2);
promise 3, task 3
In order for Promise chains to work usefully, the output of task 2 must become the input to task 3. The input to task 3 is the body of the URL that was fetched, parsed as a JSON object. But the return value of callback c1 is not a JSON object, but Promise p4 for that JSON object.
When p1 is fulfilled, c1 is invoked, and task 2 begins. And when p2 is fulfilled, c2 is invoked, and task 3 begins.
And when p2 is fulfilled, c2 is invoked, and task 3 begins. But just because task 2 begins when c1 is invoked,it does not mean that task 2 must end when c1 returns.
Promises are about managing asynchronous tasks, and if task 2 is asynchronous, then that task will not be complete by the time the callback returns.
When you pass a callback c to the then() method, then() returns a Promise p and arranges to asynchronously invoke c at some later time. The callback performs some computation and returns a value v. When the callback returns, p is resolved with the value v. When a Promise is resolved with a value that is not itself a Promise, it is immediately fulfilled with that value.
So if c returns a non-Promise, that return value becomes the value of p, p is fulfilled and we are done. But if the return value v is itself a Promise, then p is resolved but not yet fulfilled.
At this stage, p cannot settle until the Promise v settles. If v is fulfilled, then p will be fulfilled to the same value. If v is rejected, then p will be rejected for the same reason. This is what the “resolved” state of a Promise means
the Promise has become associated with, or “locked onto,” another Promise. We don’t know yet whether p will be fulfilled or rejected, but our callback c no longer has any control over that. p is “resolved” in the sense that its fate now depends entirely on what happens to Promise v.
Let’s bring this back to our URL-fetching example. When c1 returns p4, p2 is resolved. But being resolved is not the same as being fulfilled, so task 3 does not begin yet. When the full body of the HTTP response becomes available, then the .json() method can parse it and use that parsed value to fulfill p4. When p4 is fulfilled, p2 is automatically fulfilled as well, with the same parsed JSON value. At this point, the parsed JSON object is passed to c2, and task 3 begins.
More on Promises and Errors
With synchronous code, if you leave out error-handling code, you’ll at least get an exception and a stack trace that you can use to figure out what is going wrong. With asynchronous code, unhandled exceptions will often go unreported, and errors can occur silently, making them much harder to debug. The good news is that the .catch() method makes it easy to handle errors when working with Promises.
THE CATCH AND FINALLY METHODS
The .catch() method of a Promise is simply a shorthand way to call .then() with null as the first argument and an error-handling callback as the second argument.
Normal exceptions don’t work with asynchronous code. The .catch() method of Promises is an alternative that does work for asynchronous code.
fetch("/api/user/profile")
.then(response => {
if (!response.ok) {
return null;
}
let type = response.headers.get("content-type");
if (type !== "application/json") {
throw new TypeError(`Expected JSON, got ${type}`);
}
return response.json();
})
.then(profile => {
if (profile) {
displayUserProfile(profile);
}
else {
displayLoggedOutProfilePage();
}
})
.catch(e => {
if (e instanceof NetworkError) {
displayErrorMessage("Check your internet connection.");
}
else if (e instanceof TypeError) {
displayErrorMessage("Something is wrong with our server!");
}
else {
console.error(e);
}
});
p1 is the Promise returned by the fetch() call
p2 is the Promise returned by the first .then() call
c1 is the callback that we pass to that .then() call
p3 is the Promise returned by the second .then() call
c2 is the callback we pass to that call
c3 is the callback that we pass to the .catch() call
The first thing that could fail is the fetch() request itself. Let’s say p1 was rejected with a NetworkError object.
We didn’t pass an error-handling callback function as the second argument to the .then() call, so p2 rejects as well with the same NetworkError object.
Without a handler, though, p2 is rejected, and then p3 is rejected for the same reason.
At this point, the c3 error-handling callback is called, and the NetworkError-specific code within it runs.
There are a couple of things worth noting about this code. First, notice that the error object thrown with a regular, synchronous throw statement ends up being handled asynchronously with a .catch() method invocation in a Promise chain. This should make it clear why this shorthand method is preferred over passing a second argument to .then(), and also why it is so idiomatic to end Promise chains with a .catch() call.
it is also perfectly valid to use .catch() elsewhere in a Promise chain. If one of the stages in your Promise chain can fail with an error, and if the error is some kind of recoverable error that should not stop the rest of the chain from running, then you can insert a .catch() call in the chain, resulting in code that might look like this:
startAsyncOperation()
.then(doStageTwo)
.catch(recoverFromStageTwoError)
.then(doStageThree)
.then(doStageFour)
.catch(logStageThreeAndFourErrors);
If the callback returns normally, then the .catch() callback will be skipped, and the return value of the previous callback will become the input to the next .then() callback.
Once an error has been passed to a .catch() callback, it stops propagating down the Promise chain. A .catch() callback can throw a new error, but if it returns normally, than that return value is used to resolve and/or fulfill the associated Promise, and
the error stops propagating.
Sometimes, in complex network environments, errors can occur more or less at random, and it can be appropriate to handle those errors by simply retrying the asynchronous request.
queryDatabase()
.catch(e => wait(500).then(queryDatabase))
.then(displayTable)
.catch(displayDatabaseError);
Promises in Parallel
Sometimes,we want to execute a number of asynchronous operations in parallel. The function Promise.all() can do this. Promise.all() takes an array of Promise objects as its input and returns a Promise.
The returned Promise will be rejected if any of the input Promises are rejected. Otherwise, it will be fulfilled with an array of the fulfillment values of each of the input Promises.
const urls = [ /* zero or more URLs here */ ];
promises = urls.map(url => fetch(url).then(r => r.text()));
Promise.all(promises)
.then(bodies => { /* do something with the array of strings */ })
.catch(e => console.error(e));
The Promise returned by Promise.all() rejects when any of the input Promises is rejected. This happens immediately upon the first rejection and can happen while other input Promises are still pending. In ES2020, Promise.allSettled() takes an array of input
Promises and returns a Promise, just like Promise.all() does. But Promise.allSettled() never rejects the returned Promise, and it does not fulfill that Promise until all of the input Promises have settled. The Promise resolves to an array of objects, with one object for each input Promise. Each of these returned objects has a status property set to “fulfilled” or “rejected.” If the status is “fulfilled”, then the object will also have a value property that gives the fulfillment value. And if the status is “rejected”, then the object will also have a reason property that gives the error or rejection value of the corresponding Promise.
Promise.allSettled([Promise.resolve(1), Promise.reject(2),3]).then(results => {
results[0] // => { status: "fulfilled", value: 1 }
results[1] // => { status: "rejected", reason: 2 }
results[2] // => { status: "fulfilled", value: 3 }
});
Occasionally, you may want to run a number of Promises at once but may only care about the value of the first one to fulfill. In that case, you can use Promise.race() instead of Promise.all(). It returns a Promise that is fulfilled or rejected when the first of the Promises in the input array is fulfilled or rejected.
Making Promises
Promises in Sequence
async and await
These new keywords dramatically simplify the use of Promises and allow us to write Promise-based, asynchronous code that looks like synchronous code that blocks while waiting for network responses or other asynchronous events.
Asynchronous code can’t return a value or throw an exception the way that regular synchronous code can. And this is why Promises are designed the way the are. The value of a fulfilled Promise is like the return value of a synchronous function. And the value of a rejected Promise is like a value thrown by a synchronous function.
async and await take efficient, Promise-based code and hide the Promises so that your asynchronous code can be as easy to read and as easy to reason about as inefficient, blocking, synchronous code.
Given a Promise object p, the expression await p waits until p settles. If p fulfills, then the value of await p is the fulfillment value of p. On the other hand, if p is rejected, then the await p expression throws the rejection value of p.
let response = await fetch("/api/user/profile");
let profile = await response.json();
It is critical to understand right away that the await keyword does not cause your program to block and literally do nothing until the specified Promise settles. The code remains asynchronous, and the await simply disguises this fact. This means that any code that uses await is itself asynchronous.
async Functions
Because any code that uses await is asynchronous, there is one critical rule: you can only use the await keyword within functions that have been declared with the async keyword.
async function getHighScore() {
let response = await fetch("/api/user/profile");
let profile = await response.json();
return profile.highScore;
}
Declaring a function async means that the return value of the function will be a Promise even if no Promise-related code appears in the body of the function.
The getHighScore() function is declared async, so it returns a Promise. And because it returns a Promise, we can use the await keyword with it:
displayHighScore(await getHighScore());
Awaiting Multiple Promises
Suppose that we’ve written our getJSON() function using async:
async function getJSON(url) {
let response = await fetch(url);
let body = await response.json();
return body;
}
And now suppose that we want to fetch two JSON values with this function
let value1 = await getJSON(url1);
let value2 = await getJSON(url2);
The problem with this code is that it is unnecessarily sequential: the fetch of the second URL will not begin until the first fetch is complete. If the second URL does not depend on the value obtained from the firstURL, then we should probably try to fetch the two values at the same time.
let [value1, value2] = await Promise.all([getJSON(url1), getJSON(url2)]);
The for/await Loop
Suppose you have an array of URLs:
const urls = [url1, url2, url3];
You can call fetch() on each URL to get an array of Promises:
const promises = urls.map(url => fetch(url));
We could now use Promise.all() to wait for all the Promises in the array to be fulfilled. But suppose we want the results of the first fetch as soon as they become available and don’t want to wait for all the URLs to be fetched.
for(const promise of promises) {
response = await promise;
handle(response);
}
←>
for await (const response of promises) {
handle(response);
}
both examples will only work if they are within functions declared async; a for/await loop is no different than a regular await expression in that way
If you found this guide helpful feel free to checkout my GitHub/gist’s where I host similar content:
Or checkout my personal resource site:
Differences between Node.js and browsers
There are many differences between Node.js and browser environments, but many of them are small and inconsequential in practice. For example, in our Asynchronous lesson, we noted how Node’s setTimeout has a slightly different return value from a browser’s setTimeout. Let’s go over a few notable differences between the two environments.
Global vs Window
In the Node.js runtime, the global object is the object where global variables are stored. In browsers, the window object is where global variables are stored. The window also includes properties and methods that deal with drawing things on the screen like images, links, and buttons. Node doesn’t need to draw anything, and so it does not come with such properties. This means that you can’t reference window in Node.
Most browsers allow you to reference global but it is really the same object as window.
Document
Browsers have access to a document object that contains the HTML of a page that will be rendered to the browser window. There is no document in Node.
Location
Browsers have access to a location that contains information about the web address being visited in the browser. There is no location in Node, since it is not on the web.
Require and module.exports
Node has a predefined require function that we can use to import installed modules like readline. We can also import and export across our own files using require and module.exports. For example, say we had two different files, animals.js and cat.js, that existed in the same directory:
https://gist.github.com/bgoonz/cae36a07000d5dec8769d0e8cbc431b3
If we execute animals.js in Node, the program would print ‘Sennacy is a great pet!’.
Browsers don’t have a notion of a file system so we cannot use require or module.exports in the same way.
The fs module
Node comes with an fs module that contains methods that allow us to interact with our computer’s File System through JavaScript. No additional installations are required; to access this module we can simply require it. We recommend that you code along with this reading. Let’s begin with a change-some-files.js script that imports the module:
// change-some-files.js
const fs = require("fs");
Similar to what we saw in the readline lesson, require will return to us a object with many properties that will enable us to do file I/O.
Did you know? I/O is short for input/output. It’s usage is widespread and all the hip tech companies are using it, like.io.
The fs module contains tons of functionality! Chances are that if there is some operation you need to perform regarding files, the fs module supports it. The module also offers both synchronous and asynchronous implementations of these methods. We prefer to not block the thread and so we’ll opt for the asynchronous flavors of these methods.
Creating a new file
To create a file, we can use the [writeFile](https://nodejs.org/api/fs.html#fs_fs_writefile_file_data_options_callback) method. According to the documentation, there are a few ways to use it. The most straight forward way is:
https://gist.github.com/bgoonz/8898ad673bd2ecee9d93f8ec267cf213
The code acreate-a-nnew-file.js (github.com)bove will create a new file called foo.txt in the same directory as our change-some-file.js script. It will write the string 'Hello world!' into that newly created file. The third argument specifies the encoding of the characters. There are different ways to encode characters; UTF-8 is the most common and you’ll use this in most scenarios. The fourth argument to writeFile is a callback that will be invoked when the write operation is complete. The docs indicate that if there is an error during the operation (such as an invalid encoding argument), an error object will be passed into the callback. This type of error handling is quite common for asynchronous functions. Like we are used to, since writeFile is asynchronous, we need to utilize callback chaining if we want to guarantee that commands occur after the write is complete or fails.
Beware! If the file name specified to _writeFile_ already exists, it will completely overwrite the contents of that file.
We won’t be using the foo.txt file in the rest of this reading.
Reading existing files
To explore how to read a file, we’ll use VSCode to manually create a poetry.txt file within the same directory as our change-some-file.js script. Be sure to create this if you are following along.
Our poetry.txt file will contain the following lines:
My code fails
I do not know why
My code works
I do not know why
We can use the [readFile](https://nodejs.org/api/fs.html#fs_fs_readfile_path_options_callback) method to read the contents of this file. The method accepts very similar arguments to writeFile, except that the callback may be passed an error object and string containing the file contents. In the snippet below, we have replaced our previous writeFile code with readFile:
https://gist.github.com/bgoonz/3623344a6292e5210c9a11307a5549e6
Running the code above would print the following in the terminal:
THE CONTENTS ARE:
My code fails
I do not know why
My code works
I do not know why
Success! From here, you can do anything you please with the data read from the file. For example, since data is a string, we could split the string on the newline character \n to obtain an array of the file’s lines:
https://gist.github.com/bgoonz/42a46d97654db0e6c6eef77f80b59606
THE CONTENTS ARE:
[ 'My code fails',
'I do not know why',
'My code works',
'I do not know why' ]
The third line is My code works
File I/O
Using the same _poetry.txt_ file from before:
My code fails
I do not know why
My code works
I do not know why
Let’s replace occurrences of the phrase ‘do not’ with the word ‘should’.
We can read the contents of the file as a string, manipulate this string, then write this new string back into the file.
We’ll need to utilize callback chaining in order for this to work since our file I/O is asynchronous:
https://gist.github.com/bgoonz/8d3ba6828f5ba9a4692d0a938697099f
Executing the script above will edit the poetry.txt file to contain:
My code fails
I should know why
My code works
I should know why
Refactor:
https://gist.github.com/bgoonz/1ad31003fc1b2880201642b48df87e2e
If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:
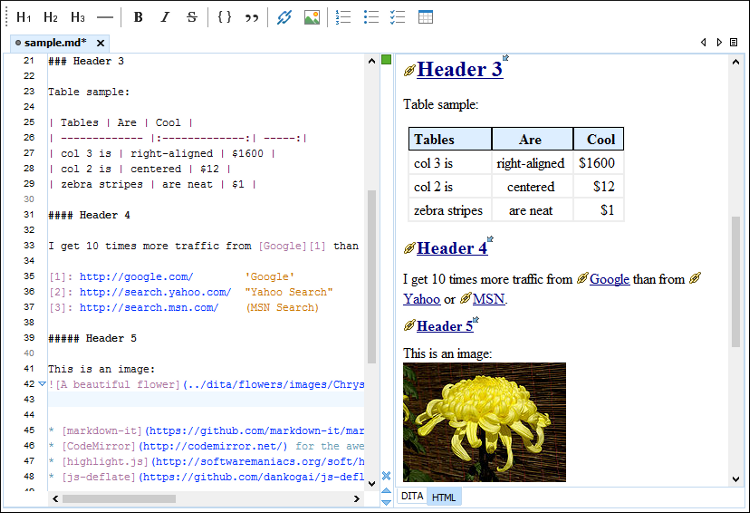
https://github.com/bgoonz/Markdown-Templates.git
Basic Syntax Guide
This topic is meant to give you a very basic overview of how Markdown works, showing only some of the most common operations you use most frequently. Keep in mind that you can also use the Edit menus to inject markdown using the toolbar, which serves as a great way to see how Markdown works. However, Markdown’s greatest strength lies in its simplicity and keyboard friendly approach that lets you focus on writing your text and staying on the keyboard.
What is Markdown
Markdown is very easy to learn and get comfortable with due it’s relatively small set of markup ‘commands’. It uses already familiar syntax to represent common formatting operations. Markdown understands basic line breaks so you can generally just type text.
Markdown also allows for raw HTML inside of a markdown document, so if you want to embed something more fancy than what Markdowns syntax can do you can always fall back to HTML. However to keep documents readable that’s generally not recommended.
Basic Markdown Syntax
The following are a few examples of the most common things you are likely to do with Markdown while building typical documentation.
Bold and Italic
markdown
This text **is bold**. This text *is italic*.
This text is bold.
This text is italic.
Header Text
markdown
# Header 1## Header 2### Header 3#### Header 4##### Header 5###### Header 6
Header 1
Header 2
Header 3
Header 4
Header 5Header 6
Line Continuation
By default Markdown adds paragraphs at double line breaks. Single line breaks by themselves are simply wrapped together into a single line. If you want to have soft returns that break a single line, add two spaces at the end of the line.
markdown
This line has a paragraph break at the end (empty line after).
Theses two lines should display as a singleline because there's no double space at the end.
The following line has a soft break at the end (two spaces at end) This line should be following on the very next line.
This line has a paragraph break at the end (empty line after).
Theses two lines should display as a single line because there’s no double space at the end.
The following line has a soft break at the end (two spaces at end)
This line should be following on the very next line.
Links
markdown
[Help Builder Web Site](http://helpbuilder.west-wind.com/)
If you need additional image tags like targets or title attributes you can also embed HTML directly:
markdown
Go the Help Builder sitest Wind site: <a href="http://west-wind.com/" target="_blank">Help Builder Site</a>.
Images
markdown


Block Quotes
Block quotes are callouts that are great for adding notes or warnings into documentation.
markdown
> ### Headers break on their own> Note that headers don't need line continuation characters as they are block elements and automatically break. Only textlines require the double spaces for single line breaks.
Headers break on their own
Note that headers don’t need line continuation characters as they are block elements and automatically break. Only text lines require the double spaces for single line breaks.
Fontawesome Icons
Help Builder includes a custom syntax for FontAwesome icons in its templates. You can embed a @ icon- followed by a font-awesome icon name to automatically embed that icon without full HTML syntax.
markdown
Gear: Configuration
Configuration
HTML Markup
You can also embed plain HTML markup into the page if you like. For example, if you want full control over fontawesome icons you can use this:
markdown
This text can be **embedded** into Markdown: <i class="fa fa-refresh fa-spin fa-lg"></i> Refresh Page
This text can be embedded into Markdown:
Refresh Page
Unordered Lists
markdown
* Item 1* Item 2* Item 3This text is part of the third item. Use two spaces at end of the the list item to break the line.
A double line break, breaks out of the list.
- Item 1
- Item 2
- Item 3
This text is part of the third item. Use two spaces at end of the the list item to break the line.
A double line break, breaks out of the list.
Ordered Lists
markdown
1. **Item 1** Item 1 is really something2. **Item 2** Item two is really something else
If you want lines to break using soft returns use two spaces at the end of a line.
- Item 1 Item 1 is really something
- Item 2
Item two is really something else
If you want to lines to break using soft returns use to spaces at the end of a line.
Inline Code
If you want to embed code in the middle of a paragraph of text to highlight a coding syntax or class/member name you can use inline code syntax:
markdown
Structured statements like `for x =1 to 10` loop structures can be codified using single back ticks.
Structured statements like for x =1 to 10 loop structures can be codified using single back ticks.
Code Blocks with Syntax Highlighting
Markdown supports code blocks syntax in a variety of ways:
markdown
The following code demonstrates:
// This is code by way of four leading spaces // or a leading tab
More text here
The following code demonstrates:
pgsql
// This is code by way of four leading spaces// or a leading tab
More text here
Code Blocks
You can also use triple back ticks plus an optional coding language to support for syntax highlighting (space injected before last ` to avoid markdown parsing):
markdown
`` `csharp// this code will be syntax highlightedfor(var i=0; i++; i < 10){ Console.WriteLine(i);}`` `
csharp
// this code will be syntax highlightedfor(var i=0; i++; i < 10){ Console.WriteLine(i);}
Many languages are supported: html, xml, javascript, css, csharp, foxpro, vbnet, sql, python, ruby, php and many more. Use the Code drop down list to get a list of available languages.
You can also leave out the language to get no syntax coloring but the code box:
markdown
`` `dosrobocopy c:\temp\test d:\temp\test`` `
dos
robocopy c:\temp\test d:\temp\test
To create a formatted block but without formatting use the txt format:
markdown
`` `txtThis is some text that will not be syntax highlightedbut shows up in a code box.`` `
which gives you:
text
This is some text that will not be syntax highlightedbut shows up in a code box.
If you found this guide helpful feel free to checkout my github/gists where I host similar content:
https://github.com/bgoonz/Markdown-Templates.git
Or Checkout my personal Resource Site:
https://github.com/bgoonz/Markdown-Templates.git
CODEX

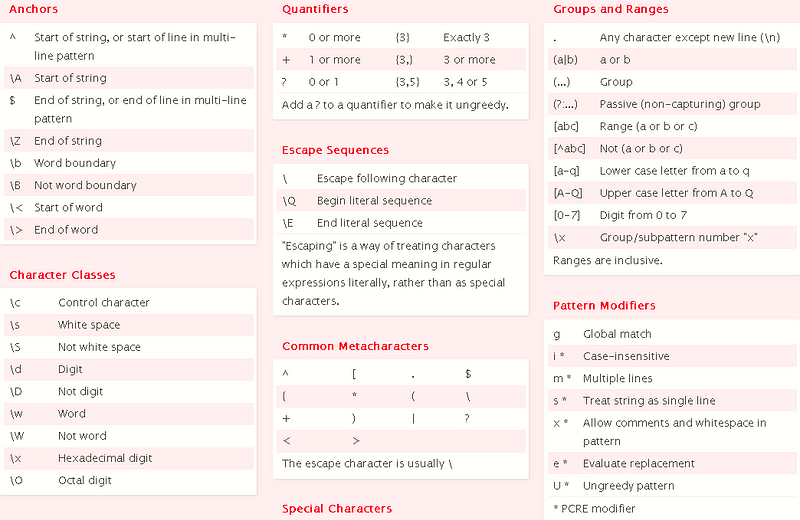
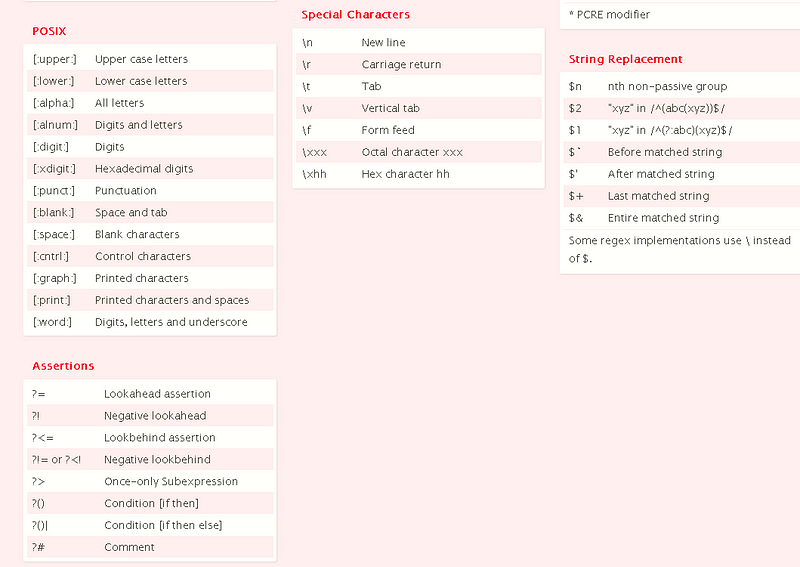
description:
Regular expressions are patterns used to match character combinations in strings. In JavaScript, regular expressions are also objects. These patterns are used with the [_exec()_](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/RegExp/exec.html) and [_test()_](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/RegExp/test.html) methods of [_RegExp_](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/RegExp.html), and with the [_match()_](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/match.html), [_matchAll()_](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/matchAll.html), [_replace()_](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/replace.html), [_replaceAll()_](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/replaceAll.html), [_search()_](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/search.html), and [_split()_](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/split.html) methods of [_String_](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String.html). This chapter describes JavaScript regular expressions.
Creating a regular expression
You construct a regular expression in one of two ways:
- Using a regular expression literal, which consists of a pattern enclosed between slashes, as follows:
**let re = /ab+c/;**
- Regular expression literals provide compilation of the regular expression when the script is loaded. If the regular expression remains constant, using this can improve performance.
2. Or calling the constructor function of the [**RegExp**](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/RegExp.html) object, as follows:
let re = new RegExp('ab+c');
Using the constructor function provides runtime compilation of the regular expression. Use the constructor function when you know the regular expression pattern will be changing, or you don’t know the pattern and are getting it from another source, such as user input.
Writing a regular expression pattern
A regular expression pattern is composed of simple characters, such as /abc/, or a combination of simple and special characters, such as /ab*c/ or /Chapter (\d+)\.\d*/.
The last example includes parentheses, which are used as a memory device. The match made with this part of the pattern is remembered for later use.
Using simple patterns
Simple patterns are constructed of characters for which you want to find a direct match.
For example, the pattern /abc/ matches character combinations in strings only when the exact sequence "abc" occurs (all characters together and in that order).
Such a match would succeed in the strings "Hi, do you know your abc's?" and "The latest airplane designs evolved from slabcraft."
In both cases the match is with the substring "abc".
There is no match in the string "Grab crab" because while it contains the substring "ab c", it does not contain the exact substring "abc".
Using special characters
When the search for a match requires something more than a direct match, such as finding one or more b’s, or finding white space, you can include special characters in the pattern.
For example, to match a single _"a"_ followed by zero or more _"b"_s followed by _"c"_, you’d use the pattern /ab*c/:
the
*after"b"means “0 or more occurrences of the preceding item.” In the string"cbbabbbbcdebc", this pattern will match the substring"abbbbc".
Assertions : Assertions include boundaries, which indicate the beginnings and endings of lines and words, and other patterns indicating in some way that a match is possible (including look-ahead, look-behind, and conditional expressions).
Character classes : Distinguish different types of characters. For example, distinguishing between letters and digits.
Groups and ranges : Indicate groups and ranges of expression characters.
Quantifiers : Indicate numbers of characters or expressions to match.
Unicode property escapes : Distinguish based on unicode character properties, for example, upper- and lower-case letters, math symbols, and punctuation.
If you want to look at all the special characters that can be used in regular expressions in a single table, see the following:
Special characters in regular expressions.
Escaping
If you need to use any of the special characters literally (actually searching for a "*", for instance), you must escape it by putting a backslash in front of it.
For instance, to search for "a" followed by "*" followed by "b",
you’d use
/a\*b/— the backslash “escapes” the"*", making it literal instead of special.
Similarly, if you’re writing a regular expression literal and need to match a slash (“/”), you need to escape that (otherwise, it terminates the pattern)
For instance, to search for the string “/example/” followed by one or more alphabetic characters, you’d use /\/example\/[a-z]+/i
–the backslashes before each slash make them literal.
To match a literal backslash, you need to escape the backslash.
For instance, to match the string “C:\” where “C” can be any letter,
you’d use /[A-Z]:\\/
— the first backslash escapes the one after it, so the expression searches for a single literal backslash.
If using the RegExp constructor with a string literal, remember that the backslash is an escape in string literals, so to use it in the regular expression, you need to escape it at the string literal level.
/a\*b/ and new RegExp("a\\*b") create the same expression,
which searches for “a” followed by a literal “*” followed by “b”.
If escape strings are not already part of your pattern you can add them using [String.replace](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/replace.html):
function escapeRegExp(string) { return string.replace(/[.*+\-?^${}()|[\]\\]/g, '\\$&'); // $& means the whole matched string}
The “g” after the regular expression is an option or flag that performs a global search, looking in the whole string and returning all matches.
Using parentheses
Parentheses around any part of the regular expression pattern causes that part of the matched substring to be remembered.
Once remembered, the substring can be recalled for other use.
Using regular expressions in JavaScript
Regular expressions are used with the **RegExp** methods
**test()** and **exec()**
and with the **String** methods **match()**, **replace()**, **search()**, and **split()**.
Method Descriptions
[exec()](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/RegExp/exec.html)
Executes a search for a match in a string.
It returns an array of information or null on a mismatch.
[test()](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/RegExp/test.html)
Tests for a match in a string.
It returns true or false.
[match()](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/match.html)
Returns an array containing all of the matches, including capturing groups, or null if no match is found.
[matchAll()](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/matchAll.html)
Returns an iterator containing all of the matches, including capturing groups.
[search()](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/search.html)
Tests for a match in a string.
It returns the index of the match, or -1 if the search fails.
[replace()](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/replace.html)
Executes a search for a match in a string, and replaces the matched substring with a replacement substring.
[replaceAll()](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/replaceAll.html)
Executes a search for all matches in a string, and replaces the matched substrings with a replacement substring.
[split()](https://github.com/bgoonz/Cheat-Sheets/blob/Reference/Global_Objects/String/split.html)
Uses a regular expression or a fixed string to break a string into an array of substrings.
Methods that use regular expressions
When you want to know whether a pattern is found in a string, use the test() or search() methods;
for more information (but slower execution) use the exec() or match() methods.
If you use exec() or match() and if the match succeeds, these methods return an array and update properties of the associated regular expression object and also of the predefined regular expression object, RegExp.
If the match fails, the **exec()** method returns **null** (which coerces to false).
In the following example, the script uses the exec() method to find a match in a string.
let myRe = /d(b+)d/g;let myArray = myRe.exec('cdbbdbsbz');
If you do not need to access the properties of the regular expression, an alternative way of creating myArray is with this script:
let myArray = /d(b+)d/g.exec('cdbbdbsbz'); // similar to "cdbbdbsbz".match(/d(b+)d/g); however, // "cdbbdbsbz".match(/d(b+)d/g) outputs Array [ "dbbd" ], while // /d(b+)d/g.exec('cdbbdbsbz') outputs Array [ 'dbbd', 'bb', index: 1, input: 'cdbbdbsbz' ].
(See different behaviors for further info about the different behaviors.)
If you want to construct the regular expression from a string, yet another alternative is this script:
let myRe = new RegExp('d(b+)d', 'g');let myArray = myRe.exec('cdbbdbsbz');
With these scripts, the match succeeds and returns the array and updates the properties shown in the following table.
Results of regular expression execution.
You can use a regular expression created with an object initializer without assigning it to a letiable.
If you do, however, every occurrence is a new regular expression.
For this reason, if you use this form without assigning it to a letiable, you cannot subsequently access the properties of that regular expression.
For example, assume you have this script:
let myRe = /d(b+)d/g;let myArray = myRe.exec('cdbbdbsbz');console.log('The value of lastIndex is ' + myRe.lastIndex);// "The value of lastIndex is 5"
However, if you have this script:
let myArray = /d(b+)d/g.exec('cdbbdbsbz');console.log('The value of lastIndex is ' + /d(b+)d/g.lastIndex);// "The value of lastIndex is 0"
The occurrences of /d(b+)d/g in the two statements are different regular expression objects and hence have different values for their lastIndex property.
If you need to access the properties of a regular expression created with an object initializer, you should first assign it to a variable.
[Advanced searching with flags]
Regular expressions have six optional flags that allow for functionality like global and case insensitive searching.
These flags can be used separately or together in any order, and are included as part of the regular expression.
Flag Description Corresponding property
g Global search. RegExp.prototype.global
i Case-insensitive search. RegExp.prototype.ignoreCase
m Multi-line search. RegExp.prototype.multiline
s Allows . to match newline characters. RegExp.prototype.dotAll
u “unicode”; treat a pattern as a sequence of unicode code points. RegExp.prototype.unicode
y Perform a “sticky” search that matches starting at the current position in the target string. RegExp.prototype.sticky
Regular expression flags
To include a flag with the regular expression, use this syntax:
let re = /pattern/flags;
or
let re = new RegExp('pattern', 'flags');
Note that the flags are an integral part of a regular expression. They cannot be added or removed later.
For example, re = /\w+\s/g creates a regular expression that looks for one or more characters followed by a space, and it looks for this combination throughout the string.
let re = /\w+\s/g;let str = 'fee fi fo fum';let myArray = str.match(re);console.log(myArray);// ["fee ", "fi ", "fo "]
You could replace the line:
let re = /\w+\s/g;
with:
let re = new RegExp('\\w+\\s', 'g');
and get the same result.
The behavior associated with the g flag is different when the .exec() method is used.
The roles of “class” and “argument” get reversed:
In the case of .match(), the string class (or data type) owns the method and the regular expression is just an argument,
while in the case of .exec(), it is the regular expression that owns the method, with the string being the argument.
Contrast this _str.match(re)_ versus _re.exec(str)_.
The g flag is used with the .exec() method to get iterative progression.
let xArray; while(xArray = re.exec(str)) console.log(xArray);// produces: // ["fee ", index: 0, input: "fee fi fo fum"]// ["fi ", index: 4, input: "fee fi fo fum"]// ["fo ", index: 7, input: "fee fi fo fum"]
The m flag is used to specify that a multiline input string should be treated as multiple lines.
If the m flag is used, ^ and $ match at the start or end of any line within the input string instead of the start or end of the entire string.
Using special characters to verify input
In the following example, the user is expected to enter a phone number. When the user presses the “Check” button, the script checks the validity of the number. If the number is valid (matches the character sequence specified by the regular expression), the script shows a message thanking the user and confirming the number. If the number is invalid, the script informs the user that the phone number is not valid.
Within non-capturing parentheses (?: , the regular expression looks for three numeric characters \d{3} OR | a left parenthesis \( followed by three digits \d{3}, followed by a close parenthesis \), (end non-capturing parenthesis )), followed by one dash, forward slash, or decimal point and when found, remember the character ([-\/\.]), followed by three digits \d{3}, followed by the remembered match of a dash, forward slash, or decimal point \1, followed by four digits \d{4}.
The Change event activated when the user presses Enter sets the value of RegExp.input.
HTML
<p> Enter your phone number (with area code) and then click "Check". <br> The expected format is like ###-###-####.</p><form action="#"> <input id="phone"> <button onclick="testInfo(document.getElementById('phone'));">Check</button></form>
JavaScript
let re = /(?:\d{3}|\(\d{3}\))([-\/\.])\d{3}\1\d{4}/;
function testInfo(phoneInput) {
let OK = re.exec(phoneInput.value);
if (!OK) {
console.error(phoneInput.value + ' isn\'t a phone number with area code!');
} else {
console.log('Thanks, your phone number is ' + OK[0]);}
}
Cheat Sheet
https://gist.github.com/bgoonz/c559a8e4d6fd2eb586b2e8452d6e233b

https://gist.github.com/bgoonz/03e15da8a9f4dd3c536e9fbbd9f380c7
If you found this guide helpful feel free to checkout my GitHub/gist’s where I host similar content:
Or Checkout my personal Resource Site:
Basics of Writing Files in Python
The common methods to operate with files are open() to open a file,
seek() to set the file’s current position at the given offset, and
close() to close th
As pointed out in a previous article that deals with reading data from files, file handling belongs to the essential knowledge of every professional Python programmer. This feature is a core part of the Python language, and no extra module needs to be loaded to do it properly.
Basics of Writing Files in Python
The common methods to operate with files are open() to open a file, seek() to set the file’s current position at the given offset, and close() to close the file afterwards. The open() method returns a file handle that represents a file object to be used to access the file for reading, writing, or appending.
Writing to a file requires a few decisions — the name of the file in which to store data and the access mode of the file. Available are two modes, writing to a new file (and overwriting any existing data) and appending data at the end of a file that already exists. The according abbreviations are “w”, and “a”, and have to be specified before opening a file.
In this article we will explain how to write data to a file line by line, as a list of lines, and appending data at the end of a file.
Writing a Single Line to a File
This first example is pretty similar to writing to files with the popular programming languages C and C++, as you’ll see in Listing 1. The process is pretty straightforward. First, we open the file using the open() method for writing, write a single line of text to the file using the write() method, and then close the file using the close() method. Keep in mind that due to the way we opened the “helloworld.txt” file it will either be created if it does not exist yet, or it will be completely overwritten.
filehandle = open('helloworld.txt', 'w')
filehandle.write('Hello, world!\n')
filehandle.close()
Listing 1
This entire process can be shortened using the with statement. Listing 2 shows how to write that. As already said before keep in mind that by opening the “helloworld.txt” file this way will either create if it does not exist yet or completely overwritten, otherwise.
with open('helloworld.txt', 'w') as filehandle:
filehandle.write('Hello, world!\n')
Listing 2
Writing a List of Lines to a File
In reality a file does not consist only of a single line, but much more data. Therefore, the contents of the file are stored in a list that represents a file buffer. To write the entire file buffer we’ll use the writelines() method. Listing 3 gives you an example of this.
filehandle = open("helloworld.txt", "w")
filebuffer = ["a first line of text", "a second line of text", "a third line"]
filehandle.writelines(filebuffer)
filehandle.close()
Listing 3
Running the Python program shown in Listing 3 and then using the cat command we can see that the file “helloworld.txt” has the following content:
$ cat helloworld.txt
a first line of text a second line of text a third line
Listing 4
This happens because the **writelines()** method does not automatically add any line separators when writing the data. Listing 5 shows how to achieve that, writing each line of text on a single line by adding the line separator “\n”. Using a generator expression each line is substituted by the line plus line separator. Again, you can formulate this using the with statement.
with open('helloworld.txt', 'w') as filehandle:
filebuffer = ["a line of text", "another line of text", "a third line"]
filehandle.writelines("%s\n" % line for line in filebuffer)
Listing 5
Now, the output file “helloworld.txt” has the desired content as shown in Listing 6:
$ cat helloworld.txt
a first line of text
a second line of text
a third line
Listing 6
Interestingly, there is a way to use output redirection in Python to write data to files. Listing 7 shows how to code that for Python 2.x.
filename = "helloworld.txt"
filecontent = ["Hello, world", "a second line", "and a third line"]
with open(filename, 'w') as filehandle:
for line in filecontent:
print >>filehandle, line
Listing 7
For the latest Python releases this does not work in the same way anymore. To do something like this we must use the **sys** module. It allows us to access the UNIX standard output channels via sys.stdout, sys.stdin, and sys.stderr.
In our case we preserve the original value of the output channel sys.stdout, first (line 8 in the code below), redefine it to the handle of our output file,
next (line 15), print the data as usual (line 18), and finally restore the original value of the output channel sys.stdout (line 21). Listing 8 contains the example code.
import sys
filename = "helloworld.txt"
original = sys.stdout
filecontent = ["Hello, world", "a second line", "and a third line"]
with open(filename, 'w') as filehandle:
sys.stdout = filehandle
for line in filecontent:
print(line)
sys.stdout = original
Listing 8
This is not necessarily best practice, but it does give you other options for writing lines to a file.
Appending Data to a File
So far, we have stored data in new files or in overwritten data in existing files. But what if we want to append data to the end of an existing file? In this case we would need to open the existing file using a different access mode. We change that to ‘a’ instead of ‘w’.
Listing 9 shows how to handle that. And Listing 10 does the same thing, but it uses the with statement rather.
filehandle = open('helloworld.txt','a')
filehandle.write('\n' + 'Hello, world!\n')
filehandle.close()
Listing 9
with open('helloworld.txt', 'a') as filehandle:
filehandle.write('\n' + 'Hello, world!\n')
Listing 10
Using the same helloworld.txt file from before, running this code will produce the following file contents:
$ cat helloworld.txt
Hello, world
a second line
and a third line
Hello, world!
Conclusion
Writing plain text data to files, or appending data to existing files, is as easy as reading from files in Python. As soon as a file is closed after writing or appending data, Python triggers a synchronization call. As a result, the updated file is immediately written to disk.
If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:
CSS Selectors
**CSS Selector**: Applies styles to a specific DOM element(s), there are various types:**Type Selectors**: Matches by node name.**Class Selectors**: Matches by class name.**ID Selectors**: Matches by ID name.**Universal Selectors**: Selects all HTML elements on a page.**Attribute Selectors**: Matches elements based on the prescence or value of a given attribute. (i.e. a[title] will match all a elements with a title attribute)
/* Type selector */
div {
background-color: #000000;
}/* Class selector */
.active {
color: #ffffff;
}/* ID selector */
list-1 {
border: 1px solid gray;
}/* Universal selector */
* {
padding: 10px;
}/* Attribute selector */
a[title] {
font-size: 2em;
}
Class Selectors
- Used to select all elements of a certain class denoted with a
.[class name] - You can assign multiple classes to a DOM element by separating them with a space.
Compound Class Selectors
- To get around accidentally selecting elements with multiple classes beyond what we want to grab we can chain dots.
- TO use a compound class selector just append the classes together when referencing them in the CSS.
- i.e. .box.yellow will select only the first element.
- KEEP IN MIND that if you do include a space it will make the selector into a descendant selector.
h1#heading,
h2.subheading {
font-style: italic;
}
- When we want to target all
h1tags with the id ofheading.
CSS Combinators
- CSS Combinators are used to combine other selectors into more complex or targeted selectors — they are very powerful!
- Be careful not to use too many of them as they will make your CSS far too complex.
**Descendant Selectors**- Separated by a space.
- Selects all descendants of a parent container.
**Direct Child Selectors**- Indicated with a
>. - Different from descendants because it only affects the direct children of an element.
.menu > .is-active { background-color: #ffe0b2; }<body> <div class="menu"> <div class="is-active">Belka</div> <div> <div class="is-active">Strelka</div> </div> </div> </body> <div class="is-active"> Laika </div> </body>- Belka would be the only element selected.
**Adjacent Sibling Selectors**- Uses the
+symbol. - Used for elements that directly follow one another and who both have the same parent.
h1 + h2 { font-style: italic; } <h1>Big header</h1> <h2>This one is styled because it is directly adjacent to the H1</h2> <h2>This one is NOT styled because there is no H1 right before it</h2>
Pseudo-Classes
**Pseudo-Class**: Specifies a special state of the seleted element(s) and does not refer to any elements or attributes contained in the DOM.- Format is a
Selector:Pseudo-Class NameorA:B a:hover { font-family: "Roboto Condensed", sans-serif; color: #4fc3f7; text-decoration: none; border-bottom: 2px solid #4fc3f7; }- Some common pseudo-classes that are frequently used are:
**active**: ‘push down’, when ele are activated.**checked**: applies to things like radio buttons or checkbox inputs.**disabled**: any disabled element.**first-child**: first element in a group of children/siblings.**focus**: elements that have current focus.**hover**: elements that have cursor hovering over it.**invalid**: any form elements in an invalid state from client-side form validation.**last-child**: last element in a group of children/siblings.**not(selector)**: elements that do not match the provided selector.**required**: form elements that are required.**valid**: form elements in a valid state.**visited**: anchor tags of whih the user has already been to the URL that the href points to.
**Pseudo-Selectors**
- Used to create pseudo-elements as children of the elements to which the property applies.
::after::before
This is the first paragraph
This is the second paragraph
This is the third paragraph
- Will add some blue smiley faces before the p tag elements.
CSS Rules
**CSS Rule**: Collection of single or compound selectors, a curly brace, zero or more properties**CSS Rule Specificity**: Sometimes CSS rules will contain multiple elements and may have overlapping properties rules for those same elements – there is an algorithm in CSS that calculates which rule takes precedence.**The Four Number Calculation**: listed in increasing order of importance.
Who has the most IDs? If no one, continue.
Who has the most classes? If no one, continue.
Who has the most tags? If no one, continue.
Last Read in the browser wins.

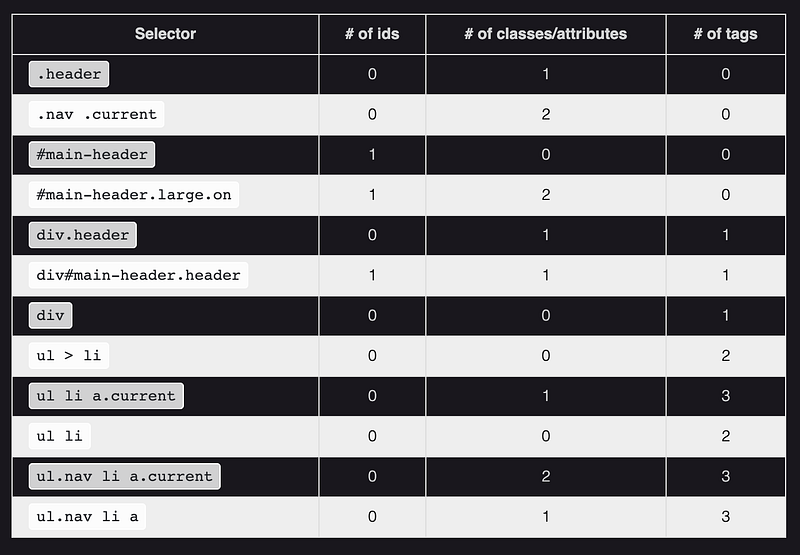


- Coming back to our example where all the CSS Rules have tied, the last step 4 wins out so our element will have a
purple border.
CSS: Type, Properties, and Imports
Typography
**font-family**: change the font.

- Remember that not all computers have the same fonts on them.
- You can import web fonts via an api by using
@import url('https://fonts.googleapis.com/css2?family=Liu+Jian+Mao+Cao&display=swap');and pasting it st the top of your CSS file.- And then reference it in your font-family.
**font-size**: Changes the size of your font.- Keep in mind the two kind of units CSS uses:
**Absolute**:**Pixels**, Points, Inches, Centimeters.**Relative**: Em, Rem.- Em: Calulating the size relative to the previous div (bubbles down)
- Rem: Calulates relative to the parent element always.
**font-style**: Used to set a font to italics.**font-weight**: Used to make a font bold.**text-align**: Used to align your text to the left, center, or right.**text-decoration**: Use to put lines above, through, or under text. Lines can be solid, dashed, or wavy!**text-transform**: Used to set text to all lowercase, uppercase, or capitalize all words.
Background-Images
- You can use the background-image property to set a background image for an element.
CSS: Colors, Borders, and Shadows
Colors
- You can set colors in CSS in three popular ways: by name, by hexadecimal RGB value, and by their decimal RGB value.
- rgba() is used to make an rbg value more transparent, the
ais used to specify thealpha channel. - Color : Property used to change the color of text.
- Background-Color : Property to change the backgrounf color of an element.
Borders
- Borders take three values: The width of the border, the style (i.e. solid, dotted, dashed), color of the border.
Shadows
- There are two kinds of shadows in CSS:
**box shadows**and**text shadows**. - Box refers to HTML elements.
- Text refers to text.
- Shadows take values such as, the horizontal & vertical offsets of the shadow, the blur radius of the shadow, the spread radius, and of course the colors.
The Box Model
Box Model : A concept that basically boils down that every DOM element has a box around it.
Imagine a gift, inside is the gift, wrapped in foam all around (padding), and the giftbox outside of it (border) and then a wrapping paper on the giftbox (margin).- For items that are using block as it’s display, the browser will follow these rules to layout the element: – The box fills 100% of the available container space. – Every new box takes on a new line/row. – Width and Height properties are respected. – Padding, Margin, and Border will push other elements away from the box. – Certain elements have block as their default display, such as: divs, headers, and paragraphs.- For items that are using inline as it’s display, the browser will follow these rules to layout the element: – Each box appears in a single line until it fills up the space. – Width and height are not respected. – Padding, Margin, and Border are applied but they do not push other elements away from the box. – Certain elements have inline as their default display, such as: span tags, anchors, and images.
Standard Box Model vs Border-Box– As per the standard Box Model, the width and height pertains to the content of the box and excludes any additional padding, borders, and margins.
This bothered many programmers so they created the border box to include the calculation of the entire box’s height and width.
Inline-Block– Inline-block uses the best features of both block and inline. – Elements still get laid out left to right. – Layout takes into account specified width and height.
Padding– Padding applies padding to every side of a box. It is shorthand for four padding properties in this order: padding-top, padding-right, padding-bottom, padding-left (clockwise!)
Border– Border applies a border on all sides of an element. It takes three values in this order: border-width, border-style, border-color. – All three properties can be broken down in the four sides clockwise: top, right, bottom, left.
Margin– Margin sets margins on every side of an element. It takes four values in this order: margin-top, margin-right, margin-bottom, margin-left. – You can use margin: 0 auto to center an element.
Positioning
- The
positionproperty allows us to set the position of elements on a page and is an integral part of creatnig a Web page layout. - It accepts five values:
static,relative,absolute,fixed,sticky. - Every property (minus
static) is used with:top,right,bottom, andleftto position an element on a page.
Static Positioning
- The default position value of page elements.
- Most likely will not use static that much.
Relative Positioning
- Remains in it’s original position in the page flow.
- It is positioned RELATIVE to the it’s ORIGINAL PLACE on the page flow.
- Creates a stacking context : overlapping elements whose order can be set by the z-index property.
pink-box {
background-color: #ff69b4;
bottom: 0;
left: -20px;
position: relative;
right: 0;
top: 0;
}


Absolute Positioning
- Absolute elements are removed from the normal page flow and other elements around it act like it’s not there. (how we can easily achieve some layering)
- Here are some examples to illustration absolute positioning:
.container {
background-color: #2b2d2f;
position: relative;
}#pink-box {
position: absolute;
top: 60px;
}


- Note that the container ele has a relative positioning — this is so that any changes made to the absolute positioned children will be positioned from it’s top-left corner.
- Note that because we removed the pink from the normal page flow, the container has now shifted the blue box to where the pink box should have been — which is why it is now layered beneath the pink.
.container {
background-color: #2b2d2f;
position: relative;
}#pink-box {
position: absolute;
top: 60px;
}#blue-box {
position: absolute;
}


- As you can see here, since we have also taken the blue box out of the normal page flow by declaring it as absoutely positioned it now overlaps over the pink box.
.container {
background-color: #2b2d2f;
position: relative;
}#pink-box {
background-color: #ff69b4;
bottom: 60px;
position: absolute;
}


- Example where the absolute element has it’s bottom property modified.
.container {
background-color: #2b2d2f;
}#pink-box {
background-color: #ff69b4;
bottom: 60px;
position: absolute;
}


- If we removed the container’s relative position. Our absolute unit would look for the nearest parent which would be the document itself.
Fixed Positioning
- Another positioning that removes it’s element from the page flow, and automatically positions it’s parent as the HTML doc itself.
- Fixed also uses top, right, bottom, and left.
- Useful for things like nav bars or other features we want to keep visible as the user scrolls.
Sticky Positioning
- Remains in it’s original position in the page flow, and it is positioned relative to it’s closest block-level ancestor and any scrolling ancestors.
- Behaves like a relatively positioned element until the point at which you would normally scroll past it’s viewport — then it sticks!
- It is positioned with top, right, bottom, and left.
- A good example are headers in a scrollable list.


Flexible Box Model
- Flexbox is a CSS module that provides a convenient way for us to display items inside a flexible container so that the layout is responsive.
- Float was used back in the day to display position of elements in a container.
- A very inconvenient aspect of float is the need to clear the float.
- To ‘clear’ a float we need to set up a ghost div to properly align — this is already sounds so inefficient.
Using Flexbox
- Flexbox automatically resizes a container element to fit the viewport size without needing to use breakpoints.
- Flexbox layout applies styles to the parent element, and it’s children.
.container {
display: flex; /*sets display to use flex*/
flex-wrap: wrap; /*bc flex tries to fit everything into one line, use wrap to have the elements wrap to the next line*/
flex-direction: row; /*lets us create either rows or columns*/
}
**flex-flow**can be used to combine wrap and direction.**justify-content**used to define the alignment of flex items along the main axis.**align-items**used to define the alignment on the Y-axis.**align-content**redistributes extra space on the cross axis.- By default, flex items will appear in the order they are added to the DOM, but we can use the
orderproperty to change that. - Some other properties we can use on flex items are:
flex-grow: dictates amount of avail. space the item should take up.flex-shrink: defines the ability for a flex item to shrink.flex-basis: Default size of an element before the remaining space is distributed.flex: shorthand for grow, shrink and basis.align-self: Overrides default alignment in the container.
Grid Layout
- CSS Grid is a 2d layout system that let’s use create a grid with columns and rows purely using Vanilla CSS. (flex is one dimensional)
Bootstrap vs CSS Grid
- Bootstrap was a front-end library commonly used to create grid layouts but now CSS grid provides greater flexibility and control.
- Grid applies style to a parent container and it’s child elements.
.grid-container {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: auto;
grid-template-areas:
"header header header"
"main . sidebar"
"footer footer footer"; grid-column-gap: 20px;
grid-row-gap: 30px;
justify-items: stretch;
align-items: stretch;
justify-content: stretch;
align-content: stretch;
}.item-1 {
grid-area: header;
}
.item-2 {
grid-area: main;
}
.item-3 {
grid-area: sidebar;
}
.item-4 {
grid-area: footer;
}
- Columns and Rows can be defined with: pixels, percentages, auto, named grid lines, using
repeat, fractions. **Grid Template Areas**gives us a handy way to map out and visualize areas of the grid layout.- Combine areas with templates to define how much space an area should take up.
**Grid Gaps**can be used to create ‘gutters’ between grid item.s- The way we have defined our grid with
grid-templatesandareasare considered explicit. - We can also
**implicitly**define grids.
.grid-container {
display: grid;
grid-template-columns: 100px 100px 100px 100px;
grid-template-rows: 50px 50px 50px;
grid-auto-columns: 100px;
grid-auto-rows: 50px;
}
- Any grid items that aren’t explicity placed are automatically placed or re-flowed
Spanning Columns & Rows
- We can use the following properties to take up a specified num of cols and rows.
**grid-column-start****grid-column-end****grid-row-start****grid-row-end**- All four properties can take any of the following values: the line number, span #, span name, auto.
.item-1 {
grid-row-start: row2-start; /* Item starts at row line named "row2-start" */
grid-row-end: 5; /* Item ends at row line 5 */
grid-column-start: 1; /* Item starts at column line 1 */
grid-column-end: three; /* Item ends at column line named "three" */
}.item-2 {
grid-row-start: 1; /* Item starts at row line 1 */
grid-row-end: span 2; /* Item spans two rows and ends at row line 3 */
grid-column-start: 3; /* Item starts at column line 3 */
grid-column-end: span col5-start; /* Item spans and ends at line named "col5-start" */
}
Grid Areas
- We use the grid areas in conjunction with grid-container property to define sections of the layout.
- We can then assign named sections to individual element’s css rules.
Justify & Align Self
- Justify items and Align Items can be used to align all grid items at once.
- Justify Self is used to align self on the row.
- It can take four values: start, end, center, stretch.
- Align Self is used to align self on the column.
- It can take four values: start, end, center, stretch.
CSS Hover Effect and Handling
Overflow
css .btn { background-color: #00bfff; color: #ffffff; border-radius: 10px; padding: 1.5rem; }
.btn--active:hover { cursor: pointer; transform: translateY(-0.25rem);
/* Moves our button up/down on the Y axis */ }
The Pseudo Class Selector **hover** activates when the cursor goes over the selected element.
Content Overflow– You can apply an overflow content property to an element if it’s inner contents are spilling over.
There are three members in the overflow family: — **overflow-x** : Apply horizontally. – **overflow-y** : Apply vertically. – **overflow** : Apply both directions.
Transitions
- Transitions provide a way to control animation speed when changing CSS properties.
- Implicit Transitions : Animations that involve transitioning between two states.
Defining Transitions
**transition-property**: specifies the name of the CSS property to apply the transition.**transition-duration**: during of the transition.**transition-delay**: time before the transition should start.
Examples :
delay {
font-size: 14px;
transition-property: font-size;
transition-duration: 4s;
transition-delay: 2s;
}#delay:hover {
font-size: 36px;
}


- After a delay of two seconds, a four second transition begins where the font size goes from 36px to 14px.
.box {
border-style: solid;
border-width: 1px;
display: block;
width: 100px;
height: 100px;
background-color: #0000ff;
transition: width 2s, height 2s, background-color 2s, transform 2s;
}.box:hover {
background-color: #ffcccc;
width: 200px;
height: 200px;
transform: rotate(180deg);
}


- When the mouse hovers over a box, it spins due to the rotate transform. Width and height change and also the bg color.
BEM Guidelines
- BEM was created as a guideline to solve the issue of loose standards around CSS naming conventions.
- BEM stands for
block,element,modifier. - Block
- A standalone entity that is meaningful on it’s own.
- Can be nested and interact with one another.
- Holistic entities without DOM rep can be blocks.
- May consist latin letters, digits, and dashes.
- Any DOM node can be a block if it accepts a class name.
- Element
- Part of a block and has no standalone meaning.
- Any element that is semantically tied to a block.
- May consist latin letters, digits, and dashes.
- Formed by using two underscores after it’s block name.
- Any DOM node within a block can be an element.
- Element classes should be used independently.
- Modifier
- A flag on blocks or elements. Use them to change appearance, behavior or state.
- Extra class name to add onto blocks or elements.
- Add mods only to the elements they modify.
- Modifier names may consist of Latin letters, digits, dashes and underscores.
- Written with two dashes.
BEM Example
/\* block selector \*/ .form { }/\* block modifier selector \*/ .form--theme-xmas { }/\* block modifier selector \*/ .form--simple { }/\* element selector \*/ .form\_\_input { }/\* element selector \*/ .form\_\_submit { }/\* element modifier selector \*/ .form\_\_submit--disabled { }https://gist.github.com/bgoonz/772d898734b648e7a4f3aa47575bc3ef
If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:

If you follow this guide to a tee… you will install PostgreSQL itself on your Windows installation. Then, you will install psql in your Ubuntu installation. Then you will also install Postbird, a cross-platform graphical user interface that makes working with SQL and PostgreSQL ‘allegedly’ …(personally I prefer to just use the command line but PG Admin makes for an immeasurably more complicated tutorial than postbird)… better than just using the command line tool **psql**.
Important Distinction: PSQL is the frontend interface for PostgreSQL … they are not synonymous!
Postgres, is a free and open-source relational database management system (RDBMS)
PSQL:
The primary front-end for PostgreSQL is the **psql** command-line program, which can be used to enter SQL queries directly, or execute them from a file.
In addition, psql provides a number of meta-commands and various shell-like features to facilitate writing scripts and automating a wide variety of tasks; for example tab completion of object names and SQL syntax.
pgAdmin:
The pgAdmin package is a free and open-source graphical user interface (GUI) administration tool for PostgreSQL.
When you read “installation”, that means the actual OS that’s running on your machine. So, you have a Windows installation, Windows 10, that’s running when you boot your computer. Then, when you start the Ubuntu installation, it’s as if there’s a completely separate computer running inside your computer. It’s like having two completely different laptops.
Other Noteworthy Distinctions:

Installing PostgreSQL 12
To install PostgreSQL 12, you need to download the installer from the Internet. PostgreSQL’s commercial company, Enterprise DB, offers installers for PostgreSQL for every major platform.
Open https://www.enterprisedb.com/downloads/postgres-postgresql-downloads. Click the link for PostgreSQL 12 for Windows x86-64.
Once that installer downloads, run it. You need to go through the normal steps of installing software.
- Yes, Windows, let the installer make changes to my device.
- Thanks for the welcome. Next.
- Yeah, that’s a good place to install it. Next.
- I don’t want that pgAdmin nor the Stack Builder things. Uncheck. Uncheck. Next.
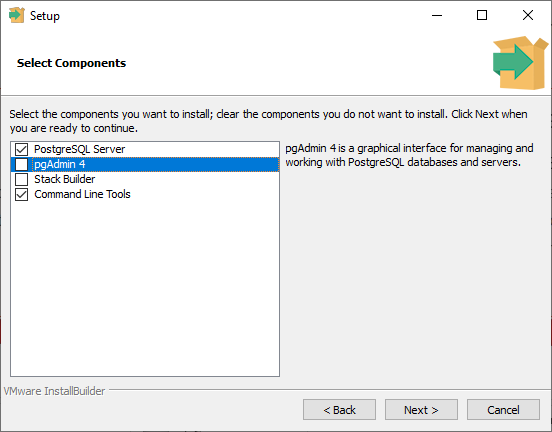
- Also, great looking directory. Thanks. Next.
Oooh! A password! I’ll enter ****. I sure won’t forget that because, if I do, I’ll have to uninstall and reinstall PostgreSQL and lose all of my hard work. Seriously, write down this password or use one you will not forget!!!!!!!!!!!!!!!
I REALLY CANNOT STRESS THE ABOVE POINT ENOUGH… Experience is a great teacher but in this case … it’s not worth it.
- Sure. 5432. Good to go. Next.
- Not even sure what that means. Default! Next.
- Yep. Looks good. Next.
Insert pop culture reference to pass the time
Installing PostgreSQL Client Tools on Ubuntu
Now, to install the PostgreSQL Client tools for Ubuntu. You need to do this so that the Node.js (and later Python) programs running on your Ubuntu installation can access the PostgreSQL server running on your Windows installation. You need to tell apt, the package manager, that you want it to go find the PostgreSQL 12 client tools from PostgreSQL itself rather than the common package repositories. You do that by issuing the following two commands. Copy and paste them one at a time into your shell. (If your Ubuntu shell isn’t running, start one.)
Pro-tip: Copy those commands because you’re not going to type them, right? After you copy one of them, you can just right-click on the Ubuntu shell. That should paste them in there for you.
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
If prompted for your password, type it.
echo "deb http://apt.postgresql.org/pub/repos/apt/ `lsb_release -cs`-pgdg main" | sudo tee /etc/apt/sources.list.d/pgdg.list
The last line of output of those two commands running should read “OK”. If it does not, try copying and pasting them one at a time.
Now that you’ve registered the PostgreSQL repositories as a source to look for PostgreSQL, you need to update the apt registry. You should do this before you install any software on Ubuntu.
sudo apt update
Once that’s finished running, the new entries for PostgreSQL 12 should be in the repository. Now, you can install them with the following command.
sudo apt install postgresql-client-12 postgresql-common
If it asks you if you want to install them, please tell it “Y”.
Test that it installed by typing psql --version. You should see it print out information about the version of the installed tools. If it tells you that it can’t find the command, try these instructions over.
Configuring the client tools
Since you’re going to be accessing the PosgreSQL installation from your Ubuntu installation on your Windows installation, you’re going to have to type that you want to access it over and over, which means extra typing. To prevent you from having to do this, you can customize your shell to always add the extra commands for you.
This assumes you’re still using Bash. If you changed the shell that your Ubuntu installation uses, please follow that shell’s directions for adding an alias to its startup file.
Make sure you’re in your Ubuntu home directory. You can do that by typing cd and hitting enter. Use ls to find out if you have a .bashrc file. Type ls .bashrc. If it shows you that one exists, that’s the one you will add the alias to. If it tells you that there is no file named that, then type ls .profile. If it shows you that one exists, that’s the one you will add the alias to. If it shows you that it does not exist, then use the file name .bashrc in the following section.
Now that you know which profile file to use, type code «profile file name» where “profile file name” is the name of the file you determined from the last section. Once Visual Studio Code starts up with your file, at the end of it (or if you’ve already added aliases, in that section), type the following.
alias psql="psql -h localhost"
When you run psql from the command line, it will now always add the part about wanting to connect to localhost every time. You would have to type that each time, otherwise.
To make sure that you set that up correctly, type psql -U postgres postgres. This tells the psql client that you want to connect as the user “postgres” (-U postgres) to the database postgres (postgres at the end), which is the default database created when PostgreSQL is installed. It will prompt you for a password. Type the password that you used when you installed PostgrSQL, earlier. If the alias works correctly and you type the correct password, then you should see something like the following output.
psql (12.2 (Ubuntu 12.2-2.pgdg18.04+1))
Type "help" for help.
postgres=#
Type \q and hit Enter to exit the PostgreSQL client tool.
Now, you will add a user for your Ubuntu identity so that you don’t have to specify it all the time. Then, you will create a file that PostgreSQL will use to automatically send your password every time.
Copy and paste the following into your Ubuntu shell. Think of a password that you want to use for your user. Replace the password in the single quotes in the command with the password that you want. It has to be a non-empty string. PostgreSQL doesn’t like it when it’s not.
psql -U postgres -c "CREATE USER `whoami` WITH PASSWORD 'password' SUPERUSER"
It should prompt you for a password. Type the password that you created when you installed PostgreSQL. Once you type the correct password, you should see “CREATE ROLE”.
Now you will create your PostgreSQL password file. Type the following into your Ubuntu shell to open Visual Studio Code and create a new file.
code ~/.pgpass
In that file, you will add this line, which tells it that on localhost for port 5432 (where PostgreSQL is running), for all databases (*), use your Ubuntu user name and the password that you just created for that user with the **psql** command you just typed. (If you have forgotten your Ubuntu user name, type whoami on the command line.) Your entry in the file should have this format.
localhost:5432:*:«your Ubuntu user name»:«the password you just used»
Once you have that information in the file, save it, and close Visual Studio Code.
The last step you have to take is change the permission on that file so that it is only readable by your user. PostgreSQL will ignore it if just anyone can read and write to it. This is for your security. Change the file permissions so only you can read and write to it. You did this once upon a time. Here’s the command.
chmod go-rw ~/.pgpass
You can confirm that only you have read/write permission by typing ls -al ~/.pgpass. That should return output that looks like this, with your Ubuntu user name instead of “web-dev-hub”.
-rw------- 1 web-dev-hub web-dev-hub 37 Mar 28 21:20 /home/web-dev-hub/.pgpass
Now, try connecting to PostreSQL by typing psql postgres. Because you added the alias to your startup script, and because you created your .pgpass file, it should now connect without prompting you for any credentials! Type \q and press Enter to exit the PostgreSQL command line client.
Installing Postbird
Head over to the Postbird releases page on GitHub. Click the installer for Windows which you can recognize because it’s the only file in the list that ends with “.exe”.
After that installer downloads, run it. You will get a warning from Windows that this is from an unidentified developer. If you don’t want to install this, find a PostgreSQL GUI client that you do trust and install it or do everything from the command line.
You should get used to seeing this because many open-source applications aren’t signed with the Microsoft Store for monetary and philosophical reasons.
Otherwise, if you trust Paxa like web-dev-hub and tens of thousands of other developers do, then click the link that reads “More info” and the “Run anyway” button.
When it’s done installing, it will launch itself. Test it out by typing the “postgres” into the “Username” field and the password from your installation in the “Password” field. Click the Connect button. It should properly connect to the running
You can close it for now. It also installed an icon on your desktop. You can launch it from there or your Start Menu at any time.
Now.. if you still have some gas in the tank… let’s put our new tools to work:
The node-postgres
The node-postgres is a collection of Node.js modules for interfacing with the PostgreSQL database. It has support for callbacks, promises, async/await, connection pooling, prepared statements, cursors, and streaming results.
In our examples we also use the Ramda library. See Ramda tutorial for more information.
Setting up node-postgres
First, we install node-postgres.
$ node -v
v14.2
$ npm init -y
We initiate a new Node application.
npm i pg
We install node-postgres with nmp i pg.
npm i ramda
In addition, we install Ramda for beautiful work with data.
cars.sql
DROP TABLE IF EXISTS cars;
CREATE TABLE cars(id SERIAL PRIMARY KEY, name VARCHAR(255), price INT);
INSERT INTO cars(name, price) VALUES(‘Audi’, 52642);
INSERT INTO cars(name, price) VALUES(‘Mercedes’, 57127);
INSERT INTO cars(name, price) VALUES(‘Skoda’, 9000);
INSERT INTO cars(name, price) VALUES(‘Volvo’, 29000);
INSERT INTO cars(name, price) VALUES(‘Bentley’, 350000);
INSERT INTO cars(name, price) VALUES(‘Citroen’, 21000);
INSERT INTO cars(name, price) VALUES(‘Hummer’, 41400);
INSERT INTO cars(name, price) VALUES(‘Volkswagen’, 21600);
In some of the examples, we use this cars table.
The node-postgres first example
In the first example, we connect to the PostgreSQL database and return a simple SELECT query result.
first.js
const pg = require(‘pg’);
const R = require(‘ramda’);
const cs = ‘postgres://postgres:s$cret@localhost:5432/ydb’;
const client = new pg.Client(cs);
client.connect();
client.query(‘SELECT 1 + 4’).then(res => {
const result = R.head(R.values(R.head(res.rows)))
console.log(result)
}).finally(() => client.end());
The example connects to the database and issues a SELECT statement.
const pg = require(‘pg’);
const R = require(‘ramda’);
We include the pg and ramda modules.
const cs = ‘postgres://postgres:s$cret@localhost:5432/ydb’;
This is the PostgreSQL connection string. It is used to build a connection to the database.
const client = new pg.Client(cs);
client.connect();
A client is created. We connect to the database with connect().
client.query(‘SELECT 1 + 4’).then(res => {
const result = R.head(R.values(R.head(res.rows)));
console.log(result);
}).finally(() => client.end());
We issue a simple SELECT query. We get the result and output it to the console. The res.rows is an array of objects; we use Ramda to get the returned scalar value. In the end, we close the connection with end().
node first.js
5
This is the output.
The node-postgres column names
In the following example, we get the columns names of a database.
column_names.js
const pg = require(‘pg’);
const cs = ‘postgres://postgres:s$cret@localhost:5432/ydb’;
const client = new pg.Client(cs);
client.connect();
client.query(‘SELECT * FROM cars’).then(res => {
const fields = res.fields.map(field => field.name);
console.log(fields);
}).catch(err => {
console.log(err.stack);
}).finally(() => {
client.end()
});
The column names are retrieved with res.fields attribute. We also use the catch clause to output potential errors.
node columnnames.js
‘id’, ‘name’, ‘price’′_id′,′name′,′price′
The output shows three column names of the cars table.
Selecting all rows
In the next example, we select all rows from the database table.
all_rows.js
const pg = require(‘pg’);
const R = require(‘ramda’);
const cs = ‘postgres://postgres:s$cret@localhost:5432/ydb’;
const client = new pg.Client(cs);
client.connect();
client.query(‘SELECT * FROM cars’).then(res => {
const data = res.rows;
console.log('all data');
data.forEach(row => {
console.log(\`Id: ${row.id} Name: ${row.name} Price: ${row.price}\`);
})
console.log('Sorted prices:');
const prices = R.pluck('price', R.sortBy(R.prop('price'), data));
console.log(prices);
}).finally(() => {
client.end()
});
TBC…
If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:
EMMET
The a toolkit for web-developers
Introduction
Emmet is a productivity toolkit for web developers that uses expressions to generate HTML snippets.
Installation
Normally, installation for Emmet should be a straight-forward process from the package-manager, as most of the modern text editors support Emmet.
Usage
You can use Emmet in two ways:
- Tab Expand Way: Type your emmet code and press
Tabkey - Interactive Method: Press
alt + ctrl + Enterand start typing your expressions. This should automatically generate HTML snippets on the fly.
This cheatsheet will assume that you press **Tab** after each expressions.
HTML
Generating HTML 5 DOCTYPE
html:5
Will generate
Child items
Child items are created using >
ul>li>p
Sibling Items
Sibling items are created using +
html>head+body
Multiplication
Items can be multiplied by *
ul>li*5
Grouping
Items can be grouped together using ()
table>(tr>th*5)+tr>t*5
Class and ID
Class and Id in Emmet can be done using . and #
div.heading
div#heading
ID and Class can also be combined together
div#heading.center
Adding Content inside tags
Contents inside tags can be added using {}
h1{Emmet is awesome}+h2{Every front end developers should use this}+p{This is paragraph}*2
Emmet is awesome
Every front end developers should use this
This is paragraph
This is paragraph
Attributes inside HTML tags
Attributes can be added using []
a[href=https://?google.com data-toggle=something target=_blank]
Numbering
Numbering can be done using $
You can use this inside tag or contents.
h${This is so awesome $}*6
This is so awesome 1
This is so awesome 2
This is so awesome 3
This is so awesome 4
This is so awesome 5
This is so awesome 6
Use @- to reverse the Numbering
img[src=image$$@-.jpg]*5





To start the numbering from specific number, use this way
img[src=emmet$@100.jpg]*5





Tips
- Use
:to expand known abbreviations
input:date
form:post
link:css
- Building Navbar
.navbar>ul>li*3>a[href=#]{Item $@-}
CSS
Emmet works surprisingly well with css as well.
f:l
float: left;
You can also use any options n/r/l
pos:a
position: absolute;
Also use any options, pos:a/r/f
d:n/b/f/i/ib
d:ib
display: inline-block;
- You can use
mfor margin andpfor padding followed by direction
mr -> margin-right
pr -> padding-right
@fwill result in
@font-face {
font-family:;
src:url();
}
You can also use these shorthands

If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:
HEAD^ # 1 commit before head
HEAD^^ # 2 commits before head
HEAD~5 # 5 commits before head
Branches
# create a new branch
git checkout -b $branchname
git push origin $branchname --set-upstream
# get a remote branch
git fetch origin
git checkout --track origin/$branchname
# delete local remote-tracking branches (lol)
git remote prune origin
# list merged branches
git branch -a --merged
# delete remote branch
git push origin :$branchname
# go back to previous branch
git checkout -
Collaboration
# Rebase your changes on top of the remote master
git pull --rebase upstream master
# Squash multiple commits into one for a cleaner git log
# (on the following screen change the word pick to either 'f' or 's')
git rebase -i $commit_ref
Submodules
# Import .gitmodules
git submodule init
# Clone missing submodules, and checkout commits
git submodule update --init --recursive
# Update remote URLs in .gitmodules
# (Use when you changed remotes in submodules)
git submodule sync
Diff
Diff with stats
git diff --stat
app/a.txt | 2 +-
app/b.txt | 8 ++----
2 files changed, 10 insertions(+), 84 deletions(-)
Just filenames
git diff --summary
Log options
--oneline
e11e9f9 Commit message here
--decorate
shows "(origin/master)"
--graph
shows graph lines
--date=relative
"2 hours ago"
Misc
Cherry pick
git rebase 76acada^
# get current sha1 (?)
git show-ref HEAD -s
# show single commit info
git log -1 f5a960b5
# Go back up to root directory
cd "$(git rev-parse --show-top-level)"
Short log
$ git shortlog
$ git shortlog HEAD~20.. # last 20 commits
James Dean (1):
Commit here
Commit there
Frank Sinatra (5):
Another commit
This other commit
Bisect
git bisect start HEAD HEAD~6
git bisect run npm test
git checkout refs/bisect/bad # this is where it screwed up
git bisect reset
Manual bisection
git bisect start
git bisect good # current version is good
git checkout HEAD~8
npm test # see if it's good
git bisect bad # current version is bad
git bisect reset # abort
Searching
git log --grep="fixes things" # search in commit messages
git log -S"window.alert" # search in code
git log -G"foo.*" # search in code (regex)
GPG Signing
git config set user.signingkey
git commit -m "Implement feature Y" --gpg-sign # Or -S, GPG signs commit
git config set commit.gpgsign true # Sign commits by default
git commit -m "Implement feature Y" --no-gpg-sign # Do not sign
---
Refs
HEAD^ # 1 commit before head
HEAD^^ # 2 commits before head
HEAD~5 # 5 commits before head
Branches
# create a new branch
git checkout -b $branchname
git push origin $branchname --set-upstream
# get a remote branch
git fetch origin
git checkout --track origin/$branchname
# delete local remote-tracking branches (lol)
git remote prune origin
# list merged branches
git branch -a --merged
# delete remote branch
git push origin :$branchname
# go back to previous branch
git checkout -
Collaboration
# Rebase your changes on top of the remote master
git pull --rebase upstream master
# Squash multiple commits into one for a cleaner git log
# (on the following screen change the word pick to either 'f' or 's')
git rebase -i $commit_ref
Submodules
# Import .gitmodules
git submodule init
# Clone missing submodules, and checkout commits
git submodule update --init --recursive
# Update remote URLs in .gitmodules
# (Use when you changed remotes in submodules)
git submodule sync
Diff
Diff with stats
git diff --stat
app/a.txt | 2 +-
app/b.txt | 8 ++----
2 files changed, 10 insertions(+), 84 deletions(-)
Just filenames
git diff --summary
Log options
--oneline
e11e9f9 Commit message here
--decorate
shows "(origin/master)"
--graph
shows graph lines
--date=relative
"2 hours ago"
Miscellaneous
Cherry pick
git rebase 76acada^
# get current sha1 (?)
git show-ref HEAD -s
# show single commit info
git log -1 f5a960b5
# Go back up to root directory
cd "$(git rev-parse --show-top-level)"
Short log
$ git shortlog
$ git shortlog HEAD~20.. # last 20 commits
James Dean (1):
Commit here
Commit there
Frank Sinatra (5):
Another commit
This other commit
Bisect
git bisect start HEAD HEAD~6
git bisect run npm test
git checkout refs/bisect/bad # this is where it screwed up
git bisect reset
Manual bisection
git bisect start
git bisect good # current version is good
git checkout HEAD~8
npm test # see if it's good
git bisect bad # current version is bad
git bisect reset # abort
Searching
git log --grep="fixes things" # search in commit messages
git log -S"window.alert" # search in code
git log -G"foo.*" # search in code (regex)
GPG Signing
git config set user.signingkey
git commit -m "Implement feature Y" --gpg-sign # Or -S, GPG signs commit
git config set commit.gpgsign true # Sign commits by default
git commit -m "Implement feature Y" --no-gpg-sign # Do not sign

If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:
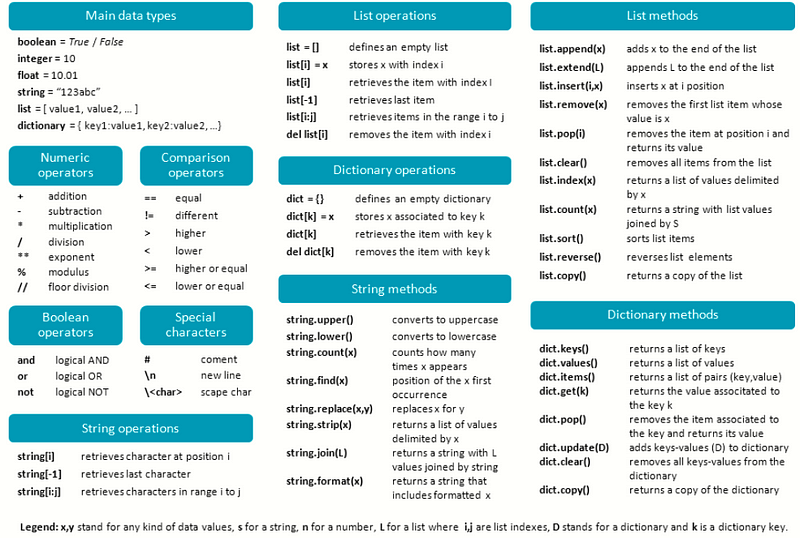
Applications of Tutorial & Cheat Sheet Respectivley (At Bottom Of Tutorial):
Basics
- PEP8 : Python Enhancement Proposals, style-guide for Python.
printis the equivalent ofconsole.log.
‘print() == console.log()’
# is used to make comments in your code.
def foo():
"""
The foo function does many amazing things that you
should not question. Just accept that it exists and
use it with caution.
"""
secretThing()
Python has a built in help function that let’s you see a description of the source code without having to navigate to it… “-SickNasty … Autor Unknown”
Numbers
- Python has three types of numbers:
- Integer
- Positive and Negative Counting Numbers.
No Decimal Point
Created by a literal non-decimal point number … or … with the
_int()_constructor.
print(3) # => 3
print(int(19)) # => 19
print(int()) # => 0
3. Complex Numbers
Consist of a real part and imaginary part.
Boolean is a subtype of integer in Python.
If you came from a background in JavaScript and learned to accept the premise(s) of the following meme…
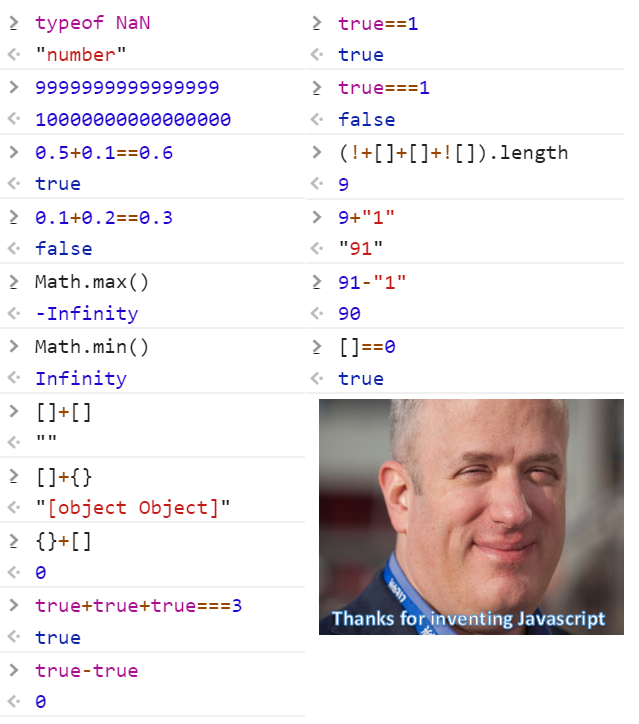
Than I am sure you will find the means to suspend your disbelief.
print(2.24) # => 2.24
print(2.) # => 2.0
print(float()) # => 0.0
print(27e-5) # => 0.00027
KEEP IN MIND:
The
**i**is switched to a**j**in programming.
T*his is because the letter i is common place as the de facto index for any and all enumerable entities so it just makes sense not to compete for name-*space when there’s another 25 letters that don’t get used for every loop under the sun. My most medium apologies to Leonhard Euler.
print(7j) # => 7j
print(5.1+7.7j)) # => 5.1+7.7j
print(complex(3, 5)) # => 3+5j
print(complex(17)) # => 17+0j
print(complex()) # => 0j
- Type Casting : The process of converting one number to another.
# Using Float
print(17) # => 17
print(float(17)) # => 17.0
# Using Int
print(17.0) # => 17.0
print(int(17.0)) # => 17
# Using Str
print(str(17.0) + ' and ' + str(17)) # => 17.0 and 17
The arithmetic operators are the same between JS and Python, with two additions:
- “**” : Double asterisk for exponent.
- “//” : Integer Division.
- There are no spaces between math operations in Python.
- Integer Division gives the other part of the number from Module; it is a way to do round down numbers replacing
**Math.floor()**in JS. - There are no
**++**and**--**in Python, the only shorthand operators are:

Strings
- Python uses both single and double quotes.
- You can escape strings like so
'Jodi asked, "What\'s up, Sam?"' - Multiline strings use triple quotes.
print('''My instructions are very long so to make them
more readable in the code I am putting them on
more than one line. I can even include "quotes"
of any kind because they won't get confused with
the end of the string!''')
Use the **len()** function to get the length of a string.
print(len(“Spaghetti”)) # => 9
Python uses **zero-based indexing**
Python allows negative indexing (thank god!)
print(“Spaghetti”[-1]) # => i
print(“Spaghetti”[-4]) # => e
- Python let’s you use ranges
You can think of this as roughly equivalent to the slice method called on a JavaScript object or string… (mind you that in JS … strings are wrapped in an object (under the hood)… upon which the string methods are actually called. As a immutable privative type by textbook definition, a string literal could not hope to invoke most of it’s methods without violating the state it was bound to on initialization if it were not for this bit of syntactic sugar.)
print(“Spaghetti”[1:4]) # => pag
print(“Spaghetti”[4:-1]) # => hett
print(“Spaghetti”[4:4]) # => (empty string)
- The end range is exclusive just like
slicein JS.
# Shortcut to get from the beginning of a string to a certain index.
print("Spaghetti"[:4]) # => Spag
print("Spaghetti"[:-1]) # => Spaghett
# Shortcut to get from a certain index to the end of a string.
print("Spaghetti"[1:]) # => paghetti
print("Spaghetti"[-4:]) # => etti
- The
indexstring function is the equiv. ofindexOf()in JS
print("Spaghetti".index("h")) # => 4
print("Spaghetti".index("t")) # => 6
- The
countfunction finds out how many times a substring appears in a string… pretty nifty for a hard coded feature of the language.
print("Spaghetti".count("h")) # => 1
print("Spaghetti".count("t")) # => 2
print("Spaghetti".count("s")) # => 0
print('''We choose to go to the moon in this decade and do the other things,
not because they are easy, but because they are hard, because that goal will
serve to organize and measure the best of our energies and skills, because that
challenge is one that we are willing to accept, one we are unwilling to
postpone, and one which we intend to win, and the others, too.
'''.count('the ')) # => 4
- You can use
**+**to concatenate strings, just like in JS. - You can also use “*” to repeat strings or multiply strings.
- Use the
**format()**function to use placeholders in a string to input values later on.
firstname = "Billy"
lastname = "Bob"
print('Your name is {0} {1}'.format(firstname, lastname)) # => Your name is Billy Bob
- Shorthand way to use format function is:
_`print(f'Your name is {firstname} {last_name}')`
Some useful string methods.
- Note that in JS
**join**is used on an Array, in Python it is used on String.

- There are also many handy testing methods.

Variables and Expressions
- Duck-Typing : Programming Style which avoids checking an object’s type to figure out what it can do.
- Duck Typing is the fundamental approach of Python.
- Assignment of a value automatically declares a variable.
a = 7
b = 'Marbles'
print(a) # => 7
print(b) # => Marbles
- You can chain variable assignments to give multiple var names the same value.
Use with caution as this is highly unreadable
count = max = min = 0
print(count) # => 0
print(max) # => 0
print(min) # => 0
The value and type of a variable can be re-assigned at any time.
a = 17
print(a) # => 17
a = 'seventeen'
print(a) # => seventeen
_NaN_does not exist in Python, but you can ‘create’ it like so:**_print(float("nan"))_**- Python replaces
_null_with_none_. **_none_**is an object and can be directly assigned to a variable.
Using none is a convenient way to check to see why an action may not be operating correctly in your program.
Boolean Data Type
- One of the biggest benefits of Python is that it reads more like English than JS does.
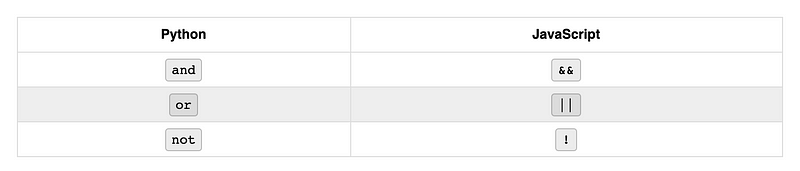
# Logical AND
print(True and True) # => True
print(True and False) # => False
print(False and False) # => False
# Logical OR
print(True or True) # => True
print(True or False) # => True
print(False or False) # => False
# Logical NOT
print(not True) # => False
print(not False and True) # => True
print(not True or False) # => False
- By default, Python considers an object to be true UNLESS it is one of the following:
- Constant
NoneorFalse - Zero of any numeric type.
- Empty Sequence or Collection.
TrueandFalsemust be capitalized
Comparison Operators
- Python uses all the same equality operators as JS.
- In Python, equality operators are processed from left to right.
- Logical operators are processed in this order:
- NOT
- AND
- OR
Just like in JS, you can use
parenthesesto change the inherent order of operations.
Short Circuit : Stopping a program when a
trueorfalsehas been reached.
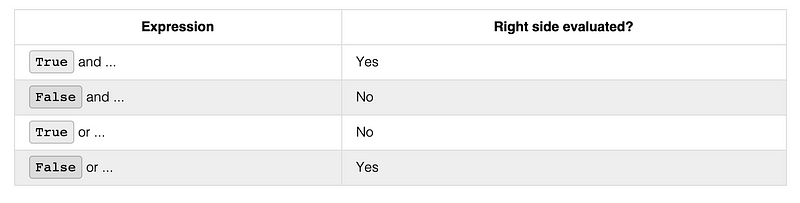
Identity vs Equality
print (2 == '2') # => False
print (2 is '2') # => False
print ("2" == '2') # => True
print ("2" is '2') # => True
# There is a distinction between the number types.
print (2 == 2.0) # => True
print (2 is 2.0) # => False
- In the Python community it is better to use
isandis notover==or!=
If Statements
if name == 'Monica':
print('Hi, Monica.')
if name == 'Monica':
print('Hi, Monica.')
else:
print('Hello, stranger.')
if name == 'Monica':
print('Hi, Monica.')
elif age < 12:
print('You are not Monica, kiddo.')
elif age > 2000:
print('Unlike you, Monica is not an undead, immortal vampire.')
elif age > 100:
print('You are not Monica, grannie.')
Remember the order of
elifstatements matter.
While Statements
spam = 0
while spam < 5:
print('Hello, world.')
spam = spam + 1
Breakstatement also exists in Python.
spam = 0
while True:
print('Hello, world.')
spam = spam + 1
if spam >= 5:
break
- As are
continuestatements
spam = 0
while True:
print('Hello, world.')
spam = spam + 1
if spam < 5:
continue
break
Try/Except Statements
- Python equivalent to
try/catch
a = 321
try:
print(len(a))
except:
print('Silently handle error here')
# Optionally include a correction to the issue
a = str(a)
print(len(a)
a = '321'
try:
print(len(a))
except:
print('Silently handle error here')
# Optionally include a correction to the issue
a = str(a)
print(len(a))
- You can name an error to give the output more specificity.
a = 100
b = 0
try:
c = a / b
except ZeroDivisionError:
c = None
print(c)
- You can also use the
passcommmand to by pass a certain error.
a = 100
b = 0
try:
print(a / b)
except ZeroDivisionError:
pass
- The
passmethod won’t allow you to bypass every single error so you can chain an exception series like so:
a = 100
# b = "5"
try:
print(a / b)
except ZeroDivisionError:
pass
except (TypeError, NameError):
print("ERROR!")
- You can use an
elsestatement to end a chain ofexceptstatements.
# tuple of file names
files = ('one.txt', 'two.txt', 'three.txt')
# simple loop
for filename in files:
try:
open the file in read mode
f = open(filename, 'r')
except OSError:
handle the case where file does not exist or permission is denied
print('cannot open file', filename)
else:
do stuff with the file object (f)
print(filename, 'opened successfully')
print('found', len(f.readlines()), 'lines')
f.close()
finallyis used at the end to clean up all actions under any circumstance.
def divide(x, y):
try:
result = x / y
except ZeroDivisionError:
print("Cannot divide by zero")
else:
print("Result is", result)
finally:
print("Finally...")
- Using duck typing to check to see if some value is able to use a certain method.
# Try a number - nothing will print out
a = 321
if hasattr(a, '__len__'):
print(len(a))
# Try a string - the length will print out (4 in this case)
b = "5555"
if hasattr(b, '__len__'):
print(len(b))
Pass
- Pass Keyword is required to write the JS equivalent of :
if (true) {
}
while (true) {}
if True:
pass
while True:
pass
Functions
- Function definition includes:
- The
**def**keyword - The name of the function
- A list of parameters enclosed in parentheses.
- A colon at the end of the line.
- One tab indentation for the code to run.
- You can use default parameters just like in JS
def greeting(name, saying="Hello"):
print(saying, name)
greeting("Monica")
# Hello Monica
greeting("Barry", "Hey")
# Hey Barry
Keep in mind, default parameters must always come after regular parameters.
# THIS IS BAD CODE AND WILL NOT RUN
def increment(delta=1, value):
return delta + value
- You can specify arguments by name without destructuring in Python.
def greeting(name, saying="Hello"):
print(saying, name)
# name has no default value, so just provide the value
# saying has a default value, so use a keyword argument
greeting("Monica", saying="Hi")
- The
lambdakeyword is used to create anonymous functions and are supposed to beone-liners.
toUpper = lambda s: s.upper()
Notes
Formatted Strings
Remember that in Python join() is called on a string with an array/list passed in as the argument.
Python has a very powerful formatting engine.
format() is also applied directly to strings.
shoppinglist = [‘bread’,’milk’,’eggs’]
print(‘,’.join(shoppinglist))
Comma Thousands Separator
print(‘{:,}’.format(1234567890))
‘1,234,567,890’
Date and Time
d = datetime.datetime(2020, 7, 4, 12, 15, 58)
print(‘{:%Y-%m-%d %H:%M:%S}’.format(d))
‘2020-07-04 12:15:58’
Percentage
points = 190
total = 220
print(‘Correct answers: {:.2%}’.format(points/total))
Correct answers: 86.36%
Data Tables
width=8
print(‘ decimal hex binary’)
print(‘-’*27)
for num in range(1,16):
for base in ‘dXb’:
print(‘{0:{width}{base}}’.format(num, base=base, width=width), end=’ ‘)
print()
Getting Input from the Command Line
Python runs synchronously, all programs and processes will stop when listening for a user input.
The input function shows a prompt to a user and waits for them to type ‘ENTER’.
Scripts vs Programs
Programming Script : A set of code that runs in a linear fashion.
The largest difference between scripts and programs is the level of complexity and purpose. Programs typically have many UI’s.
Python can be used to display html, css, and JS.
It is common to use Python as an API (Application Programming Interface)
Structured Data
Sequence : The most basic data structure in Python where the index determines the order.
List
Tuple
Range
Collections : Unordered data structures, hashable values.
Dictionaries
Sets
Iterable : Generic name for a sequence or collection; any object that can be iterated through.
Can be mutable or immutable.
Built In Data Types
Lists are the python equivalent of arrays.
empty_list = []
departments = [‘HR’,’Development’,’Sales’,’Finance’,’IT’,’Customer Support’]
You can instantiate
specials = list()
Test if a value is in a list.
print(1 in [1, 2, 3]) #> True
print(4 in [1, 2, 3]) #> False
# Tuples : Very similar to lists, but they are immutable
Instantiated with parentheses
time_blocks = (‘AM’,’PM’)
Sometimes instantiated without
colors = ‘red’,’blue’,’green’
numbers = 1, 2, 3
Tuple() built in can be used to convert other data into a tuple
tuple(‘abc’) # returns (‘a’, ‘b’, ‘c’)
tuple([1,2,3]) # returns (1, 2, 3)
# Think of tuples as constant variables.
Ranges : A list of numbers which can’t be changed; often used with for loops.
Declared using one to three parameters.
Start : opt. default 0, first # in sequence.
Stop : required next number past the last number in the sequence.
Step : opt. default 1, difference between each number in the sequence.
range(5) # [0, 1, 2, 3, 4]
range(1,5) # [1, 2, 3, 4]
range(0, 25, 5) # [0, 5, 10, 15, 20]
range(0) # [ ]
for let (i = 0; i < 5; i++)
for let (i = 1; i < 5; i++)
for let (i = 0; i < 25; i+=5)
for let(i = 0; i = 0; i++)
# Keep in mind that stop is not included in the range.
Dictionaries : Mappable collection where a hashable value is used as a key to ref. an object stored in the dictionary.
Mutable.
a = {‘one’:1, ‘two’:2, ‘three’:3}
b = dict(one=1, two=2, three=3)
c = dict([(‘two’, 2), (‘one’, 1), (‘three’, 3)])
# a, b, and c are all equal
Declared with curly braces of the built in dict()
Benefit of dictionaries in Python is that it doesn’t matter how it is defined, if the keys and values are the same the dictionaries are considered equal.
Use the in operator to see if a key exists in a dictionary.
Sets : Unordered collection of distinct objects; objects that need to be hashable.
Always be unique, duplicate items are auto dropped from the set.
Common Uses:
Removing Duplicates
Membership Testing
Mathematical Operators: Intersection, Union, Difference, Symmetric Difference.
Standard Set is mutable, Python has a immutable version called frozenset.
Sets created by putting comma seperated values inside braces:
schoolbag = {‘book’,’paper’,’pencil’,’pencil’,’book’,’book’,’book’,’eraser’}
print(schoolbag)
Also can use set constructor to automatically put it into a set.
letters = set(‘abracadabra’)
print(letters)
Built-In Functions
Functions using iterables
filter(function, iterable) : creates new iterable of the same type which includes each item for which the function returns true.
map(function, iterable) : creates new iterable of the same type which includes the result of calling the function on every item of the iterable.
sorted(iterable, key=None, reverse=False) : creates a new sorted list from the items in the iterable.
Output is always a list
key: opt function which coverts and item to a value to be compared.
reverse: optional boolean.
enumerate(iterable, start=0) : starts with a sequence and converts it to a series of tuples
quarters = [‘First’, ‘Second’, ‘Third’, ‘Fourth’]
print(enumerate(quarters))
print(enumerate(quarters, start=1))
(0, ‘First’), (1, ‘Second’), (2, ‘Third’), (3, ‘Fourth’)
(1, ‘First’), (2, ‘Second’), (3, ‘Third’), (4, ‘Fourth’)
zip(*iterables) : creates a zip object filled with tuples that combine 1 to 1 the items in each provided iterable.
Functions that analyze iterable
len(iterable) : returns the count of the number of items.
max(*args, key=None) : returns the largest of two or more arguments.
max(iterable, key=None) : returns the largest item in the iterable.
key optional function which converts an item to a value to be compared.
min works the same way as max
sum(iterable) : used with a list of numbers to generate the total.
There is a faster way to concatenate an array of strings into one string, so do not use sum for that.
any(iterable) : returns True if any items in the iterable are true.
all(iterable) : returns True is all items in the iterable are true.
Working with dictionaries
dir(dictionary) : returns the list of keys in the dictionary.
Working with sets
Union : The pipe | operator or union(*sets) function can be used to produce a new set which is a combination of all elements in the provided set.
a = {1, 2, 3}
b = {2, 4, 6}
print(a | b) # => {1, 2, 3, 4, 6}
Intersection : The & operator ca be used to produce a new set of only the elements that appear in all sets.
a = {1, 2, 3}
b = {2, 4, 6}
print(a & b) # => {2}
Difference : The — operator can be used to produce a new set of only the elements that appear in the first set and NOT the others.
Symmetric Difference : The ^ operator can be used to produce a new set of only the elements that appear in exactly one set and not in both.
a = {1, 2, 3}
b = {2, 4, 6}
print(a — b) # => {1, 3}
print(b — a) # => {4, 6}
print(a ^ b) # => {1, 3, 4, 6}
**For Statements
In python, there is only one for loop.**
Always Includes:
1. The for keyword
2. A variable name
3. The ‘in’ keyword
4. An iterable of some kid
5. A colon
6. On the next line, an indented block of code called the for clause.
You can use break and continue statements inside for loops as well.
You can use the range function as the iterable for the for loop.
print(‘My name is’)
for i in range(5):
print(‘Carlita Cinco (‘ + str(i) + ‘)’)
total = 0
for num in range(101):
total += num
print(total)
Looping over a list in Python
for c in [‘a’, ‘b’, ‘c’]:
print(c)
lst = [0, 1, 2, 3]
for i in lst:
print(i)
Common technique is to use the len() on a pre-defined list with a for loop to iterate over the indices of the list.
supplies = [‘pens’, ‘staplers’, ‘flame-throwers’, ‘binders’]
for i in range(len(supplies)):
print(‘Index ‘ + str(i) + ‘ in supplies is: ‘ + supplies[i])
You can loop and destructure at the same time.
l = 1, 2], [3, 4], [5, 6
for a, b in l:
print(a, ‘, ‘, b)
Prints 1, 2
Prints 3, 4
Prints 5, 6
You can use values() and keys() to loop over dictionaries.
spam = {‘color’: ‘red’, ‘age’: 42}
for v in spam.values():
print(v)
Prints red
Prints 42
for k in spam.keys():
print(k)
Prints color
Prints age
For loops can also iterate over both keys and values.
Getting tuples
for i in spam.items():
print(i)
Prints (‘color’, ‘red’)
Prints (‘age’, 42)
Destructuring to values
for k, v in spam.items():
print(‘Key: ‘ + k + ‘ Value: ‘ + str(v))
Prints Key: age Value: 42
Prints Key: color Value: red
Looping over string
for c in “abcdefg”:
print(c)
When you order arguments within a function or function call, the args need to occur in a particular order:
formal positional args.
*args
keyword args with default values
**kwargs
def example(arg1, arg2, *args, **kwargs):
pass
def example2(arg1, arg2, *args, kw1=”shark”, kw2=”blowfish”, **kwargs):
pass
Importing in Python
Modules are similar to packages in Node.js
Come in different types:
Built-In,
Third-Party,
Custom.
All loaded using import statements.
Terms
module : Python code in a separate file.
package : Path to a directory that contains modules.
init.py : Default file for a package.
submodule : Another file in a module’s folder.
function : Function in a module.
A module can be any file but it is usually created by placing a special file init.py into a folder. pic
Try to avoid importing with wildcards in Python.
Use multiple lines for clarity when importing.
from urllib.request import (
HTTPDefaultErrorHandler as ErrorHandler,
HTTPRedirectHandler as RedirectHandler,
Request,
pathname2url,
url2pathname,
urlopen,
)
Watching Out for Python 2
Python 3 removed <> and only uses !=
format() was introduced with P3
All strings in P3 are unicode and encoded.
md5 was removed.
ConfigParser was renamed to configparser
sets were killed in favor of set() class.
print was a statement in P2, but is a function in P3.
Topics revisited (in python syntax)
https://gist.github.com/bgoonz/82154f50603f73826c27377ebaa498b5
Cheat Sheet:
https://gist.github.com/bgoonz/282774d28326ff83d8b42ae77ab1fee3
If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:
Python Cheat Sheet:
https://gist.github.com/bgoonz/999163a278b987fe47fb247fd4d66904
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://github.com/bgoonzhttps://github.com/bgoonz
Or Checkout my personal Resource Site:
Fetch
fetch('/data.json') .then(response => response.json()) .then(data => { console.log(data) }) .catch(err => ...)
Response
fetch('/data.json').then(res => { res.text() // response body (=> Promise) res.json() // parse via JSON (=> Promise) res.status //=> 200 res.statusText //=> 'OK' res.redirected //=> false res.ok //=> true res.url //=> 'http://site.com/data.json' res.type //=> 'basic' // ('cors' 'default' 'error' // 'opaque' 'opaqueredirect')
res.headers.get('Content-Type')})
Request options
fetch('/data.json', { method: 'post', body: new FormData(form), // post body body: JSON.stringify(...),
headers: { 'Accept': 'application/json' },
credentials: 'same-origin', // send cookies credentials: 'include', // send cookies, even in CORS
})
Catching errors
fetch('/data.json') .then(checkStatus)
function checkStatus (res) { if (res.status >= 200 && res.status < 300) { return res } else { let err = new Error(res.statusText) err.response = res throw err }}
Non-2xx responses are still successful requests. Use another function to turn them to errors.
Using with node.js
const fetch = require('isomorphic-fetch')
See: isomorphic-fetch (npmjs.com)
If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:
Settings
app.set('x', 'yyy')app.get('x') //=> 'yyy'
app.enable('trust proxy')app.disable('trust proxy')
app.enabled('trust proxy') //=> true
Enviorment
app.get('env')
Config
app.configure('production', function() { app.set...})
Wares
app.use(express.static(__dirname + '/public'))app.use(express.logger())
Helpers
app.locals({ title: "MyApp",})
Request & response
Request
// GET /user/tjreq.path //=> "/user/tj"req.url //=> "/user/tj"req.xhr //=> true|falsereq.method //=> "GET"req.paramsreq.params.name //=> "tj"req.params[0]
// GET /search?q=tobi+ferretreq.query.q // => "tobi ferret"
req.cookies
req.accepted// [ { value: 'application/json', quality: 1, type: 'application', subtype: 'json' },// { value: 'text/html', quality: 0.5, type: 'text',subtype: 'html' } ]
req.is('html')req.is('text/html')
req.headersreq.headers['host']req.headers['user-agent']req.headers['accept-encoding']req.headers['accept-language']
Response
res.redirect('/')res.redirect(301, '/')
res.set('Content-Type', 'text/html')
res.send('hi')res.send(200, 'hi')
res.json({ a: 2 })
Heroku is an web application that makes deploying applications easy for a beginner.
https://gist.github.com/bgoonz/7bf839da876126324957e1f0f0feb578
Before you begin deploying, make sure to remove any console.log‘s or debugger‘s in any production code. You can search your entire project folder if you are using them anywhere.
You will set up Heroku to run on a production, not development, version of your application. When a Node.js application like yours is pushed up to Heroku, it is identified as a Node.js application because of the package.json file. It runs npm install automatically. Then, if there is a heroku-postbuild script in the package.json file, it will run that script. Afterwards, it will automatically run npm start.
In the following phases, you will configure your application to work in production, not just in development, and configure the package.json scripts for install, heroku-postbuild and start scripts to install, build your React application, and start the Express production server.
Phase 1: Heroku Connection
If you haven’t created a Heroku account yet, create one here.
Add a new application in your Heroku dashboard named whatever you want. Under the “Resources” tab in your new application, click “Find more add-ons” and add the “Heroku Postgres” add-on with the free Hobby Dev setting.
In your terminal, install the Heroku CLI. Afterwards, login to Heroku in your terminal by running the following:
heroku login
Add Heroku as a remote to your project’s git repository in the following command and replace <name-of-Heroku-app> with the name of the application you created in the Heroku dashboard.
heroku git:remote -a <name-of-Heroku-app>
Next, you will set up your Express + React application to be deployable to Heroku.
Phase 2: Setting up your Express + React application
Right now, your React application is on a different localhost port than your Express application. However, since your React application only consists of static files that don’t need to bundled continuously with changes in production, your Express application can serve the React assets in production too. These static files live in the frontend/build folder after running npm run build in the frontend folder.
Add the following changes into your backend/routes.index.js file.
At the root route, serve the React application’s static index.html file along with XSRF-TOKEN cookie. Then serve up all the React application’s static files using the express.static middleware. Serve the index.html and set the XSRF-TOKEN cookie again on all routes that don’t start in /api. You should already have this set up in backend/routes/index.js which should now look like this:
// backend/routes/index.jsconst express = require('express');const router = express.Router();const apiRouter = require('./api');
router.use('/api', apiRouter);
// Static routes// Serve React build files in productionif (process.env.NODE_ENV === 'production') { const path = require('path'); // Serve the frontend's index.html file at the root route router.get('/', (req, res) => { res.cookie('XSRF-TOKEN', req.csrfToken()); res.sendFile( path.resolve(__dirname, '../../frontend', 'build', 'index.html') ); });
// Serve the static assets in the frontend's build folder router.use(express.static(path.resolve("../frontend/build")));
// Serve the frontend's index.html file at all other routes NOT starting with /api router.get(/^(?!\/?api).*/, (req, res) => { res.cookie('XSRF-TOKEN', req.csrfToken()); res.sendFile( path.resolve(__dirname, '../../frontend', 'build', 'index.html') ); });}
// Add a XSRF-TOKEN cookie in developmentif (process.env.NODE_ENV !== 'production') { router.get('/api/csrf/restore', (req, res) => { res.cookie('XSRF-TOKEN', req.csrfToken()); res.status(201).json({}); });}
module.exports = router;
Your Express backend’s package.json should include scripts to run the sequelize CLI commands.
The backend/package.json‘s scripts should now look like this:
"scripts": { "sequelize": "sequelize", "sequelize-cli": "sequelize-cli", "start": "per-env", "start:development": "nodemon -r dotenv/config ./bin/www", "start:production": "node ./bin/www" },
Initialize a package.json file at the very root of your project directory (outside of both the backend and frontend folders). The scripts defined in this package.json file will be run by Heroku, not the scripts defined in the backend/package.json or the frontend/package.json.
When Heroku runs npm install, it should install packages for both the backend and the frontend. Overwrite the install script in the root package.json with:
npm --prefix backend install backend && npm --prefix frontend install frontend
This will run npm install in the backend folder then run npm install in the frontend folder.
Next, define a heroku-postbuild script that will run the npm run build command in the frontend folder. Remember, Heroku will automatically run this script after running npm install.
Define a sequelize script that will run npm run sequelize in the backend folder.
Finally, define a start that will run npm start in the `backend folder.
The root package.json‘s scripts should look like this:
"scripts": { "heroku-postbuild": "npm run build --prefix frontend", "install": "npm --prefix backend install backend && npm --prefix frontend install frontend", "dev:backend": "npm install --prefix backend start", "dev:frontend": "npm install --prefix frontend start", "sequelize": "npm run --prefix backend sequelize", "sequelize-cli": "npm run --prefix backend sequelize-cli", "start": "npm start --prefix backend" },
The dev:backend and dev:frontend scripts are optional and will not be used for Heroku.
Finally, commit your changes.
Phase 3: Deploy to Heroku
Once you’re finished setting this up, navigate to your application’s Heroku dashboard. Under “Settings” there is a section for “Config Vars”. Click the Reveal Config Vars button to see all your production environment variables. You should have a DATABASE_URL environment variable already from the Heroku Postgres add-on.
Add environment variables for JWT_EXPIRES_IN and JWT_SECRET and any other environment variables you need for production.
You can also set environment variables through the Heroku CLI you installed earlier in your terminal. See the docs for Setting Heroku Config Variables.
Push your project to Heroku. Heroku only allows the master branch to be pushed. But, you can alias your branch to be named master when pushing to Heroku. For example, to push a branch called login-branch to master run:
git push heroku login-branch:master
If you do want to push the master branch, just run:
git push heroku master
You may want to make two applications on Heroku, the master branch site that should have working code only. And your staging site that you can use to test your work in progress code.
Now you need to migrate and seed your production database.
Using the Heroku CLI, you can run commands inside of your production application just like in development using the heroku run command.
For example to migrate the production database, run:
heroku run npm run sequelize db:migrate
To seed the production database, run:
heroku run npm run sequelize db:seed:all
Note: You can interact with your database this way as you’d like, but beware that db:drop cannot be run in the Heroku environment. If you want to drop and create the database, you need to remove and add back the “Heroku Postgres” add-on.
Another way to interact with the production application is by opening a bash shell through your terminal by running:
heroku bash
In the opened shell, you can run things like npm run sequelize db:migrate.
Open your deployed site and check to see if you successfully deployed your Express + React application to Heroku!
If you see an Application Error or are experiencing different behavior than what you see in your local environment, check the logs by running:
heroku logs
If you want to open a connection to the logs to continuously output to your terminal, then run:
heroku logs --tail
The logs may clue you into why you are experiencing errors or different behavior.
If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:
CODEX
Each table is made up of rows and columns. If you think of a table as a grid, the column go from left to right across the grid and each entry of data is listed down as a row.
Each row in a relational is uniquely identified by a primary key. This can be by one or more sets of column values. In most scenarios it is a single column, such as employeeID.
Every relational table has one primary key. Its purpose is to uniquely identify each row in the database. No two rows can have the same primary key value. The practical result of this is that you can select every single row by just knowing its primary key.
SQL Server UNIQUE constraints allow you to ensure that the data stored in a column, or a group of columns, is unique among the rows in a table.
Although both UNIQUE and PRIMARY KEY constraints enforce the uniqueness of data, you should use the UNIQUE constraint instead of PRIMARY KEY constraint when you want to enforce the uniqueness of a column, or a group of columns, that are not the primary key columns.
Different from PRIMARY KEY constraints, UNIQUE constraints allow NULL. Moreover, UNIQUE constraints treat the NULL as a regular value, therefore, it only allows one NULL per column.

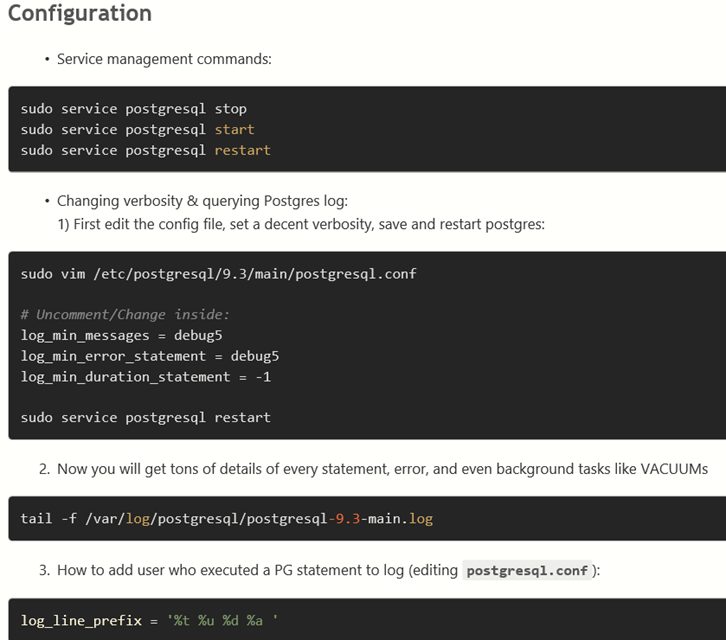

Create a new role:
CREATE ROLE role_name;
Create a new role with a username and password:
CREATE ROLE username NOINHERIT LOGIN PASSWORD password;
Change role for the current session to the new_role:
SET ROLE new_role;
Allow role_1 to set its role as role_2:
GRANT role_2 TO role_1;
Managing databases
CREATE DATABASE [IF NOT EXISTS] db_name;
Delete a database permanently:
DROP DATABASE [IF EXISTS] db_name;
Managing tables
Create a new table or a temporary table
CREATE [TEMP] TABLE [IF NOT EXISTS] table_name( pk SERIAL PRIMARY KEY, c1 type(size) NOT NULL, c2 type(size) NULL, ...);
Add a new column to a table:
ALTER TABLE table_name ADD COLUMN new_column_name TYPE;
Drop a column in a table:
ALTER TABLE table_name DROP COLUMN column_name;
ALTER TABLE table_name RENAME column_name TO new_column_name;
Set or remove a default value for a column:
ALTER TABLE table_name ALTER COLUMN [SET DEFAULT value | DROP DEFAULT]
Add a primary key to a table.
ALTER TABLE table_name ADD PRIMARY KEY (column,...);
Remove the primary key from a table.
ALTER TABLE table_nameDROP CONSTRAINT primary_key_constraint_name;
ALTER TABLE table_name RENAME TO new_table_name;
Drop a table and its dependent objects:
DROP TABLE [IF EXISTS] table_name CASCADE;
Managing views
CREATE OR REPLACE view_name ASquery;
CREATE RECURSIVE VIEW view_name(column_list) ASSELECT column_list;
CREATE MATERIALIZED VIEW view_nameASqueryWITH [NO] DATA;
Refresh a materialized view:
REFRESH MATERIALIZED VIEW CONCURRENTLY view_name;
Drop a view:
DROP VIEW [ IF EXISTS ] view_name;
Drop a materialized view:
DROP MATERIALIZED VIEW view_name;
Rename a view:
ALTER VIEW view_name RENAME TO new_name;
Managing indexes
Creating an index with the specified name on a table
CREATE [UNIQUE] INDEX index_nameON table (column,...)
Removing a specified index from a table
DROP INDEX index_name;
Querying data from tables
Query all data from a table:
SELECT * FROM table_name;
Query data from specified columns of all rows in a table:
SELECT column_listFROM table;
Query data and select only unique rows:
SELECT DISTINCT (column)FROM table;
Query data from a table with a filter:
SELECT *FROM tableWHERE condition;
Assign an alias to a column in the result set:
SELECT column_1 AS new_column_1, ...FROM table;
Query data using the [LIKE](https://www.postgresqltutorial.com/postgresql-like/) operator:
SELECT * FROM table_nameWHERE column LIKE '%value%'
Query data using the [BETWEEN](https://www.postgresqltutorial.com/postgresql-between/) operator:
SELECT * FROM table_nameWHERE column BETWEEN low AND high;
Query data using the [IN](https://www.postgresqltutorial.com/postgresql-in/) operator:
SELECT * FROM table_nameWHERE column IN (value1, value2,...);
Constrain the returned rows with the [LIMIT](https://www.postgresqltutorial.com/postgresql-limit/) clause:
SELECT * FROM table_nameLIMIT limit OFFSET offsetORDER BY column_name;
Query data from multiple using the inner join, left join, full outer join, cross join and natural join:
SELECT *FROM table1INNER JOIN table2 ON conditionsSELECT *FROM table1LEFT JOIN table2 ON conditionsSELECT *FROM table1FULL OUTER JOIN table2 ON conditionsSELECT *FROM table1CROSS JOIN table2;SELECT *FROM table1NATURAL JOIN table2;
Return the number of rows of a table.
SELECT COUNT (*)FROM table_name;
Sort rows in ascending or descending order:
SELECT select_listFROM tableORDER BY column ASC [DESC], column2 ASC [DESC],...;
Group rows using [GROUP BY](https://www.postgresqltutorial.com/postgresql-group-by/) clause.
SELECT *FROM tableGROUP BY column_1, column_2, ...;
Filter groups using the [HAVING](https://www.postgresqltutorial.com/postgresql-having/) clause.
SELECT *FROM tableGROUP BY column_1HAVING condition;
Set operations
Combine the result set of two or more queries with [UNION](https://www.postgresqltutorial.com/postgresql-union/) operator:
SELECT * FROM table1UNIONSELECT * FROM table2;
Minus a result set using [EXCEPT](https://www.postgresqltutorial.com/postgresql-tutorial/postgresql-except/) operator:
SELECT * FROM table1EXCEPTSELECT * FROM table2;
Get intersection of the result sets of two queries:
SELECT * FROM table1INTERSECTSELECT * FROM table2;
Modifying data
Insert a new row into a table:
INSERT INTO table(column1,column2,...)VALUES(value_1,value_2,...);
Insert multiple rows into a table:
INSERT INTO table_name(column1,column2,...)VALUES(value_1,value_2,...), (value_1,value_2,...), (value_1,value_2,...)...
Update data for all rows:
UPDATE table_nameSET column_1 = value_1, ...;
Update data for a set of rows specified by a condition in the WHERE clause.
UPDATE tableSET column_1 = value_1, ...WHERE condition;
Delete all rows of a table:
DELETE FROM table_name;
Delete specific rows based on a condition:
DELETE FROM table_nameWHERE condition;
Performance
Show the query plan for a query:
EXPLAIN query;
Show and execute the query plan for a query:
EXPLAIN ANALYZE query;
Collect statistics:
ANALYZE table_name;
Postgres & JSON:
Creating the DB and the Table
DROP DATABASE IF EXISTS books_db;CREATE DATABASE books_db WITH ENCODING='UTF8' TEMPLATE template0;
DROP TABLE IF EXISTS books;
CREATE TABLE books ( id SERIAL PRIMARY KEY, client VARCHAR NOT NULL, data JSONb NOT NULL);
Populating the DB
INSERT INTO books(client, data) values( 'Joe', '{ "title": "Siddhartha", "author": { "firstname": "Herman", "lastname": "Hesse" } }' ); INSERT INTO books(client, data) values('Jenny', '{ "title": "Bryan Guner", "author": { "firstname": "Jack", "lastname": "Kerouac" } }'); INSERT INTO books(client, data) values('Jenny', '{ "title": "100 años de soledad", "author": { "firstname": "Gabo", "lastname": "Marquéz" } }');
Lets see everything inside the table books:
SELECT * FROM books;
Output:

-> operator returns values out of JSON columns
Selecting 1 column:
SELECT client, data->'title' AS title FROM books;
Output:

Selecting 2 columns:
SELECT client, data->'title' AS title, data->'author' AS author FROM books;
Output:

-> vs ->>
The -> operator returns the original JSON type (which might be an object), whereas ->> returns text.
Return NESTED objects
You can use the -> to return a nested object and thus chain the operators:
SELECT client, data->'author'->'last_name' AS author FROM books;
Output:

Filtering
Select rows based on a value inside your JSON:
SELECT client, data->'title' AS title FROM books WHERE data->'title' = '"Bryan Guner"';
Notice WHERE uses -> so we must compare to JSON '"Bryan Guner"'
Or we could use ->> and compare to 'Bryan Guner'
Output:

Nested filtering
Find rows based on the value of a nested JSON object:
SELECT client, data->'title' AS title FROM books WHERE data->'author'->>'last_name' = 'Kerouac';
Output:

A real world example
CREATE TABLE events ( name varchar(200), visitor_id varchar(200), properties json, browser json);
We’re going to store events in this table, like pageviews. Each event has properties, which could be anything (e.g. current page) and also sends information about the browser (like OS, screen resolution, etc). Both of these are completely free form and could change over time (as we think of extra stuff to track).
INSERT INTO events VALUES ( 'pageview', '1', '{ "page": "/" }', '{ "name": "Chrome", "os": "Mac", "resolution": { "x": 1440, "y": 900 } }');INSERT INTO events VALUES ( 'pageview', '2', '{ "page": "/" }', '{ "name": "Firefox", "os": "Windows", "resolution": { "x": 1920, "y": 1200 } }');INSERT INTO events VALUES ( 'pageview', '1', '{ "page": "/account" }', '{ "name": "Chrome", "os": "Mac", "resolution": { "x": 1440, "y": 900 } }');INSERT INTO events VALUES ( 'purchase', '5', '{ "amount": 10 }', '{ "name": "Firefox", "os": "Windows", "resolution": { "x": 1024, "y": 768 } }');INSERT INTO events VALUES ( 'purchase', '15', '{ "amount": 200 }', '{ "name": "Firefox", "os": "Windows", "resolution": { "x": 1280, "y": 800 } }');INSERT INTO events VALUES ( 'purchase', '15', '{ "amount": 500 }', '{ "name": "Firefox", "os": "Windows", "resolution": { "x": 1280, "y": 800 } }');
Now lets select everything:
SELECT * FROM events;
Output:

JSON operators + PostgreSQL aggregate functions
Using the JSON operators, combined with traditional PostgreSQL aggregate functions, we can pull out whatever we want. You have the full might of an RDBMS at your disposal.
- Lets see browser usage:
SELECT browser->>'name' AS browser, count(browser) FROM events GROUP BY browser->>'name';
Output:

- Total revenue per visitor:
SELECT visitor_id, SUM(CAST(properties->>'amount' AS integer)) AS total FROM events WHERE CAST(properties->>'amount' AS integer) > 0 GROUP BY visitor_id;
Output:

- Average screen resolution
SELECT AVG(CAST(browser->'resolution'->>'x' AS integer)) AS width, AVG(CAST(browser->'resolution'->>'y' AS integer)) AS height FROM events;
Output:

If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://github.com/bgoonzhttps://github.com/bgoonz
Or Checkout my personal Resource Site:

Curating Complexity: A Guide to Big-O Notation
- Why is looking at runtime not a reliable method of calculating time complexity?
- Not all computers are made equal( some may be stronger and therefore boost our runtime speed )
- How many background processes ran concurrently with our program that was being tested?
- We also need to ask if our code remains performant if we increase the size of the input.
- The real question we need to answering is:
How does our performance scale?.
big ‘O’ notation
- Big O Notation is a tool for describing the efficiency of algorithms with respect to the size of the input arguments.
- Since we use mathematical functions in Big-O, there are a few big picture ideas that we’ll want to keep in mind:
- The function should be defined by the size of the input.
SmallerBig O is better (lower time complexity)- Big O is used to describe the worst case scenario.
- Big O is simplified to show only its most dominant mathematical term.
Simplifying Math Terms
- We can use the following rules to simplify the our Big O functions:
Simplify Products: If the function is a product of many terms, we drop the terms that don’t depend on n.Simplify Sums: If the function is a sum of many terms, we drop the non-dominant terms.n: size of the inputT(f): unsimplified math functionO(f): simplified math function.
Putting it all together

- First we apply the product rule to drop all constants.
- Then we apply the sum rule to select the single most dominant term.
Complexity Classes
Common Complexity Classes
There are 7 major classes in Time Complexity

O(1) Constant
The algorithm takes roughly the same number of steps for any input size.
https://gist.github.com/eengineergz/91b823971e8faac788f38ff670efc19d#file-constant-js
O(log(n)) Logarithmic
In most cases our hidden base of Logarithmic time is 2, log complexity algorithm’s will typically display ‘halving’ the size of the input (like binary search!)
https://gist.github.com/eengineergz/a1e6dec81f0639818db7f9a8e76b3992
O(n) Linear
Linear algorithm’s will access each item of the input “once”.
https://gist.github.com/eengineergz/cc953ba2bd6e1d6f524a6d8b297aad5b
O(nlog(n)) Log Linear Time
Combination of linear and logarithmic behavior, we will see features from both classes.
Algorithm’s that are log-linear will use both recursion AND iteration.
https://gist.github.com/eengineergz/e9bd6337c17f1623a4da088574ed0d8e
O(nc) Polynomial
C is a fixed constant.
https://gist.github.com/eengineergz/3e6096e66bac80b962435b7d873cdbe9
O(c^n) Exponential
C is now the number of recursive calls made in each stack frame.
Algorithm’s with exponential time are VERY SLOW.
https://gist.github.com/eengineergz/5dec7e3736d7b5e28a5f1c85b5b50705
Memoization
- Memoization : a design pattern used to reduce the overall number of calculations that can occur in algorithms that use recursive strategies to solve.
- MZ stores the results of the sub-problems in some other data structure, so that we can avoid duplicate calculations and only ‘solve’ each problem once.
- Two features that comprise memoization:
- FUNCTION MUST BE RECURSIVE.
- Our additional Data Structure is usually an object (we refer to it as our memo… or sometimes cache!)


Memoizing Factorial
https://gist.github.com/eengineergz/0f92023740a44e3b41a0defb227ade37#file-memoizing-factorial-js
Our memo object is mapping out our arguments of factorial to it’s return value.
- Keep in mind we didn’t improve the speed of our algorithm.
Memoizing Fibonacci
- Our time complexity for Fibonacci goes from O(2^n) to O(n) after applying memoization.
The Memoization Formula
Rules:
- Write the unoptimized brute force recursion (make sure it works);
- Add memo object as an additional argument .
- Add a base case condition that returns the stored value if the function’s argument is in the memo.
- Before returning the result of the recursive case, store it in the memo as a value and make the function’s argument it’s key.
Things to remember
- When solving DP problems with Memoization, it is helpful to draw out the visual tree first.
- When you notice duplicate sub-tree’s that means we can memoize.
https://gist.github.com/eengineergz/c15feb228a51a3543625009c8fd0b6de
Tabulation
Tabulation Strategy
Use When:
- The function is iterative and not recursive.
- The accompanying DS is usually an array.
https://gist.github.com/eengineergz/a57bf449f5a8b16eedd1aa9fd71707e2
Steps for tabulation
- Create a table array based off the size of the input.
- Initialize some values in the table to ‘answer’ the trivially small subproblem.
- Iterate through the array and fill in the remaining entries.
- Your final answer is usually the last entry in the table.
Memo and Tab Demo with Fibonacci
Normal Recursive Fibonacci
function fibonacci(n) {
if (n <= 2) return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
Memoization Fibonacci 1
https://gist.github.com/eengineergz/504a9120ca40bbb4a246549937c43a12
Memoization Fibonacci 2
https://gist.github.com/eengineergz/07d315d92b3458a8640cee31bce9c236
Tabulated Fibonacci
https://gist.github.com/eengineergz/b1b1f7e259193ecdc432350b6199f2d3
Example of Linear Search
https://gist.github.com/eengineergz/e98354b287ce2f80da4ab943399eb555
- Worst Case Scenario: The term does not even exist in the array.
- Meaning: If it doesn’t exist then our for loop would run until the end therefore making our time complexity O(n).
Sorting Algorithms
Bubble Sort
Time Complexity: Quadratic O(n^2)
- The inner for-loop contributes to O(n), however in a worst case scenario the while loop will need to run n times before bringing all n elements to their final resting spot.
Space Complexity: O(1)
- Bubble Sort will always use the same amount of memory regardless of n.
https://gist.github.com/eengineergz/e67e56bed7c5a20a54851867ba5efef6
- The first major sorting algorithm one learns in introductory programming courses.
- Gives an intro on how to convert unsorted data into sorted data.
It’s almost never used in production code because:
- It’s not efficient
- It’s not commonly used
- There is stigma attached to it
_Bubbling Up_: Term that infers that an item is in motion, moving in some direction, and has some final resting destination.- Bubble sort, sorts an array of integers by bubbling the largest integer to the top.
https://gist.github.com/eengineergz/fd4acc0c89033bd219ebf9d3ec40b053https://gist.github.com/eengineergz/80934783c628c70ac2a5a48119a82d54
- Worst Case & Best Case are always the same because it makes nested loops.
- Double for loops are polynomial time complexity or more specifically in this case Quadratic (Big O) of: O(n²)
Selection Sort
Time Complexity: Quadratic O(n^2)
- Our outer loop will contribute O(n) while the inner loop will contribute O(n / 2) on average. Because our loops are nested we will get O(n²);
Space Complexity: O(1)
- Selection Sort will always use the same amount of memory regardless of n.
https://gist.github.com/eengineergz/4abc0fe0bf01599b0c4104b0ba633402
- Selection sort organizes the smallest elements to the start of the array.
Summary of how Selection Sort should work:
- Set MIN to location 0
- Search the minimum element in the list.
- Swap with value at location Min
- Increment Min to point to next element.
- Repeat until list is sorted.
https://gist.github.com/eengineergz/61f130c8e0097572ed908fe2629bdee0
Insertion Sort
Time Complexity: Quadratic O(n^2)
- Our outer loop will contribute O(n) while the inner loop will contribute O(n / 2) on average. Because our loops are nested we will get O(n²);
Space Complexity: O(n)
- Because we are creating a subArray for each element in the original input, our Space Comlexity becomes linear.

https://gist.github.com/eengineergz/a9f4b8596c7546ac92746db659186d8c
Merge Sort
Time Complexity: Log Linear O(nlog(n))
- Since our array gets split in half every single time we contribute O(log(n)). The while loop contained in our helper merge function contributes O(n) therefore our time complexity is O(nlog(n));
Space Complexity: O(n) - We are linear O(n) time because we are creating subArrays.
Example of Merge Sort
https://gist.github.com/eengineergz/18fbb7edc9f5c4820ccfcecacf3c5e48https://gist.github.com/eengineergz/cbb533137a7f957d3bc4077395c1ff64
- Merge sort is O(nlog(n)) time.
- We need a function for merging and a function for sorting.
Steps:
- If there is only one element in the list, it is already sorted; return the array.
- Otherwise, divide the list recursively into two halves until it can no longer be divided.
- Merge the smallest lists into new list in a sorted order.
Quick Sort
Time Complexity: Quadratic O(n^2)
- Even though the average time complexity O(nLog(n)), the worst case scenario is always quadratic.
Space Complexity: O(n)
- Our space complexity is linear O(n) because of the partition arrays we create.
- QS is another Divide and Conquer strategy.
- Some key ideas to keep in mind:
- It is easy to sort elements of an array relative to a particular target value.
- An array of 0 or 1 elements is already trivially sorted.
https://gist.github.com/eengineergz/24bcbc5248a8c4e1671945e9512da57e
Binary Search
Time Complexity: Log Time O(log(n))
Space Complexity: O(1)
{kind=link}
{kind=link}
{kind=link}
Recursive Solution
https://gist.github.com/eengineergz/c82c00a4bcba4b69b7d326d6cad3ac8c
Min Max Solution
https://gist.github.com/eengineergz/eb8d1e1684db15cc2c8af28e13f38751https://gist.github.com/eengineergz/bc3f576b9795ccef12a108e36f9f820a
- Must be conducted on a sorted array.
- Binary search is logarithmic time, not exponential b/c n is cut down by two, not growing.
- Binary Search is part of Divide and Conquer.
Insertion Sort
- Works by building a larger and larger sorted region at the left-most end of the array.
Steps:
- If it is the first element, and it is already sorted; return 1.
- Pick next element.
- Compare with all elements in the sorted sub list
- Shift all the elements in the sorted sub list that is greater than the value to be sorted.
- Insert the value
- Repeat until list is sorted.
https://gist.github.com/eengineergz/ffead1de0836c4bcc6445780a604f617
If you found this guide helpful feel free to checkout my GitHub/gists where I host similar content:
https://gist.github.com/bgoonzhttps://gist.github.com/bgoonz
Or Checkout my personal Resource Site:
https://gist.github.com/bgoonz

https://gist.github.com/bgoonz/af844eda5a20b0fdc0b813304401602b
Windows Subsystem for Linux (WSL) and Ubuntu

Test if you have Ubuntu installed by typing “Ubuntu” in the search box in the bottom app bar that reads “Type here to search”. If you see a search result that reads “Ubuntu 20.04 LTS” with “App” under it, then you have it installed.
- In the application search box in the bottom bar, type “PowerShell” to find the application named “Windows PowerShell”
- Right-click on “Windows PowerShell” and choose “Run as administrator” from the popup menu
- In the blue PowerShell window, type the following:
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux - Restart your computer
- In the application search box in the bottom bar, type “Store” to find the application named “Microsoft Store”
- Click “Microsoft Store”
- Click the “Search” button in the upper-right corner of the window
- Type in “Ubuntu”
- Click “Run Linux on Windows (Get the apps)”
- Click the orange tile labeled “Ubuntu” Note that there are 3 versions in the Microsoft Store… you want the one just entitled ‘Ubuntu’
- Click “Install”
- After it downloads, click “Launch”
- If you get the option, pin the application to the task bar. Otherwise, right-click on the orange Ubuntu icon in the task bar and choose “Pin to taskbar”
- When prompted to “Enter new UNIX username”, type your first name with no spaces
- When prompted, enter and retype a password for this UNIX user (it can be the same as your Windows password)
- Confirm your installation by typing the command
whoami ‘as in who-am-i'followed by Enter at the prompt (it should print your first name) - You need to update your packages, so type
sudo apt update(if prompted for your password, enter it) - You need to upgrade your packages, so type
sudo apt upgrade(if prompted for your password, enter it)
Git
Git comes with Ubuntu, so there’s nothing to install. However, you should configure it using the following instructions.
Open an Ubuntu terminal if you don’t have one open already.
- You need to configure Git, so type
git config --global user.name "Your Name"with replacing “Your Name” with your real name. - You need to configure Git, so type
git config --global user.email your@email.comwith replacing “your@email.com” with your real email.
Note: if you want git to remember your login credentials type:
$ git config --global credential.helper store
Google Chrome
Test if you have Chrome installed by typing “Chrome” in the search box in the bottom app bar that reads “Type here to search”. If you see a search result that reads “Chrome” with “App” under it, then you have it installed. Otherwise, follow these instructions to install Google Chrome.
- Open Microsoft Edge, the blue “e” in the task bar, and type in http://chrome.google.com. Click the “Download Chrome” button. Click the “Accept and Install” button after reading the terms of service. Click “Save” in the “What do you want to do with ChromeSetup.exe” dialog at the bottom of the window. When you have the option to “Run” it, do so. Answer the questions as you’d like. Set it as the default browser.
- Right-click on the Chrome icon in the task bar and choose “Pin to taskbar”.
Node.js
Test if you have Node.js installed by opening an Ubuntu terminal and typing node --version. If it reports “Command ‘node’ not found”, then you need to follow these directions.
- In the Ubuntu terminal, type
sudo apt updateand press Enter - In the Ubuntu terminal, type
sudo apt install build-essentialand press Enter - In the Ubuntu terminal, type
curl -o- [https://raw.githubusercontent.com/nvm-sh/nvm/v0.35.2/install.sh](https://raw.githubusercontent.com/nvm-sh/nvm/v0.35.2/install.sh) | bashand press Enter - In the Ubuntu terminal, type
. ./.bashrcand press Enter - In the Ubuntu terminal, type
nvm install --ltsand press Enter - Confirm that node is installed by typing
node --versionand seeing it print something that is not “Command not found”!
Unzip
You will often have to download a zip file and unzip it. It is easier to do this from the command line. So we need to install a linux unzip utility.
In the Ubuntu terminal type: sudo apt install unzip and press Enter
Mocha.js
Test if you have Mocha.js installed by opening an Ubuntu terminal and typing which mocha. If it prints a path, then you’re good. Otherwise, if it prints nothing, install Mocha.js by typing npm install -g mocha.
Python 3
Ubuntu does not come with Python 3. Install it using the command sudo apt install python3. Test it by typing python3 --version and seeing it print a number.
Note about WSL
As of the time of writing of this document, WSL has an issue renaming or deleting files if Visual Studio Code is open. So before doing any linux commands which manipulate files, make sure you close Visual Studio Code before running those commands in the Ubuntu terminal.
Some other common instillations
# Installing build essentials
sudo apt-get install -y build-essential libssl-dev
# Nodejs and NVM
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.33.2/install.sh | bash
source ~/.profile
sudo nvm install 7.10.0
sudo nvm use 7.10.0
node -v
nodemon
sudo npm install -g nodemon
sudo npm install -g loopback-cli
# Forever to run nodejs scripts forever
sudo npm install forever -g
# Git - a version control system
sudo apt-get update
sudo apt-get install -y git xclip
# Grunt - an automated task runner
sudo npm install -g grunt-cli
# Bower - a dependency manager
sudo npm install -g bower
# Yeoman - for generators
sudo npm install -g yo
# maven
sudo apt-get install maven -y
# Gulp - an automated task runner
sudo npm install -g gulp-cli
# Angular FullStack - My favorite MEAN boilerplate (MEAN = MongoDB, Express, Angularjs, Nodejs)
sudo npm install -g generator-angular-fullstack
# Vim, Curl, Python - Some random useful stuff
sudo apt-get install -y vim curl python-software-properties
sudo apt-get install -y python-dev, python-pip
sudo apt-get install -y libkrb5-dev
# Installing JDK and JRE
sudo apt-get install -y default-jre
sudo apt-get install -y default-jdk
# Archive Extractors
sudo apt-get install -y unace unrar zip unzip p7zip-full p7zip-rar sharutils rar uudeview mpack arj cabextract file-roller
# FileZilla - a FTP client
sudo apt-get install -y filezilla
If you found this guide helpful feel free to checkout my github/gists where I host similar content:
Or Checkout my personal Resource Site:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus. Donec sed odio dui. Aenean eu leo quam. Pellentesque ornare sem lacinia quam venenatis vestibulum. Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Praesent commodo cursus magna, vel scelerisque nisl consectetur et.
Donec sed odio dui. Aenean eu leo quam. Pellentesque ornare sem lacinia quam venenatis vestibulum. Vivamus sagittis lacus vel augue laoreet rutrum faucibus dolor auctor. Nullam quis risus eget urna mollis ornare vel eu leo. Praesent commodo cursus magna, vel scelerisque nisl consectetur et. Etiam porta sem malesuada magna mollis euismod.
Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec sed odio dui. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Integer posuere erat a ante venenatis dapibus posuere velit aliquet.
Nulla vitae elit libero, a pharetra augue. Nullam id dolor id nibh ultricies vehicula ut id elit. Cras mattis consectetur purus sit amet fermentum. Vestibulum id ligula porta felis euismod semper. Donec ullamcorper nulla non metus auctor fringilla.
Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus. Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Nulla vitae elit libero, a pharetra augue. Cras mattis consectetur purus sit amet fermentum.
Duis mollis, est non commodo luctus, nisi erat porttitor ligula, eget lacinia odio sem nec elit. Sed posuere consectetur est at lobortis. Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Donec sed odio dui. Cras mattis consectetur purus sit amet fermentum. Etiam porta sem malesuada magna mollis euismod. Vestibulum id ligula porta felis euismod semper.
Etiam porta sem malesuada magna mollis euismod. Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Nullam id dolor id nibh ultricies vehicula ut id elit. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras mattis consectetur purus sit amet fermentum. Maecenas sed diam eget risus varius blandit sit amet non magna.
Nullam quis risus eget urna mollis ornare vel eu leo. Donec id elit non mi porta gravida at eget metus. Aenean eu leo quam. Pellentesque ornare sem lacinia quam venenatis vestibulum. Nullam quis risus eget urna mollis ornare vel eu leo. Donec sed odio dui. Maecenas sed diam eget risus varius blandit sit amet non magna. Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus.
Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus. Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Nulla vitae elit libero, a pharetra augue. Cras mattis consectetur purus sit amet fermentum.
Duis mollis, est non commodo luctus, nisi erat porttitor ligula, eget lacinia odio sem nec elit. Sed posuere consectetur est at lobortis. Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Donec sed odio dui. Cras mattis consectetur purus sit amet fermentum. Etiam porta sem malesuada magna mollis euismod. Vestibulum id ligula porta felis euismod semper.
Etiam porta sem malesuada magna mollis euismod. Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Nullam id dolor id nibh ultricies vehicula ut id elit. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras mattis consectetur purus sit amet fermentum. Maecenas sed diam eget risus varius blandit sit amet non magna.
Nullam quis risus eget urna mollis ornare vel eu leo. Donec id elit non mi porta gravida at eget metus. Aenean eu leo quam. Pellentesque ornare sem lacinia quam venenatis vestibulum. Nullam quis risus eget urna mollis ornare vel eu leo. Donec sed odio dui. Maecenas sed diam eget risus varius blandit sit amet non magna. Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus.
It all begins with an idea. Maybe you want to launch a business. Maybe you want to turn a hobby into something more. Or maybe you have a creative project to share with the world. Whatever it is, the way you tell your story online can make all the difference.
Don’t worry about sounding professional. Sound like you. There are over 1.5 billion websites out there, but your story is what’s going to separate this one from the rest. If you read the words back and don’t hear your own voice in your head, that’s a good sign you still have more work to do.
Be clear, be confident and don’t overthink it. The beauty of your story is that it’s going to continue to evolve and your site can evolve with it. Your goal should be to make it feel right for right now. Later will take care of itself. It always does.
Aenean eu leo quam. Pellentesque ornare sem lacinia quam venenatis vestibulum. Praesent commodo cursus magna, vel scelerisque nisl consectetur et. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Aenean lacinia bibendum nulla sed consectetur. Nullam id dolor id nibh ultricies vehicula ut id elit. Donec sed odio dui.
Aenean lacinia bibendum nulla sed consectetur. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Etiam porta sem malesuada magna mollis euismod. Donec sed odio dui.
Curabitur blandit tempus porttitor. Vivamus sagittis lacus vel augue laoreet rutrum faucibus dolor auctor. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Praesent commodo cursus magna, vel scelerisque nisl consectetur et. Curabitur blandit tempus porttitor. Vestibulum id ligula porta felis euismod semper.
Praesent commodo cursus magna, vel scelerisque nisl consectetur et. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Cras mattis consectetur purus sit amet fermentum. Nullam quis risus eget urna mollis ornare vel eu leo. Maecenas faucibus mollis interdum. Aenean lacinia bibendum nulla sed consectetur.
It all begins with an idea. Maybe you want to launch a business. Maybe you want to turn a hobby into something more. Or maybe you have a creative project to share with the world. Whatever it is, the way you tell your story online can make all the difference.
Don’t worry about sounding professional. Sound like you. There are over 1.5 billion websites out there, but your story is what’s going to separate this one from the rest. If you read the words back and don’t hear your own voice in your head, that’s a good sign you still have more work to do.
Be clear, be confident and don’t overthink it. The beauty of your story is that it’s going to continue to evolve and your site can evolve with it. Your goal should be to make it feel right for right now. Later will take care of itself. It always does.
Maecenas sed diam eget risus varius blandit sit amet non magna. Vestibulum id ligula porta felis euismod semper. Duis mollis, est non commodo luctus, nisi erat porttitor ligula, eget lacinia odio sem nec elit. Aenean eu leo quam. Pellentesque ornare sem lacinia quam venenatis vestibulum. Sed posuere consectetur est at lobortis. Morbi leo risus, porta ac consectetur ac, vestibulum at eros. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus.
Donec id elit non mi porta gravida at eget metus. Nullam quis risus eget urna mollis ornare vel eu leo. Sed posuere consectetur est at lobortis. Maecenas sed diam eget risus varius blandit sit amet non magna. Nulla vitae elit libero, a pharetra augue. Etiam porta sem malesuada magna mollis euismod.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec ullamcorper nulla non metus auctor fringilla. Donec id elit non mi porta gravida at eget metus. Duis mollis, est non commodo luctus, nisi erat porttitor ligula, eget lacinia odio sem nec elit. Etiam porta sem malesuada magna mollis euismod. Praesent commodo cursus magna, vel scelerisque nisl consectetur et.
Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus. Vestibulum id ligula porta felis euismod semper. Aenean eu leo quam. Pellentesque ornare sem lacinia quam venenatis vestibulum. Maecenas faucibus mollis interdum. Cras mattis consectetur purus sit amet fermentum.
It all begins with an idea. Maybe you want to launch a business. Maybe you want to turn a hobby into something more. Or maybe you have a creative project to share with the world. Whatever it is, the way you tell your story online can make all the difference.
Don’t worry about sounding professional. Sound like you. There are over 1.5 billion websites out there, but your story is what’s going to separate this one from the rest. If you read the words back and don’t hear your own voice in your head, that’s a good sign you still have more work to do.
Be clear, be confident and don’t overthink it. The beauty of your story is that it’s going to continue to evolve and your site can evolve with it. Your goal should be to make it feel right for right now. Later will take care of itself. It always does.
Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Donec id elit non mi porta gravida at eget metus. Praesent commodo cursus magna, vel scelerisque nisl consectetur et. Praesent commodo cursus magna, vel scelerisque nisl consectetur et. Sed posuere consectetur est at lobortis. Nulla vitae elit libero, a pharetra augue. Praesent commodo cursus magna, vel scelerisque nisl consectetur et.
Donec sed odio dui. Etiam porta sem malesuada magna mollis euismod. Vivamus sagittis lacus vel augue laoreet rutrum faucibus dolor auctor. Nulla vitae elit libero, a pharetra augue. Morbi leo risus, porta ac consectetur ac, vestibulum at eros.
Donec id elit non mi porta gravida at eget metus. Morbi leo risus, porta ac consectetur ac, vestibulum at eros. Integer posuere erat a ante venenatis dapibus posuere velit aliquet. Donec sed odio dui. Donec sed odio dui.
Maecenas faucibus mollis interdum. Donec ullamcorper nulla non metus auctor fringilla. Cras mattis consectetur purus sit amet fermentum. Maecenas faucibus mollis interdum. Nullam quis risus eget urna mollis ornare vel eu leo. Nullam id dolor id nibh ultricies vehicula ut id elit.
It all begins with an idea. Maybe you want to launch a business. Maybe you want to turn a hobby into something more. Or maybe you have a creative project to share with the world. Whatever it is, the way you tell your story online can make all the difference.
Don’t worry about sounding professional. Sound like you. There are over 1.5 billion websites out there, but your story is what’s going to separate this one from the rest. If you read the words back and don’t hear your own voice in your head, that’s a good sign you still have more work to do.
Be clear, be confident and don’t overthink it. The beauty of your story is that it’s going to continue to evolve and your site can evolve with it. Your goal should be to make it feel right for right now. Later will take care of itself. It always does.
Praesent commodo cursus magna, vel scelerisque nisl consectetur et. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Nulla vitae elit libero, a pharetra augue. Etiam porta sem malesuada magna mollis euismod. Nullam id dolor id nibh ultricies vehicula ut id elit.
Duis mollis, est non commodo luctus, nisi erat porttitor ligula, eget lacinia odio sem nec elit. Curabitur blandit tempus porttitor. Aenean eu leo quam. Pellentesque ornare sem lacinia quam venenatis vestibulum. Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus. Donec sed odio dui.
Aenean lacinia bibendum nulla sed consectetur. Curabitur blandit tempus porttitor. Donec id elit non mi porta gravida at eget metus. Praesent commodo cursus magna, vel scelerisque nisl consectetur et. Nullam quis risus eget urna mollis ornare vel eu leo. Vivamus sagittis lacus vel augue laoreet rutrum faucibus dolor auctor.